一、概述
HBase是针对谷歌BigTable的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的
与传统数据库对比
- 数据类型:HBase将数据存储为未经解释的字符串
- 数据操作:HBase不存复杂的表与表之间的关系
- 存储模式:HBase按列存储,可以降低IO开销,支持大量并发用户查询
- 数据索引:HBase只有一个索引——行键。关系数据库可以有多个负责索引
- 数据维护:HBase执行更新操作时,不会删除原有数据
- 可伸缩性:关系数据库很难实现横向扩展。
二、HBase的实现原理
在一个HBase中,存储了很多的表,每个表中的行是根据行键的字典进行排序的,因为包含的行的数量很大,无法存储在一台机器上。需要按照行键的值对表中的行进行分区,每个行区间构成一个分区,称为“Region”,包含了某个值域区间的所有数据,是负载均衡和数据分发的基本单位,这些Region会被分发的不同的Region服务器上,一个Region的默认大小是100MB~200MB,Master主服务器会将Region分配到不同的Region服务器上,每个Region服务器负责管理一个Region集合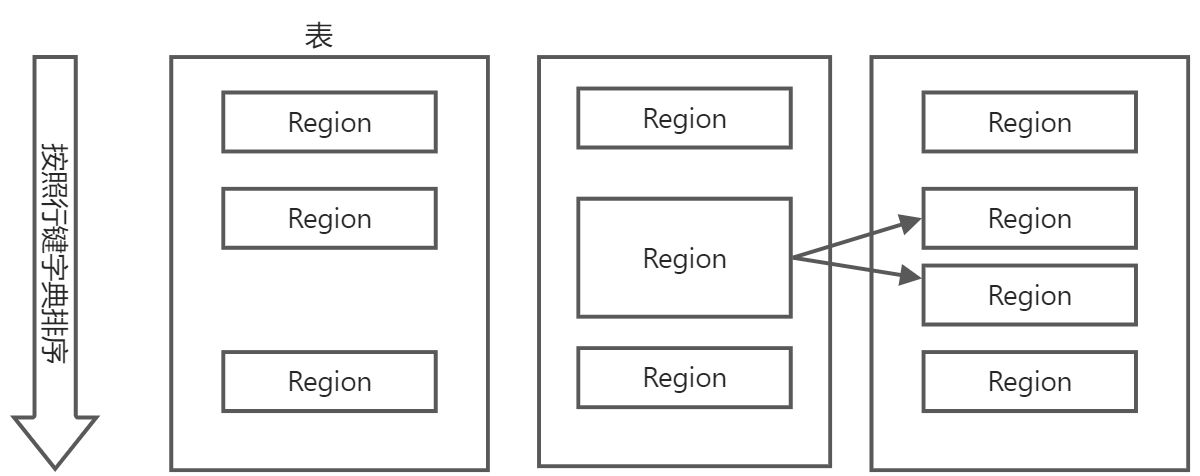
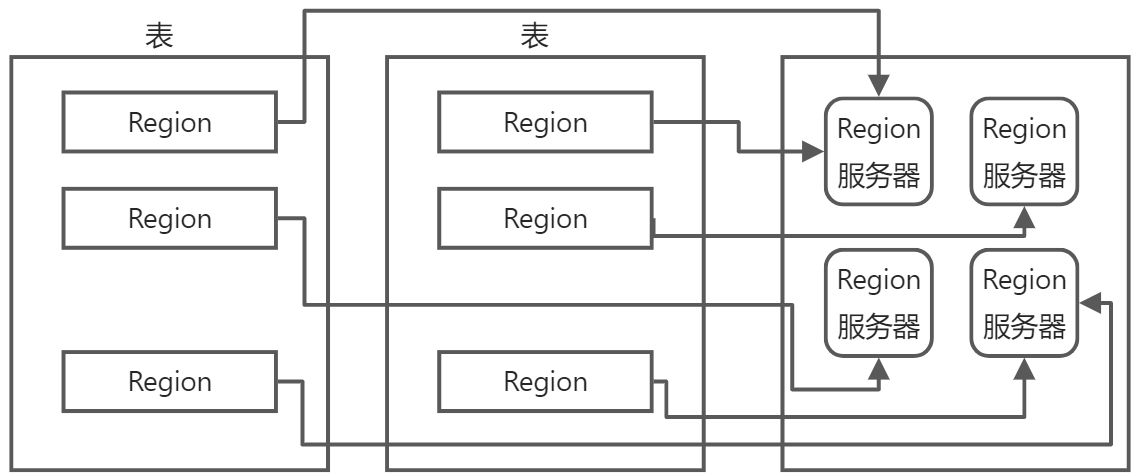
Region的定位
必须设计相应的Region定位机制,保证客户端知道在哪里可以找到自己需要的数据。
Region标识符:表名+Region ID+开始主键
需要有存放Region标识符(元信息)的表——.META.表(元数据表)
当.META.表的条目变多时,.META.表也会被分裂成多个Region
因此需要再构建新的映射表——根数据表(-ROOT-表),-ROOT-表是不能被分割的,永远只存在一个Region用于存放-ROOT-表。
注意:为了加快访问速度,.META.表的全部Region都保存在内存中。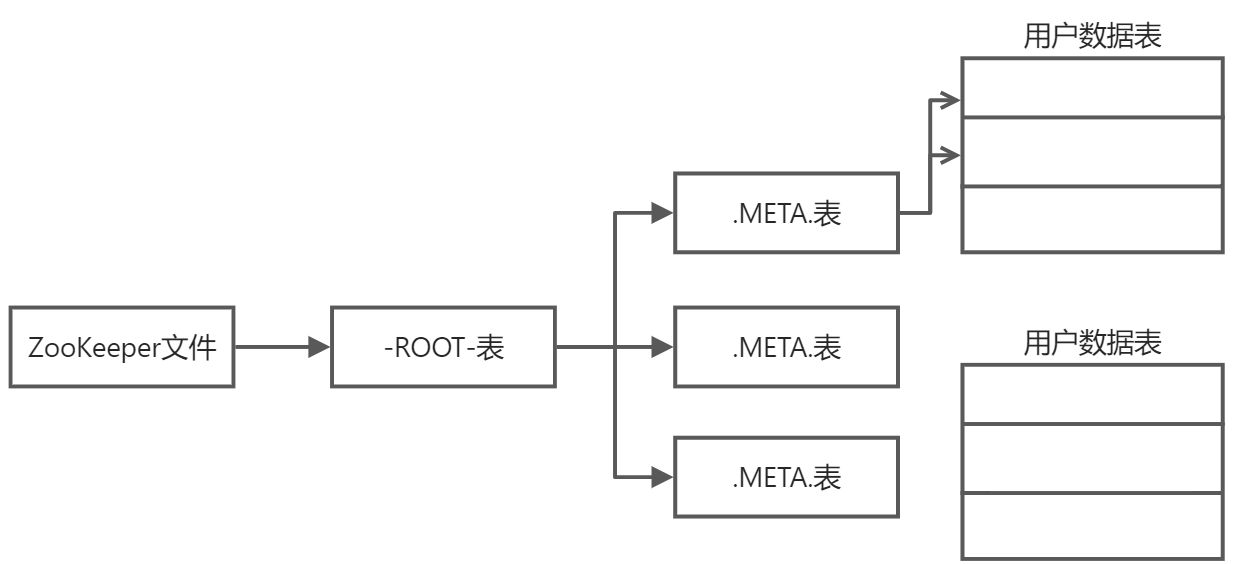
当客户端访问数据时,不会访问主服务区master,而是首先访问ZooKeeper,获取-ROOT表的位置信息,然后访问-ROOT表,获取.META.表,接着访问.META.表,找到所需的Region位于哪个Region服务器,然后才会到该服务器读取信息。
三、HBase的运行机制
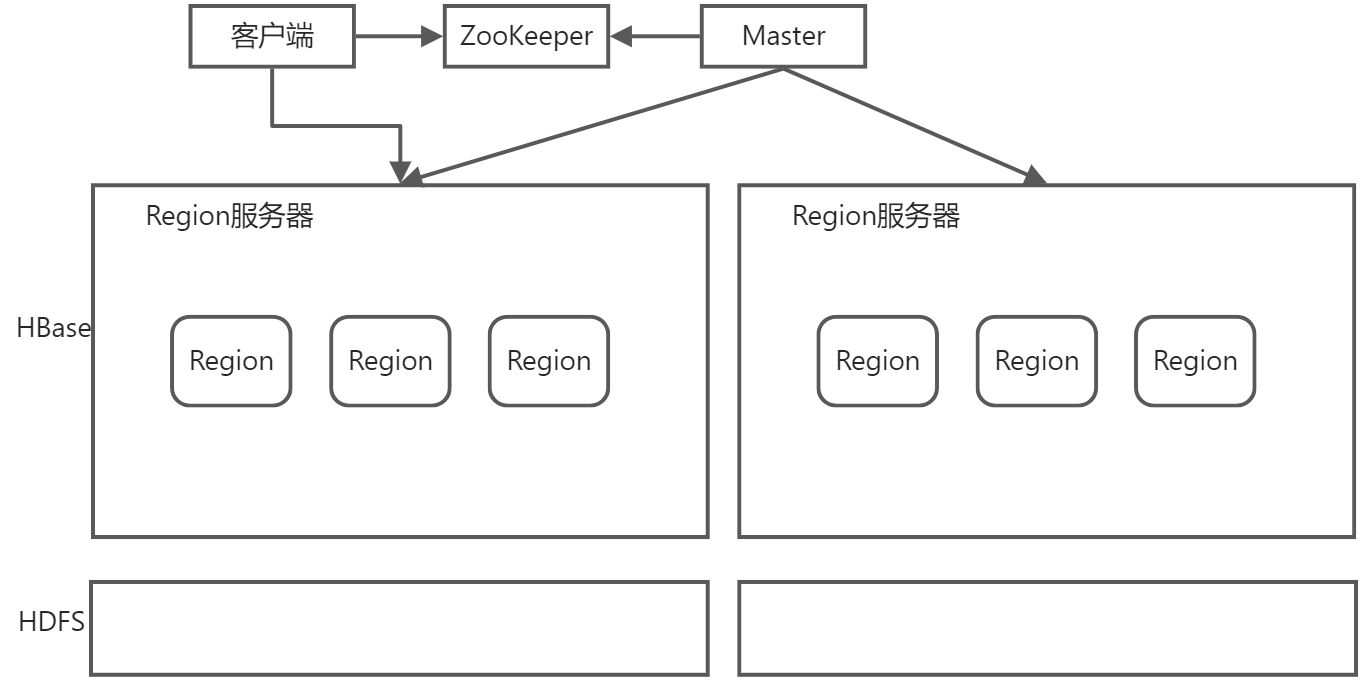
Master
主要负责表和Region的管理工作。
- 管理用户对表的增加、删除、修改、查询
- 实现不同Region服务器的负载均衡
- 当Region分裂或合并后,车东西调整其分布
- 对发生故障的Region服务器上的Region进行迁移
HBase一般采用HDFS作为底层数据存储。
对于管理类操作,客户端与Master进行RPC。
对于数据读写类操作,客户端与Region服务器进行RPC
Region服务器的工作原理
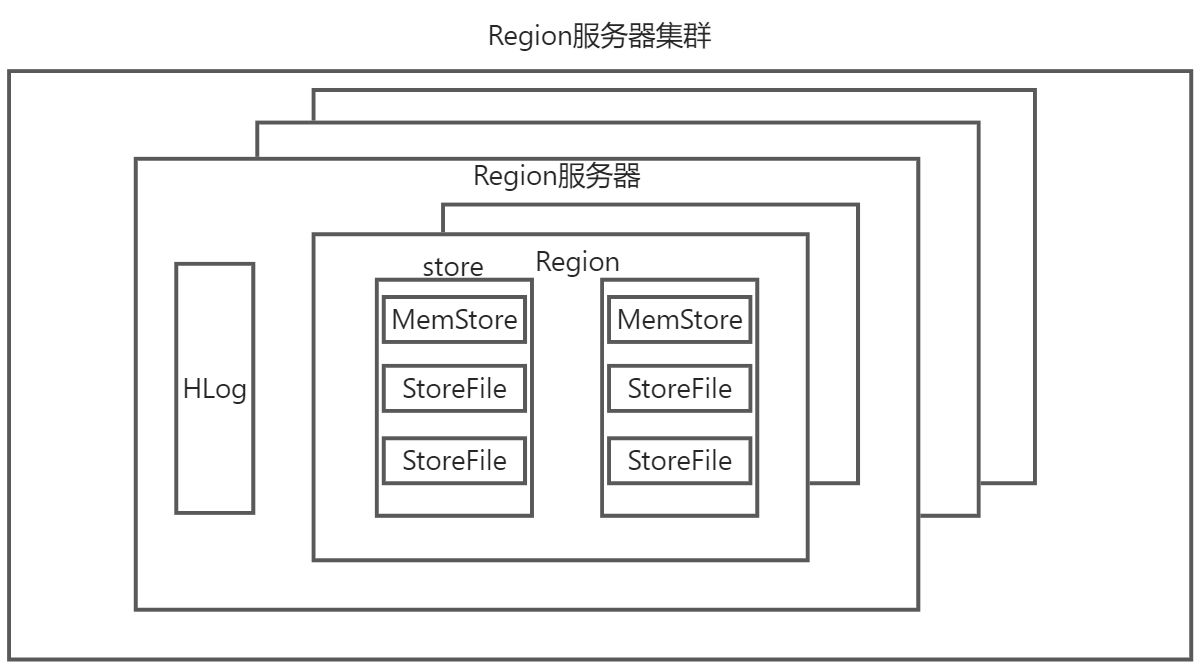
Region服务器内部管理了一系列Region和一个HLog,其中HLog是磁盘上的记录文件,记录着所有的更新操作,每个Region内有多个store,一个store对应着表的一个列族的存储,一个store包含一个Memstore和多个StoreFile,MemStore是内存中的缓存,保存最近更新的数据,StoreFile是磁盘中的文件。
这些文件都是B树结构,方便快速读取
读写数据
当用户写入数据时,会先写入HLog和MemStore中
用户读取数据时,先去MemStore缓存中查找,MemStore中没有再去查找StoreFile。
缓存的刷新
MemStore的容量是由限制的,系统会周期性的调用Region.flushcache()将MemStore缓存中的内容写入磁盘的StoreFile文件中,清空缓存,每清空一次缓存,都会在HLog中进行登记。每次缓存刷新都会生成一个新的StoreFile文件。
Region服务器有一个自己的HLog文件,服务器启动时,会先扫描HLog文件,检查在缓存刷新后是否有新的更新操作,如果有,则将更新内容写入MemStore,然后刷新缓存,写入StoreFile,最后删除旧的HLog文件,开始提供服务。
StoreFile的合并
由于一个Region中有多个StoreFile,当数目较多时,不利于用户的查找,因此当StoreFile的数量达到一定阈值时,系统调用Store.compact()把多个StoreFile合并为一个大文件。
StoreFile原理
当StoreFile合并越来越大时,就会触发文件分裂操作,同时当前的一个父Region会被分成两个子Region,父Region会下线,新分裂出的两个子Region被分配到两个Region服务器中。
HLog原理
Hlog是一种预写式日志(Write Ahead Log),用户更新数据必须首先被记入日志后才能写入MemStore缓存。这是由于当Region服务器故障时,MemStore缓存中的数据(还没有被写入磁盘)会全部丢失,因此采用HLog。
当服务器发生故障时,会将HLog按其所属的Region对象进行拆分,并随Region分配到新的Region服务器中,Region服务器会重新做一个遍日志中的操作,完成数据恢复。

若有收获,就点个赞吧
0 人点赞
