开一个坑来学习下dgl官方教程中的dgl.nn相关网络
https://docs.dgl.ai/api/python/nn.pytorch.html#
https://www.yuque.com/mamudechengxuyuan/od99k2/tiqmtt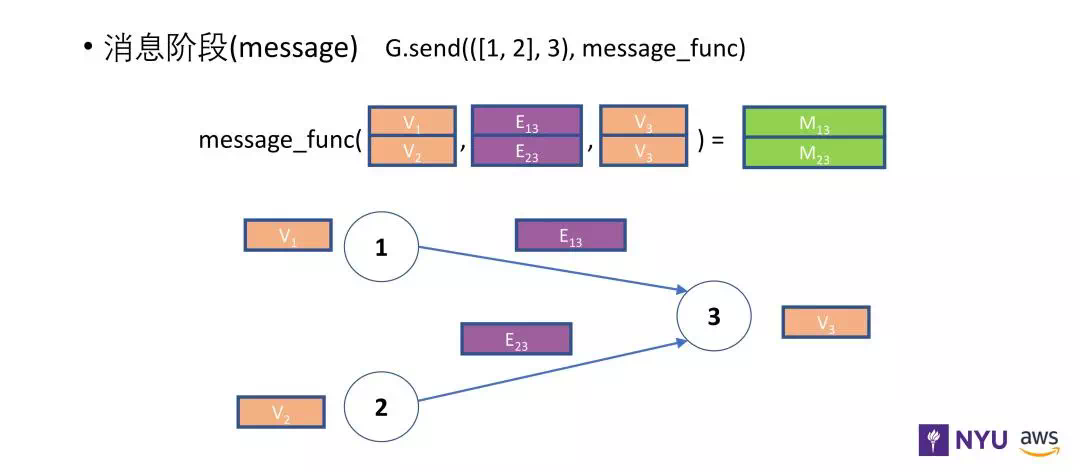
Conv Layer
GraphConv
classdgl.nn.pytorch.conv.``GraphConv(in_feats, out_feats, norm=’both’, weight=True, bias=True, activation=None, allow_zero_in_degree=False)forward(graph, feat, weight=None, edge_weight=None)
论文:https://arxiv.org/abs/1609.02907
图卷积的更新函数为: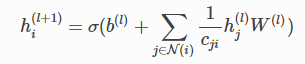
N(i)是节点i的邻居节点集合,Cji是节点度的平方根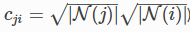 ,σ是激活函数。
,σ是激活函数。
若每条边的权重tensor是给定的,那么weighted graph conv的更新函数为: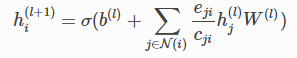
其中eji是节点j到节点i的边的标量权重,需注意这与论文中定义的权重图卷积网络不同。
注意:零入度的节点会导致非法输出值(因为没有信息流入,聚合函数会得到空的输入),一般采用对每个节点添加self-loop的边来避免这种问题(同构图而言)
g = dgl.add_self_loop(g)
EdgeWeightNorm
classdgl.nn.pytorch.conv.``EdgeWeightNorm(norm=’both’, eps=0.0)forward(graph, edge_weight)
该模块将标量边权重按图结构进行normalize
RelGraphConv
classdgl.nn.pytorch.conv.``RelGraphConv(in_feat, out_feat, num_rels, regularizer=’basis’, num_bases=None, bias=True, activation=None, self_loop=True, low_mem=False, dropout=0.0, layer_norm=False)
num_rels: 关系的数量
num_bases:基底的数量,默认等于关系数forward(g, feat, etypes, norm=None)
论文:**https://arxiv.org/abs/1703.06103
关系图卷积层的更新函数为: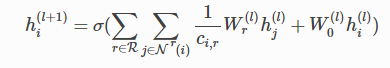
其中N(i)是节点i的邻居节点集合,r为关系,c是归一化数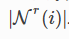 ,W0是self-loop权重
,W0是self-loop权重
基正则化通过该式分解Wr: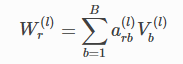
其中B是基底的数量,通过基底的线性组合得到权重矩阵
TAGConv
classdgl.nn.pytorch.conv.``TAGConv(in_feats, out_feats, k=2, bias=True, activation=None)
forward(graph, feat)
论文:https://arxiv.org/pdf/1710.10370.pdf
Topology Adaptive Graph Conv的更新函数为: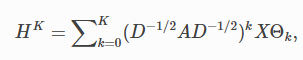
其中A是邻接矩阵,D是对角线度矩阵,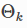 是将不同跳的结果线性求和的权重系数,k代表跳数
是将不同跳的结果线性求和的权重系数,k代表跳数
GATConv
classdgl.nn.pytorch.conv.``GATConv(in_feats, out_feats, num_heads, feat_drop=0.0, attn_drop=0.0, negative_slope=0.2, residual=False, activation=None, allow_zero_in_degree=False)
negtivate_slope:LeakyReLU angle of negative slope.
residual:是否使用残差连接
forward(graph, feat, get_attention=False)
get_attention:是否返回attention value
返回的是(N, H, Dout),其中H是头的数量;若返回attention值,则是一个(E, H, 1)的tensor,其中E是边的数量
论文:**https://arxiv.org/pdf/1710.10903.pdf
图注意力网络更新函数为: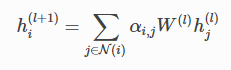
其中αij是节点i和j之间的权重分数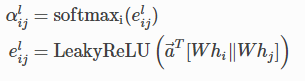
EdgeConv
classdgl.nn.pytorch.conv.``EdgeConv(in_feat, out_feat, batch_norm=False, allow_zero_in_degree=False)forward(g, feat)
论文:https://arxiv.org/pdf/1801.07829.pdf
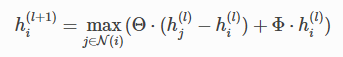
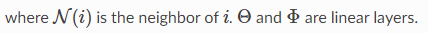
SAGEConv
classdgl.nn.pytorch.conv.``SAGEConv(in_feats, out_feats, aggregator_type, feat_drop=0.0, bias=True, norm=None, activation=None)
aggregator_type: 可供选择的聚合器有mean,gcn,pool,lstmforward(graph, feat, edge_weight=None)
论文:https://arxiv.org/pdf/1706.02216.pdf
GraphSAGE的更新函数为: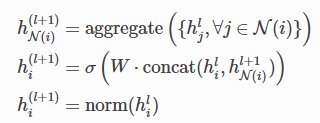
若提供了每条边的权重tensor,那么聚合过程为: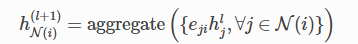
其中eji是节点j到i的标量权重
SGConv
classdgl.nn.pytorch.conv.``SGConv(in_feats, out_feats, k=1, cached=False, bias=True, norm=None, allow_zero_in_degree=False)
k:跳数
cached:模块是否在第一次前向计算时缓存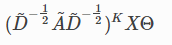 ,在Transductive Learning时设置为True
,在Transductive Learning时设置为Trueforward(graph, feat)
**
论文:https://arxiv.org/pdf/1902.07153.pdf
Simplifying Graph Conv的更新函数定义为: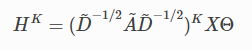
其中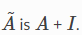 (即图的输入是具有自循环边的)
(即图的输入是具有自循环边的)
APPNPConv
classdgl.nn.pytorch.conv.``APPNPConv(k, alpha, edge_drop=0.0)
k:迭代次数
alpha:teleport probabilityforward(graph, feat)
论文:https://arxiv.org/pdf/1810.05997.pdf
Approximate Personalized Propagation of Neural Prediction layer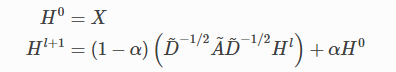
GINConv
classdgl.nn.pytorch.conv.``GINConv(apply_func, aggregator_type, init_eps=0, learn_eps=False)
apply_func:激活函数
aggregator_type:聚合器类型可选(sum,max,mean)
init_eps:初始ε
learn_eps:ε是否可学习forward(graph, feat, edge_weight=None)
**
论文:https://arxiv.org/pdf/1810.00826.pdf
Graph Isomorphism Network layer(同构网络层)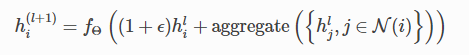
若提供了边权重eji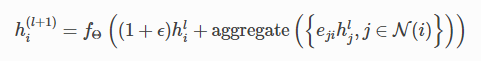
GatedGraphConv
classdgl.nn.pytorch.conv.``GatedGraphConv(in_feats, out_feats, n_steps, n_etypes, bias=True)forward(graph, feat, etypes)
论文:https://arxiv.org/pdf/1511.05493.pdf
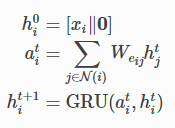
GMMConv
classdgl.nn.pytorch.conv.``GMMConv(in_feats, out_feats, dim, n_kernels, aggregator_type=’sum’, residual=False, bias=True, allow_zero_in_degree=False)forward(graph, feat, pseudo)
论文:http://openaccess.thecvf.com/content_cvpr_2017/papers/Monti_Geometric_Deep_Learning_CVPR_2017_paper.pdf
混合高斯模型卷积层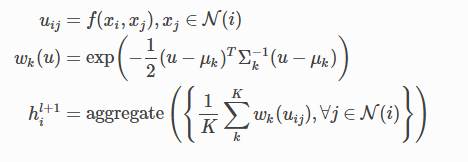
ChebConv
AGNNConv
NNConv
AtomicConv
CFConv
DotGatConv

若有收获,就点个赞吧
0 人点赞
