应用与集群管理
本章主要介绍应用与集群相关的一些操作管理命令,包括关闭、重置、开启服务,还有建立集群的一些信息。有关集群搭建请参考后续的「RabbitMQ 运维」章节
应用管理
停止运行 stop 用于停止运行 RabbitMQ 和 Erlang 虚拟机。
rabbitmqctl stop [pid_file]参数:pid_file:通过 rabbitmq-server 命令启动 RabbitMQ 服务创建的。默认情况存放与 rabbitmq安装目录/var/lib/rabbitmq/mnesia 目录下;可以通过 RABBITMQ_PID_FILE 环境变量来改变存放路径。注意:通过 rabbitmq-server --detach 这个后缀命令启动不会生成 pid_file 文件Copied!
1
2
3
4
5
6
实践练习
# 注意啊,我们通过 rabbitmq-server -detached 后台运行启动的# 可以通过它来停止,而且写一个错误的路径也可以停止运行# 通过下面讲解的 shutdown 命令,可以看到这个 pid 或许不是真正的 pid 文件# 因为在启动的时候打印了 Warning: PID file not written; -detached was passed.[root@study mnesia]# rabbitmqctl stop /opt/rabbitmq/var/lib/rabbitmq/mnesia/rabbit@study.pidStopping and halting node rabbit@studyCopied!
1
2
3
4
5
6
停止运行 shutdown
用于停止运行 RabbitMQ 和 Erlang 虚拟机。
rabbitmqctl shutdownCopied!
1
执行该指令会阻塞知道 Erlang 虚拟机进程退出。如果 RabbitMQ 没有成功关闭,则会返回一个非零值。
与 stop 不同的是,不需要指定 pid_file,而且可以阻塞等待指定进程的关闭
实践练习
[root@study mnesia]# rabbitmqctl shutdownShutting down RabbitMQ node rabbit@study running at PID 19531Waiting for PID 19531 to terminateRabbitMQ node rabbit@study running at PID 19531 successfully shut downCopied!
1
2
3
4
停止 RabbitMQ 服务应用:stop_app
停止 RabbitMQ 服务应用,但是 Erlang 虚拟机还是处于运行状态。此命令的执行优先于其他管理操作(这些管理操作需要先停止 RabbitMQ 应用),比如 rabbitmqct reset
实践练习
[root@study mnesia]# rabbitmqctl stop_appStopping rabbit application on node rabbit@studyCopied!
1
2
启动 RabbitMQ 服务应用:start_app
该命令的典型应用场景是:在执行了其他的管理操作之后,重新启动之前停止的 RabbitMQ 应用,比如 rabbitmqct reset
实践练习
[root@study mnesia]# rabbitmqctl start_appStarting node rabbit@studyCopied!
1
2
等待 RabbitMQ 应用的启动:wait
rabbitmqctl wait [pid_file]Copied!
1
等待 RabbitMQ 应用的启动。它会 等到 pid_file 的创建,然后 等待 pid_file 中所代表的进程启动。当指定的进程没有启动 RabbitMQ 应用而关闭时将返回失败。
实践练习
[root@study mnesia]# rabbitmqctl wait /opt/rabbitmq/var/lib/rabbitmq/mnesia/rabbit@study.pidWaiting for rabbit@studypid is 18130Error: process_not_running# 前面讲到启动时,有一个警告 Warning: PID file not written;# 在这里也能证明出来,的确没有写入。这个 18130 可能是最开始笔者不小心直接执行了 rabbitmq-server 创建的Copied!
1
2
3
4
5
6
重置 RabbitMQ 节点:reset
rabbitmqctl resetCopied!
1
将 RabbitMQ 节点重置还原到最初状态。包括从 原来所在的集群中删除此节点,从管理数据库中删除所有的配置数据,如已配置的用户、vhost 等。以及删除所有的持久化消息。
执行该命令前必须停止 RabbitMQ 应用,比如先执行 rabbitmqctl stop_app
这里笔者就不尝试实践了,只有一个节点
强制重置 RabbitMQ 节点:force_reset
rabbitmqctl force_resetCopied!
1
与 reset 类似,不过它无论当前管理数据库的状态和集群配置是什么,都会无条件的重置节点。只能在数据库或集群配置已损坏的情况下使用。
配置轮换日志文件:rotate_logs
rabbitmqctl rotate_logs {suffix}Copied!
1
配置 RabbitMQ 节点轮换日志文件。RabbitMQ 节点会将原来的日志文件中的内容追加到「原始名称 + 后缀」的日志文件中,然后再将新的日志内容记录到新创建的日志文件中(与原日志同名)。
当目标文件不存在时,会重新创建。如果不指定 suffix 后缀,则日志文件只是重新打开而不会进行轮换。
实践练习
# 进入到日志目录[root@study ~]# cd /opt/rabbitmq/var/log/rabbitmq/[root@study rabbitmq]# ll总用量 60-rw-r--r--. 1 root root 59781 6月 29 06:04 rabbit@study.log-rw-r--r--. 1 root root 0 6月 23 10:23 rabbit@study-sasl.log# 执行轮换操作[root@study rabbitmq]# rabbitmqctl rotate_logs .1Rotating logs to files with suffix ".1"[root@study rabbitmq]# ll总用量 60-rw-r--r--. 1 root root 0 6月 29 06:17 rabbit@study.log-rw-r--r--. 1 root root 59856 6月 29 06:17 rabbit@study.log.1-rw-r--r--. 1 root root 0 6月 29 06:17 rabbit@study-sasl.log-rw-r--r--. 1 root root 0 6月 29 06:17 rabbit@study-sasl.log.1# 可以看到原来的文件被归档了一样。Copied!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
编译:hipe_compile
rabbitmqctl hipe_compile {directory}Copied!
1
将部分 RabbitMQ 代码用 HiPE 编译,并将编译后的 .beam 文件保存到指定的文件目录中。如果该目录不存在则会创建,如果存在,则先删除里面的任何 .beam 文件。
如果要使用预编译的这些文件,则需要设置 RABBITMQ_SERVER_CODE_PATH 环境变量来指定 hipe_compile 调用的路径
名词解释:
- HiPE:High Performance Erlang,是 Erlang 版的 JIT 编译
- .beam :是 Erlang 编译器生成的文件格式,可以直接加载到 Erlang 虚拟机中运行的文件格式
如下所示
[root@study rabbitmq]# rabbitmqctl hipe_compile /opt/rabbitmq/tmp/rabbit-hipe/ebinHiPE compiling: |---------------------------------------------------------||#########################################################|Compiled 57 modules in 221sCopied!
1
2
3
4
5
6
7
虽然知道有啥用处,指定的新目录里面的确多了很多 .beamni c 文件
集群管理
这里只列出来命令,具体的使用详见后续章节 RabbitMQ 运维;
#加入集群:join_cluster
rabbitmqctl join_cluster {cluster_node} [--ram]Copied!
1
集群状态:cluster_status
rabbitmqctl cluster_statusCopied!
1
修改集群节点类型
rabbitmqctl change_cluster_node_type {disc | ram }Copied!
1
修改集群节点的类型,修改之前需要停止 RabbitMQ 引用
删除集群节点:forget_cluster_node
rabbitmqctl forget_cluster_node [--offline]Copied!
1
更新集群信息:update_cluster_nodes
rabbitmqctl update_cluster_nodes {clusternode}Copied!
1
在集群中的节点应用启动前咨询 clusternode 节点的最新信息,并更新相应的集群信息;
与 join_cluster 不同,它不加入集群;如这种情况:
- 节点 A 和节点 B 在集群中,
- 当节点 A 离线了,节点 C 又和 节点 B 组成了一个集群,
- 然后节点 B 又离开了集群
当节点 A 醒来时,它会尝试联系节点 B,但是这样会失败,因为节点 B 已经不在集群中了。
rabbitmqctl update_cluster_nodes -n A CCopied!
1
确保节点可以启动:force_boot
rabbitmqctl force_bootCopied!
1
确保节点可以启动,即使它不是最后一个关闭的节点。
通常情况下,当关闭整个 RabbitMQ 集群时,重启的第一个节点 应该是最后关闭的节点,因为它可以看到其他节点所看不到的事情。但是有时候会出现一些异常情况,比如整个集群都断电,所有节点都不是最后一个关闭的。
在这种情况下就可以使用该命令告诉节点可以无条件启动。
在此节点关闭后,集群的任何变化,都会丢失。如果最后一个关闭的节点永久丢失了,那么需要优先使用
rabbitmqctl forget_cluster_node --offlineCopied!
1
同步镜像队列内容:sync_queue
rabbitmqctl sync_queue [-p vhost] {queue}Copied!
1
指定 未同步队列 queue 的 slave 镜像可以同步 master 镜像行的内容。同步期间此队列会被阻塞(所有此队列的生产消息都会被阻塞),直到同步完成。
前提是:配置了 queue 镜像
注意:未同步队列中的消息被消耗尽后,最终也会变成同步,此命令主要用于未耗尽的队列。(详见后组章节 RabbitMQ 高阶)
取消镜像队列同步:cancel_sync_queue
rabbitmqctl cancel_sync_queue [-p vhost] {queue}Copied!
1
设置集群名称:set_cluster_name
rabbitmqctl set_cluster_name {name}Copied!
1
设置集群名称。
集群名称在客户端连接时会通报给客户端。Federation 和 Shovel 插件也会有用到集群名的地方,详细内容参考后续章节 跨越集群的界限
集群名称 默认是集群中第一个节点的名称,通过该命令重新设置。在 web 管理界面右上角有可以修改,如下图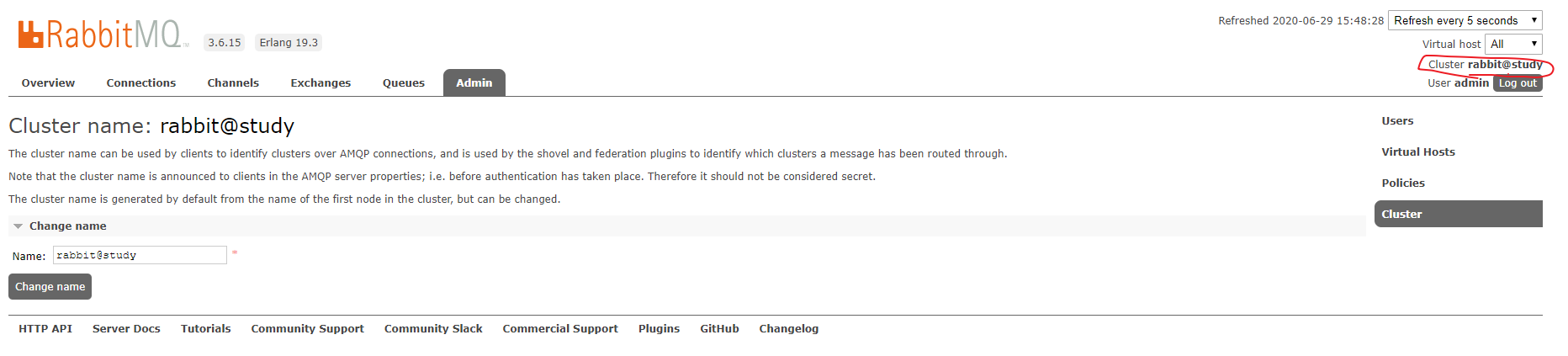
通过集群状态也能查看到当前的集群名称
[root@study rabbitmq]# rabbitmqctl cluster_statusCluster status of node rabbit@study[{nodes,[{disc,[rabbit@study]}]},{running_nodes,[rabbit@study]},{cluster_name,<<"rabbit@study">>},{partitions,[]},{alarms,[{rabbit@study,[]}]}]# 这个是没有操作过集群的,默认就是个单节点的集群

若有收获,就点个赞吧
0 人点赞
