集合体系:
一、list集合
2.list常用的三个子类的区别:
ArrayList:
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。
Vector:
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。
Vector相对ArrayList查询慢(线程安全的)
Vector相对LinkedList增删慢(数组结构)
LinkedList:
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
底层存储原理:数组与链表的区别:
1.ArrayList是基于数组实现的,所以查找速度快: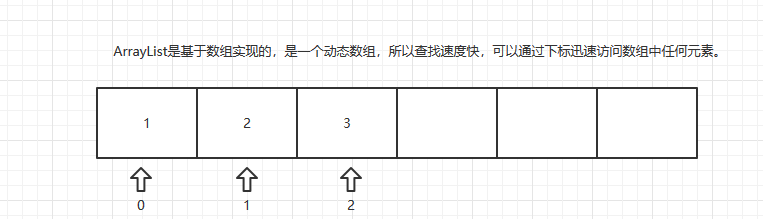
增加删除慢的原因:
1.插入或删除元素: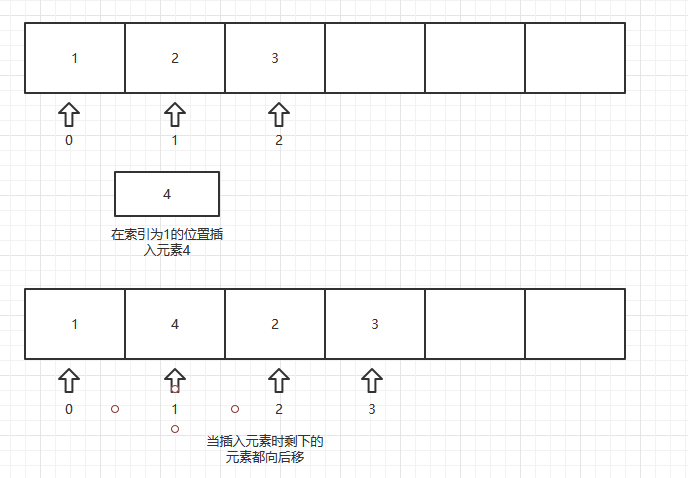
2.LinkedList 底层数据结构是链表
优点:删除和添加元素的效率比较高
缺点:数据结构复杂 分为单向链表和双向链表
删除和添加元素的效率比较高的原因:
以单向链表为例;
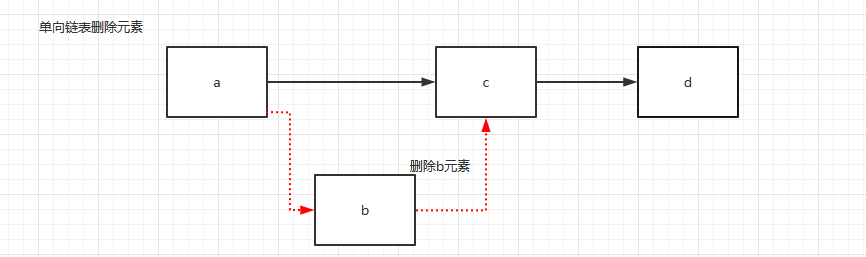
ArrayList数组和LinkedList 链表:
数组查询快的原因:数组简单易用,使用的是连续的内存空间,可以借助CPU的缓存机制,预读数组中的数据,所以访问的下效率更高。而链表在内存中并不是连续存储的,所以对CPU缓存不友好,没办法预读。
对于数组来说,存储空间是连续的,所以在加载某个下标的时候可以把以后的几个下标元素也加载到 CPU 缓存这样执行速度会快于存储空间不连续的链表存储。
CPU 在从内存读取数据的时候,会先把读取到的数据加载到 CPU 的缓存中。而 CPU 每次从内存读取数据并不是只读取那个特定要访问的地址,而是读取一个数据块,并保存到 CPU 缓存中,然后下次访问内存数据的时候就会先从 CPU 缓存开始查找,如果找到就不需要再从内存中取。这样就实现了比内存访问速度更快的机制,也就是 CPU 缓存存在的意义 : 为了弥补内存访问速度过慢与 CPU 执行速度快之间的差异而引入。
数组的遍历:
增强for 和 普通for 的区别:
增强for 实现原理类似迭代器,通过移动指针来实现遍历
普通for是通过索引来实现遍历
增强for遍历 在遍历同时删除元素会报异常,普通for不会 但是集合大小变了
3.Vector
Vector是线程安全的,vector中大部分方法增加了Sychronized关键字修饰;
Vector实现了一个可以自动增长的对象数组,类似于动态数组,能够调整自身的大小,能够根据索引进行查询;
Vector实现了RnadomAccess接口,因此能够队数据进行随机访问。
二、set集合
set集合存放不可重复的、无序的元素;
通过元素的equals方法,来判断是否为重复元素。
1.HashSet
HashSet实现Set接口,由哈希表支持。不保证Set的迭代顺序,该类允许使用null元素。
HashSet中存储的元素不能重复,且是无序的;HashSet是线程不安全的,存储速度快。
HashSet如何保证元素的唯一性:
是通过对象的HashCode和equals方法来保证对象的唯一性的。
由于底层判断依赖于equals和hashCode方法,故所存取的元素需要重写这两个方法,以按照我们的期待存取元素。保证元素唯一性。
equals:比较的是两个对象的内存地址值和值
hashCode:比较的是两个对象在hash表中的位置;对象的内存地址通过hash函数算法得到hashcode
1.equal()相等的两个对象他们的hashCode()肯定相等,也就是用equal()对比是绝对可靠的。
2.hashCode()相等的两个对象他们的equal()不一定相等。
HashCode的存在主要是为了查找的快捷性
每当需要对比两个对象是否相等的时候,首先用hashCode()去对比,如果hashCode()不一样,则表示这两个对象肯定不相等(也就不必再用equal()去对比了),如果hashCode()相同,此时再对比他们的equals(),如果equals()也相同,则表示这两个对象是真的相同了,这样既能大大提高了效率也保证了对比的绝对正确性!
HashSet集合的数据结构:
jdk1.8之前:数组+链表
jdk1.8之后:数组+链表
数组+红黑树
2.LinkedHashSet
LinkedHashSet继承自HashSet(保证元素唯一的,与HashSet的原理一样),源码更少、更简单,唯一的区别是LinkedHashSet内部使用的是LinkHashMap。这样做的意义或者好处就是LinkedHashSet中的元素顺序是可以保证的,也就是说遍历序和插入序是一致的(能保证怎么存就怎么取的集合对象)。
3.Collections和Collection的区别:
Collections是一个帮助类。它包含有各种有关集合操作的静态多态方法。此类不能实例化,用于对集合中元素进行排序、搜索以及线程安全等各种操作,服务于Java的Collection框架。
Collection是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式,其直接继承接口有List与Set。
3.TreeSet
TreeSet是一个有序的集合,他的作用是提供有序的Set集合。
TreeSet底层是二叉树,可以对对象元素进行排序,但是自定义类需要实现comparable接口,重写comparaTo() 方法。
TreeSet是非线程安全的。
三、Map 集合
Map是一种键值对集合(key-value),Map集合中的每一个元素都包含一个键值对象和一个值对象。键对象不可以重复,值对象可以重复。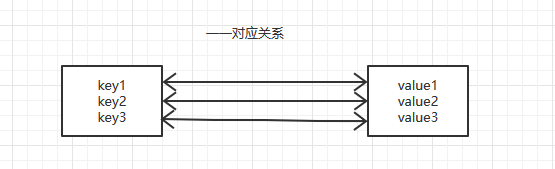
Map接口主要又两个实现类;HashMap类和TreeMap类。HashMap类是按哈希算法来存储键对象的,TreeMap类可以对键对象进行排序。
1.HashMap
HashMap 是由数组+链表或者数组+红黑树组成。HashMap中链表越少,性能越好。
HashMap 是一种基于key-value得数据结构:
1.1关键点:
1.1.1基于Map接口
1.1.2允许key和value都允许为null;
1.1.3HashMap是线程非同步的,想要线程同步的HashMap可以用HashTable或ConcurrentHashMap。
1.1.4不保证顺序和插入时顺序相同。
1.2HashMap的扩容因子为0.75的原因(负载因子的作用是节省时间和空间):
负载因子过大,虽然空间利用率上去了,但是时间效率降低了(这样会出现大量的Hash的冲突,底层的红黑树变得异常复杂。对于查询效率极其不利。这种情况就是牺牲了时间来保证空间的利用率。)。
负载因子太小,虽然时间效率提升了,但是空间利用率降低了(填充的元素减少了,Hash冲突也会减少,底层的链表长度或者是红黑树的高度就会降低。查询效率就会增加,空间的利用率就会大大的降低)。

若有收获,就点个赞吧
0 人点赞
