什么是Stream流
Java 8 API添加了一个新的抽象称为Stream流,可以以一种声明的方式处理数据。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果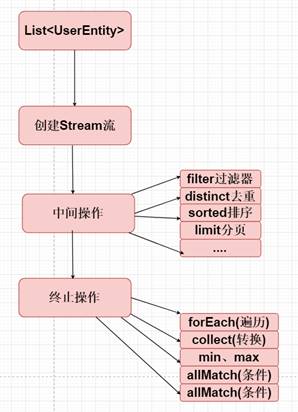
Stream流创建方式
在 Java 8 中, 集合接口有两个方法来生成流:
- stream() − 为集合创建串行流,采用单线程执行。
- parallelStream() − 为集合创建并行流,采用多线程执行。
parallelStream效率比Stream要高
ArrayList<UserEntity> userEntities = new ArrayList<>();userEntities.add(new UserEntity("tifa", 16));userEntities.add(new UserEntity("Aerith", 22));userEntities.add(new UserEntity("Cloud", 24));userEntities.stream();userEntities.parallelStream();
并行流与串行流区别:
串行流:单线程的方式操作; 数据量比较少的时候。
并行流:多线程方式操作;数据量比较大的时候,原理:
Fork join 将一个大的任务拆分n多个小的子任务并行执行,最后在统计结果,有可能会非常消耗cpu的资源,确实可以提高效率。
常用方法
ForEach(遍历)
Stream 提供了新的方法 ‘forEach’ 来迭代流中的每个数据。forEach是最终操作
Random random = new Random();random.ints().limit(10).forEach(System.out::println);
Collect(收集)
接收一个Collector实例,将流中元素收集成另外一个数据结构
List<People> list = Arrays.asList(new People("tifa",16),new People("Aerith", 22),new People("cloud",24));//list集合转为setlist.stream().collect(Collectors.toSet()).forEach(System.out::println);//list转为map// value 为对象 people -> people jdk1.8返回当前对象list.stream().collect(Collectors.toMap(People::getName, people->people)).forEach((k,v)->{System.out.println("key:"+k+" value:"+v);});
Filter(过滤)
过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于中间操作,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。
stringList.stream().filter((s) -> s.startsWith("a")).forEach(System.out::println);//aaa2 aaa1
forEach 是为 Lambda 而设计的,保持了最紧凑的风格。而且 Lambda 表达式本身是可以重用的,非常方便。
Sorted(排序)
排序是一个 中间操作,返回的是排序好后的 Stream。如果你不指定一个自定义的 Comparator 则会使用默认排序。
stringList.stream().sorted().filter((s) -> s.startsWith("a")).forEach(System.out::println);// aaa1 aaa2
需要注意的是,排序只创建了一个排列好后的Stream,而不会影响原有的数据源,排序之后原数据stringCollection是不会被修改的:
System.out.println(stringList);// ddd2, aaa2, bbb1, aaa1, bbb3, ccc, bbb2, ddd1
多字段排序
List<类> rankList = new ArrayList<>(); 代表某个集合//返回 对象集合以类属性一升序排序rankList.stream().sorted(Comparator.comparing(类::属性一));//返回 对象集合以类属性一降序排序 注意两种写法rankList.stream().sorted(Comparator.comparing(类::属性一).reversed()); //先以属性一升序,然后对结果集进行属性一降序rankList.stream().sorted(Comparator.comparing(类::属性一, Comparator.reverseOrder())); //以属性一降序//返回 对象集合以类属性一升序 属性二升序rankList.stream().sorted(Comparator.comparing(类::属性一).thenComparing(类::属性二));//返回 对象集合以类属性一降序 属性二升序 注意两种写法rankList.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二));//先以属性一升序,升序结果进行属性一降序,再进行属性二升序rankList.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()).thenComparing(类::属性二));//先以属性一降序,再进行属性二升序//返回 对象集合以类属性一降序 属性二降序 注意两种写法rankList.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二,Comparator.reverseOrder()));//先以属性一升序,升序结果进行属性一降序,再进行属性二降序rankList.stream().sorted(Comparator.comparing(类::属性一,Comparator.reverseOrder()).thenComparing(类::属性二,Comparator.reverseOrder()));//先以属性一降序,再进行属性二降序//返回 对象集合以类属性一升序 属性二降序 注意两种写法rankList.stream().sorted(Comparator.comparing(类::属性一).reversed().thenComparing(类::属性二).reversed());//先以属性一升序,升序结果进行属性一降序,再进行属性二升序,结果进行属性一降序属性二降序rankList.stream().sorted(Comparator.comparing(类::属性一).thenComparing(类::属性二,Comparator.reverseOrder()));//先以属性一升序,再进行属性二降序
Map(映射)
中间操作 map 会将元素根据指定的 Function 接口来依次将元素转成另外的对象。
可以通过map来将对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
stringList.stream().map(String::toUpperCase).sorted((a, b) -> b.compareTo(a)).forEach(System.out::println);// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "AAA2", "AAA1"
stream中map和flatMap的区别:
map只是一维 1对1 的映射
flatmap可以将一个2维的集合映射成一个一维,相当于他映射的深度比map深了一层 ,所以名称上就把map加了个flat 叫flatmap
案例:对给定单词列表 [“Hello”,”World”],想返回列表[“H”,”e”,”l”,”o”,”W”,”r”,”d”]
使用map
String[] words = new String[]{"Hello","World"};Arrays.stream(words).map(word -> word.split("")).distinct().collect(toList()).forEach(System.out::print);/**输出结果为一个包含两个string的list*[Ljava.lang.String;@71f0b72e[Ljava.lang.String;@7a34f66a*/
这个实现方式是有问题的,传递给map方法的lambda为每个单词生成了一个String[]。因此,map返回的流实际上是Stream<String[]>类型的。你真正想要的是用Stream来表示一个字符串。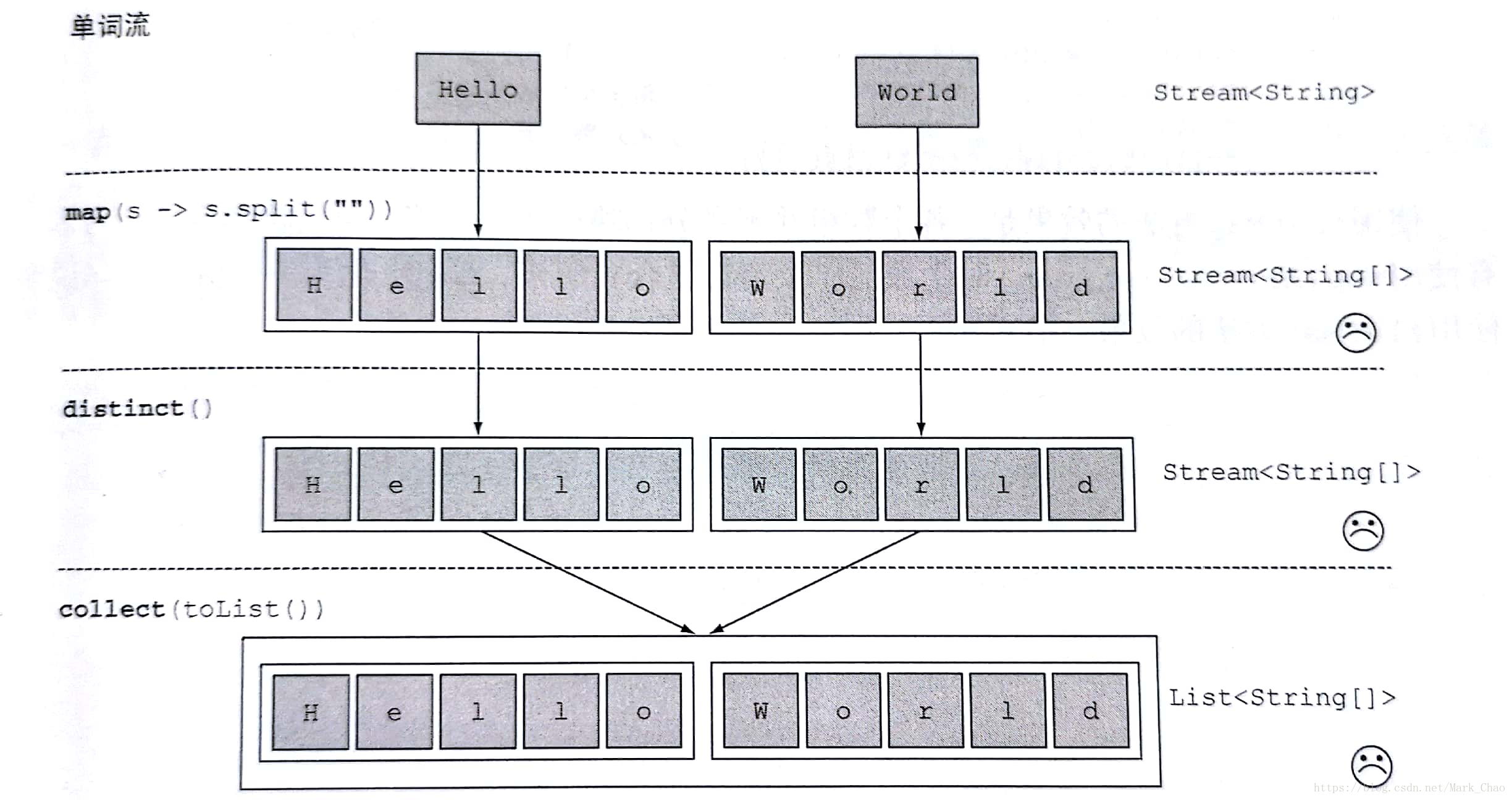
使用flatMap(对流扁平化处理)
String[] words = new String[]{"Hello","World"};Arrays.stream(words).map(word -> word.split("")).flatMap(Arrays::stream).distinct().collect(toList()).forEach(System.out::print);//输出结果为HeloWrd
使用flatMap方法的效果是,各个数组并不是分别映射一个流,而是映射成流的内容,所有使用map(Array::stream)时生成的单个流被合并起来,即扁平化为一个流。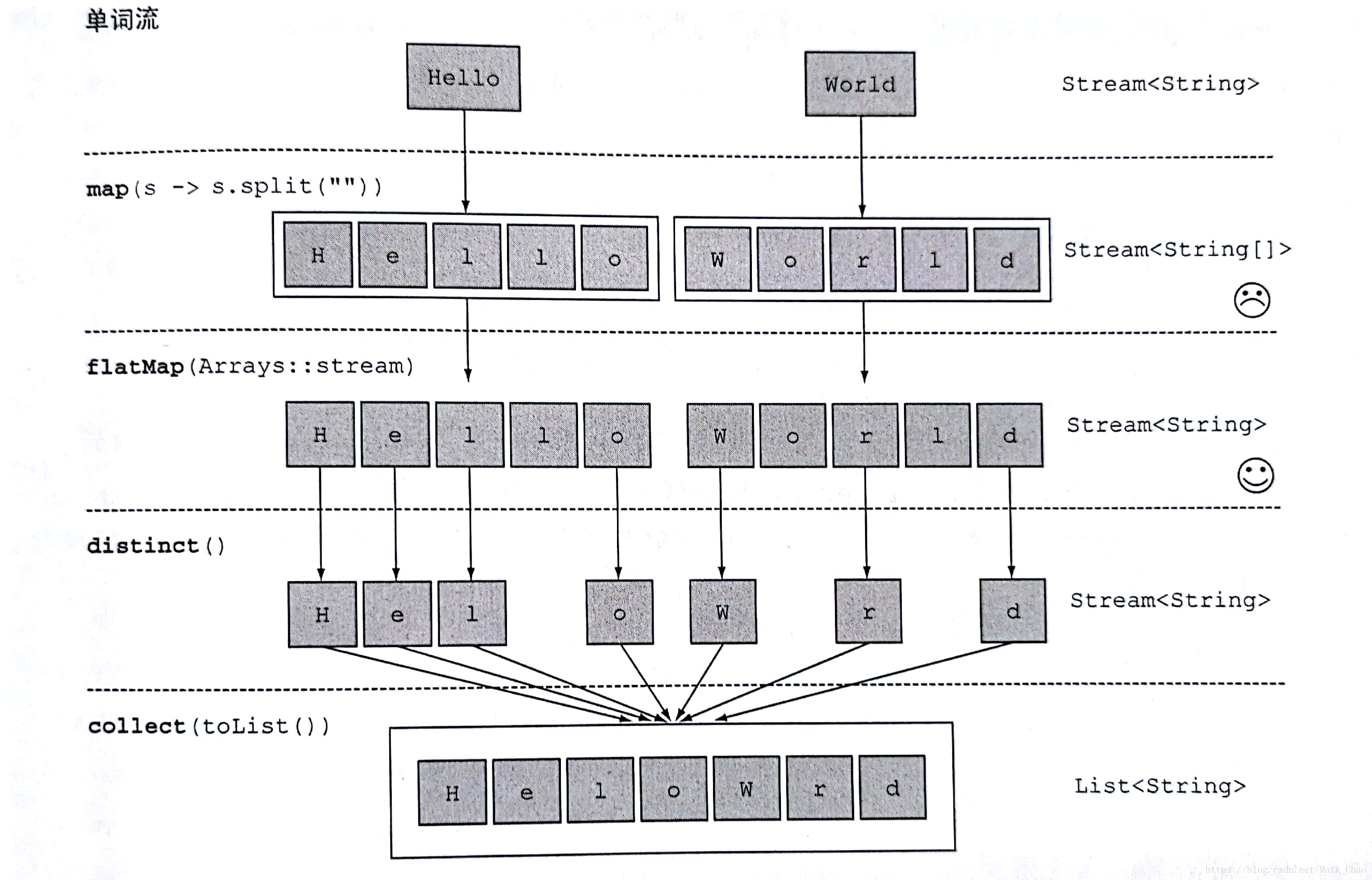
Match(匹配)
Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配整个Stream。所有的匹配操作都是 最终操作 ,并返回一个 boolean 类型的值。
- anyMatch表示,判断的条件里,任意一个元素成功,返回true
- allMatch表示,判断条件里的元素,所有的都是,返回true
noneMatch跟allMatch相反,判断条件里的元素,所有的都不是,返回true
boolean anyStartsWithA =stringList.stream().anyMatch((s) -> s.startsWith("a"));System.out.println(anyStartsWithA); // trueboolean allStartsWithA =stringList.stream().allMatch((s) -> s.startsWith("a"));System.out.println(allStartsWithA); // falseboolean noneStartsWithZ =stringList.stream().noneMatch((s) -> s.startsWith("z"));System.out.println(noneStartsWithZ); // true
Count(计数)
计数是一个 最终操作,返回Stream中元素的个数,返回值类型是 long
long startsWithB =stringList.stream().filter((s) -> s.startsWith("b")).count();System.out.println(startsWithB); // 3
Reduce(规约)
这是一个 最终操作 ,允许通过指定的函数来将stream中的多个元素规约为一个元素,规约后的结果是通过Optional 接口表示的:
Optional<String> reduced =stringList.stream().sorted().reduce((s1, s2) -> s1 + "#" + s2);reduced.ifPresent(System.out::println);//aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2
注: 这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于Integer sum = integers.reduce(0, (a, b) -> a+b);也有没有起始值的情况,这时会把 Stream 的前面两个元素组合起来,返回的是 Optional。
// 字符串连接,concat = "ABCD"String concat = Stream.of("A", "B", "C", "D").reduce("", String::concat);// 求最小值,minValue = -3.0double minValue = Stream.of(-1.5, 1.0, -3.0, -2.0).reduce(Double.MAX_VALUE, Double::min);// 求和,sumValue = 10, 有起始值int sumValue = Stream.of(1, 2, 3, 4).reduce(0, Integer::sum);// 求和,sumValue = 10, 无起始值sumValue = Stream.of(1, 2, 3, 4).reduce(Integer::sum).get();// 过滤,字符串连接,concat = "ace"concat = Stream.of("a", "B", "c", "D", "e", "F").filter(x -> x.compareTo("Z") > 0).reduce("", String::concat);
上面代码例如第一个示例的 reduce(),第一个参数(空白字符)即为起始值,第二个参数(String::concat)为 BinaryOperator。这类有起始值的 reduce() 都返回具体的对象。而对于第四个示例没有起始值的 reduce(),由于可能没有足够的元素,返回的是 Optional,请留意这个区别。
groupingBy(分组)
Map<String,List<DashboardResponseDto>> grouped = list.stream().collect(Collectors.groupingBy(e -> String.format("%s&%s",e.getLatitude(),e.getLongitude()));
limit和skip
Limit
从头开始获取,只取用前n个
参数n是一个long型,如果集合当前长度大于参数则进行截取,否则不进行操作
limit方法是一个延迟方法,只是对流中的元素进行截取,返回的是一个新的流,所以可以继续调用Stream流中的其他方法
Skip
就是跳过,跳过前n个
如果流的当前长度大于n,则跳过前n个,否则会得到一个长度为0的空流
stream.skip(2).limit(1).forEach(System.out::Println);

若有收获,就点个赞吧
0 人点赞
