从往浏览器输入 URL 到获取网页内容之间发生了什么
URI 和 URL
URI, Uniform Resource Identifier, 统一资源标识符;
URL, Uniform Resource Locator, 统一资源定位符;
URN, Uniform Resource Name, 统一资源名称。
URI/URL https://github.com/favicon.ico 定义了图标资源
favicon.ico唯一访问方式,包括访问协议 (HTTPS)、访问路径 (根路径)、资源名称 (favicon.ico); URN ISBN: 0451450523 指定了 ISBN 编号为 0451450523 的书(只为资源命名,但不指定资源的位置)。


URL 基本组成规范
scheme://[username:password@]hostname[:port][/path][;parameters][?query][#fragment]
scheme
访问资源的协议,亦称为 protocol。
常用的协议有 http、https、ftp、sftp、smb 等。
username 与 password
访问特定内容时需要提供的用户名与密码。
访问 https://ssr3.scrape.center/ 需要在弹窗中输入用户名和密码;但访问 https://admin:admin@ssr3.scrape.center/ 则可直接授权。
hostname
表现为域名或 IP 地址的主机地址。
dns.google 和 8.8.8.8 分别是 https://dns.google/ 的二级域名与 IP 地址。 二级域(名):位于互联网域名系统的顶级域之下(
example是example.com的二级域)。

port
服务器设定的服务端口。若 URL 没有端口信息,则认为使用了协议的默认的端口号:http 协议的默认端口是 80,https 协议的默认端口号是 443。
https://www.baidu.com/ 等价于 https://www.baidu.com:443/; http://www.baidu.com/ 等价于 http://www.baidu.com:80/。
path
资源在服务器中的地址。
https://github.com/favicon.ico 的 path 是 favicon.ico,即访问服务器根目录下的 favicon.ico。
parameters
访问特定资源时的参数。
很少使用,甚至常常将参数
parameters与查询query混用。
query
查询指定资源。
https://www.baidu.com/s?ie=UTF-8&wd=crawler 的 query 部分是
ie=UTF-8&wd=crawler:指定ie值为UTF-8,且wd值为crawler。 更常用。query因此表意扩大为:(GET 请求)参数、parameters、params 等。
fragment
指向用于补充描述的资源内部的书签片段。
- 前端框架 Vue、React 都可以借助
fragment做单页面路由管理;- 用作 HTML 锚点控制页面的定位。
HTTP 和 HTTPS
HTTP 和 HTTPS 协议都属于计算机网络中的应用层协议,其下层基于 TCP 协议实现。TCP 协议属于计算机网络的传输层协议,包括建立连接时的“三次握手”和断开连接时的“四次挥手”等过程。
HTTP
HTTP (HyperText Transfer Protocol, 超文本传输协议) 是一种用于分布式、协作式和超媒体信息系统的应用层协议。最初的设计目的是为了提供一种高效可靠地发布、接收 HTML 页面的方法。
发展史如下表:
| 版本 | 产生时间 | 特点 | 现状 |
|---|---|---|---|
| HTTP 0.9 | 1991 年 | 只接受 GET 一种请求方法,没有在通讯中指定版本号,且不支持请求头。 不涉及数据包传输,规定了客户端与服务器间的通信格式。 |
已过时 |
| HTTP 1.0 | 1996 年 | 传输内容格式不限制,增加 PUT、PATCH、HEAD、OPTIONS、DELETE 命令 | 正式作为标准 |
| HTTP 1.1 | 1997 年 | 实现持久连接(长连接)、节约带宽、HOST 域、管道机制、分块传输编码的概念 | 正式作为标准并广泛使用 |
| HTTP 2.0 | 2015 年 | 实现多路复用、服务器推送、头信息压缩、二进制协议等概念 | 逐渐覆盖市场 |
总的来说,HTTP 2.0 在传输层做了很多优化,比 HTTP 1.1 更快、更简单、更稳定:通过支持完整的请求与响应复用来减少延迟、通过有效压缩 HTTP 请求头字段将协议开销降至最低、增加对请求优先级和服务器推送的支持。
当前,主流网站现已支持 HTTP 2.0,主流浏览器同样也实现了对 HTTP 2.0 的支持。但大部分网站仍以 HTTP 1.1 为主,且部分编程语言中的库可能仍只支持 HTTP 1.1(如 Python 的 requests 库尚且只支持 HTTP 1.1,但 hyper、httpx 等库已支持 HTTP 2.0)。
以下详述 HTTP 2.0 相比 HTTP 1.1 的主要新变化:
二进制分帧层
二进制分帧层是 HTTP 2.0 性能增强的核心。从 HTTP 1.x 到 HTTP 2.0,对请求 (Request) 和响应 (Response) 头部 (Head) 或实体 (Body) 在内的传输从使用文本换行符分隔的文本格式修改为了解析更高效的二进制格式。同时将数据分割为二进制编码的帧。
帧:HTTP 2.0 中,数据通信的最小单位。如,请求被分割为了请求头帧 (Request Headers Frame) 和请求体/数据帧 (Request Data Frame); 数据流:由唯一整数 ID 标识的,可承载双向消息的虚拟数据通道; 消息:一系列与完整逻辑请求/响应对应的帧。
二进制分帧层的连接可承载不限数量的二进制双向数据流(双向 HTTP 消息),使同一域名下的所有通信都只需要单个连接,即这些 TCP 连接实现了复用,这一特性成为了 HTTP 2.0 所有功能优化的基础。
多路复用
得益于 HTTP 2.0 的二进制分帧技术,连接不再依赖 TCP 的方式实现,而以分帧、重组方式实现。由此,避免了浏览器对同一域名不得超过 6~8 个 TCP 连接的限制,可在 1 个连接中并行交错地发送/接收多个请求/响应且互不干扰。大大降低了时延,减少了本地内存消耗,充分利用了网络容量,提升了数据传输性能而使页面响应更迅速。
HTTP 2.0 的每个请求都可以带上表示信息优先级的一个 31 位的值(0 值信息具有最高优先级)。通过在客户端和服务器设定特定的流策略,实现流、消息和帧传输的最优方案。
流控制
为了避免数据发送端发送的数据量超出数据接收端的需求或处理能力,需要引入流控制机制。
客户端请求了一个具有较高优先级的视频流,但用户已暂停观看了,客户端此时需要暂停或限制来自服务器的传输; 一个代理服务器可能具有较快的下游连接和较慢的上游连接,希望调节下游连接的数据传输速度以匹配上游连接速度。
虽然 HTTP 基于 TCP 实现,但原生 TCP 协议的流控制机制不够精细,无法提供必要的应用级 API 调节各数据流的传输。为此,HTTP 2.0 提供了一组简单的构建块,允许客户端和服务器自行实现数据流和连接级流的控制,这是流控制的特性:
- 流控制具有方向性。接收端可根据自身需要,为数据流或整个连接设置窗口大小;
- 流控制的窗口大小可动态调整。在初始连接和数据流流控制窗口(以字节计)的基础上,接收端收到发送端发出的
DATA帧后减小窗口,收到WINDOW_UPDATE帧后增大窗口; - 流控制无法停用。建立 HTTP 2.0 连接后,客户端将与服务器交换
SETTINGS帧,这会在两个方向上设置默认为 65,535 字节的流控制窗口。其中,接收方可以设置较大的最大窗口大小,并在接收到任意数据后发送WINDOW_UPDATE帧来维持这一大小;
至此,HTTP 2.0 通过简单的构建块,实现了策略的自定义,可灵活调节资源的使用与分配、提升了网页应用的实际和感知性能。
服务端推送
服务端推送指的是服务器可以对一个客户端请求发送多个响应。即除了响应最初的请求外,服务器还可在客户端未发出请求的前提下推送额外资源。为了保障安全性,服务的推送遵守同源策略——内容需由服务器和客户端共同确认。
对于客户端必要资源(如 CSS 和 JS 文件),服务端推送技术可在客户端的某次请求响应后(HTML 相关请求)完成资源推送,由此减少响应延时(不必等到客户端开始解析 HTML 时再发送这些请求)。
服务端可以主动推送,客户端也有权决定是否接收:若服务端推送的资源载入缓存,浏览器可发送RST_STREAM帧以拒收响应。
HTTPS
HTTPS (HyperText Transfer Protocol Secure, 超文本传输安全协议) 常被称为 HTTP over TLS、HTTP over SSL 或 HTTP Secure,是一种通过计算机网络进行安全通信的传输协议。HTTPS 利用 HTTP 通信,在 HTTP 下加入 SSL 层作为安全基础,通过 SSL/TLS 加密数据包。其主要目的是为网站服务器提供身份认证,保护交换资料的隐私与完整性。
SSL 的主要作用:
- 建立信息安全通道,保证数据传输的安全性;
- 确认网站的真实性(可在浏览器地址栏或通过 CA 机构颁发的安全签章查看网站认证的真实信息)。 :::info 越来越多的网站和 App 朝着 HTTPS 的方向发展,HTTPS 已成大势:
- 苹果公司强制所有 iOS App 在 2017 年 1 月 1 日前全部改用 HTTPS 加密传输,否则 App 无法上架应用商店;
- 从 2017 年 1 月推出的 Chrome 56 开始,浏览器对未进行 HTTPS 加密的网址提示风险——在地址栏提醒用户“此网页不安全”;
- 腾讯微信小程序的官方需求文档要求后台使用 HTTPS 请求进行网络通信,否则无法正常完成请求;
- ……
:::
HTTP 的请求过程
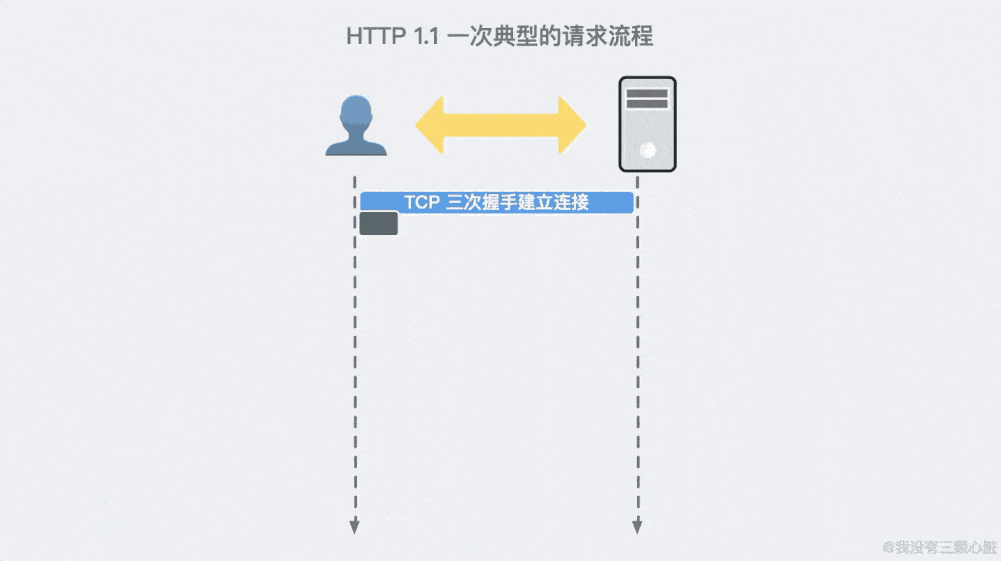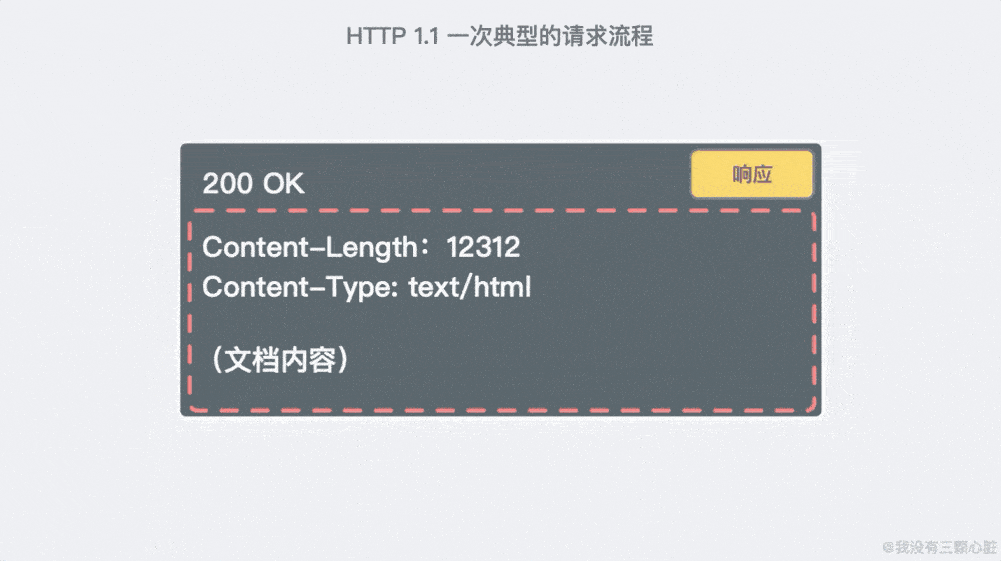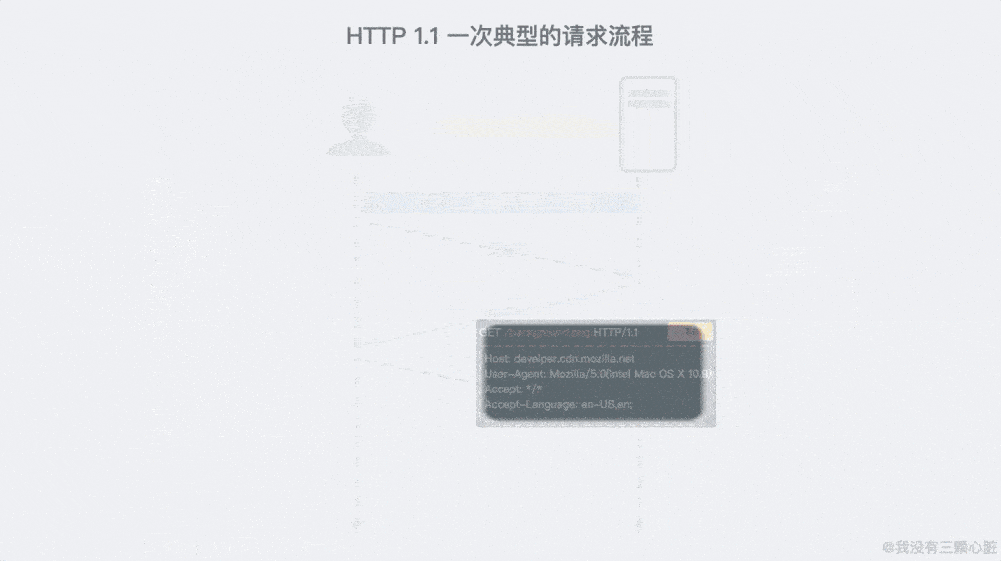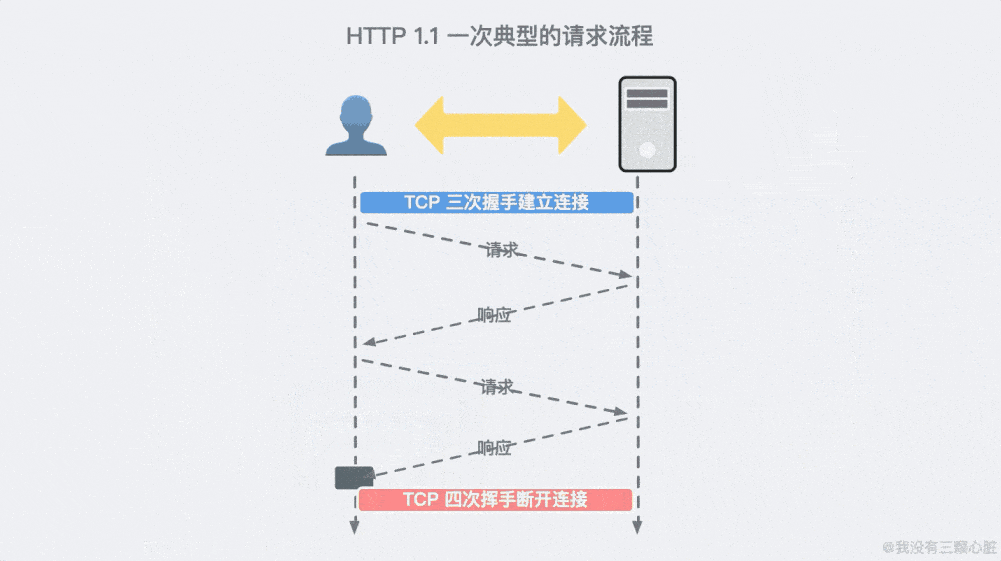
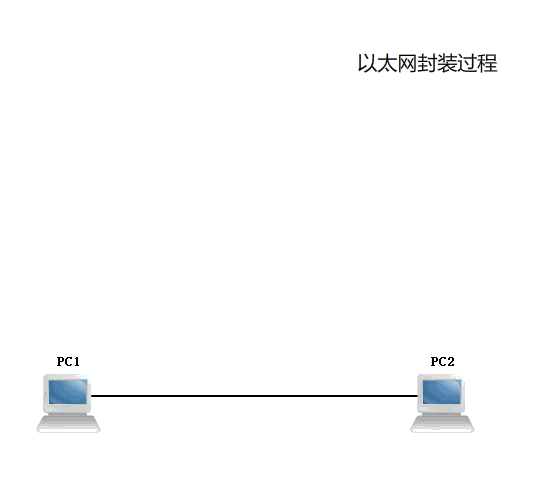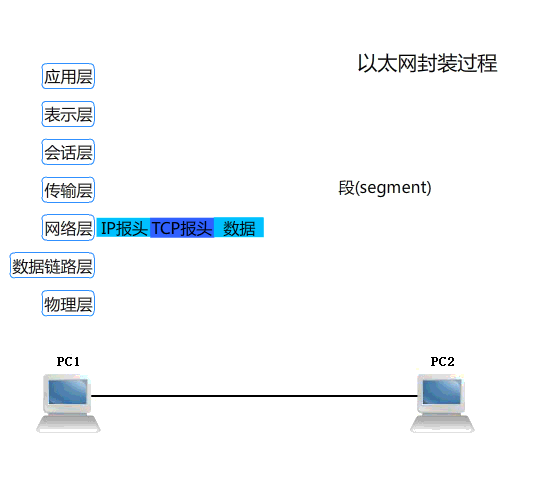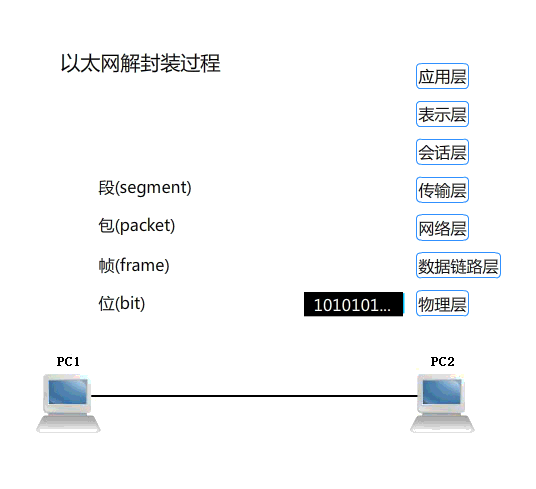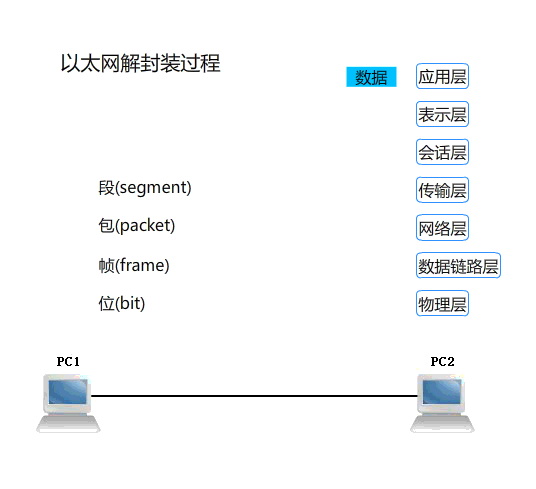
浏览器访问特定 URL 的基本流程:
- 在浏览器地址栏输人 URL 后回车;
- 浏览器向网站服务器发送请求;
- 网站服务器解析并处理请求后,返回特定响应;
- 响应的数据传回至浏览器;
- 浏览器解析数据(包括源代码等);
- 渲染网页。
用 Chrome 浏览器开发者工具的 Network 监听组件记录并显示访问请求的 URL 时产生的所有网络请求和响应,以此演示上述过程(以访问百度 (https://baidu.com/) 为例):
- 打开 Chrome 的开发者工具(使用网页右键菜单、自定义及控制选项、快捷键
F12或Ctrl+Shift+I均可直接唤起);
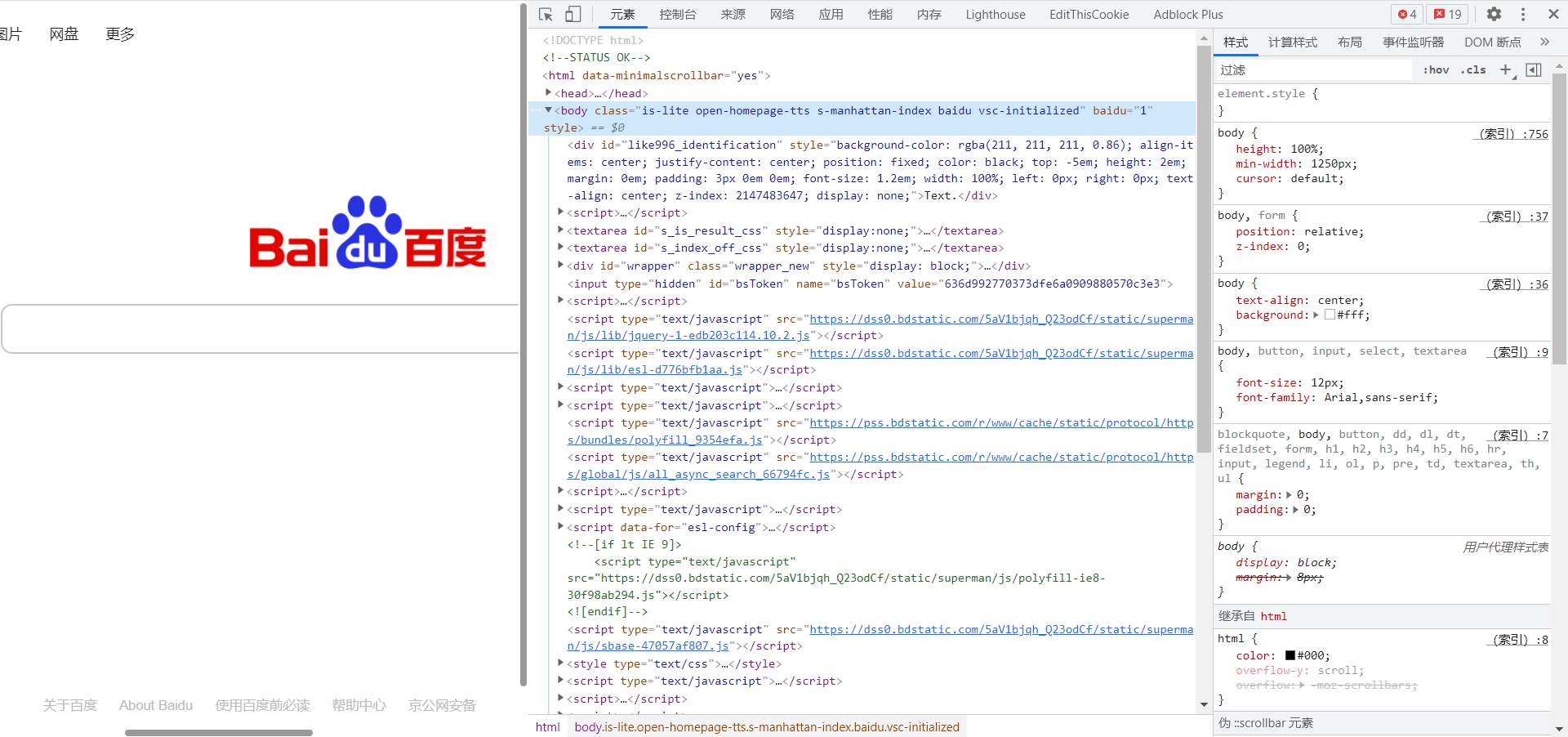
- 将开发者工具切换到“网络 (Network)”面板,保持启用网络日志录制状态(
Ctrl+E)并刷新网页(Ctrl+R),即可在面板下方列出全部请求及响应过程的条目;
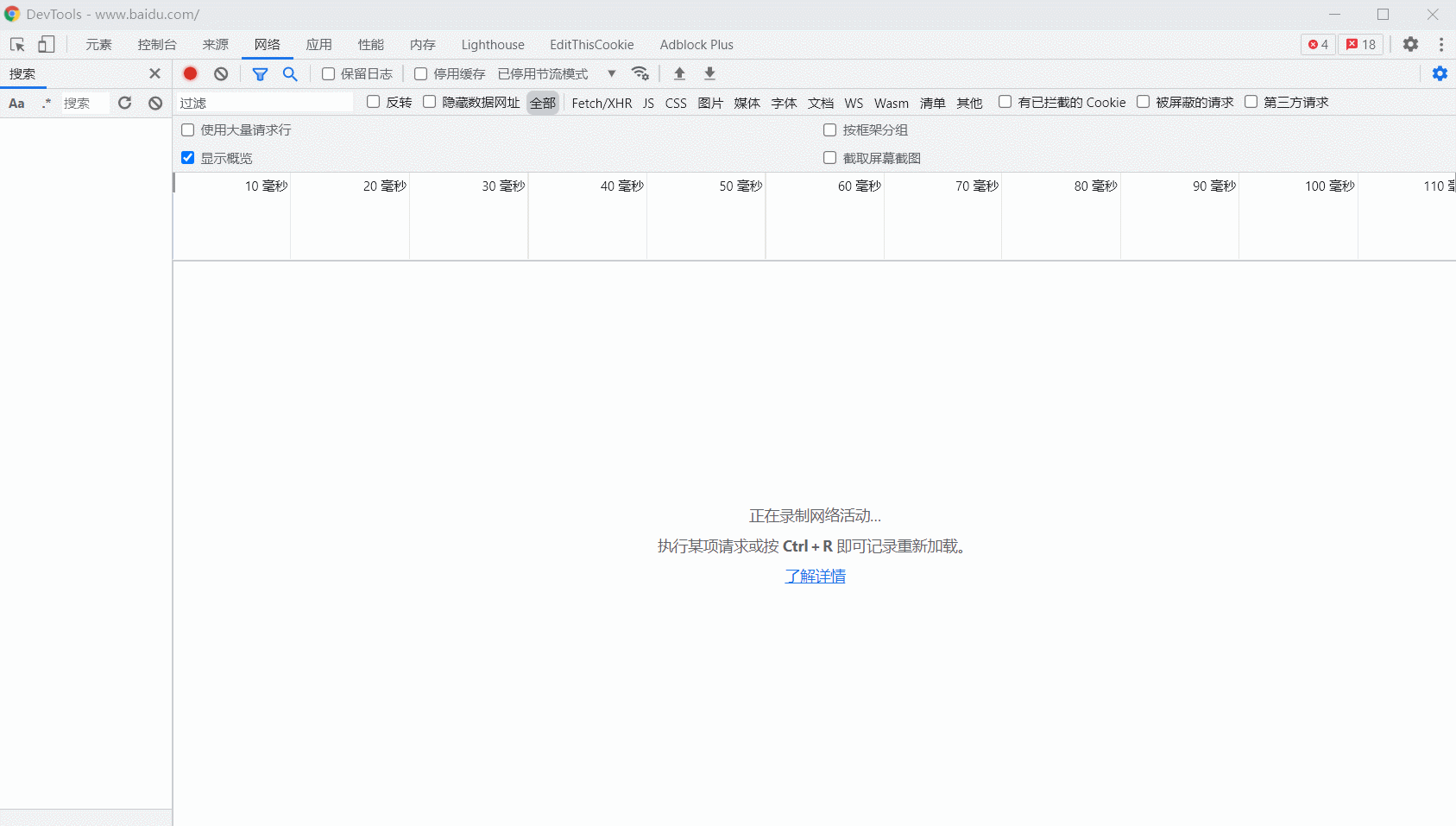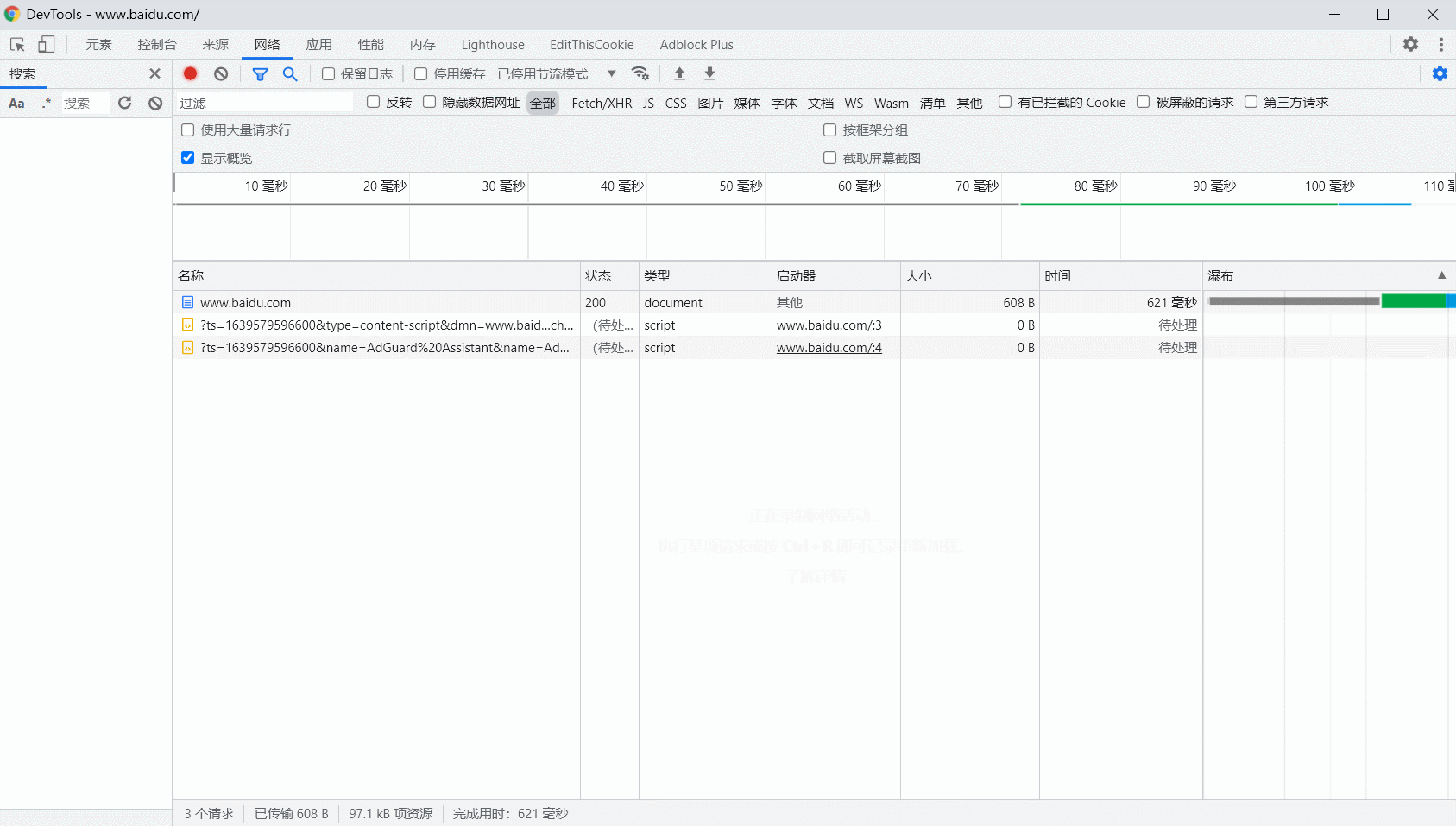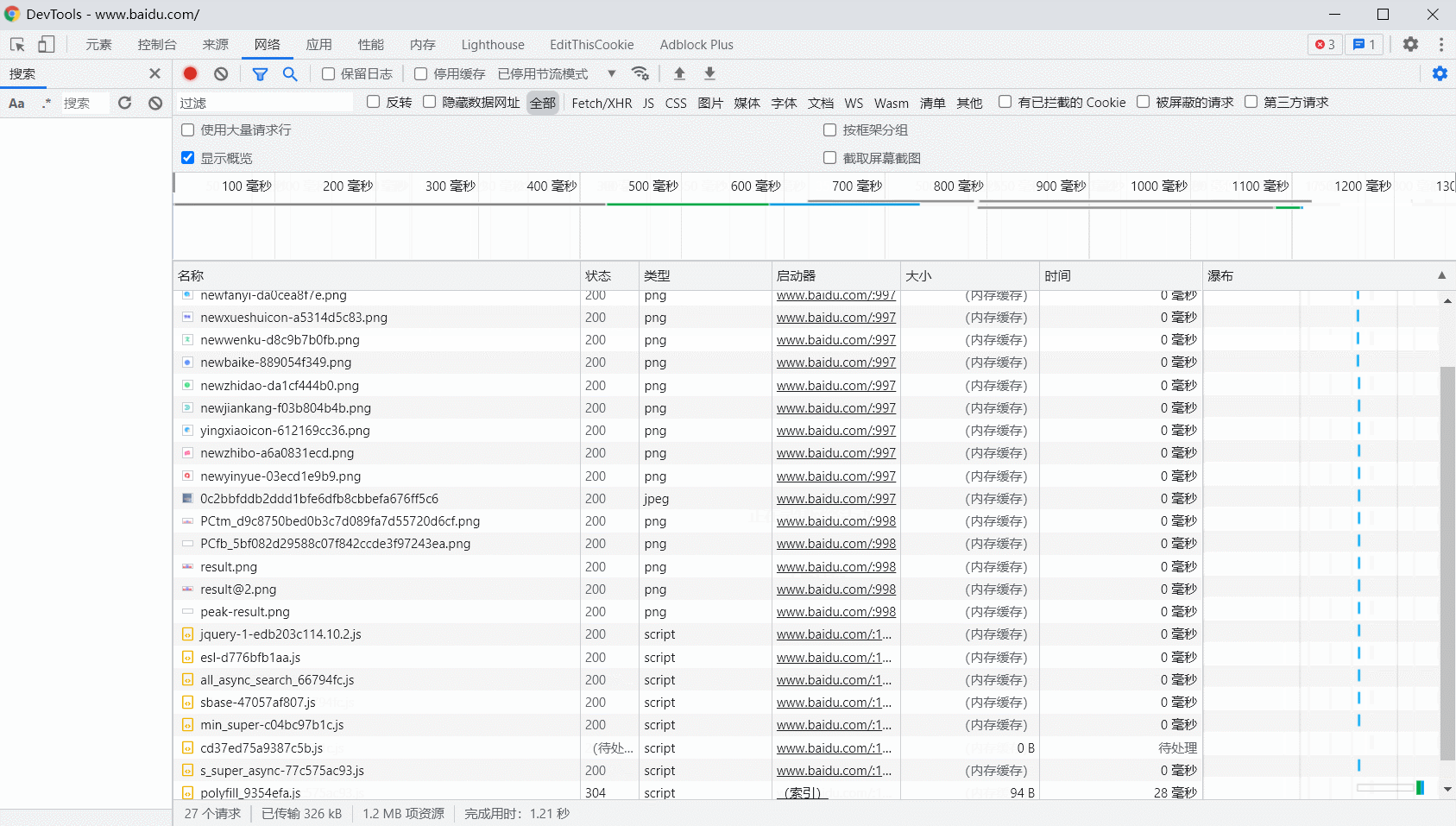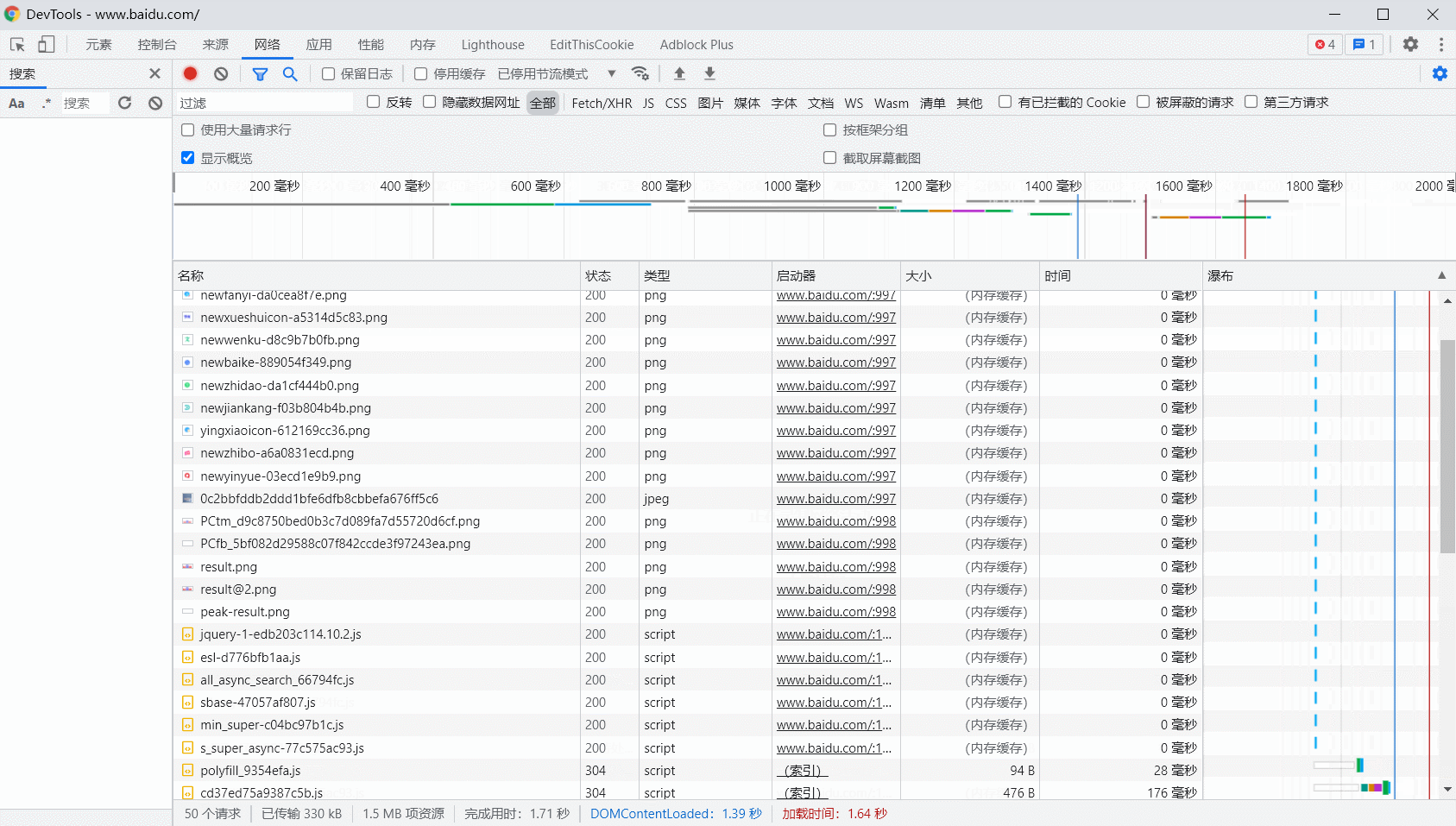
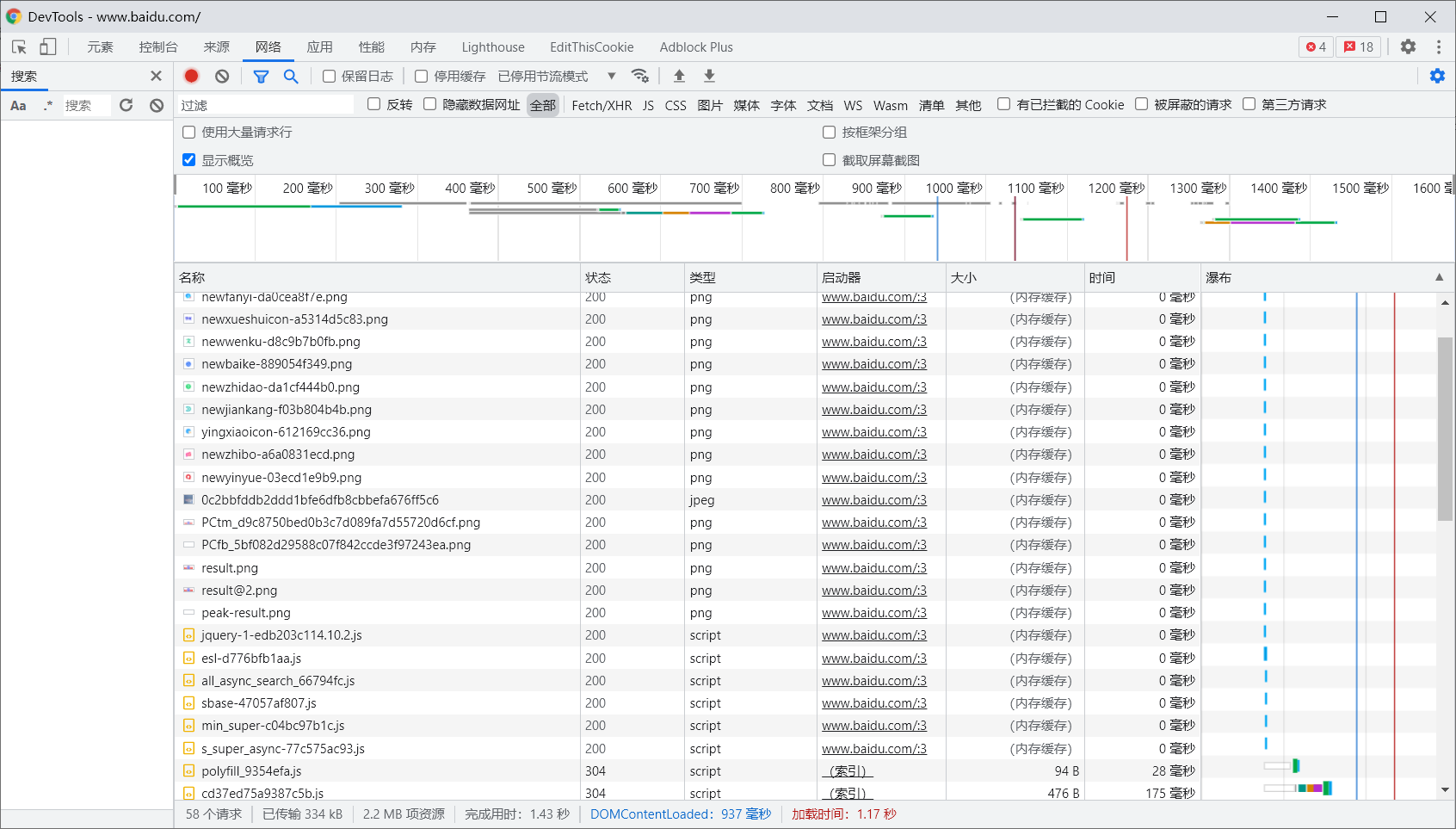

网络请求/响应列表的各列含义(一些项目并未完全显示,完全项目列表见上右图。以 www.baidu.com/ 为例):
- 名称 (Name):请求的名称。一般截取 URL 的最后一部分内容作为名称;
- 状态 (Status):响应的状态码。示例中为 200,即响应正常(可通过状态码判断请求的响应状态);
- 协议 (Protocol):请求的协议类型。示例中的 http/1.1 代表 HTTP 1.1 版本,h2 代表 HTTP2.0 版本;
- 类型 (Type):请求的文档类型。示例中的 document 表示请求了一个 HTML 文档;
- 启动器 (Initiator):标记发起请求的对象或进程——请求的来源;
- 大小 (Size):文件或请求到的资源大小(载入自缓存中资源将被标记为 from cache、内存缓存或磁盘缓存);
- 时间 (Time):从发起请求到获取响应的耗时;
- 瀑布 (Waterfall):网络请求/响应过程的可视化瀑布流。
单击请求/响应列表的各个条目,将展开更多详细信息: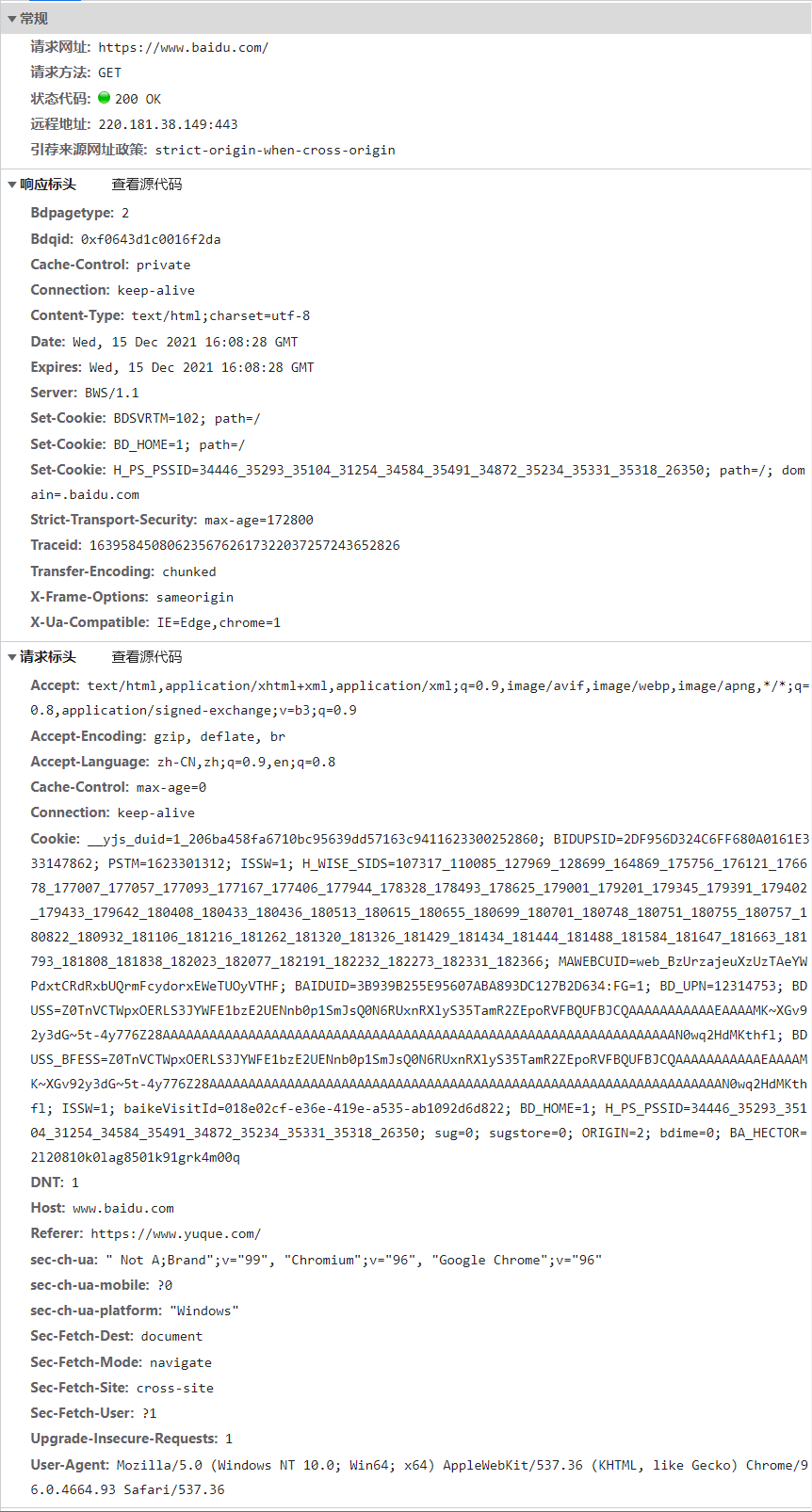
- 常规 (General):包含请求网址 (Request URL)、请求方法 (Request Method)、响应状态码 (Status Code)、远程服务器地址及端口号 (Remote Address)、Referrer 判别策略 (Referrer Policy)。
- 请求标头 (Request Headers):包含如浏览器标识、Cookie、Host 等信息,这些信息作为请求的一部分用于服务器判断请求的合法性并决定响应的内容;
响应标头 (Response Headers):包含服务器类型、文档类型、日期等信息,这些信息被浏览器接受并解析后用于网页的渲染与呈现。
请求
请求 (Request) 是由客户端发送的,用以触发服务器响应的的动作。由请求方法 (Request Method)、请求网址 (Request URL)、请求头 (Request Headers)、请求体 (Request Body) 四部分组成。
请求方法 (Request Method)
客户端请求服务端的方式,以 GET 和 POST 方法最常见。
GET 请求:用搜索引擎搜索关键词就产生了一个 GET 请求。GET 方法请求的数据将显式地包含在 URL 的参数中。如 https://www.baidu.com/s?wd=scrawler 中,此 URL 包含了请求的 query,其中的
wd=scrawler表示以“scrawler”作为关键词 (wd) 搜寻。理论上,GET 请求的数据大小没有限制,但随浏览器的不同而有差异(一般在 1024 字节内);- POST 请求:输入用户名与密码登录网站时,将通过 POST 请求以表单形式提交数据,包含在请求体中,而不体现在 URL 的 parameters 或 query 中,适用于敏感信息的传输或大文件的上传。理论上,用 POST 请求提交的数据大小不设上限,但受制于服务器或其负载能力。 | 请求名称 | 含义 | 描述 | | —- | —- | —- | | GET | 获取 | 请求指定的页面信息,并返回实体主体 | | HEAD | 报头 | 与 GET 请求类似,但返回的响应中无具体内容,用于获取报头 | | POST | 投递 | 将数据包含在请求体,常用于提交表单或上传文件,请求服务器处理数据(可能导致新资源的建立或旧资源的更新) | | PUT | 推送 | 用上传自客户端的数据取代指定文档内容 | | DELETE | 删除 | 请求服务器删除指定页面 | | CONNECT | 连接 | HTTP/1.1 协议中,为能够将连接改为管道方式的代理服务器预留的请求方法 | | OPTIONS | 选项 | 允许客户端查看服务器性能 | | TRACE | 回溯 | 回显服务器收到的请求用于测试或诊断 | | PATCH | 补丁 | 对 PUT 方法的补充,用于对已知资源进行局部更新 |
参见:菜鸟教程 - HTTP 请求方法。
请求网址 (Request URL)
可唯一确定期望请求资源的 URL 地址。参见上文的 URL 基本组成规范。
请求头 (Request Headers)
为服务器提供请求所需的附加信息,重要的有:
- Accept:请求报头域,指定客户端可接受的信息类型;
- Accept-Encoding:指定客户端可接受的内容编码方式;
- Accept-Language:指定客户端可接受的自然语言类型;
- Cookie:Cookie 存储在用户本地,与 Session 一起用于会话跟踪、辨别用户并维持当前会话。如登录需要用户名密码认证的网页后,Cookie 参与了登录状态信息的维持。后续的请求将带上 Cookie,使会话在相当长的一段时间内保持登录状态;
- Host:指定请求资源的主机 IP 及端口号(请求 URL 的原始服务器或网关位置。从 HTTP 1.1 开始,Host 是必须的);
- Referer:标识请求的来源。可用于服务器的来源统计、防盗链处理等;
- User-Agent:简称 UA,是用于服务器识别客户端的操作系统与浏览器类型及版本的特殊字符串头。指定爬虫的 UA 可实现浏览器的伪装;
- Content-Type:在 HTTP 协议消息头中,用于表示具体请求的媒体类型。亦称为互联网媒体类型 (Internet Media Type) 或 MIME 类型。
请求体 (Request Body)
包含了 POST 请求时的表单数据。对于 GET 请求,请求体为空。
在一般网站的登录页中,填写用户名与密码并点击登录按钮后,数据将以表单的形式提交。这时的 POST 请求中,Request Headers 的 Content-Type 内容应指定为 application/x-www-form-urlencoded。
POST 请求中,Content-Type 和可提交的数据类型关系如下表:
| Content-Type | 可提交的数据类型 |
|---|---|
| text/html | HTML 数据 |
| text/xml | XML 数据 |
| application/x-www-form-urlencoded | 表单数据 |
| multipart/form-data | 表单文件 |
| application/x-javascript | JavaScript 文件 |
| application/json | 序列化的 JSON 数据 |
| image/gif | GIF 图片 |
| image/jpeg | JPEG 图片 |
应使用正确的 Content-Type 构造爬虫的 POST 请求、了解各种请求库各个参数使用的 Content-Type 类型,否则将无法得到预期的响应。
响应
响应 (Response) 是服务器得到请求并处理后,返回给客户端的内容。包括响应状态码 (Response Status Code)、响应头 (Response Headers) 和响应体 (Response Body) 三部分。
响应状态码 (Response Status Code)
由三个十进制数字组成,指示服务器的响应状态。根据第一个十进制数字将状态码分为五类:
- 信息响应 (100~199):服务器收到请求,需要请求者继续执行操作;
- 成功响应 (200~299):操作被服务器成功接收并处理;
- 重定向 (300~399):重定向后需要进一步的操作;
- 客户端错误 (400~499):请求包含语法错误或无法完成;
- 服务器错误 (500~599):服务器在处理请求时发生了错误。 | 状态码 | 英文名 | 含义 | 描述 | | —- | —- | —- | —- | | 100 | Continue | 继续 | 服务器已接收到请求的一部分,正在等待其余部分。请求者应当继续请求 | | 101 | Switching Protocols | 切换协议 | 请求者已要求服务器切换协议,服务器已确认并准备切换 | | 200 | OK | 成功 | 服务器已成功处理了请求 | | 201 | Created | 已创建 | 请求服务器成功并创建了新资源 | | 202 | Accepted | 已接收 | 服务器已接收请求,但尚未处理 | | 203 | Non-Authoritative Information | 非授权信息 | 服务器已成功处理了请求,但返回的信息可能来自另一个源(返回的 meta 信息不在原始的服务器中,而是一个副本) | | 204 | No Content | 无内容 | 服务器成功处理了请求,但未返回任何内容 | | 205 | Reset Content | 重置内容 | 服务器成功处理了请求,且内容被重置 | | 206 | Partial Content | 部分内容 | 服务器成功处理了部分请求 | | 300 | Multiple Choices | 多种选择 | 针对请求,服务器可执行多种操作 | | 301 | Moved Permanently | 永久移动 | 即永久重定向,请求的网页已永久移动到新 URI(浏览器会自动定向到新返回的 URI) | | 302 | Found | 临时移动 | 即暂时重定向,请求的网页暂时跳转到其他页面 | | 303 | See Other | 查看其他位置 | 若原始请求方法为 POST,重定向的目标文档应用 GET 获取 | | 304 | Not Modified | 未修改 | 此次请求返回的网页未经修改,继续使用上次的资源 | | 305 | Use Proxy | 使用代理 | 请求者应该使用代理访问该网页 | | 307 | Temporary Redirect | 临时重定向 | 临时从其他位置响应请求的资源(使用 GET 请求重定向) | | 400 | Bad Request | 错误请求 | 服务器无法解析该请求 | | 401 | Unauthorized | 未授权 | 请求没有进行身份验证或验证未通过 | | 403 | Forbidden | 禁止访问 | 服务器拒绝此请求 | | 404 | Not Found | 未找到 | 服务器找不到请求的网页 | | 405 | Method Not Allowed | 方法禁用 | 服务器禁用了请求中指定的方法 | | 406 | Not Acceptable | 不接收 | 无法使用请求的内容响应请求的网页 | | 407 | Proxy Authentication Required | 需要代理授权 | 请求者需要使用代理授权 | | 408 | Request Time-out | 请求超时 | 服务器请求超时 | | 409 | Conflict | 冲突 | 服务器在完成请求时发生冲突 | | 410 | Gone | 已删除 | 请求的资源已永久删除 | | 411 | Length Required | 需要有效长度 | 服务器不接收不含有效内容长度标头字段的请求 | | 412 | Precondition Failed | 未满足前提条件 | 服务器未满足请求者在请求中设置的某一个前提条件 | | 413 | Request Entity Too Large | 请求实体过大 | 请求实体过大,超出服务器的处理能力 | | 414 | Request-URI Too Large | 请求 URI 过长 | 请求 URI 过长,服务器无法处理 | | 415 | Unsupported Media Type | 不支持类型 | 请求格式不被请求页面支持 | | 416 | Requested Range Not Satisfiable | 请求范围不符 | 页面无法提供请求的范围 | | 417 | Expectation Failed | 未满足期望值 | 服务器未满足期望请求标头字段的要求 | | 500 | Interal Server Error | 服务器内部错误 | 服务器遇到错误,无法完成请求 | | 501 | Not Implemented | 未实现 | 服务器不具备完成请求的能力 | | 502 | Bad Gateway | 错误网关 | 服务器作为网关或代理,接收到上游服务器的无效响应 | | 503 | Service Unavailable | 服务不可用 | 服务器目前无法使用 | | 504 | Gateway Time-out | 网关超时 | 服务器作为网关或代理,没有及时从上游服务器接收到请求 | | 505 | HTTP Version Not Supported | HTTP 版本不支持 | 服务器不支持请求中使用的 HTTP 协议版本 |
爬虫可根据响应状态码执行不同的行为。
响应头 (Response Headers)
为客户端提供接收响应所需的附加信息,重要的有:
- Date:标识响应的产生时间;
- Last-Modified:指定资源的最后修改时间;
- Content-Encoding:指定响应内容的编码类型;
- Server:描述服务器的名称、版本号等信息;
- Content-Type:指定返回数据的文档类型。其值与文档类型的对应关系参见请求体 (Request Body) 的表格;
- Set-Cookie:设置 Cookie 至本地。下次的请求应带上该 Cookie 内容;
- Expires:指定响应的过期时间。过期前再次访问相同的内容时,代理服务器或浏览器将直接从缓存中加载内容。可降低服务器负载、缩短加载时间。
响应体 (Response Body)
响应的正文数据,是响应的主体。请求网页时,响应体应为网页的 HTML 代码;请求图片时,响应体应为图片的二进制数据。用爬虫请求网页时,解析的就是响应体内容:通过响应体得到网页源代、JSON 数据等,然后从中获取目标内容。
可在已获取特定 URL 请求列表的浏览器开发者工具中,选择一个请求,选择展开窗口的预览 (Preview)项目,即可查看响应体内容。以 https://www.baidu.com/ 为例: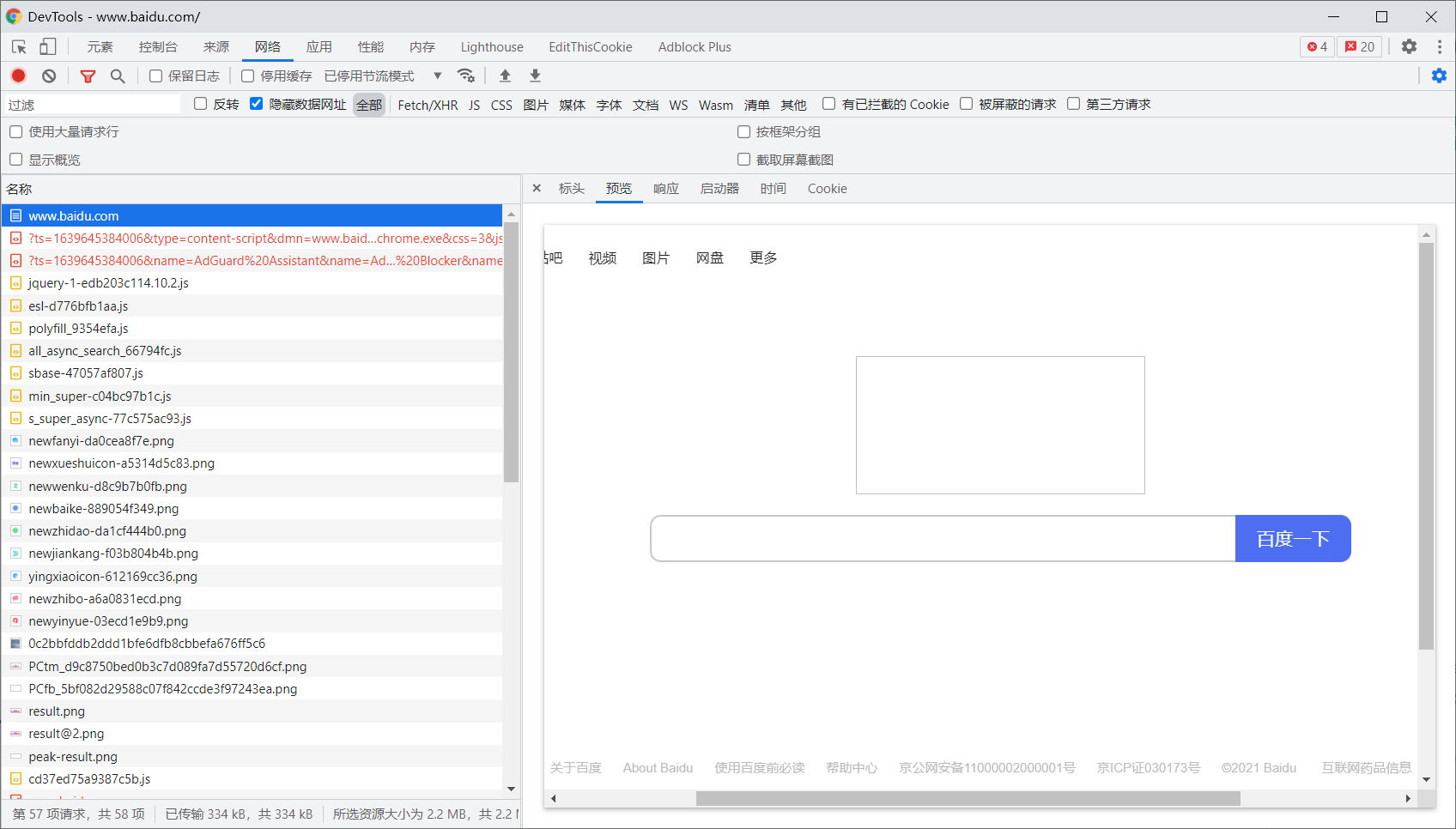

若有收获,就点个赞吧
0 人点赞
