Reactor 模型
Reactor 模型的 IO
Reactor 模型,其 IO 属于同步非阻塞 IO。下面仍以 channel 发起读操作请求为例来分析整个执行过程:
- 当 channel 的执行线程发起了 read()调用后,其会向 selector 注册了 OPS_READ 事件然后该线程会不停的查看该事件是否就绪。
- 当 selector 接收到这个注册后,其就会不停的查看该 channel 所关联的网卡缓存中是否具有了数据。当 selector 轮询到该 channel 的网卡缓存中具有了数据后,该读操作就绪。
- 此时该线程就查看到了就绪,会发起 system call,将网卡缓存中的数据读取到 user buffer中。这些操作完成后,会再执行 read()后面的逻辑。整个执行过程,该线程未发生阻塞。所以 Reactor 模型是“同步非阻塞 IO”模型。
Reactor 单线程模型
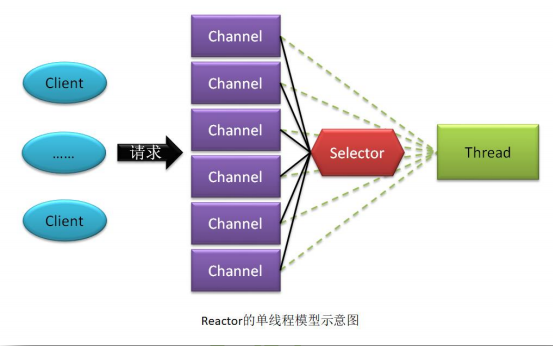Reactor 单线程模型,指的是当前的 Sever 会为每一个通信对端形成一个 Channel,而所有这些 Channel 都会与一个线程相绑定,该线程用于完成它们间的所有通信处理。线程主要的工作是:
如果是 Server,则该线程需要接收并处理 Client 的连接请求。
如果是 Client,则该线程需要向 Server 发起连接。
读取通信对端的消息。
向通信对端发送消息。
Reactor 线程池模型
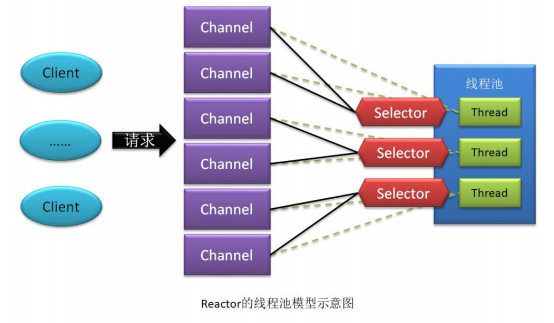Reactor 单线程模型中使用一个线程处理所有通信对端的所有请求,在高并发场景中会严重影响系统性能。所以将单线程模型里面的这个单线程替换成了一个线程池,既 为每个Selector会为Channel分配一个线程池专门来处理这个Channel的请求以来提高在高并发场景下的性能。
Reactor 多线程池模型

如果客户端的连接的并发量是数以百万计的,而且 IO 操作还比较耗时,此时的 Server 即使采用的是 Reactor 线程池模型,系统性能也会急剧下降。此时,可以将连接操作与 IO 操作分开处理,形成 Reactor 的多线程模型。当客户端通过处理连接请求的 Channel 连接上 Server 后,系统会为该客户端再生成一个子 Channel 专门用于处理该客户端的 IO 请求。这两类不同的 Channel 连接着两类不同的线程池。而线程池中的线程数量,可以根据需求分别设置。提高了系统性能。
Netty-Server 的 Reactor 模型

中的每一个 EventLoop 都绑定着一个线程,用于处理该 Channel 与当前 Server 间的操作。Netty-Server 采用了多线程模型。不过线程池是由 EventLoopGroup 充当。EventLoopGroup一个 Channel 只能与一个 EventLoop 绑定,但一个 EventLoop 可以绑定多个 Channel。即 Channel与 EventLoop 间的关系是 n:1。
Netty-Client 的 Reactor 模型

Netty-Client 采用的是线程池模型。因为其只需要与 Server 连接一次即可,无需区分连接请求与 IO 请求。
Proactor 模型
在高性能的网络通信设计中,有两个比较著名的网络通信模型 Reactor 和 Proactor 模式,其中 Reactor 模式属于同步非阻塞 I/O 的网络通信模型,而 Proactor 运属于异步非阻塞 I/O的网络通信模型。Proactor 模型,其 IO 属于异步非阻塞 IO。下面仍以 channel 发起读操作请求为例来分析整个执行过程:
当 channel 的执行线程调用了异步的 read()操作后,其会继续执行 read()后的逻辑。而该 read()会将本次操作注册到一个 Proactor 实例中,注册本次操作关注的事件为 Read Complete。
一个 channel 的所有 IO 操作共享一个 Proactor 实例这个 Proactor 实例是在 channel 创建时完成的初始化。每个Proactor 实例具有一个绑定的线程,用于执行相关 IO 操作。
当 Proactor 实例接收了 read()操作的注册后,其会为网络缓存注册一个监听。若网卡缓存中有了数据,则马上通过 DMA 控制将数据写入到 user buffer 中。一旦数据写入 user buffer完成,则该 IO 操作完毕,产生 Read Complete 事件,此时会将该事件写入到 Proactor 所维护的一个队列。Proactor 实例会将队列中的事件发送给各个 IO 调用者线程,以使他们触发相应的回调。
当前 read()操作的调用线程无需阻塞等待 read()操作的完成,而是直接执行后面的逻辑。由于 read()操作本身是由另外一个线程来执行,所以 Proactor 模型是“异步非阻塞 IO”模型。
Reactor 中的 selector 是一种“事件分离器”的实现。在 Proactor 中不存在事件分离器,但存在一个 Proactor 实例。该实例会根据不同的 IO 操作,监听不同的内容。例如,本例为网卡缓存注册了监听。
Proactor 优缺点
- Proactor 在处理高耗时 IO 时的性能要高于 Reactor,但对于低耗时 IO 的执行效率提升并不明显。
- Proactor 的异步性使其并发处理能力要强于 Reactor。
- Proactor 的实现逻辑复杂,编码成本较 Reactor 要高很多。
- Proactor 的异步依赖于操作系统对于异步的支持。若操作系统对异步的支持不好,Proactor 的性能还不如 Reactor。
Netty 与 Proactor
Netty4 是 NIO 的,其网络通信模型采用的是 Reactor。
Netty5 是 AIO 的,其网络通信模型采用的是 Proactor。但该版本已经被不再维护。主要原因还是 Linux 目前对于异步的支持不完善,导致其执行效率很低。
Proactor 与 Epoll
Proactor 与 Epoll 是没有可比性的
Epoll:是“事件分离器”对就绪事件的发现方式,有 select、poll 与 epoll 三种方式。epoll采用的是回调方式,而不是轮询方式。Reactor 模型中具有“事件分离器”。
Proactor:是一种网络通信模型,该模型中就不存在“事件分离器”。
Netty 中的 Epoll 多路复用器
epoll 的效率在如下场景中并不一定比 poll 的高。
- 当出现大批量的读/写事件切换时,epoll 的效率会远远低于 poll。因为 epoll 需要进行大量的用户空间到内核空间的切换,而 poll 仅需要在用户空间做简单的位运算即可完成。
- 若Client与Server端有大量的仅用于传递少量数据的短连接,则epoll的效率要低于poll。因为 epoll 下的每个 socket 连接都需要发生两次用户空间与内核空间的转换,而 poll 不需要。
- epoll 完全属于 Linux,虽然其它系统平台也有 epoll 的支持,但并不完全相同。
- 高性能处理的代码编写逻辑 epoll 要比 poll 更复杂,更难调试。特别是边缘触发。如果错过额外的读/写操作,很容易导致死锁。

若有收获,就点个赞吧
0 人点赞
