Overall architecture
下面这张图的做法其实就是三个网络,层数递减,输入的分辨率也递减。最后的结果再concat到一起,过一层吧。然后看结果。中间没有任何的交织

What happen?
- 怎么对不同的数据都切成patch,然后最后还要组合在一起,然后concat其他俩网络的feature
a. 每次只输入一个数据,保证分块后的patch最后经过各种操作后还可以组合在一起
对于这个问题,研究了monai slide_window_inference
fall_back_tuple() Typically used whenuser_providedis a tuple of window size provided by the user,defaultis defined by data, this function returns an updateduser_providedwith its non-positive
components replaced by the corresponding components fromdefault.
dense_patch_slice() Store all slices in list, return all the slice(0:x) in 3 dimension.
unravel_slice 就是类似返回当前sw_batch_size个索引,每个索引第一部分是在当前的batch中的位置,第二个None(channel),第三四五就是对应的维度切片。
importance_map默认是全为1,计算过的位置就会加一个map - 现在的一个新问题是,按照monai unet最后输出的是一个2通道的,那么最后咋把三个结果concat呢?
a. monai UNet通道数最少得有(a, b) - 数据输入设想,是每个数据都crop成(512, 512, 128)大小的数据。这样最浅层的网络只会降采样一次(按照monai UNet的设计,bottom层不会有降低和提高分辨率的操作)
- monai UNet网络结构的设计,所有的block都是会过两次卷积。
a. encoder部分,就先经过步长为2的卷积,下采样,同时还会两倍通道数。然后再经过步长为1的卷积正常操作,这里也不改变通道的数量。
b. decoder部分(这里和下图里的不太一样)是先concat然后再ConvTranse, 之后再正常卷积。
c. 因为原文是第一次不降采样之后每次输入block之前都会降采样。这里是最后一个block不降采样,前面每次都降采样。 - S层(16, 32) M层(16, 32, 64) L层(16, 32, 64, 128, 256)
- 看一下别的模型怎么解决多输入这个问题的。
a. 还没看,但是用自己的方法解决了。还是可以看看别的方法 - 多监督,把其余几个网络的结果进行深监督,然后最后一层赋予更大的权重(jiadong)
a. 目前的效果不好 - 当前的验证集效果波动非常大,How to solve this
a. coslr,确实写了,尝试降低下限试试
b. 数据shuffle一下,训练的时候确实是shuffle了
c. batch_size 太小了,用gn来解决
d. 关于patch_size 必须是2的幂这件事
e. 增加BCE+DiceLoss
zx’ words:- 用group normalization z所有的都用gn, 除了最后的聚合层
- 最下层concat一下
- 第三个维度强行resize成一个统一大小,把有label的地方crop出来再resize(确定crop是不是出了问题)
Results part
1. number of parameters
| Model | parameters | |
|---|---|---|
| UNet( | 4.8M | |
| VNet(Standard) | 45.6 M | |
| TripleUNet(2,3,5) | 5.1M | |
2. The experiments result record
1. UNet
| id | max epoch | best val dice(epoch) | test dice | source |
|---|---|---|---|---|
| 1 | 500 | 0.8284(312) | 0.8255 | . |
| 2 | with stable lr | 0.6917 |
roi_size = (256, 256, 64) # window size of validationsw_batch_size = 4 # the batch size to run window slicesval_num = 30data = PulVessel_lightning(in_dir, batch_size=1, num_workers=4, val_num=val_num,cache=True, cache_rate=1, predict_num=1)max_epochs=500,self._model = UNet(spatial_dims=3,in_channels=1,out_channels=2,channels=(16, 32, 64, 128, 256),strides=(2, 2, 2, 2),num_res_units=2,norm=Norm.BATCH,)self.loss_function = DiceLoss(to_onehot_y=True, sigmoid=True, squared_pred=False, include_background=False)self.post_pred = AsDiscrete(argmax=True, to_onehot=2)self.post_label = AsDiscrete(to_onehot=2)self.dice_metric = DiceMetric(include_background=False, reduction="mean", get_not_nans=False)def configure_optimizers(self):optimizer = torch.optim.Adam(self._model.parameters(), 0.0001)lr_scheduler = CosineAnnealingLR(optimizer, eta_min=0.0001/100, T_max=500,last_epoch=-1, verbose=True)return [optimizer], [lr_scheduler]self.train_transforms = Compose([LoadImaged(keys=["vol", "seg"]),EnsureChannelFirstd(keys=["vol", "seg"]),ScaleIntensityRanged(keys=['vol'], a_min=-900.0, a_max=200,b_min=0, b_max=1, clip=True),# RandSpatialCropd(keys=["vol", "seg"], roi_size=(1000, 1000, 48), random_size=False),RandCropByPosNegLabeld(keys=["vol", "seg"], label_key='seg', spatial_size=[256, 256, 64], pos=1,neg=1, num_samples=1),RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=1),RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=2),ToTensord(keys=["vol", "seg"]),])self.val_transforms = Compose([LoadImaged(keys=["vol", "seg"]),EnsureChannelFirstd(keys=["vol", "seg"]),ScaleIntensityRanged(keys=['vol'], a_min=-900.0, a_max=200,b_min=0, b_max=1, clip=True),# RandSpatialCropd(keys=["vol", "seg"], roi_size=(1000, 1000, 48), random_size=False),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=1),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=2),ToTensord(keys=["vol", "seg"]),])self.test_transforms = Compose([LoadImaged(keys=["vol", "seg"]),EnsureChannelFirstd(keys=["vol", "seg"]),ScaleIntensityRanged(keys=['vol'], a_min=-900.0, a_max=200,b_min=0, b_max=1, clip=True),# RandSpatialCropd(keys=["vol", "seg"], roi_size=(1000, 1000, 48), random_size=False),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=1),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=2),ToTensord(keys=["vol", "seg"]),])Acurrent epoch: 499 current mean dice: 0.8048best mean dice: 0.8284 at epoch: 312test:The mean prediction loss is 0.17454605525539768 The best performance is 0.1278761625289917the event folder:/hpc/data/home/bme/liujy3/code/PulVessel_Lightning/UNet/logs/default/version_0
2. VNet
| id | max epoch | best val dice(epoch) | test dice | source |
|---|---|---|---|---|
| 1 | 500 | 0.8027(294) | 0.78 | VNet1 |
self._model = VNet(spatial_dims=3,in_channels=1,out_channels=2,) # standard VNetself.loss_function = DiceLoss(to_onehot_y=True, sigmoid=True, squared_pred=False, include_background=False)self.post_pred = AsDiscrete(argmax=True, to_onehot=2)self.post_label = AsDiscrete(to_onehot=2)self.dice_metric = DiceMetric(include_background=False, reduction="mean", get_not_nans=False)def configure_optimizers(self):optimizer = torch.optim.Adam(self._model.parameters(), 0.0001)lr_scheduler = CosineAnnealingLR(optimizer, eta_min=0.0001/100, T_max=500,last_epoch=-1, verbose=True)return [optimizer], [lr_scheduler]roi_size = (256, 256, 64) # window size of validationsw_batch_size = 4val_num = 30data = PulVessel_lightning(in_dir, batch_size=1, num_workers=4, val_num=val_num,cache=True, cache_rate=1, predict_num=1) # for bme clusterself.train_transforms = Compose([LoadImaged(keys=["vol", "seg"]),EnsureChannelFirstd(keys=["vol", "seg"]),ScaleIntensityRanged(keys=['vol'], a_min=-900.0, a_max=200,b_min=0, b_max=1, clip=True),# RandSpatialCropd(keys=["vol", "seg"], roi_size=(1000, 1000, 48), random_size=False),RandCropByPosNegLabeld(keys=["vol", "seg"], label_key='seg', spatial_size=[256, 256, 64], pos=1,neg=1, num_samples=1),RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=1),RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=2),ToTensord(keys=["vol", "seg"]),])self.val_transforms = Compose([LoadImaged(keys=["vol", "seg"]),EnsureChannelFirstd(keys=["vol", "seg"]),ScaleIntensityRanged(keys=['vol'], a_min=-900.0, a_max=200,b_min=0, b_max=1, clip=True),# RandSpatialCropd(keys=["vol", "seg"], roi_size=(1000, 1000, 48), random_size=False),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=1),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=2),ToTensord(keys=["vol", "seg"]),])self.test_transforms = Compose([LoadImaged(keys=["vol", "seg"]),EnsureChannelFirstd(keys=["vol", "seg"]),ScaleIntensityRanged(keys=['vol'], a_min=-900.0, a_max=200,b_min=0, b_max=1, clip=True),# RandSpatialCropd(keys=["vol", "seg"], roi_size=(1000, 1000, 48), random_size=False),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=1),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=2),ToTensord(keys=["vol", "seg"]),])Best loss is 0.2252 at epoch 294dice:0.8027test: The mean prediction loss is 0.22441603291419246 The best performance is 0.15201616287231445the event floder:/hpc/data/home/bme/liujy3/code/PulVessel_Lightning/VNet/logs/default/version_6
3. TripleUNet( sdata->lpath, ldata->spath)
| id | max epoch | best val dice(epoch) | test dice | source |
|---|---|---|---|---|
| 1 | 350 | 0.5070(284) | 0.57 | TripleU |
| 2 | 293 | 0.6308(272) | 0.63(0.72best) |
```python roi_size = (-1, -1, 64) # window size of validation sw_batch_size = 4 # the batch size to run window slices val_num = 30 # the number of the validation data
data = PulVessel_lightning(in_dir, batch_size=1, num_workers=4, val_num=val_num, cache=True, cache_rate=1, predict_num=1) # for hp # for bme clust
model
self._modelS = UNet( spatial_dims=3, in_channels=1, out_channels=2, channels=(16, 32), strides=(2,), num_res_units=2, norm=Norm.BATCH, ) self._modelM = UNet( spatial_dims=3, in_channels=1, out_channels=2, channels=(16, 32, 64), strides=(2, 2,), num_res_units=2, norm=Norm.BATCH, ) self._modelL = UNet( spatial_dims=3, in_channels=1, out_channels=2, channels=(16, 32, 64, 128, 256), strides=(2, 2, 2, 2), num_res_units=2, norm=Norm.BATCH, ) self.final_layer = Convolution( spatial_dims=3, in_channels=6, out_channels=2, strides=1, kernel_size=3, act=Act.PRELU, norm=Norm.BATCH, dropout=0.0, bias=True, conv_only=True, is_transposed=True, )
data
output_s = self._modelS(x) output_m = fake_slide_window(x, 1 / 2, self.sw_batch_size, self._modelM) output_l = fake_slide_window(x, 1 / 4, self.sw_batch_size, self._modelL)
self.train_transforms = Compose( [ LoadImaged(keys=[“vol”, “seg”]), EnsureChannelFirstd(keys=[“vol”, “seg”]), ScaleIntensityRanged(keys=[‘vol’], a_min=-900.0, a_max=200, b_min=0, b_max=1, clip=True), RandSpatialCropd(keys=[“vol”, “seg”], roi_size=(512, 512, 128), random_size=False),
# RandCropByPosNegLabeld(keys=["vol", "seg"], label_key='seg', spatial_size=[512, 512, 128], pos=1,# neg=1, num_samples=4),RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=1),RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=2),ToTensord(keys=["vol", "seg"]),])
self.val_transforms = Compose( [ LoadImaged(keys=[“vol”, “seg”]), EnsureChannelFirstd(keys=[“vol”, “seg”]), ScaleIntensityRanged(keys=[‘vol’], a_min=-900.0, a_max=200, b_min=0, b_max=1, clip=True),
# RandSpatialCropd(keys=["vol", "seg"], roi_size=(1000, 1000, 48), random_size=False),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=1),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=2),ToTensord(keys=["vol", "seg"]),]
)
self.test_transforms = Compose( [ LoadImaged(keys=[“vol”, “seg”]), EnsureChannelFirstd(keys=[“vol”, “seg”]), ScaleIntensityRanged(keys=[‘vol’], a_min=-900.0, a_max=200, b_min=0, b_max=1, clip=True),
# RandSpatialCropd(keys=["vol", "seg"], roi_size=(1000, 1000, 48), random_size=False),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=1),# RandFlipd(keys=["vol", "seg"], prob=0.5, spatial_axis=2),ToTensord(keys=["vol", "seg"]),]
)
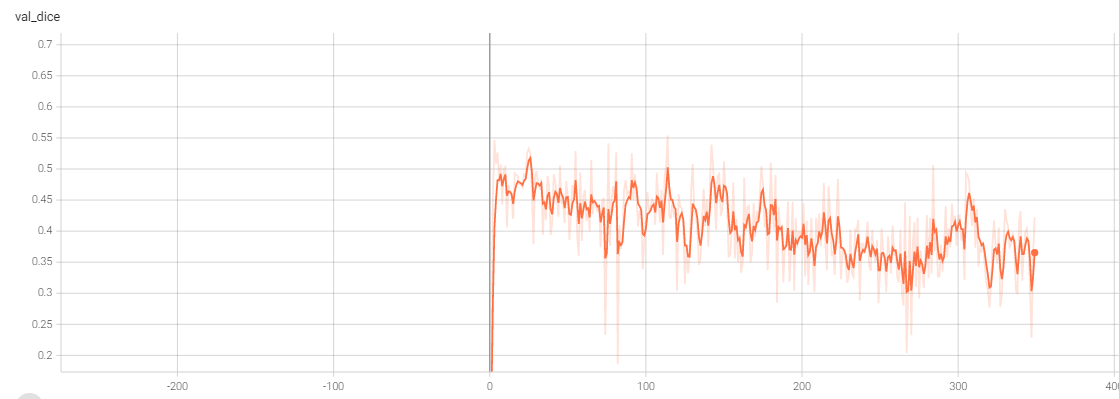2. 加入了多监督。loss =0.4* loss_t +0.2* loss_l +0.2* loss_m +0.2* loss_sdir:/hpc/data/home/bme/liujy3/code/TripNewUnet/TripleTest/logs/default/version2(and version1)<br />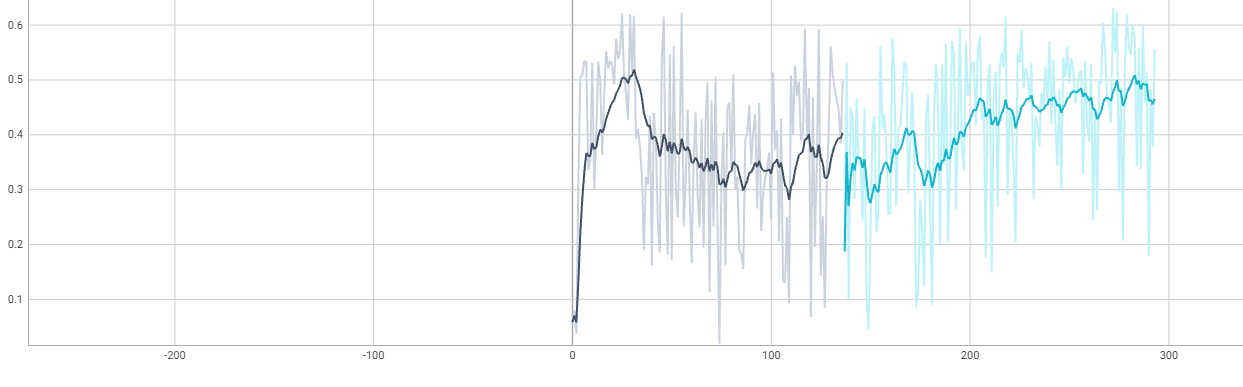<a name="dILOG"></a>### 4. TripleUNet| id | max epoch | best val dice(epoch) | test dice | source || --- | --- | --- | --- | --- || 1 | 263 | 0.8639(216) | 0.8528 | [TripleU](https://www.yuque.com/tuoyu-hy28g/gar920/clgl92?inner=ASMqk) || 2 | 237 | 0.8678(184) | 0.8513 | || 3 | | 0.8572(245) | | || 4 | | 0.8679(216) | | |1.```pythons_channel=(16, 32),m_channel=(16, 32, 64),l_channel=(16, 32, 64, 128, 256),kernel_size: Union[Sequence[int], int] = 3,up_kernel_size: Union[Sequence[int], int] = 3,num_res_units: int = 2,#model# s_networkself.down_s_1 = self._get_down_layer(1, self.s_channel[0], 2, norm=(Norm.GROUP, {'num_groups': 4}))self.bottom_s = self._get_bottom_layer(self.s_channel[0], self.s_channel[1], norm=(Norm.GROUP, {'num_groups': 8}))self.up_s_1 = self._get_up_layer(self.s_channel[0] + self.s_channel[1], 2, 2, norm=(Norm.GROUP, {'num_groups': 1}),is_top=True)# m_networkself.down_m_1 = self._get_down_layer(1, self.m_channel[0], 2, norm=(Norm.GROUP, {'num_groups': 4})) # 1 -> 16self.down_m_2 = self._get_down_layer(self.m_channel[0], self.m_channel[1], 2,norm=(Norm.GROUP, {'num_groups': 8})) # 16 -> 32self.bottom_m = self._get_bottom_layer(self.m_channel[1], self.m_channel[2],norm=(Norm.GROUP, {'num_groups': 16})) # 32 -> 64self.up_m_1 = self._get_up_layer(self.m_channel[1] + self.m_channel[2], self.m_channel[0], 2,norm=(Norm.GROUP, {'num_groups': 8})) # 32+64 -> 16self.up_m_2 = self._get_up_layer(self.m_channel[0] * 2, 2, 2, norm=(Norm.GROUP, {'num_groups': 1}),is_top=True) # 16+16 -> 2# l_networkself.down_l_1 = self._get_down_layer(1, self.l_channel[0], 2, norm=(Norm.GROUP, {'num_groups': 4})) # 1 -> 16self.down_l_2 = self._get_down_layer(self.l_channel[0], self.l_channel[1], 2,norm=(Norm.GROUP, {'num_groups': 8})) # 16 -> 32self.down_l_3 = self._get_down_layer(self.l_channel[1], self.l_channel[2], 2,norm=(Norm.GROUP, {'num_groups': 16})) # 32 -> 64self.down_l_4 = self._get_down_layer(self.l_channel[2], self.l_channel[3], 2,norm=(Norm.GROUP, {'num_groups': 32})) # 64-128self.bottom_l = self._get_bottom_layer(self.l_channel[3], self.l_channel[4],norm=(Norm.GROUP, {'num_groups': 32})) # 128-256self.up_l_1 = self._get_up_layer(self.l_channel[3] + self.l_channel[4], self.l_channel[2], 2,norm=(Norm.GROUP, {'num_groups': 16})) # 256+128 - 64self.up_l_2 = self._get_up_layer(self.l_channel[2] * 2, self.l_channel[1], 2,norm=(Norm.GROUP, {'num_groups': 8})) # 64+64 - 32self.up_l_3 = self._get_up_layer(self.l_channel[1] * 2, self.l_channel[0], 2,norm=(Norm.GROUP, {'num_groups': 4})) # 32+32 - 16self.up_l_4 = self._get_up_layer(self.l_channel[0] * 2, 2, 2, norm=(Norm.GROUP, {'num_groups': 1}),is_top=True) # 16+16 - 2self.final_layer = Convolution(spatial_dims=3,in_channels=6,out_channels=2,strides=1,kernel_size=3,act=Act.PRELU,norm=Norm.INSTANCE,dropout=0.0,bias=True,conv_only=True,is_transposed=True,)
loss =0.4 loss_t +0.2 loss_l +0.2 loss_m +0.2 loss_s
其余跟之前一样,就是加了GN,效果好了很多。下一个实验:证明GN的作用,再在新代码上用BN试试。
/hpc/data/home/bme/liujy3/code/mTU/mTU1/logs/default/version_0
2.
将1中的normalization改为了BN,测试看是不是GN的效果提升,但是并不是,效果仍然和上面一样好。现在就是在找原因。
3.
现在为了找出是不是fake slide window 里面每次的batchsize为1的问题,我已经改过一次了。但是效果仍然一样。
将自己写的网络实例化,然后传入fake slide window,但是效果一样
import torchimport torch.nn as nnfrom typing import Any, Sequence, Tuple, Union, Optionalfrom monai.inferers.utils import _get_scan_intervalfrom monai.data.utils import dense_patch_slices, compute_importance_map, get_valid_patch_sizefrom monai.utils import BlendModefrom monai.data.utils import dense_patch_slicesfrom monai.networks.blocks.convolutions import Convolution, ResidualUnitfrom monai.networks.layers.factories import Act, Normclass mTriUNet(torch.nn.Module):def __init__(self,spatial_dims: int = 3,s_channel=(16, 32),m_channel=(16, 32, 64),l_channel=(16, 32, 64, 128, 256),kernel_size: Union[Sequence[int], int] = 3,up_kernel_size: Union[Sequence[int], int] = 3,num_res_units: int = 2,act: Union[Tuple, str] = Act.PRELU,norm: Union[Tuple, str] = Norm.BATCH,dropout: float = 0.0,bias: bool = True,dimensions: Optional[int] = None,):super().__init__()self.dimensions = spatial_dimsself.kernel_size = kernel_sizeself.up_kernel_size = up_kernel_sizeself.num_res_units = num_res_unitsself.act = actself.norm = normself.dropout = dropoutself.bias = biasself.s_channel = s_channelself.m_channel = m_channelself.l_channel = l_channel# s_networkself.down_s_1 = self._get_down_layer(1, self.s_channel[0], 2, norm=self.norm)self.bottom_s = self._get_bottom_layer(self.s_channel[0], self.s_channel[1], norm=self.norm)self.up_s_1 = self._get_up_layer(self.s_channel[0] + self.s_channel[1], 2, 2, norm=self.norm,is_top=True)# m_networkself.down_m_1 = self._get_down_layer(1, self.m_channel[0], 2, norm=self.norm) # 1 -> 16self.down_m_2 = self._get_down_layer(self.m_channel[0], self.m_channel[1], 2,norm=self.norm) # 16 -> 32self.bottom_m = self._get_bottom_layer(self.m_channel[1], self.m_channel[2],norm=self.norm) # 32 -> 64self.up_m_1 = self._get_up_layer(self.m_channel[1] + self.m_channel[2], self.m_channel[0], 2,norm=self.norm) # 32+64 -> 16self.up_m_2 = self._get_up_layer(self.m_channel[0] * 2, 2, 2, norm=self.norm,is_top=True) # 16+16 -> 2# l_networkself.down_l_1 = self._get_down_layer(1, self.l_channel[0], 2, norm=self.norm) # 1 -> 16self.down_l_2 = self._get_down_layer(self.l_channel[0], self.l_channel[1], 2,norm=self.norm) # 16 -> 32self.down_l_3 = self._get_down_layer(self.l_channel[1], self.l_channel[2], 2,norm=self.norm) # 32 -> 64self.down_l_4 = self._get_down_layer(self.l_channel[2], self.l_channel[3], 2,norm=self.norm) # 64-128self.bottom_l = self._get_bottom_layer(self.l_channel[3], self.l_channel[4],norm=self.norm) # 128-256self.up_l_1 = self._get_up_layer(self.l_channel[3] + self.l_channel[4], self.l_channel[2], 2,norm=self.norm) # 256+128 - 64self.up_l_2 = self._get_up_layer(self.l_channel[2] * 2, self.l_channel[1], 2,norm=self.norm) # 64+64 - 32self.up_l_3 = self._get_up_layer(self.l_channel[1] * 2, self.l_channel[0], 2,norm=self.norm) # 32+32 - 16self.up_l_4 = self._get_up_layer(self.l_channel[0] * 2, 2, 2, norm=self.norm,is_top=True) # 16+16 - 2self.final_layer = Convolution(spatial_dims=3,in_channels=6,out_channels=2,strides=1,kernel_size=3,act=Act.PRELU,norm=Norm.INSTANCE,dropout=0.0,bias=True,conv_only=True,is_transposed=True,)def _get_down_layer(self,in_channels: int,out_channels: int,strides: int,norm: Union[Tuple, str] = Norm.INSTANCE,is_top=False) -> nn.Module:"""Args:in_channels: number of input channels.out_channels: number of output channels.strides: convolution stride.is_top: True if this is the top block."""mod: nn.Moduleif self.num_res_units > 0:mod = ResidualUnit(self.dimensions,in_channels,out_channels,strides=strides,kernel_size=self.kernel_size,subunits=self.num_res_units,act=self.act,norm=norm,dropout=self.dropout,bias=self.bias,)return modmod = Convolution(self.dimensions,in_channels,out_channels,strides=strides,kernel_size=self.kernel_size,act=self.act,norm=norm,dropout=self.dropout,bias=self.bias,)return moddef _get_bottom_layer(self,in_channels: int,out_channels: int,norm: Union[Tuple, str] = Norm.INSTANCE) -> nn.Module:"""Args:in_channels: number of input channels.out_channels: number of output channels."""return self._get_down_layer(in_channels, out_channels, 1, norm, False)def _get_up_layer(self,in_channels: int,out_channels: int,strides: int,norm: Union[Tuple, str] = Norm.INSTANCE,is_top: bool = False) -> nn.Module:"""Args:in_channels: number of input channels.out_channels: number of output channels.strides: convolution stride.is_top: True if this is the top block."""conv: Union[Convolution, nn.Sequential]conv = Convolution(self.dimensions,in_channels,out_channels,strides=strides,kernel_size=self.up_kernel_size,act=self.act,norm=norm,dropout=self.dropout,bias=self.bias,conv_only=is_top and self.num_res_units == 0,is_transposed=True,)if self.num_res_units > 0:ru = ResidualUnit(self.dimensions,out_channels,out_channels,strides=1,kernel_size=self.kernel_size,subunits=1,act=self.act,norm=norm,dropout=self.dropout,bias=self.bias,last_conv_only=is_top,)conv = nn.Sequential(conv, ru)return convdef fake_slide_window(self,inputs: torch.Tensor,ratio,sw_batch_size: int,mode: Union[BlendMode, str] = BlendMode.CONSTANT,sigma_scale: Union[Sequence[float], float] = 0.125,device: Union[torch.device, str, None] = None,sw_device: Union[torch.device, str, None] = None,*args: Any,**kwargs: Any,) -> torch.Tensor:num_spatial_dims = len(inputs.shape) - 2if device is None:device = inputs.deviceif sw_device is None:sw_device = inputs.deviceimage_size = list(inputs.shape[2:])batch_size = inputs.shape[0]roi_size = []for i in image_size:i = i * ratioroi_size.append(int(i))# =0?overlap = 0scan_interval = _get_scan_interval(image_size, roi_size, num_spatial_dims, overlap)# Store all slices in listslices = dense_patch_slices(image_size, roi_size, scan_interval)num_win = len(slices) # number of windows per imagetotal_slices = num_win * batch_size # total number of windows# Create window-level importance mapimportance_map = compute_importance_map(get_valid_patch_size(image_size, roi_size), mode=mode, sigma_scale=sigma_scale, device=device)# Perform predictionsoutput_image, count_map = torch.tensor(0.0, device=device), torch.tensor(0.0, device=device)_initialized = Falsefor slice_g in range(0, total_slices, sw_batch_size):slice_range = range(slice_g, min(slice_g + sw_batch_size, total_slices))unravel_slice = [[slice(int(idx / num_win), int(idx / num_win) + 1), slice(None)] + list(slices[idx % num_win])for idx in slice_range]window_data = torch.cat([inputs[win_slice] for win_slice in unravel_slice]).to(sw_device)if ratio == 1/2:seg_prob = self.m_network(window_data).to(device) # batched patch segmentationelif ratio == 1/4:seg_prob = self.s_network(window_data).to(device)if not _initialized: # init. buffer at the first iterationoutput_classes = seg_prob.shape[1]output_shape = [batch_size, output_classes] + list(image_size)# allocate memory to store the full output and the count for overlapping partsoutput_image = torch.zeros(output_shape, dtype=torch.float32, device=device)count_map = torch.zeros(output_shape, dtype=torch.float32, device=device)_initialized = True# store the result in the proper location of the full output. Apply weights from importance map.for idx, original_idx in zip(slice_range, unravel_slice):output_image[original_idx] += importance_map * seg_prob[idx - slice_g]count_map[original_idx] += importance_map# account for any overlapping sectionsoutput_image = output_image / count_mapreturn output_imagedef s_network(self, x_s):down_out_s_1 = self.down_s_1(x_s)bottom_out_s = self.bottom_s(down_out_s_1)up_out_s_1 = self.up_s_1(torch.cat([down_out_s_1, bottom_out_s], dim=1))return up_out_s_1def m_network(self, x_m):down_out_m_1 = self.down_m_1(x_m)down_out_m_2 = self.down_m_2(down_out_m_1)bottom_out_m = self.bottom_m(down_out_m_2)up_out_m_1 = self.up_m_1(torch.cat([down_out_m_2, bottom_out_m], dim=1))up_out_m_2 = self.up_m_2(torch.cat([down_out_m_1, up_out_m_1], dim=1))return up_out_m_2def l_network(self, x_l):down_out_l_1 = self.down_l_1(x_l)down_out_l_2 = self.down_l_2(down_out_l_1)down_out_l_3 = self.down_l_3(down_out_l_2)down_out_l_4 = self.down_l_4(down_out_l_3)bottom_out_l = self.bottom_l(down_out_l_4)up_out_l_1 = self.up_l_1(torch.cat([down_out_l_4, bottom_out_l], dim=1))up_out_l_2 = self.up_l_2(torch.cat([down_out_l_3, up_out_l_1], dim=1))up_out_l_3 = self.up_l_3(torch.cat([down_out_l_2, up_out_l_2], dim=1))up_out_l_4 = self.up_l_4(torch.cat([down_out_l_1, up_out_l_3], dim=1))return up_out_l_4def forward(self, x):# input data# three-path# s (16, 32)output_s = self.fake_slide_window(x, 1/4, 1)# m (16, 32, 64)output_m = self.fake_slide_window(x, 1/2, 1)# l (16, 32, 64, 128, 256)output_l = self.l_network(x)# concatoutput = torch.cat((output_l, output_m, output_s), 1)# final layer + softmax?output = self.final_layer(output)return output, output_l, output_m, output_s
4.
我现在猜测是我的网络的问题,然后我用了原来的UNet和bn,然后用我新的切patch的方法,但是他妈的结果还是一样,bullshit。
import torchimport torch.nn as nnimport pytorch_lightning as plfrom typing import Any, Callable, List, Sequence, Tuple, Unionfrom monai.networks.layers.factories import Actfrom monai.utils import BlendModefrom monai.inferers.utils import _get_scan_intervalfrom monai.data.utils import dense_patch_slices, compute_importance_map, get_valid_patch_sizefrom monai.networks.layers import Normfrom monai.networks.blocks.convolutions import Convolution, ResidualUnitfrom monai.networks.nets import UNetdef recover_divisible_patch(inputs, image_size, slice_range, unravel_slice):# only for non-overlapdevice = inputs.devicebatch_size = 1output_classes = inputs.shape[1]output_shape = [batch_size, output_classes] + list(image_size)# allocate memory to store the full output and the count for overlapping partsoutput_image = torch.zeros(output_shape, dtype=torch.float32, device=device)# store the result in the proper location of the full output. Apply weights from importance map.for idx, original_idx in zip(slice_range, unravel_slice):output_image[original_idx] += inputs[idx]return output_imagedef divisible_patch(inputs: torch.Tensor,ratio,device: Union[torch.device, str, None] = None,*args: Any,**kwargs: Any,):num_spatial_dims = len(inputs.shape) - 2if device is None:device = inputs.deviceimage_size = list(inputs.shape[2:])batch_size = inputs.shape[0]roi_size = []for i in image_size:i = i * ratioroi_size.append(int(i))overlap = 0scan_interval = _get_scan_interval(image_size, roi_size, num_spatial_dims, overlap)# Store all slices in listslices = dense_patch_slices(image_size, roi_size, scan_interval)num_win = len(slices) # number of windows per imagetotal_slices = num_win * batch_size # total number of windowsslice_range = range(0, total_slices)unravel_slice = [[slice(int(idx / num_win), int(idx / num_win) + 1), slice(None)] + list(slices[idx % num_win])for idx in slice_range]# This is end of cut datawindow_data = torch.cat([inputs[win_slice] for win_slice in unravel_slice]).to(device)return window_data, image_size, slice_range, unravel_sliceclass mswTripleUNet(torch.nn.Module):def __init__(self):super().__init__()self._modelS = UNet(spatial_dims=3,in_channels=1,out_channels=2,channels=(16, 32),strides=(2,),num_res_units=2,norm=Norm.BATCH,)self._modelM = UNet(spatial_dims=3,in_channels=1,out_channels=2,channels=(16, 32, 64),strides=(2, 2,),num_res_units=2,norm=Norm.BATCH,)self._modelL = UNet(spatial_dims=3,in_channels=1,out_channels=2,channels=(16, 32, 64, 128, 256),strides=(2, 2, 2, 2),num_res_units=2,norm=Norm.BATCH,)self.final_layer = Convolution(spatial_dims=3,in_channels=6,out_channels=2,strides=1,kernel_size=3,act=Act.PRELU,norm=Norm.BATCH,dropout=0.0,bias=True,conv_only=True,is_transposed=True,)# the batch size to run window slicesself.sw_batch_size = 1def forward(self, x):# input datax_l = xx_m, image_size_m, slice_range_m, unravel_slice_m = divisible_patch(x, 1/2)x_s, image_size_s, slice_range_s, unravel_slice_s = divisible_patch(x, 1/4)# split into 3 partoutput_s = self._modelS(x_s)output_s = recover_divisible_patch(output_s, image_size_s, slice_range_s, unravel_slice_s)output_m = self._modelM(x_m)output_m = recover_divisible_patch(output_m, image_size_m, slice_range_m, unravel_slice_m)output_l = self._modelL(x_l)# concatoutput = torch.cat((output_s, output_m, output_l), 1)# final layer + softmax?output = self.final_layer(output)return output, output_l, output_m, output_s
5. TripeUNet(543)
| id | different | max epoch | best val dice(epoch) | test dice | source |
|---|---|---|---|---|---|
| 1 | 5 4 3 | 228 | 0.8613(213) | 0.8507 | |
| 2 | 最后不叠加loss | still | 0.8680 335 | ||
| 3 | 中间融合(add+BN), 叠加loss | 231 | 0.8583 213 | ||
| 4 | 中间融合(add+GN),叠加loss | 250 | 0.8674 237 | 0.8552 | |
| 5 | 中间融合(cat+GN),叠加loss(TU_ccatgn_new) | 253 | 0.8714 187 | 0.8586 | |
| 6 | 中间融合(cat_gn+GN),叠加loss | 227 | 0.8619 216 |
第五:cat之后别忘了加normalization,灵感来自attention。
6. for other dataset
| id | dataset | method | max epoch | best val dice(epoch) | test dice | source |
|---|---|---|---|---|---|---|
| 1 | Cornary | 中间融合(cat+GN) | 337 | 0.7605 334 | ||
| 2 | roi_jy | 中间融合(cat+GN) | 243 | 0.8736 89 | ||
| 3 | ||||||
| 4 | ||||||
| 5 |
- cornary
- jingyang 采用的选择roi的方法,下面是他们的大小
the mean of s1 is 368.1923076923077, the min of s1 is 299, the max of s1 is 434
the mean of s2 is 256.46153846153845, the min of s2 is 199, the max of s2 is 322
the mean of s3 is 251.6769230769231, the min of s3 is 157, the max of s3 is 320
256 128 128
128 64 64
64 32 32
32 16 16
16 8 8
7. bottom重新组合
使中间S和M网络对应的尺寸都缩小一倍,使他们可以组合在一起。
- 缩小
- 可以使bottom带有stride(之前的bottom_layer都没有stride
- 让倒数第二层的步长翻倍(目前采用了这个,简单,对应的up也得翻倍
- 重组
- 一个问题是加上对batch_size的支持(先就为1这么跑吧
| id | dataset | method | max epoch | best val dice(epoch) | test dice | source |
| —- | —- | —- | —- | —- | —- | —- |
| 1 | roi_jy | 2a | 260 | 0.8709 255 | | |
| 2 |
|
| | | | | | 3 | | | | | | | | 4 | | | | | | | | 5 | |
| | | | |
- 一个问题是加上对batch_size的支持(先就为1这么跑吧
| id | dataset | method | max epoch | best val dice(epoch) | test dice | source |
| —- | —- | —- | —- | —- | —- | —- |
| 1 | roi_jy | 2a | 260 | 0.8709 255 | | |
| 2 |
这个问题就在于最后一维的块太小了,而且采用1b的方法最后的步长太大,很多的信息都没有采集到。
todo: 把roi数据裁大一点。
end: 把margin增大到了16,但是效果还是没有提升,反而val_Dice只有0.54,严重怀疑我的代码有问题。(TU_16Roi-52869)
问题,可能在于最后一层是prelu,考虑设置成sigmoid,这样不用在diceloss里算sigmoid了。至于算dice,一般是在argmax之后算。
8. Multi-Scale(jm)
TU_multiscale. 数据大小分别是(256, 192, 192), (214, 160, 160), (192, 128, 128)。然后大网络->中网络,中网络->小网络。所有数据都是提前先切patch,每个数据都切了不少patch。(问题:这些patch都过一遍吗,还是每次就随机选择呢?应该还是要随机选择,肯定不可能全部过一遍)
as the S the center.<br />v1: three path, and supervised persepctively.<br />v2: three path, crop, simple convlution, and finally supervised by the center part.
| id | dataset | method | max epoch | patch strategy or number | best val dice(epoch) | test dice | source | |
|---|---|---|---|---|---|---|---|---|
| 1 | roi_jy | v1 | 250(randsample) | 0.7756(149) | ||||
| 2 | roi_jy | v2 | 125 | 0.7345(107) | ||||
| 3 | ||||||||
| 4 | ||||||||
| 5 |
9. Tu_trans
| id | dataset | method | max epoch | patch strategy or number | best val dice(epoch) | test dice | source | |
|---|---|---|---|---|---|---|---|---|
| 1 | roi_jy | S2M2L | 432 | 0.7612(387 | ||||
| 2 | roi_jy | L2M2S | doing | 125 | ||||
| 3 | roi_jy | Lonly2S | 149 | 0.6607(90 | ||||
| 4 | roi_jy | mTUV2L2S | 500 | 0.82 | 0.77 | |||
| 5 |
10. 跳连 concat
| id | dataset | method | max epoch | patch strategy or number | best val dice(epoch) | test dice | source | |
|---|---|---|---|---|---|---|---|---|
| 1 | roi_jy | v1 | 500 | 0.8410(325 | ||||
| 2 | roi_jy | v2(with background) | 500 | 0 | 0.8437 | |||
| 3 | roi_jy | |||||||
| 4 | roi_jy | |||||||
| 5 |
如果采用先训练大网络,然后训练其他网络的方法。那么在load进大网络参数后,还更新它吗?如果不更新的话,最后的loss还加权吗?(我觉得需要更新,因为目的是增加多尺度的内容
也可以采用freeze的方法,先freeze部分参数,但是得有初始值,然后

若有收获,就点个赞吧
0 人点赞
