Cache 架构
简介
Apache Traffic Server不仅是HTTP代理服务器, 还是HTTP缓存服务器。Traffic Server可以缓存任何字节流数据, 不过目前仅支持通过HTTP协议来传输这些字节流数据。当这样的一个字节流被缓存住时(还有相关的HTTP协议头)我们称之为缓存中的一个对象。每个对象可以通过全局唯一的缓存key的来定位。
这篇文档旨在对Traffic Server缓存系统的基本框架和实现细节进行一下描述。为了帮助理解cache系统的内部机制, 我们也会对cache系统的配置做一些简单的讨论。这篇文当对从事TrafficServer核心开发以及插件开发的人员都会很有帮助。这里假定读者已经熟悉了管理员指南这部分内容,特别是Http反向代理缓存、缓存配置以及相关的配置文件和具体的取值。
遗憾的是内部的一些术语并不是特别一致, 因此为了试图创造一些一致性,这篇文档会经常以不同的形式来使用这些术语。
Cache的布局
接下来的章节会介绍持久化下来的cache数据是如何组织的。Traffic Server将其持久化存储设备看成常规字节的集合, 假定存储设备上没有其他结构。而且Traffic Server不会使用操作系统上面的文件系统功能, 一个文件仅仅是用来标识出一个字节集合。
Cache存储
Traffic Server使用的裸存储设备定义在配置文件storage.config中。文件中的每一行定义了一个具有一致性存储特征的cache设备。
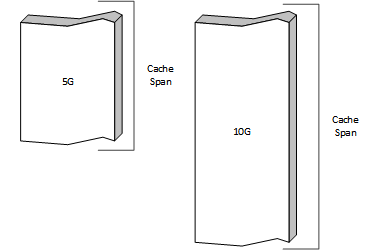
Traffic Server的管理员可以根据实际情况将存储空间组织成一系列分卷,这些分卷定义在volume.config配置文件中, cache分卷是管理存储配置的基本单位。
Cache分卷的容量可以通过存储百分比来定义, 也可以定义为一个绝对的数值。默认情况下,每一个cache分卷定义的存储空间都会分散到所有的cache设备中,这是出于健壮性的考虑(一个盘有问题不会影响这个cache分卷在其他盘上的存储空间)。cache分卷和cache设备的交集是cache带,每个cache设备会被切分成若干个cache带, 而每个cache分卷是由一系列来自不同的cache设备中的cache带组成。
如果Cache分卷按下面这样定义:

那么对于前面定义的Cache设备的实际布局将会如下所示:
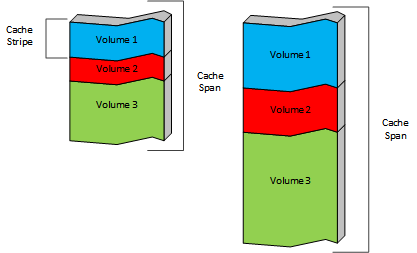
Cache带是cache设计实现过程中的最基本的单位。一个缓存对象会被完整的存储在单一的Cache带中,因此也就存储在单一的Cache设备中,对象从不跨Cache设备或跨Cache分卷存储。每一个对象会通过回源的URL来计算一个hash值,然后得到对应的Cache分卷。可以通过配置hosting.config文件来指定那些域名的数据存储在哪些Cache分卷中。此外,从4.0.1版本开始可以指定一个Cache分卷包含哪些Cache设备(也就指定了Cache带)。
traffic_server进程启动的时候会根据storage.config和cache.config配置文件来计算Cache设备, Cache分卷, Cache带的布局和结构,因此对这些文件的修改会导致对原有cache数据的全部重新校验。
Cache带数据结构
Traffic Server将一个Cache带代表的存储区域看做一个一致性的字节集合,而在内部会对每一个Cache带进行独立地对待。这一节描述的数据结构对于每一个Cache带都是一样的。在代码中会用Vol类来代表Cache带, 用CacheVol来代表Cache分卷,一个Cache分卷由位于所有不同设备上的Cache带组成。
在对一个对象进行操作之前必须先明确这个对象所在的`Cache带`, 因为每个`Cache带`分别拥有着独立的索引空间。如果缓存对象所在的`Cache带`发生变化的话那么这个缓存对象也将失效, 因为在新的`Cache带`中并没有这个缓存对象的索引。
Cache索引
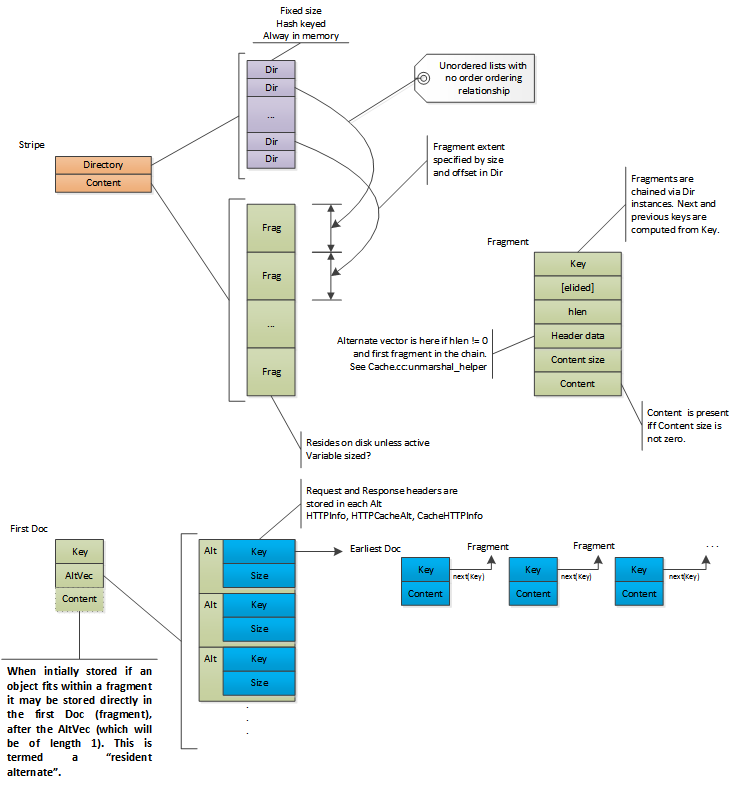
Cache带中存储的内容是通过索引来进行定位的,索引中的每一个元素我们称之为目录项,代码中使用Dir来表示。每一个目录项代表了cache中一段连续的存储空间。这里会涉及到各种概念包括分片、分段、文档等。本文会使用”分片”这个术语,这也是代码中最常用到的概念。”文档”这个术语用来表示一个分片的头部数据。目录项被视为通过Cache ID做为key而计算得到的哈希值。查看索引探测这一节可以看到如何通过Cache ID来定位一个目录项。默认情况下Cache ID是通过对象的URL来计算得到。
索引数据会被持久化在内存中,这也意味着目录项必须足够的小(目前只有10个字节),这也将导致可存储的信息不够多。从另外一个方面来考虑,绝大多数的cache miss情况是不需要任何的磁盘I/O操作的,这是一个很大的性能收益。
此外,当一个Cache带初始化之后,那么它对应的索引空间大小也就明确下来,而且不会再改变。索引空间的大小和Cache带的大小相关(线性),因此Traffic Server的内存占用也会和磁盘大小相关。由于索引空间的总大小是不变的,也就意味着占用的内存大小也是固定的,因此当Traffic Server在cache中存储更多的对象的时候并不会消耗额外的内存。如果有足够的内存保证Traffic Server在空白存储的情况下正常运行,那么在cache存满的情况下仍然可以正常运行。
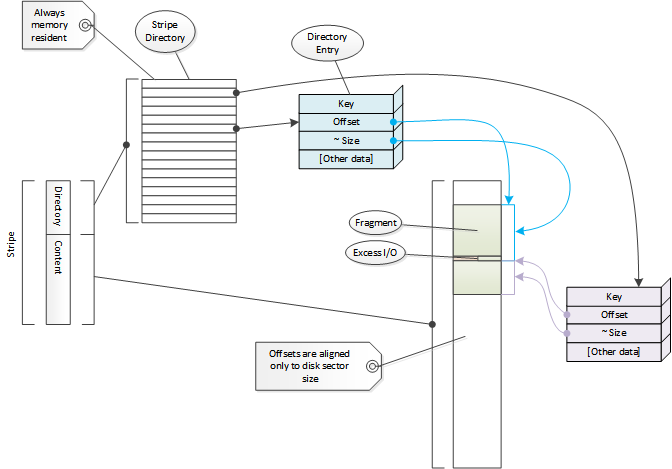
每一个目录项中都保存了在Cache带中的偏移量和大小,目录项中存储的大小是一个能够包含分片中实际数据大小的粗略值,实际的大小保存在分片的头部区域中(在磁盘上)。
只有通过读取磁盘才能得到HTTP头部保存的数据,这部分数据中保存着对象的原始URL。
索引空间是通过哈希表来组织的,以链表的方式来解决冲突。由于每个目录项很小,因此目录项会被直接作为哈希桶的链表头。
通过对索引中的所有项进行分组的方式来实现链表,第一层的分组就是索引桶,包含了固定数目(目前是4)的目录项。每个索引桶中的第一个目录项将作为这个哈希桶的根。
The term “bucket” is used in the code to mean both the conceptual bucket for hashing and for astructural grouping mechanism in the directory and so these will be qualified as needed todistinguish them. The unqualified term “bucket” is almost always used to mean the structuralgrouping in the directory.
多个索引桶会集成为段,一个Cache带中的所有段拥有相同数目的索引桶。在计算一个Cache带有多少个段时,要保证每个段要拥有尽可能多的索引桶数目,同时要保证一个段拥有的目录项个数不能超过65535。
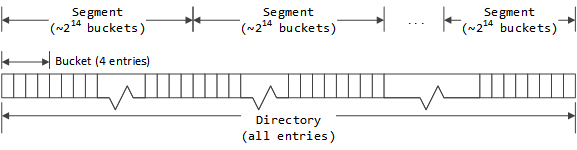
同一个段中的每个目录项以链表的形式组织起来,目录项会体现出向前和向后的索引。由于一个段中的目录项不会超过65535,因此16位足以表示出索引值。在Cache带的头部会保存一个目录项数组,数组的每一项是对应段中的空闲目录项的链表头。Active entries are stored via the bucket structure. 当一个Cache带初始化的时候, 每个目录桶中的第一个目录项会被清零(标示为未使用),而所有的其他项会被放入对应的段空闲链表中。这就意味着每个目录桶中的第一项会被当做哈希桶的第一项,它们不会被放入空闲列表中,而是会被清零。目录桶中的其他项会被优先选择进入对应的哈希桶中,但不是强制的。每个段中的空闲目录项链表在初始化的时候会让每个目录桶中的其他项顺序的添加进来,先是每个目录桶中的第二项,然后是第三项、第四项。由于空闲链表采用的是先进先出的策略,所以在选择的时候会先选择所有目录痛的第四项,然后才是第三项,以此类推。当需要从一个目录桶中分配出一个新的目录项时,会从第一项到最后一项顺序查找,这样可以让目录桶中的目录项尽可能的本地化(通过Cache ID计算得到的哈希桶会尽量选择同一个目录桶中的目录项)。
目录桶是存储格式上的划分,每个桶中有4项;而哈希桶则是查找时使用的数据结构,每个哈希桶中的所有冲突项以链表的形式组织。计算时哈希桶和目录桶是一一对应的,但是哈希桶中的冲突项可能会多于4,因此这个时候会将其他目录桶中的空现项拿来用连到本哈希桶的链表中。哈希桶在组织链表时会优先选择本哈希桶对应的目录桶中的这4个目录项,然后才会去使用其他目录桶中的空闲项。
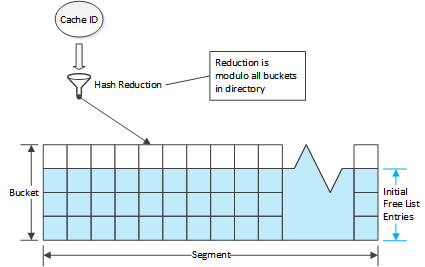
一个在使用中的目录项会从空闲链表中移除,当这个目录项不在使用时会重新回到空闲链表。当需要把一个分片设置对应的目录项时,会通过cache ID来定位所在的哈希桶(也会拿来定位所在的段和目录桶),如果对应的目录桶中的第一项并未使用,那么会直接拿来给这个分片使用,否则会查看一下这个目录桶中的其他项,如果有空闲则会拿来使用。如果还是找不到空闲项,将会会使用空闲链表中的第一项,这一项会被链到哈希桶的冲突链表中,以确保可以通过cache ID来查找到。
存储布局
存储布局指的是Cache带的元信息,由三部分组成 - 头部、索引数据、尾部。Cache带的元信息存储了两份,头部和尾部在代码中使用的是相同的数据结构VolHeaderFooter,这个数据结构的尾部包含一个变化长度的数组,这个数组用来保存每个段的空闲目录链表的表头,每一项包含对应段中空闲链表的第一项的索引,尾部其实是头部的拷贝,但不包含每个段的空闲链表数组。因此头部的大小会受目录项大小影响,但是尾部不会。
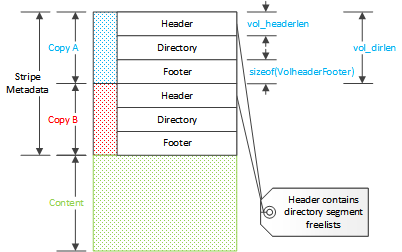
每一个Cache带包含以下几个能够描述基本布局的变量:
skip
Cache带数据的开始位置,物理磁盘上最开始的一段数据会被保留下来,这样可以避免对操作系统造成一些干扰,这个值也代表了其他的Cache带在Cache设备上的偏移量。
start
Cache带元信息之后的数据区在磁盘上的偏移量。
length
Cache带的字节大小,Vol::len。
data length
Cache带上内容区的总块数(512字节为一块),Vol::data_blocks。
这里必须要留意代码中提到的长度和大小这些词,因为在不同的地方会分别用刀三种不同的单位(字节,cache块,存储块)。
索引区的总大小(目录项的个数)的计算方法是用Cache带的大小除以平均对象大小来得到,索引区会消耗等量大小的内存,如果cache存储变大那么Traffic Server消耗的内存也就越多,平均对象大小默认是8000字节,可以通过proxy.config.cache.min_average_object_size来配置。增加平均对象大小会减少索引区对内存的占用,同时也意味着cache中能够存储的不同对象的数量也会减少。
磁盘上的内容区域保存真正的对象数据,内容区域会被当做一个环形的缓冲区,新对象会覆盖掉最早cache下来的对象。新的缓存对象在Cache带中写到的位置被称为写光标,这意味着写光标到达的区域所保存的原来的对象将会被淘汰,即便这个对象还没有过期。当一个在磁盘上的对象被覆盖时,并不会立即的检测到因为索引并没有做更新,而是在后面读取对象分片的时候才会检测到失败。
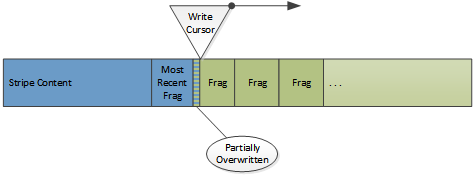
磁盘上的cache数据从来不会更新
这是一个需要特别注意的事情,更新操作(对于收到304响应对过期对象进行刷新)实际上就是将对象的新拷贝写到写光标的位置。The originals are left as “dead” space which will be consumed when the write cursor arrives at that disk location.当Cache带中的索引发生更新操作时(内存中),cache上的原有分片数据将失效,这也是比较常见的存储管理手段。当需要从cache中删除一个对象时,只需要更新一下索引即可,不需要其他的操作,特别是不需要任何的I/O操作。
对象数据结构
每个对象会存储两种类型的数据,元数据和内容数据。元数据包括对象的HTTP header和描述信息,而内容数据包含对象的真正内容,发送给客户端的字节流。
cache中的对象用Doc这个数据结构来表示,Doc可以认为是分片的头部数据,而且会存储在每个分片的开始位置(对象的每个分片都是一个Doc)。对象的第一个分片被称为first Doc并且会保存有对象的元数据,任何对一个对象的操作都需要先读取这第一个分片。分片的定位方法是将对象的cache key转换为cacheID然后通过这个cacheID来查找对象的目录项,目录项中保存了对象第一个分片在磁盘上的偏移量和大小,然后就会从磁盘上读取出来。对象的地一个分片会包含对象的请求头和响应头以及对象的所有描述属性(比如content length)。
Traffic Server支持对象内容多样化,也称之为多副本。所有副本的全部元信息都会保存在对象的第一个分片中,包括每个副本的HTTP header信息。因此当从磁盘上读取出对象的first Doc之后就可以做副本选择。如果一个对象拥有多个副本,那么每个副本会独立地分别存在其他分片中。如果对象只有一个副本,那么对象的内容有可能和元信息同时存在第一个分片中。每个副本的内容都会对应一个目录项,而每个副本目录项的查找key都会保存在第一片中的元信息中
在4.0.1版本之前,header数据会保存在CacheHTTPInfoVector这个结构中,这个结构会被序列化之后存在磁盘上,在这个结构的后面会保存和对象其他片相关的一些附加信息。
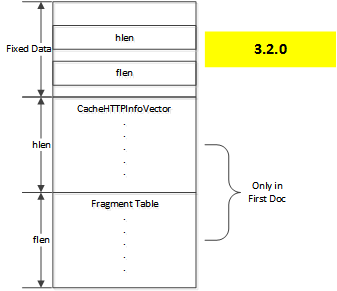
这样存在一个问题,如果一个对象有多个副本,那么只有一个分片table是不够的。因此在元数据中不在单独保存分片信息,而是将分片信息合并到CacheHTTPInfoVector结构中,这样就产生了下面的格式:

向量中的每一个元素代表了一个副本,包含的信息有HTTP header、分片表和一个cache key,这个cache key对应的目录项用来定位对象的earliest doc`,这也是该副本的开始分片的索引。
当一个对象最开始被缓存的时候,它只会有一个副本,因此内容也会同时保存在first Doc中(如果内容不大的话),在代码中称之为常驻副本,这只会在对象最初被保存的时候出现。如果元数据发生改变(比如发送If-Modified-Since请求之后接收到了304响应),那么对象的内容数据会被保留在原始分片中,但是会用新的分片来保存对象的first Doc(对象内容过小的情况除外),这样对象不会再有常驻副本,这里提到的过小是要小于配置中指定的proxy.config.cache.alt_rewrite_max_size的值。
CacheHTTPInfoVector只会保存在`first Doc`中,包括`earliest Doc`在内的其他Doc中的hlen的值应该是0,否则会被忽略。
大对象会被切分成多个分片在cache中存储下来,如果文档的总长度比first Doc或earliest Doc大的话就一定是存在分片,在这种情况下会保存一个分片偏移量Table,用来保存每个分片的第一个字节相对于对象初始字节的偏移量(很显然第一个分片的偏移量总是0)。这样在对大文件处理range请求时会更加的高效,因为range请求中覆盖不到的数据分片会被忽略。序列中的最后一个分片通过接近于对象总长度的分片大小和偏移量来检测,因为没有明确的结尾标示。每个分片是通过序列中的前一片计算得出,第N片的计算公式如下:
key_for_N_plus_one = next_key(key_for_N);
这里next_key是一个全局的函数,用来通过一个已知的cache key确定性的计算得出一个新的cache key。
如果一个对象存在多个分片,那么在保存的时候会先写数据分片(包括earliest Doc)最后再保存first Doc。在从磁盘上读取时,会同时校验first Doc和earliest Doc(确保对象并没有被写光标覆盖)来确保磁盘上保存有完整的对象(这两个Doc将其他Doc夹在中间,所以如果这两个Doc有效的话,整个对象的数据就是有效的)。一个对象的所有分片是排好序的,但这些分片不一定在磁盘上市连续存储的,因为Traffic Server会交替的接收不同对象的数据。
如果一个对象在cache中被标识为’pinned’的话,那么这个对象在磁盘上的数据就不可以被覆盖,因此会在写光标的位置采取疏散策略,每个分片会被读出来然后再重新写回磁盘。对于正在被疏散的对象会有一个特殊的查找机制,确保这些对象可以在内存中被找到而不是磁盘,因为此时对象在磁盘上的数据是不可靠的。The cache scans ahead of the write cursor to discover pinned objects as there is a dead zone immediately before the write cursor from which data cannot be evacuated. 待疏散的数据会先从磁盘上读取出来,然后放入写队列中等待写回磁盘。
对象是否可以被’钉住’需要通过cache.config配置文件来制定,并且proxy.config.cache.permit.pinning这个配置的值不能为0(默认是0)。写光标附近的对象如果正在被使用的话,也会自动地采用同样的疏散机制,但并不是通过Dir中的pinned这个位来表示。
其他注意事项
Some general observations on the data structures.
Cyclone buffer
因为cache是循环写的,因此对象不会无限期保存在磁盘上,即使对象没有过期但仍然可能会被覆盖掉。Marking an object as pinned preserves the object through the passage of the write cursor but this is done by copying the object across the gap, in effect re-storing it in the cache. 如果被钉住的对象过大或者过多的话会导致过多的磁盘开销。最初设计为让管理员来对很小又很频繁访问的对象来设置固定属性。
对象数据过期的目的是防止这些内容发送给客户端,它们并不是真正意义上的删除或清除。存储空间不会立即被回收因为写操作只会在写光标的位置发生,删除一个对象仅仅是删除这个对象在索引区的目录项,这就可以让被删除对象的文档完全失效。
Cache这样设计是因为web内容相对来说都是小对象而且内容经常变化,这样设计也是为了满足高性能低延迟的需求,因为存储上很少出现分片,而且cache miss和对象的删除不需要磁盘的I/O操作,但是在大对象的存储上确实不够理想。
磁盘故障
cache在设计的时候考虑到在一定程度上能够容忍磁盘故障情况的发生。如果一块磁盘发生故障,那么只会造成Cache分卷在这个磁盘上的Cache带的数据不可用,不会影响在其他磁盘上的Cache带的数据。要做的主要工作中就是保证其他正常Cache带上的数据能够继续使用,同时要将哈希到故障磁盘上的数据分配到其他的Cache带中,这些工作在下面这个函数中完成:
AIO_Callback_handler::handle_disk_failure
从新将一块磁盘恢复到正常工作状态有点复杂,更改一个cache key所属的Cache带会导致缓存中的数据不可访问,This is obviouly not a problem when a disk has failed, but is a bit trickier to decide which cached objects are to be de facto evicted if a new storage unit is added to a running system. The mechanism for this, if any, is still under investigation.
实现细节
索引目录项
Cache带中的索引目录项结构定义如下:
class Dir, 在P_CacheDir.h文件中定义的。
Cache带的索引区由一组Dir对象组成,每一个目录项代表着Cache带上存储的一块缓存对象。因为每个对象至少要有一个索引目录项相对应,因此目录项结构的大小尽量精简。
offset成员表示对象在Cache带上的开始字节位置,由40个位来表示,拆分为offset(低24字节)和offset_high(高16字节)来组成。因为每个Cache带都有一个索引区,因此这个offset代表的是在这个Cache带中的偏移量。
size和big这两个成员用来计算对象分片的大概尺寸,这个只用来表示需要从offset这个偏移量处读取多少字节。分片的实际大小保存在Doc的元信息中,每当读取完之后就会得到这个值。索引这个大概尺寸至少要喝实际大小相等,也可以更大一些,但也会导致过多无用的读取。
分片的大致尺寸的计算方法如下:
( *size* + 1 ) * 2 ^ ( ``CACHE_BLOCK_SHIFT`` + 3 * *big* )
这里的CACHE_BLOCK_SHIFT代表一个基本cache块的位长(这里会是9,也就是一个扇区的大小,512字节)。因此替换之后也就是:
( *size* + 1 ) * 2 ^ (9 + 3 * *big*)
因为big这个成员的大小是2比特位,所以系数和大小对应关系如下所示:
如果size的值是0,那表示只有一个系数的大小。
分片大小可以在records.config中进行设置
proxy.config.cache.target_fragment_size
这个值应该设置为一个cache目录项系数的整数倍,不一定设置为2的幂次,大的分片会提高I/O效率,但也会导致有更多的浪费。默认大小是1M,这是一个在大多数环境下都相对合理的数字,不过在某些场景下调整这个数字会得到更好的性能。 Traffic Server imposes an internal maximum of a 4194232 bytes which is 4M (2^22) less the size of a struct Doc. In practice then the largest reasonable target fragment size is 4M - 262144 = 3932160.
When a fragment is stored to disk the size data in the cache index entry is set to the finest granularity permitted by the size of the fragment. To determine this consult the cache entry multipler table, find the smallest maximum size that is at least as large as the fragment. That will indicate the value of big selected and therefore the granularity of the approximate size. That represents the largest possible amount of wasted disk I/O when the fragment is read from disk.
The set of index entries for a volume are grouped in to segments. The number of segments for an index is selected so that there are as few segments as possible such that no segment has more than 2^16 entries. Intra-segment references can therefore use a 16 bit value to refer to any other entry in the segment.
Index entries in a segment are grouped buckets each of DIR_DEPTH (currently 4) entries. These are handled in the standard hash table way, giving somewhat less than 2^14 buckets per segment.
目录探测项
目录项探测是指通过一个cache ID来在一个Cache带的索引区中查找一个指定的目录项。在程序中通过函数dir_probe()来完成,需要制定三个参数分别是:cache ID(key),cache带和上一个冲突的项。最后一个参数即使输入又是输出,在探测期间会被修改。
指定一个ID,高64位会被拿来计算属于哪个segment,通过取模运算(模上segment总数)。低64位用来计算属于哪个bucket,也是通过取模运算(模上一个segment中拥有的bucket的总数)。last_collision的值用来保存上一次匹配上的值,这个值是通过dir_probe()返回的。
通过计算之后得到了对应的桶,然后从这个桶中找出一个匹配上的项,通过比较cache ID的低12位和目录项中的cache tag来检查,从目录桶中的第一项开始,然后沿着链表去查找。如果查找到一个tag匹配上的项并且之前没有其他冲突的项那么就返回这个项并且把这项赋值给last_collision,如果设置了冲突项并且不等于当前match的项那么继续沿着链表查找,如果等于那么就重置collision然后继续查找。这样设计的目的是在找到上一个冲突项之前忽略所有匹配的项,要返回之后匹配上的项。If the search falls off the end of the linked list then a miss result is returned (if no last collision), otherwise the probe is restarted after clearing the collision on the presumption that the entry for the collision has been removed from the bucket. This can lead to repeats among the returned values but guarantees that no valid entry will be skipped.
上一个冲突项在一段时间之后被拿来重新发起一次目录项探测,This is important because the match returned may not be the actual object - although the hashing of the cache ID to a bucket and the tag matching is unlikely to create false positives, that is possible. When a fragment is read the full cache ID is available and checked and if wrong, that read can be discarded and the next possible match from the directory found because the cache virtual connection tracks the last collision value.
Cache的一些操作
当HTTP请求头被解析完并经过remap处理之后就会做一些cache操作,隧道类的事务不会对cache进行操作,因为从不解析header。
这里需要介绍一下术语’cache valid’,表示一个对象可以写入到cache中()。这很重要因为Traffic Server在一个事务处理过程中会计算cache有效性很多次,而且只会对cache有效的对象进行操作。在HTTP事务处理过程中这个标准还可能会发生改变,这是为了避免对cache无效的对象进行操作。
cache的三个基本操作是查找、读取和写入。cache的删除操作仅仅是更改对应的索引项。
当客户端的请求被解析完并且确认要进行cache操作,会发起cache查找。如果查找成功,那么就会发起一个cache读取的操作,如果查找失败或者读取失败,那么会发起一个cache写入的操作。
可缓存性
一个请求对cache进行的第一个操作就是判断这个请求的对象是否cache有效。解析和remap工作完成之后就会进行这个判断,如果是负数那么就表示后面的cache操作会完全忽略,不会做cache的查找和写入操作。There are a number of prerequisites along with configuration options to change them. Additional cacheability checks are done later in the process when more is known about the transaction (such as plugin operations and the origin server response). Those checks are described as appropriate in the sections on the relevant operations.
Cache查找
如果HTTP请求被认为cache有效,那么就会发起一次cache查找。cache查找用来判断一个对象是否已经在cache中,某些情况下,cache查找用来确认对象的first Doc仍然在cache中。
一次cache的查找需要三个基本步骤:
- 计算cache key
一般通过请求的URL来计算,但也可以被插件中的业务逻辑覆盖掉,据我所知cache的索引字符串并不会被保存下来,因为一般假定就是通过客户端请求头来计算。
- 确定使用哪个cache带(也是通过cache key得到的)
cache key会被拿来当做一个哈希key来在cache 带数组中进行查找,这个数组的构建和安排也能够体现出cache带是如何赋值的。
cache key还会被拿来计算一下在cache带中的索引。此外,其他地方的索引也会被考虑进来,比如说agg buffer中的数据对应的索引
如果查找到了索引,那么会从磁盘上读取到对应的first Doc,并验证其有效性。
在代码中是通过CacheVC::openReadStartHead()和CacheVC::openReadStartEarliest()这两个函数来完成。
如果查找成功,那么会创建一个信息更全的结构体(OpenDir),这里要注意的是目录探测的时候也会检查是否已经有现存的OpenDir结构体了,如果已经存在那么直接返回。
Cache读取
Cache读取是在cache查找成功之后发起的,此时first Doc已经加载到了内存中,可以拿来查找其它信息。在first doc中会包含对象所有副本的HTTP头信息。
有了first doc中的一些信息就可以选中一个副本,这是通过比较客户端请求的信息和存储的所有副本响应头的信息而得到,不过这个也可以在插件中通过TS_HTTP_ALT_SELECT_HOOK点来做控制修改。
内容通常会被拿来计算一下是否已经腐烂,这是一项重要的检查,方法是查看一下副本的header和其他元信息(选中副本之后才能做这些检查)。
这个工作会在HttpTransact::what_is_document_freshness这个函数中完成。
…
Cache写入
写Cache操作是通过CacheVC对象完成的,CacheVC是一个虚拟的连接,接收数据并写入cache。如果需要在多个虚拟连接之间传递数据的话,一般通过HttpTunnel来完成。写入cache时要将CacheVC对象作为Tunnel的消费者,它会和发送给客户端的虚拟连接并行执行。数据不会先写入cache再写到client, 数据会被拆分开并且同时向两个连接中并行发送,这也就避免了在两个连接上做数据同步。
每个CacheVC的事务是独立处理的,在cache带这个层面它们会互相影响,因为它们都会向Cache带中写数据。CacheVC内部会一直保存数据直到事务结束或者数据超过分片大小,如果是前一种情况的话整个对象会被直接写入cache带,如果是后一种情况的话会先将一个分片大小的数据写入cache带然后CacheVC继续操作余下的数据,cache带会把这些不同的写请求的数据缓存到aggregation buffer中。
如果一个对象的大小不超过分片大小那么对象会被整个写入cache,不会涉及到顺序。对于大的对象来讲,earliest Doc最先写入cache,first Doc最后写入cache,这有利于判断一个磁盘上的对象是否可以被覆盖,因为写光标会保证如果一个对象的第一个分片(earliest doc)没有被覆盖的话,那么其他分片也不会被覆盖(当一个对象在cache中写完的时候,写光标会在这个对象的first Doc的位置)。
CacheVC的逻辑需要保证不会一次性提交超过分片大小写操作。
更新
Aggregation Buffer
疏散机制
疏散操作
初始化

若有收获,就点个赞吧
0 人点赞
