二分/折半查找
在有序的数组里找出指定的值,返回该值在数组中的索引。
查找步骤如下:
- 从有序数组的最中间元素开始查找,如果该元素正好是指定查找的值,则查找过程结束。否则进行下一步;
- 如果指定要查找的元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半区域查找,然后重复第一步的操作;
- 重复以上过程,直到找到目标元素的索引,查找成功;或者直到子数组为空,查找失败。
优点是比较次数少,查找速度快,平均性能好; 其缺点是要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而查找频繁的有序列表。
1.非递归
//arr:数组;key:查找的元素function search(arr, key) {//初始索引开始位置和结束位置var start = 0,end = arr.length - 1;while(start <= end) {//取上限和下限中间的索引var mid = parseInt((end + start) /2);if(key == arr[mid]) {//如果找到则直接返回return mid;} else if(key > arr[mid]) {//如果key是大于数组中间索引的值则将索引开始位置设置为中间索引+1start = mid + 1;} else {//如果key是小于数组中间索引的值则将索引结束位置设置为中间索引-1end = mid -1;}}//如果在循环内没有找到查找的key(start<=end)的情况则返回-1return -1;}var arr = [0,13,21,35,46,52,68,77,89,94];search(arr, 68); //6search(arr, 1); //-1
2.递归
//arr:数组;key:查找的元素;start:开始索引;end:结束索引function search2(arr,key,start,end){//首先判断当前起始索引是否大于结束索引,如果大于说明没有找到元素返回-1if(start > end) {return -1;}//如果手动调用不写start和end参数会当做第一次运行默认值//三元表达式:如果不写end参数则为undefined说明第一次调用所以结束索引为arr.length-1//如果是递归调用则使用传进来的参数end值var end= end===undefined ? arr.length-1 : end;//如果 || 前面的为真则赋值start,如果为假则赋值后面的0//所以end变量没有写var end = end || arr.length-1;这样如果递归调用时候传参end为0时会被转化为false,导致赋值给arr.length-1造成无限循环溢出;var start=start || 0;//取中间的索引var mid=parseInt((start+end)/2);if(key==arr[mid]){//如果找到则直接返回return mid;}else if(key<arr[mid]){//如果key小于则递归调用自身,将结束索引设置为中间索引-1return search2(arr,key,start,mid-1);}else{//如果key大于则递归调用自身,将起始索引设置为中间索引+1return search2(arr,key,mid+1,end);}}var arr = [0,13,21,35,46,52,68,77,89,94];search2(arr, 77); //7search2(arr, 99); //-1
找出最大和的连续子数组
一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组 是数组中的一个连续部分。
示例 1:输入: nums = [-2,1,-3,4,-1,2,1,-5,4] 输出: 6 解释: 连续子数组 [4,-1,2,1] 的和最大,为 6 。
示例 2:输入: nums = [1] 输出: 1
示例 3:输入: nums = [5,4,-1,7,8] 输出: 23
提示:
1 <= nums.length <= 105-104 <= nums[i] <= 104
进阶:如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的 分治法 求解。
题目:
/**
* @param {number[]} nums
* @return {number}
*/
var maxSubArray = function(nums) {
};
思路: 假设 nums 数组的长度是 n,下标从 0 到 n-1。我们用 f(i) 代表以第 i 个数结尾的「连续子数组的最大和」,那么很显然我们要求的答案就是: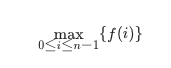
因此我们只需要求出每个位置的 f(i),然后返回 f 数组中的最大值即可。那么我们如何求 f(i) 呢?我们可以考虑 nums[i] 单独成为一段还是加入 f(i-1) 对应的那一段,这取决于 nums[i] 和 f(i-1) + nums[i] 的大小,我们希望获得一个比较大的,于是可以写出这样的动态规划转移方程: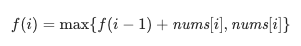
不难给出一个时间复杂度 O(n)、空间复杂度 O(n) 的实现,即用一个 f 数组来保存 f(i) 的值,用一个循环求出所有 f(i)。考虑到 f(i) 只和 f(i-1) 相关,于是我们可以只用一个变量 pre 来维护对于当前 f(i) 的 f(i-1) 的值是多少,从而让空间复杂度降低到 O(1),这有点类似「滚动数组」的思想。
方法一:动态规划
var maxSubArray = function(nums) {
let pre = 0, maxAns = nums[0];
nums.forEach((x) => {
pre = Math.max(pre + x, x);
maxAns = Math.max(maxAns, pre);
});
return maxAns;
};
复杂度
- 时间复杂度:O(n),其中 n 为 nums 数组的长度。我们只需要遍历一遍数组即可求得答案。
-
方法二:分治
这个分治方法类似于「线段树求解最长公共上升子序列问题」的 pushUp 操作。
我们定义一个操作 get(a, l, r) 表示查询 a 序列 [l,r] 区间内的最大子段和,那么最终我们要求的答案就是 get(nums, 0, nums.size() - 1)。如何分治实现这个操作呢?对于一个区间 [l,r],我们取 m = (l + r)/2,对区间 [l,m] 和 [m+1,r] 分治求解。当递归逐层深入直到区间长度缩小为 1 的时候,递归「开始回升」。这个时候我们考虑如何通过 [l,m] 区间的信息和 [m+1,r] 区间的信息合并成区间 [l,r] 的信息。最关键的两个问题是: 我们要维护区间的哪些信息呢?
- 我们如何合并这些信息呢?
对于一个区间 [l,r],我们可以维护四个量:
- lSum 表示 [l,r] 内以 l 为左端点的最大子段和
- rSum 表示 [l,r] 内以 r 为右端点的最大子段和
- mSum 表示 [l,r] 内的最大子段和
- iSum 表示 [l,r] 的区间和
以下简称 [l,m] 为 [l,r] 的「左子区间」,[m+1,r] 为 [l,r] 的「右子区间」。我们考虑如何维护这些量呢(如何通过左右子区间的信息合并得到 [l,r] 的信息)?对于长度为 1 的区间 [i, i],四个量的值都和 nums}[i] 相等。对于长度大于 1 的区间:
- 首先最好维护的是 iSum,区间 [l,r] 的 iSum 就等于「左子区间」的 iSum 加上「右子区间」的 iSum。
- 对于 [l,r] 的 lSum,存在两种可能,它要么等于「左子区间」的 lSum,要么等于「左子区间」的 iSum 加上「右子区间」的 lSum,二者取大。
- 对于 [l,r] 的 rSum,同理,它要么等于「右子区间」的 rSum,要么等于「右子区间」的 iSum 加上「左子区间」的 rSum,二者取大。
- 当计算好上面的三个量之后,就很好计算 [l,r] 的 mSum 了。我们可以考虑 [l,r] 的 mSum 对应的区间是否跨越 m——它可能不跨越 m,也就是说 [l,r] 的 mSum 可能是「左子区间」的 mSum 和 「右子区间」的 mSum 中的一个;它也可能跨越 m,可能是「左子区间」的 rSum 和 「右子区间」的 lSum 求和。三者取大。
这样问题就得到了解决。
function Status(l, r, m, i) {
this.lSum = l;
this.rSum = r;
this.mSum = m;
this.iSum = i;
}
const pushUp = (l, r) => {
const iSum = l.iSum + r.iSum;
const lSum = Math.max(l.lSum, l.iSum + r.lSum);
const rSum = Math.max(r.rSum, r.iSum + l.rSum);
const mSum = Math.max(Math.max(l.mSum, r.mSum), l.rSum + r.lSum);
return new Status(lSum, rSum, mSum, iSum);
}
const getInfo = (a, l, r) => {
if (l === r) {
return new Status(a[l], a[l], a[l], a[l]);
}
const m = (l + r) >> 1;
const lSub = getInfo(a, l, m);
const rSub = getInfo(a, m + 1, r);
return pushUp(lSub, rSub);
}
var maxSubArray = function(nums) {
return getInfo(nums, 0, nums.length - 1).mSum;
};
复杂度分析
假设序列 a 的长度为 n。
- 时间复杂度:假设我们把递归的过程看作是一颗二叉树的先序遍历,那么这颗二叉树的深度的渐进上界为 O(log n),这里的总时间相当于遍历这颗二叉树的所有节点,故总时间的渐进上界是 O(\sum_{i=1}^{\log n} 2^{i-1})=O(n),故渐进时间复杂度为 O(n)。
- 空间复杂度:递归会使用 O(log n) 的栈空间,故渐进空间复杂度为 O(log n)。
「方法二」相较于「方法一」来说,时间复杂度相同,但是因为使用了递归,并且维护了四个信息的结构体,运行的时间略长,空间复杂度也不如方法一优秀,而且难以理解。那么这种方法存在的意义是什么呢?
对于这道题而言,确实是如此的。但是仔细观察「方法二」,它不仅可以解决区间 [0, n-1],还可以用于解决任意的子区间 [l,r] 的问题。如果我们把 [0, n-1] 分治下去出现的所有子区间的信息都用堆式存储的方式记忆化下来,即建成一颗真正的树之后,我们就可以在 O(log n) 的时间内求到任意区间内的答案,我们甚至可以修改序列中的值,做一些简单的维护,之后仍然可以在 O(log n) 的时间内求到任意区间内的答案,对于大规模查询的情况下,这种方法的优势便体现了出来。这棵树就是上文提及的一种神奇的数据结构——线段树。
最长子序列
给定一个数组array和一个数target,如果array存在连续的几个数相加等于target,返回这几个数的最大个数,否则返回-1
岛屿数量
给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:
grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出: 1
示例 2:
输入:
grid = [
["1","1","0","0","0"],
["1","1","0","0","0"],
["0","0","1","0","0"],
["0","0","0","1","1"]
]
输出: 3
提示:
- m == grid.length
- n == grid[i].length
- 1 <= m, n <= 300
grid[i][j] 的值为 ‘0’ 或 ‘1’ ```javascript /**
@param {character[][]} grid
@return {number}
*/
var numIslands = function(grid) {
};
<a name="Rh2MD"></a>
## 方法一:深度优先搜索
我们可以将二维网格看成一个无向图,竖直或水平相邻的 11 之间有边相连。<br />为了求出岛屿的数量,我们可以扫描整个二维网格。如果一个位置为 11,则以其为起始节点开始进行深度优先搜索。在深度优先搜索的过程中,每个搜索到的 11 都会被重新标记为 00。<br />最终岛屿的数量就是我们进行深度优先搜索的次数。
```javascript
const numIslands = (grid) => {
let count = 0
for (let i = 0; i < grid.length; i++) {
for (let j = 0; j < grid[0].length; j++) {
if (grid[i][j] === '1') {
count++
turnZero(i, j, grid)
}
}
}
return count
}
function turnZero(i, j, grid) {
if (i < 0 || i >= grid.length || j < 0
|| j >= grid[0].length || grid[i][j] === '0') return
grid[i][j] = '0'
turnZero(i, j + 1, grid)
turnZero(i, j - 1, grid)
turnZero(i + 1, j, grid)
turnZero(i - 1, j, grid)
}
复杂度分析
- 时间复杂度:O(MN),其中 M 和 N 分别为行数和列数。
空间复杂度:O(MN),在最坏情况下,整个网格均为陆地,深度优先搜索的深度达到 MN。
方法二:广度优先搜索
同样地,我们也可以使用广度优先搜索代替深度优先搜索。
为了求出岛屿的数量,我们可以扫描整个二维网格。如果一个位置为 11,则将其加入队列,开始进行广度优先搜索。在广度优先搜索的过程中,每个搜索到的 11 都会被重新标记为 00。直到队列为空,搜索结束。
最终岛屿的数量就是我们进行广度优先搜索的次数。 ```javascript const numIslands = (grid) => {let count = 0
let queue = []
for (let i = 0; i < grid.length; i++) {
for (let j = 0; j < grid[0].length; j++) {
if (grid[i][j] === '1') { count++ grid[i][j] = '0' // 做标记,避免重复遍历 queue.push([i, j]) turnZero(queue, grid) }}
}
return count
}
function turnZero(queue, grid) {
const dirs = [[0, 1], [1, 0], [0, -1], [-1, 0]]
while (queue.length) {
const cur = queue.shift()
for (const dir of dirs) {
const x = cur[0] + dir[0]
const y = cur[1] + dir[1]
if (x < 0 || x >= grid.length || y < 0 || y >= grid[0].length || grid[x][y] !== '1') {
continue
}
grid[x][y] = '0'
queue.push([x, y])
}
}
}
**复杂度分析**
- 时间复杂度:O(MN),其中 M 和 N 分别为行数和列数。
- 空间复杂度:O(min(M,N)),在最坏情况下,整个网格均为陆地,队列的大小可以达到 min(M,N)。
<a name="nbAls"></a>
## 方法三:并查集
同样地,我们也可以使用并查集代替搜索。<br />为了求出岛屿的数量,我们可以扫描整个二维网格。如果一个位置为 1,则将其与相邻四个方向上的 1 在并查集中进行合并。<br />最终岛屿的数量就是并查集中连通分量的数目。
```javascript
/**
* @param {character[][]} grid
* @return {number}
*/
var numIslands = function(grid) {
const Y = grid.length;
const X = grid[0].length;
const uf = new UnionFind();
for(let i = 0; i < Y; i++) {
for(let j = 0; j < X; j++) {
if(grid[i][j] == 1) uf.makeSet([i, j]);
}
}
for(let i = 0; i < Y; i++) {
for(let j = 0; j < X; j++) {
if (grid[i][j] == 1) {
console.log(i , j)
if ((i + 1 < Y) && (grid[i + 1][j] == 1)) uf.union([i, j], [i + 1, j]); // 右侧
if ((j + 1 < X) && (grid[i][j + 1] == 1)) uf.union([i, j], [i, j + 1]); // 下侧
}
}
}
return uf.getCount();
};
class UnionFind {
constructor() {
this.parents = {};
this.count = 0;
}
makeSet(x) {
this.parents[x] = x + '';
this.count++;
}
findSet(x) { // 路径压缩,查x的根节点
while (this.parents[x] !== (x + '')) {
x = this.parents[x];
}
return x + '';
}
union(x, y) {
this.link(this.findSet(x), this.findSet(y));
}
link(x, y) {
if (x === y) return;
this.parents[x] = y;
this.count--;
}
getCount() {
return this.count;
}
}
复杂度分析
- 时间复杂度:O(MN×α(MN)),其中 MM 和 NN 分别为行数和列数。注意当使用路径压缩(见 find 函数)和按秩合并(见数组 rank)实现并查集时,单次操作的时间复杂度为 α(MN),其中 α(x) 为反阿克曼函数,当自变量 xx 的值在人类可观测的范围内(宇宙中粒子的数量)时,函数 α(x) 的值不会超过 5,因此也可以看成是常数时间复杂度。
-
HJ93 数组分组
描述
输入int型数组,询问该数组能否分成两组,使得两组中各元素加起来的和相等,并且,所有5的倍数必须在其中一个组中,所有3的倍数在另一个组中(不包括5的倍数),不是5的倍数也不是3的倍数能放在任意一组,可以将数组分为空数组,能满足以上条件,输出true;不满足时输出false。
数据范围:每个数组大小满足 1≤n≤50 ,输入的数据大小满足 ∣val∣≤500
输入描述:第一行是数据个数,第二行是输入的数据
输出描述:返回true或者false
示例1
输入:4 1 5 -5 1
输出:true
说明:第一组:5 -5 1 第二组:1
示例2
输入:3 3 5 8
输出:false
说明:由于3和5不能放在同一组,所以不存在一种分法。
```javascript //参考网友ld1230的解法 //思想:将能整除3或者5的各自分为一组,记为sum1和sum2,剩余的保存在数组nums里 //现有两组,剩余nums里的数要么在sum1里要么在sum2里,利用递归依次放在sum1和sum2中 //最终nums里的数字全部放进去,若sum1 == sum2,则返回true,否则,返回false let str; while(str = readline()){ let num = readline(); let arr = num.split(‘ ‘); let three = arr.filter((v)=>{ return v%3==0 && v%5!=0; })let five = arr.filter((v)=>{ return v%5==0; })
let other = arr.filter((v)=>{ return v%5!=0 &&v%3!=0; }) //所有三的倍数的数字的和 let tsum = three.reduce((pre,cur)=>{ return pre+cur1; },0) //所有五的倍数的数字的和 let fsum = five.reduce((pre,cur)=>{ return pre+cur1; },0)
console.log(isExists(tsum,fsum,other,0)) }
function isExists(sum1,sum2,nums,index){ if(index == nums.length && sum1 != sum2) return false; if(index == nums.length && sum1 == sum2) return true; if(index < nums.length) return isExists(sum1+parseInt(nums[index]), sum2, nums, index+1) || isExists(sum1, sum2+parseInt(nums[index]), nums, index+1); return false; }
<a name="LgY2M"></a>
# <br />合并表记录
题目描述<br />数据表记录包含表索引和数值(int范围的整数),请对表索引相同的记录进行合并,即将相同索引的数值进行求和运算,输出按照key值升序进行输出。<br />输入描述:<br />先输入键值对的个数<br />然后输入成对的index和value值,以空格隔开<br />输出描述:<br />输出合并后的键值对(多行)
示例1<br /> 输入<br /> 4<br /> 0 1<br /> 0 2<br /> 1 2<br /> 3 4<br /> 输出<br /> 0 3<br /> 1 2<br /> 3 4
```javascript
let keyNum = readline();
let keyMap = {};
for(let i = 0; i < keyNum; i++) {
// let kv = readline(); //这里不能直接读取进来后得到数组
let kv = readline().split(' ').map(function(item){
return parseInt(item); //转换成正整数
}); // map对数组的每个元素都遍历一次,同时返回一个新的值
if(keyMap[kv[0]]) {
keyMap[kv[0]] += kv[1];
} else {
keyMap[kv[0]] = kv[1];
}
}
//下面几种遍历方法都试过,但是都有问题
// map遍历方法
/*
map.forEach(function(value,key){
console.log(value,key);
});
for(let item of map){};
for(let item of map.values()){};
for(let item of map.keys()){};
*/
// 这里使用 Object.keys() 方法,可以返回对象的 key 值为一个数组,也可以返回字符串/数组的 索引值
let res = Object.keys(keyMap);
for(let j = 0; j < res.length; j++) {
console.log(res[j]+' '+keyMap[res[j]]);
}
叠书:给定一个二维数组类似于”[[20,16],[20,21],[10,20],[9,10]]”
对于二维数组的每一个元素:第一个元素表示书的宽度,第二个元素表示书的高度,叠在上面的书比在下面的书宽度和高度都要小,求最多能叠的书的数量 。
思路:动态规划,实质是求最长递增子序列,但本题有两个因素需要考虑,可以通过排序将长度置为有序,这样其实就是对宽度求最长递增子序列,且可能存在长度相同的情况,在更新dp数组判定时,也要考虑到
// 获取输入
const input = "[[16,15], [16, 14], [13, 12], [15, 14]]"
// 转为数组
const arr = JSON.parse(input)
const len = arr.length
// dp数组 dp[i]表示前i本书的最长子序列长度
// 默认为1即每个序列本身就是一个子序列,长度为1
const dp = new Array(len).fill(1)
// 对输入的数组按照长度、宽度的大小进行排序
arr.sort((a, b) => {
if (a[0] !== b[0]) {
return a[0] - b[0]
} else {
return a[1] - b[1]
}
})
// 结果,初始为1,即至少可以放一本书
let res = 1
// 从第2本书向前找,看看加上它能不能增加长度
for (let i = 1; i < len; i++) {
// 要新加的书的长度和宽度
const cur = arr[i]
for (let j = 0; j < i; j++) {
// 要比较的书的长度和宽度
const pre = arr[j]
if (cur[0] > pre[0] && cur[1] > pre[1]) {
// 新加的书的长宽均大于当前书,说明这本书可以加在当前书的递增序列之后
// 判断此时的递增子序列最大值
dp[i] = Math.max(dp[i], dp[j] + 1)
}
// 更新最大值结果
res = Math.max(res, dp[i])
}
}
console.log(res);
假设你正在爬楼梯。需要 n 阶你才能到达楼顶
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢
示例 1:
输入:n = 2
输出:2
解释:有两种方法可以爬到楼顶。
1. 1 阶 + 1 阶
2. 2 阶
示例 2:
输入:n = 3
输出:3
解释:有三种方法可以爬到楼顶。
1. 1 阶 + 1 阶 + 1 阶
2. 1 阶 + 2 阶
3. 2 阶 + 1 阶
var climbStairs = function(n) {
const dp = [];
dp[0] = 1;
dp[1] = 1;
for(let i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[n];
};
给出三个矩形的左上角x、y坐标、长和宽,求三个矩形相交的面积
给一组数和一个数据,求该数据包含数组里的数的最多个数
输入:2 11 5 3 10
20
输出:4
思路:先对数组排序,然后从小到大一个一个去试
扑克牌顺子
给定13张牌(牌型有2,3,4,5,6,7,8,9,10,J,Q,K,A);顺子最少需要五张连续的牌,最小牌从3开始,最大到A;如{2,3,4,5,6},{J,Q,K,A,2}都不是顺子,输入13张牌的牌型(会有重复),输出其中可以组成的顺子,如有多组,按顺子的第一张牌大小排序输出,没有则输出NO;
例如:输入 2 3 5 J K Q 9 8 7 7 J A 2
输出 NO;
输入:J K 2 4 7 8 9 8 10 Q 3 K J
输出 7 8 9 10 J Q K
#include<stdio.h>
#include<string.h>
int cmp(int* a, int* b) {
return *a - *b;
}
int main()
{
//输入牌型有字符有数字还有‘10’,所以我选择按字符串输入,再分割
char str[30];
gets(str);
int len = strlen(str);
str[len] = '\0';
char str1[][3] = { "2","3","4","5","6","7","8","9","10","J","Q","K","A" };
int arr[] = { 2,3,4,5,6,7,8,9,10,11,12,13,14 };
int sign[14];//分割后的数组
int index = 0;//下标
for (int i = 0; i <= len; i++)
{
if (str[i] == ' ' || str[i] == '\0')
{
if (str[i - 1] == '0')
sign[index++] = 10;
else
{
for (int j = 0; j < 13; j++)
{
if (str[i - 1] == str1[j][0])
{
sign[index++] = arr[j];
break;
}
}
}
}
}
int flag = 0;
model:qsort(sign, 13, sizeof(int), cmp);
for (int i = 0; i < 13; i++)
{
if (sign[i] >= 3 && sign[i] <= 10)
{
int k = sign[i];
int count = 1;
for (int j = i + 1; j < 13; j++)
{
if (sign[j] - sign[j - 1] == 1)
{
count++;
sign[j - 1] = 2;
if (sign[j] == 14)
{
sign[j] = 2;
break;
}
}
else if (sign[j] == sign[j - 1])
continue;
else
break;
}
if (count >= 5)
{
flag = 1;
for (int j = k; j < k + count; j++) {
printf("%s ", str1[j - 2]);
}
printf("\n");
goto model;
}
}
}
if (flag == 0)
printf("NO\n");
return 0;
}

若有收获,就点个赞吧
0 人点赞
