简介
Map 节点将给定的函数应用于其每个输入,并返回转换后的数据。对于每一行输入,map 返回一行。有关更多详细信息,请参阅 map API。
下图说明了 map 如何将转换应用于输入的每一行。
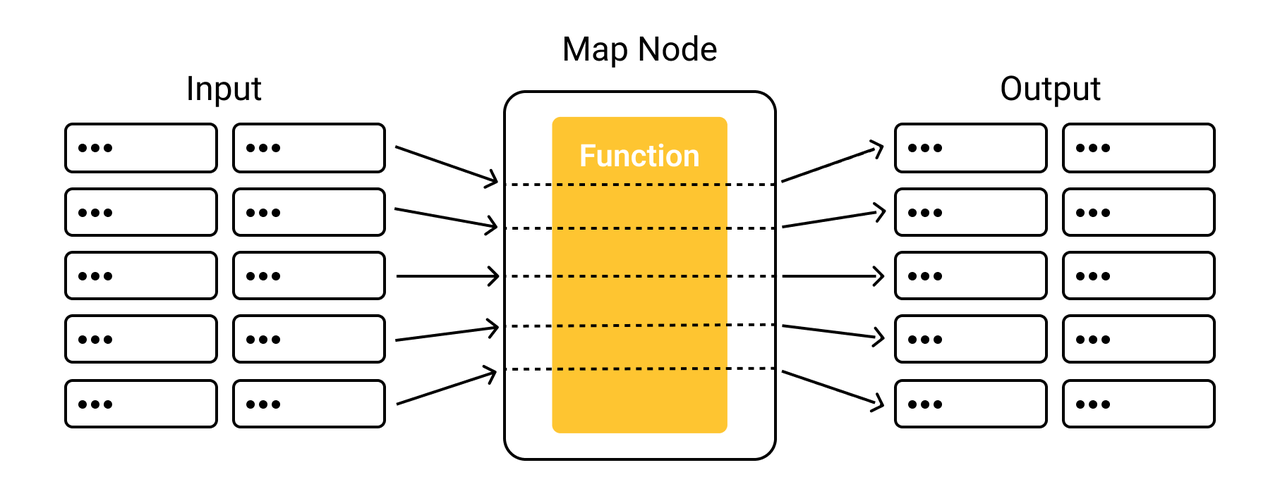
示例
我们使用 map(input_schema, output_schema, fn, config=None) 接口来创建一个 map 节点。
请注意,fn 函数的输入应该遵循 input_schema,而 fn 函数的输出应该遵循 output_schema。函数的多对输入和输出意味着在源表和相应的目标表中存在多列数据。
现在,让我们以文本特征提取管道为例,演示如何使用 map 节点。
此示例定义了一个用于文本特征提取的管道。
在运行管道时,您可以使用 batch (batch_inputs) 一次插入多行数据。
from towhee import pipe, opstext_embedding = (pipe.input('text').map('text', 'embedding', ops.sentence_embedding.transformers(model_name='all-MiniLM-L6-v2')).output('text', 'embedding'))data = ['Hello, world.', 'How are you?']res = text_embedding.batch(data)
text_embedding 管道的 DAG 如下图所示。图中箭头上的文本描述了数据如何由每个节点进行转换。节点的输出得到了突出显示。

每个节点中的数据转换如下图所示。

此管道中有一个 map 节点。
map('text', 'embedding', ops.sentence_embedding.transformers(model_name='all-MiniLM-L6-v2'))
该节点将 sentence_embedding/transformers 操作符应用于文本以提取文本特征并生成句子嵌入。该运算符返回嵌入的列表(embedding)作为输出。

若有收获,就点个赞吧
0 人点赞
