一、requests模块
- urllib 模块 【比较古老的模块,已经被requests模块取代】
- requests 模块 : python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高
使用流程
- 指定url
**url = "目标地址"**
**
- 发起请求 get/post ,返回一个响应对象
**response = requests.get(url = url)****response.encoding="utf-8" # 修改响应对象的字符集**
- 获取响应数据 [请求对象.text 属性]
**page_text = response.text**
- 持久化存储数据
**file = open("./新建文件名.html","w" encoding=" utf-8")****file.write(text)****file.close()**
3、爬虫简单使用
import requestsif __name__ == '__main__':# 指定爬取网址url = "https://www.baidu.com/"# 发起请求response = requests.get(url=url)# 修改响应的字符集response.encoding = "utf-8"# 获得爬取的信息page_text = response.text# 持久化file = open("./vip.html", "w", encoding="utf-8")file.write(page_text)file.close()print("爬取数据完毕")
二、爬取指定词条的搜索结果页面 (网页采集器) 指定关键字搜索爬虫
1、UA检测:
门户网站的服务器回检测对应请求的载体身份标识,如果检测到请求的载体身份标识位某一款浏览器,那么这次请求一定是一个正常的请求。但是如果检测到请求的载体身份标识不是某一款浏览器的,则表示该次请求为不正常的请求(爬虫),服务器端很有可能拒绝该次请求
2、UA伪装:User-Agent(请求载体的身份标识)
让爬虫对应的请求载体身份标识伪装城某一款浏览器
import requestsif __name__ == '__main__':# UA伪装:将对应的User-Agent 封装到一个字典中# 从浏览器中 复制一个user-agent 过来,然后存到字典中headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/85.0.4183.121 Safari/537.36 "}# 处理url携带的参数 query的参数url = "https://www.sogou.com/web"# 将url携带的参数封装到字典中kw = input("请输入要搜寻的关键字:")param = {"query": kw}# 现在对指定的url 发起的请求,url是携带参数的,并且请求过程中处理了参数# 第二个参数:是查询中的参数# 第三个参数:是浏览器的User-Agent 请求头参数 UA 伪装response = requests.get(url=url, params=param, headers=headers)page_text = response.textfile_name = kw + ".html"with open(file_name, "w", encoding="utf-8") as fl:fl.write(page_text)print(file_name, " 爬取完毕")
三、破解百度翻译 (爬取 POST请求返回的json数据)
- 在百度翻译的页面中输入 单词之后,会自动的发送AJAX请求 更新页面中的局部内容
- 每次输入一个字符,就会发送一个AJAX请求,如果输入abc 会有3个XHR请求
- 服务器响应回来的数据类型格式 application/json
- post 请求,携带了参数 “kw” : “单词”
import requests# 导入json的包import jsonif __name__ == '__main__':# 1.指定url post请求地址在开发者工具那里看post_url = "https://fanyi.baidu.com/sug"e = input("输入要翻译的中文:")data = {"kw": e}# 在请求之前进行UA伪装headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/85.0.4183.121 Safari/537.36 "}# 2.发送post请求# data形参:接收一个字典,字典里面存放了数据# headers形参:UA伪装response = requests.post(url=post_url, data=data, headers=headers)# 3. 因为返回的是json数据,所以方法名是json(),返回一个字典对象# 如果确认响应数据是json 类型的 才可以使用json() 接收返回的数据dict_obj = response.json()# 存储文件名file_name = e + ".json"# 4. 进行持久化存储,直接存储成json格式的文件# json包下的dump()方法将信息写入到json格式的文本中# 第一个参数是字典变量,第二个参数是是一个open()返回的对象,第三个参数 表示禁用ascii 编码file = open(file_name, "w", encoding="utf-8")json.dump(dict_obj, fp=file, ensure_ascii=False)print("数据爬取结束")
四、练习
1、爬取豆瓣电影的电影排行榜 (AJAX发送get请求,json数据)
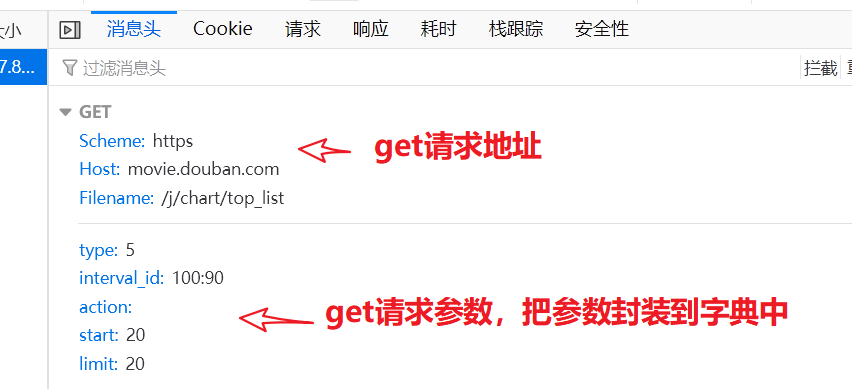
import requestsimport jsonif __name__ == '__main__':# 1.指定urlurl = "https://movie.douban.com/j/chart/top_list"# 指定携带参数dict_info = {"type": "5","interval_id": "100:90","action": "","start": "0", # 从库中第几部电影去取"limit": "100" # 一次性取出来多少个}# UA 伪装headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/85.0.4183.121 Safari/537.36 "}# 2.发送get请求response = requests.get(url, dict_info, headers=headers)# 3.获取响应数据dict_obj = response.json()# 4.处理响应数据file = open("douban.json", "w", encoding="utf-8")json.dump(dict_obj, fp=file, ensure_ascii=False)print("豆瓣排行榜爬取完毕")
2、爬取国家药品管理总局 化妆品生产许可证相关数据

此页面在加载完毕的时候会发送AJAX请求,向后端发送请求
动态加载数据 : 由ajax或其他异步通信方式 发送请求 获取数据
通过ajax 普通爬取后,发现爬到的数据只有 名字,和id 等垃圾信息,没有 许可证信息
通过企业名称进去后,发现路径是 :http://scxk.nmpa.gov.cn:81/xk/itownet/portal/dzpz.jsp?id=b47a8488b1a640f0b46cdc73d71fa244
通过id来获取许可证详细信息【详情页的数据也是动态获取的 通过id值】
所以得出:可以批量获取多家企业的id后【通过第一次爬取的json串中的 id值】,然后再通过id爬取更详细的信息
import requestsimport jsonif __name__ == '__main__':url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList"# UA 伪装headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/85.0.4183.121 Safari/537.36 "}# 用来存储所有的企业详情数据 列表all_data_list = []params = {"on": "true","page": "1","pageSize": "15","productName": "","conditionType": "1","applyname": "","applysn": "",}# 发送post请求response = requests.post(url, params=params, headers=headers)response.encoding = "utf-8"# 返回一个字典info_json = response.json()# 通过查看json 发现里面有一个List list里面有idinfo_list = info_json["list"]# 通过遍历 获得id,for x in info_list:info_id = x["ID"]url = "http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById"# 将获取的id值 封装到字典中new_data = {"id": info_id}# 发送post请求new_response = requests.post(url=url, data=new_data, headers=headers)# 得到爬取的数据dict_json = new_response.json()# 将爬到的数据【字典】 追加到外面的列表中all_data_list.append(dict_json)# 将爬取的数据 追加写入到 文件中fl = open("国家药品.json", "w", encoding="utf-8")json.dump(all_data_list, fp=fl, ensure_ascii=False)fl.close()print("爬取完毕")

若有收获,就点个赞吧
0 人点赞
