可以通过在sql语句前面加上explain关键字来查看语句执行的信息
如 explain select * from table where id = 1;
通过这些信息 可以对sql语句做相应的优化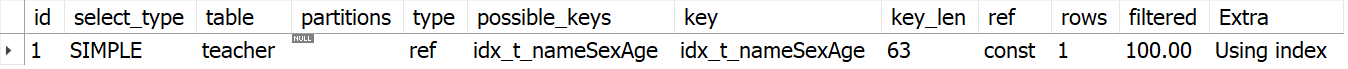
ID字段
select查询的序列号 包含一组数字 表示查询中执行select子句或操作表的顺序
当id相同时 执行顺序由上至下
id不同时 id值越大越先被执行
select_type
查询的类型 主要是用于区分普通查询、联合查询、子查询等复杂的查询
有如下取值:
1)SIMPLE
简单的select查询 查询中不包含子查询或者union
2)PRIMARY
查询中包含任何复杂的子部分 最外层查询则被标记为primary
3)SUBQUERY
在select 或 where列表中包含了子查询
4)DERIVED
在from列表中包含的子查询被标记为DERIVED(衍生)mysql会递归执行这些子查询 把结果放在临时表里
5)UNION
若第二个select出现在union之后 则被标记为union 若union包含在from子句的子查询中 外层select将被标记为DERIVED
6)UNION RESULT
从union合并的表获取结果的select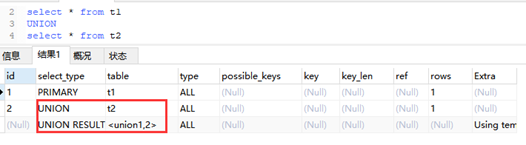
type
访问类型 sql查询优化中一个很重要的指标
性能从好到坏依次是:
system > const > eq_ref > ref > range > index > ALL
一般来说 好的sql查询至少达到range级别 最好能达到ref
1)system
表只有一行记录(等于系统表)这是const类型的特例 平时不会出现 可以忽略不计
2)const
表示通过索引一次就找到了
const用于比较primary key 或者 unique索引 因为只需匹配一行数据 所有很快
如果where查询条件中包含主键 mysql就能将该查询转换为一个const
3)eq_ref
唯一性索引扫描
对于每个索引键 表中只有一条记录与之匹配 常见于主键 或 唯一索引扫描
4)ref
非唯一性索引扫描 返回匹配某个单独值的所有行
本质是也是一种索引访问 它返回所有匹配某个单独值的行
然而他可能会找到多个符合条件的行 可以是0行或多行 所以它应该属于查找和扫描的混合体
5)range
只检索给定范围的行 使用一个索引来选择行
key字段显示使用了那个索引 一般就是在where语句中出现了bettween、<、>、in等的查询
这种范围扫描索引比全表扫描要好
因为只需要开始索引的于某个点 结束于另一个点 不用扫描全部索引
6)index
当查询的结果全为索引列的时候 虽然也是全部扫描 但是只查询的索引库 而没有去查询数据
index与ALL区别为index类型只遍历索引树
Index与ALL虽然都是读全表 但index是从索引中读取 而ALL是从硬盘读取
7)ALL
全表扫描 遍历全表以找到匹配的行
possible_keys
查询涉及到的字段上存在索引 就该索引将被列出 但查询时不一定被使用
key
实际使用的索引 如果为NULL 则没有使用索引
查询中如果使用了覆盖索引 则该索引仅出现在key列表中
key_len
表示索引中使用的字节数 查询中使用的索引的长度(最大可能长度)并非实际使用长度 理论上长度越短越好
key_len是根据表定义计算而得的 不是通过表内检索出的
ref
rows
根据表统计信息及索引选用情况 大致估算出找到所需的记录所需要读取的行数
Extra
包含不适合在其他字段中显示但是十分重要的额外信息
常见取值:
1)Using temporary
使用临时表保存中间结果 也就是说mysql在对查询结果排序时使用了临时表
常见于order by 和 group by
2)Using index
表示相应的select操作中使用了覆盖索引(Covering Index)避免了访问表的数据行 效率高
如果同时出现Using where 表明索引被用来执行索引键值的查找
如果没有同时出现Using where 表明索引用来读取数据而非执行查找动作
3)Using where
使用了where过滤

若有收获,就点个赞吧
0 人点赞
