Java集合(容器)框架
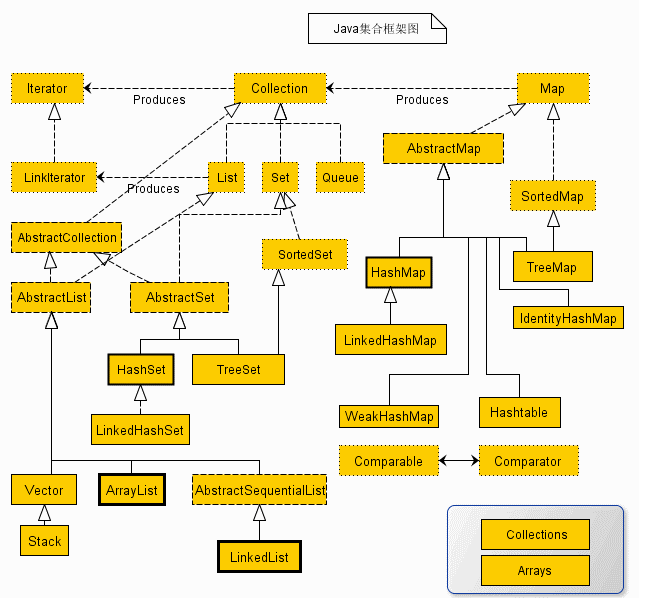
所有的集合框架都包含如下内容:接口、实现(类)、算法。接口下面是一些抽象类,最后是具体实现类。
Collection 与 Map
Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。
Collection 接口又有 3 种子类型,List、Set 和 Queue,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet。
Map常用的实现类有HashMap、LinkedHashMap 等等。
尽管 Map 不是集合,但是它们完全整合在集合中。
List 与 Set
- Set 接口实例存储的是无序的,不重复的数据。List 接口实例存储的是有序的,可以重复的元素;
- Set检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 <实现类有HashSet,TreeSet>;
- List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 <实现类有ArrayList,LinkedList,Vector> | 元素 | List | Set | | :—-: | :—-: | :—-: | | 排序 | 有序 | 无序 | | 重复 | 可重复 | 不重复 | | null | 允许 | 允许 | | 插入效率 | 低 | 高 | | 删除效率 | 低 | 高 | | 查找效率 | 高 | 低 | | 线程安全 | Collections.synchronizedList与CopyOnWriteArrayList | Collections.synchronizedSet与CopyOnWriteArraySet | | 特性 | 动态增长 | 不允许添加重复元素(相同则覆盖原有元素) |
CopyOnWrite适用于读多写少的场景,是以空间换时间的思想
Queue
队列是一种特殊的线性表,它只允许在表的前端进行删除操作,而在表的后端进行插入操作(先进先出)。
常见的有单队列、循环队列…
一般用于缓冲、并发访问。
Map
迭代 Map 中的元素不存在直接了当的方法。如果要查询某个 Map 以了解其哪些元素满足特定查询,或如果要迭代其所有元素(无论原因如何),则您首先需要获取该 Map 的“视图”。有三种可能的视图:
- 所有键值对 — 参见 entrySet()
- 所有键 — 参见 keySet()
- 所有值 — 参见 values()
前两个视图均返回 Set 对象,第三个视图返回 Collection 对象。
调整 Map 大小和选择负载因子
监测您的应用程序。如果发现某个 Map 造成瓶颈,则分析造成瓶颈的原因,并部分或全部更改该 Map 的以下内容:Map 类;Map 大小;负载因子;关键对象 equals() 方法实现。专用的 Map 的基本上都需要特殊用途的定制 Map 实现,否则通用 Map 将实现您所需的性能目标。
Doug Lea 是纽约州立大学奥斯威戈分校计算机科学系的教授。他创建了一组公共领域的程序包(统称 util.concurrent),该程序包包含许多可以简化高性能并行编程的实用程序类。这些类中包含两个 Map,即 ConcurrentReaderHashMap 和 ConcurrentHashMap。这些 Map 实现是线程安全的,并且不需要对并发访问或更新进行同步,同时还适用于大多数需要 Map 的情况。它们还远比同步的 Map(如 Hashtable)或使用同步的包装器更具伸缩性,并且与 HashMap 相比,它们对性能的破坏很小。util.concurrent 程序包构成了 JSR166 的基础;JSR166 已经开发了一个包含在 Java 1.5 版中的并发实用程序,而 Java 1.5 版将把这些 Map 包含在一个新的 java.util.concurrent 程序包中。 —https://www.oracle.com/cn/database/technology/maps.html
迭代器 - Iterator
Java Iterator(迭代器)不是一个集合,它是一种用于访问集合的方法,可用于迭代 ArrayList 和 HashSet 等集合。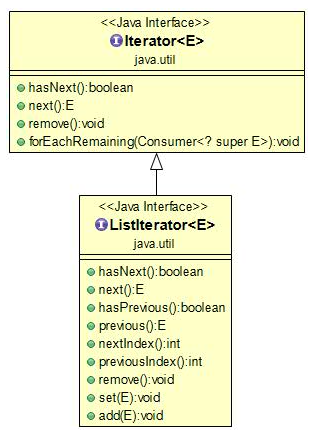
迭代器的基本操作是 next 、hasNext 和 remove
调用 next() 会返回迭代器的下一个元素,并且更新迭代器的状态
调用 hasNext() 用于检测集合中是否还有元素
调用 remove() 将迭代器返回的元素删除
public class IteratorUsage {public static void main(String[] args) {// 创建集合ArrayList<String> list = new ArrayList<>();list.add("1");list.add("2");list.add("3");list.add("4");// 获取迭代器Iterator<String> it = list.iterator();// 输出集合中的所有元素while (it.hasNext()) {// 需要把当前元素读取出来进行操作String item = it.next();if ("3".equals(item)) {//用迭代器 的 remove() 方法后,达到了在删除元素时不破坏遍历it.remove();} else {System.out.println(item);}}}}

比较器 - Comparator
- 排序,需要比较两个对象谁排在前谁排在后
分组,需要比较两个对象是否是属于同一组 … ```java public class Man { public String name; public String gander; public Integer age;
public Man(String name, String gander, Integer age) {
this.name = name;this.gander = gander;this.age = age;
} @Override public String toString(){
return name + "\t" + gander + "\t" + age;} }
public class ComparatorUsage {
public static <T> List<List<T>> group(List<T> dataList, Comparator<? super T> comparator) {
List<List<T>> result = new ArrayList<>();
for (T item : dataList) {
boolean isSameGroup = false;
for (int j = 0; j < result.size(); j++) {
int ret = comparator.compare(item, result.get(j).get(0));
if (ret == 0) {
isSameGroup = true;
result.get(j).add(item);
break;
}
}
if (!isSameGroup) {
List<T> innerList = new ArrayList<T>();
result.add(innerList);
innerList.add(item);
}
}
return result;
}
public static void main(String[] args) {
List<Man> list = new ArrayList<>();
list.add(new Man("Jack", "男", 32));
list.add(new Man("Ross", "女", 12));
list.add(new Man("Ben", "男", 62));
list.add(new Man("Dive", "女", 22));
Collections.sort(list, new Comparator<Man>() {
@Override
public int compare(Man a, Man b) {
return a.age - b.age;
}
});
System.out.println(list);
List<List<Man>> groupByAge = group(list, new Comparator<Man>() {
@Override
public int compare(Man a, Man b) {
// 按年龄分组
if (a.age < 20) {
return -1;
} else if (a.age < 60) {
return 0;
} else {
return 1;
}
}
});
System.out.println(groupByAge);
List<List<Man>> groupByGander = group(list, new Comparator<Man>() {
@Override
public int compare(Man a, Man b) {
// 按性别分组
return a.gander.compareTo(b.gander);
}
});
System.out.println(groupByGander);
}
}

<a name="SidKz"></a>
# ArrayList
> 底层数据结构:动态数组,默认容量10,负载因子0.75,特点:随机存取、自动扩容
> 使用场景:
> 1. 频繁访问列表中的某一个元素;
> 1. 只需要在列表末尾进行添加和删除元素操作
<a name="2Ixy8"></a>
## 扩容
**ArrayList的大小是如何自动增加的?**
> 1. 在arraylist中增加一个对象的时候,会先去检查arraylist数组,以确保已存在的数组中有足够的容量来存储这个新的对象。如果没有足够容量的话(加载因子的系数小于等于1,意指即当元素个数超过容量长度*加载因子的系数时,进行扩容),就会新建一个长度更长的数组,旧的数组就会使用Arrays.copyOf方法被复制到新的数组中去,现有的数组引用指向了新的数组
> 1. 默认大小10(可指定),在扩容时每次扩容都是原容量的1.5倍,newCapacity = (oldCapacity * 3)/2 + 1;
<a name="tzehf"></a>
## 序列化
**ArrayList 中 elementData 为什么使用 transient 修饰?**
```java
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
- 使用了 transient 修饰,可以防止被自动序列化
- 由于 ArrayList 是基于动态数组实现的,所以并不是所有的空间都被使用,因此 ArrayList 自定义了序列化与反序列化,具体可以看 writeObject 和 readObject 两个方法
- 需要注意的一点是,当对象中自定义了 writeObject 和 readObject 方法时,JVM 会调用这两个自定义方法来实现序列化与反序列化
注:其他集合实现同样有这个特点
ArrayList 中的 elementData 为什么是 Object 而不是泛型T ?
- Java 中泛型运用的目的就是实现对象的重用,泛型T和Object类其实在编写时没有太大区别
- JVM中没有T这个概念,T只是存在于编写时,进入虚拟机运行时,虚拟机会对泛型标志进行类型擦除,也就是替换T会限定类型替换(根据运行时类型),如果没有限定就会用Object替换
- Object可以new Object(),就是说可以实例化,而T不能实例化。在反射方面来说,从运行时,返回一个T的实例时,不需要经过强制转换,然后Object则需要经过转换才能得到
???
源码
Vector
All Implemented Interfaces:Serializable, Cloneable, Iterable
, Collection , List , RandomAccess 底层数据结构:动态数组 特点:支持同步、提供随机访问、可克隆、支持序列化、速度慢 扩容:newCapcity = oldCapcity << 1
LinkedList
底层数据结构:双向链表实现、保留了头尾两个指针(维护了first和last节点,可以使用其实现栈,队列,双向队列等),特点:查询慢、插入快、实现了Queue接口 使用场景:
- 需要通过循环迭代来访问列表中的某些元素
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作
HashSet
底层数据结构:HashMap,默认容量16,负载因子0.75 特点:无重复、允许null、无序、存取速度快
HashMap
底层数据结构:链表+数组+红黑树(JDK1.8增加了红黑树,JDK1.8对HashMap底层的实现进行了优化,例如引入红黑树的数据结构和扩容的优化等),默认容量16,负载因子0.75 特点:允许重复、最多只允许一条记录的键为null(允许多条记录的值为null)、无序
Node类的基本属性有: hash:key的哈希值 key:节点的key,类型和定义HashMap时的key相同 value:节点的value,类型和定义HashMap时的value相同 next:该节点的下一节点
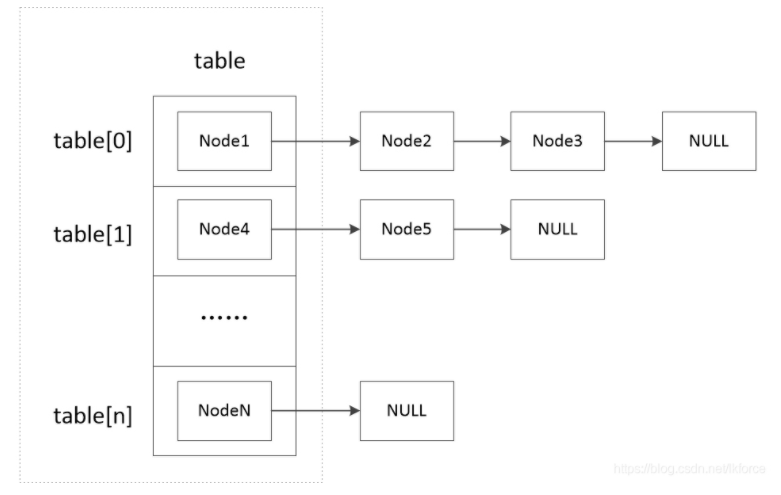
扩容
默认容量16,负载因子0.75,如果HashMap初始化的时候指定了容量,HashMap会把这个容量修改为2的幂等数,然后创建对应长度的table; 当容量超过oldCap*负载因子时 newCap = oldCap << 1 当链表中的节点数量大于TREEIFY_THRESHOLD(8)时,链表将会考虑改为红黑树
HashMap的数组长度为什么保持2的次幂?
减少之前已经散列良好的老数组的数据位置重新调换
保证低位全为1,而扩容后只有一位差异,也就是多出了最左位的1,这样在通过 h&(length-1)的时候,只要h对应的最左边的那一个差异位为0,就能保证得到的新的数组索引和老数组索引一致(大大减少了之前已经散列良好的老数组的数据位置重新调换)
数组长度保持2的次幂,length-1的低位都为1,会使得获得的数组索引index更加均匀
LinkedHashMap
底层数据结构:LinkedList+HashMap(Hash table and linked list implementation of the Map interface) 特点:有序(LinkedList定义了迭代顺序)
线程安全问题
ArrayList、LinkedList、HashSet、HashMap、LinkedHashMap不是线程安全的(可用Collections.synchronized*进行包装) Vector、ConcurrentArrayList、ConcurrentHashMap…是线程安全的
参考
https://www.runoob.com/java/java-collections.html
https://www.oracle.com/cn/database/technology/maps.html

若有收获,就点个赞吧
0 人点赞
