React 的组件更新过程
当某个 React 组件发生更新时(state 或者 props 发生改变),React 将会根据新的状态构建一棵新的 Virtual DOM 树,然后使用 diff 算法将这个 Virtual DOM 和 之前的 Virtual DOM 进行对比,如果不同则重新渲染
React 会在渲染之前会先调用 shouldComponentUpdate 这个函数检查是否需要重新渲染,该函数的默认返回值是 true,所以组件中的任何一个位置发生改变了,组件中其他不变的部分也会重新渲染
当一个组件渲染的结构很简单的时候,这种因为某个状态改变引起整个组件改变的影响可能不大,但是当组件渲染很复杂的时候,比如一个很多节点的树形组件,当更改某一个叶子节点的状态时,整个树形都会重新渲染,即使是那些状态没有更新的节点,这在某种程度上耗费了性能,导致整个组件的渲染和更新速度变慢,从而影响用户体验
PureComponent 的浅比较
基于上面提到的性能问题,所以 React 又推出了 PureComponent, 和它有类似功能的是 PureRenderMixin 插件,PureRenderMixin 插件实现了 shouldComponentUpdate 方法,该方法主要是执行了一次浅比较,代码如下:
function shallowCompare(instance, nextProps, nextState) {return (!shallowEqual(instance.props, nextProps) ||!shallowEqual(instance.state, nextState));}
PureComponent 判断是否需要更新的逻辑和 PureRenderMixin 插件一样,源码如下:
if (this._compositeType === CompositeTypes.PureClass) {shouldUpdate =!shallowEqual(prevProps, nextProps) ||!shallowEqual(inst.state, nextState);}
利用上述两种方法虽然可以避免没有改变的元素发生不必要的重新渲染,但是使用上面的这种浅比较还是会带来一些问题
问题
假如现在要将后台的传来的数据渲染成一个列表,数据如下:
[{'id':0,name:'xiaoming'},{'id':1,name:'lilei'},{'id':2,name:'hanmeimei'},]
这是一个很简单的操作,然后我们做了一个更新的功能,当我们将 id 为1的那条的姓名改成 ‘Miss Li’,并期望在改变之后组件可以重新渲染的时候,发现使用 PureComponent 组件并没有重新渲染,因为更改后的数据和修改前的数据使用的同一个内存,所以比较的结果永远都是 false,导致组件并没有重新渲染
那该怎样才能保证在 setState 后让该列表组件重新渲染?估计大家心里立刻有两个方案,一个是重新获取后台数据然后重新渲染,另一个是重新拷贝一份数据然后更改相应的地方后重新 set 给某个 State 完成重新渲染
但是我们可以看出,这两个操作最终的效果仍然是创建另一个与初始数组在内容上完全相同的数组,虽然相对繁琐但是着实有效。不过这两个方案各有缺点,比如第一个方案需要额外增加一次网络请求,第二个是万一数据量过于庞大就会造成内存的浪费
解决问题的几种方式
要解决上面这个问题,就要考虑怎么实现更新后的引用数据和原数据指向的内存不一致,也就是使用 Immutable 数据,有下面几种方法:
使用 lodash 的深拷贝
import _ from "lodash";const data = {list: [{name: 'aaa',sex: 'man'}, {name: 'bbb',sex: 'woman'}],status: true,}const newData = _.cloneDeepWith(data);shallowEqual(data, newData) //false//更改其中的某个字段再比较newData.list[0].name = 'ccc';shallowEqual(data.list, newData.list) //false
这种方式就是先深拷贝复杂类型,然后更改其中的某项值,这样两者使用的是不同的引用地址,自然在比较的时候返回的就是 false,但是有一个缺点是这种深拷贝的实现会耗费很多内存
使用 JSON.stringify()
const data = {list: [{name: 'aaa',sex: 'man'}, {name: 'bbb',sex: 'woman'}],status: true,c: function(){console.log('aaa')}}const newData = JSON.parse(JSON.stringify(data))shallowEqual(data, newData) //false//更改其中的某个字段再比较newData.list[0].name = 'ccc';shallowEqual(data.list, newData.list) //false
这种方式其实就是深拷贝的一种变种形式,它的缺点除了和上面那种一样之外,还有两点就是如果你的对象里有函数,函数无法被拷贝下来,同时也无法拷贝 copyObj 对象原型链上的属性和方法
使用 Object 解构
const data = {list: [{name: 'aaa',sex: 'man'}, {name: 'bbb',sex: 'woman'}],status: true,}const newData = {...data};console.log(shallowEqual(data, newData)); //falseconsole.log(shallowEqual(data, newData)); //true//添加一个字段newData.status = false;console.log(shallowEqual(data, newData)); //false//修改复杂类型的某个字段newData.list[0].name = 'abbb';console.log(shallowEqual(data, newData)); //true
通过上面的测试可以发现:当修改数据中的简单类型的变量的时候,使用解构是可以解决问题的,但是当修改其中的复杂类型的时候就不能检测到
因为解构在经过 babel 编译后是 Object.assign(),但它是一个浅拷贝,用图来表示如下:
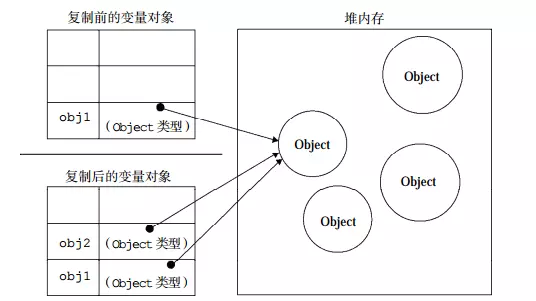
所以这种方式的缺点显而易见,对于复杂类型的数据无法检测到其更新
使用第三方库
immutability-helper
一个基于 Array 和 Object 操作的库,就一个文件但是使用起来很方便,例如上面的例子就可以写成下面这种
import update from 'immutability-helper';const data = {list: [{name: 'aaa',sex: 'man'}, {name: 'bbb',sex: 'woman'}],status: true,}const newData = update(data, { list: { 0: { name: { $set: "bbb" } } } });console.log(this.shallowEqual(data, newData)); //false//当只发生如下改变时const newData = update(data,{status:{$set: false}});console.log(this.shallowEqual(data, newData)); //falseconsole.log(this.shallowEqual(data.list, newData.list)); //true
同时可以发现当只改变 data 中的 status 字段时,比较前后两者的引用字段,发现是共享内存的,这在一定程度上节省了内存的消耗,而且 API 都是熟知的一些对 Array 和 Object 操作,比较容易上手
immutable
相比于 immutability-helper, immutable 则要强大许多,但是与此同时,也增加了学习的成本,因为需要学习新的 API,具体知识点可参考这里
immutability-helper-x
API更好用,可以将
const newData = update(data, { list: { 0: { name: { $set: "bbb" } } } });
简化为可读性更强的
const newData = update.$set(data, 'list.0.name', "bbb");或者const newData = update.$set(data, ['list', '0', 'name'], "bbb");

若有收获,就点个赞吧
0 人点赞
