通常的请求都为get,是可以在url地址栏里可见的,可以直接通过拼接url地址实现发送请求获取解析数据。部分网站使用POST请求发送数据,数据的传输在url地址栏不可见,但是前后端的数据包交互在浏览器内都是可见的,可以通过抓包手段获取数据包,解析得到正确的目标数据。
这里以某道为例,没有恶意,只是学习。QAQ
- 使用chrom的f12进入network
数据一般都是通过js加载出来的,异步数据点击XHR抓包。
- 清理掉调试器内的数据,在form表单框内键入目的文字,调试器内出现可疑文件:

打开文件点击preview进行预览数据包内容:
目标确定,的确为可疑对象。
- 注意一点:在从搜索到出结果的过程中地址栏中的url地址没有改变,说明请求的地址不是这个,应该向正确的url地址发送请求才能获取到目标数据。在头里可以看到到底是向哪一个url地址发送请求获取到数据的,Request URL 字段就是我们要发送请求的url地址。
res = requests.post(
headers=headers,
proxies=proxies,
url=url,
data=data
)
注意:headers、data一定从控制台中复制,然后分析具体要发送什么东西,特别是data,一般而言headers直接复制即可,但是对于form表单提交的数据:data,不同的内容一定发送不同的data,或许某些字段是不变的,但是一定会有变动的字段,可能涉及到某些加密,对于加密的数据通过分析js代码找出加密的方式,用python实现,封装到data,即可躲避网站的检测。
proxies:proxies是设置的代理ip,当利用本机ip超频访问网站会被网站的反扒机制封掉ip,为了避免这种情况的发生可通过使用代理ip躲避反扒机制对本机ip的检测,如果代理ip被封,从ip池中随机获取即可(涉及到从网站中爬取ip,测试成功并持久化到记事本中,在后面将会详细讲解)。proxies的使用规则:
proxies = {'http:': 'http://IP + PORT','https:': 'https://IP + PORT'}
解析data
输入hello的data: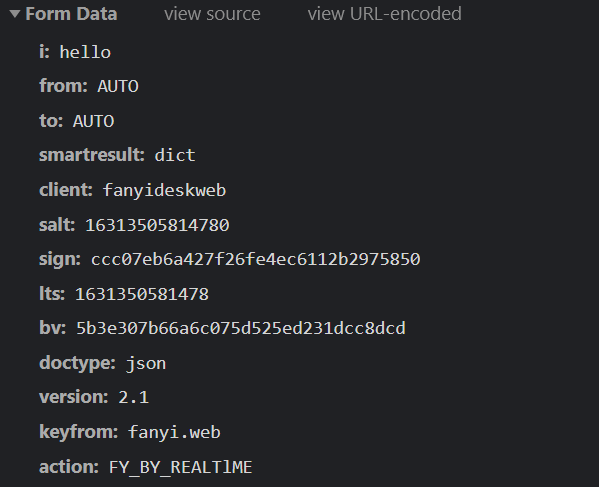
输入fuck: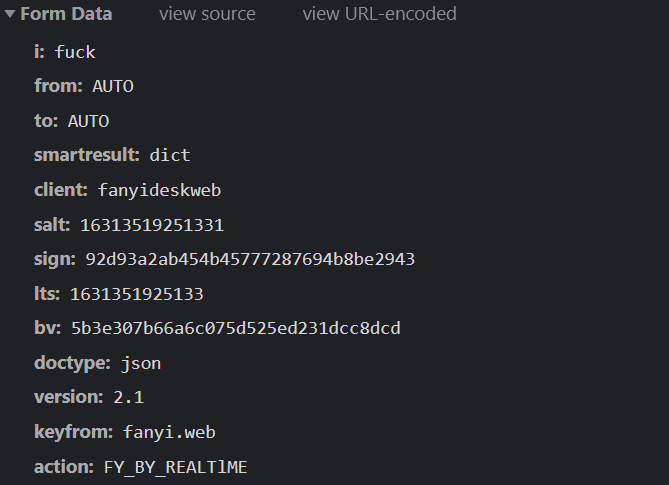
分析上述的表,得出以下结论:
- i为搜索的词
- salt不同, 为纯数字,应该和时间戳相关
- sign不同 , 为32为无序码,可能是md5加密
- its不同,为13为数字,可能和时间戳相关
解决上述的问题,即可完美的模拟浏览器访问而非爬虫访问。
上述的数据都是通过js处理后展示出来的,所以要得出加密机制,要分析js源代码。
打开js源代码:
打开全局搜索,以加密的字段为搜索内容,搜索出在js中的位置,分析出可能为加密代码的部分,找出加密逻辑,在python中实现,并入到data中。
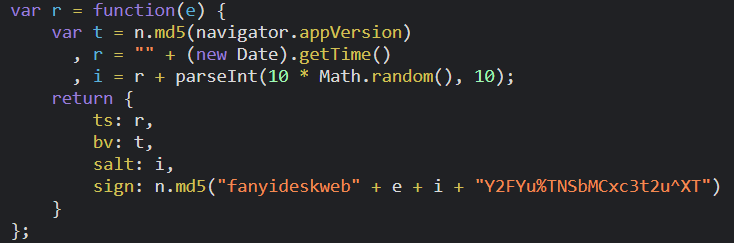
ts为时间戳的字符串形式
bv为md5加密navigator.appVersion,在控制台的console中输出一下发现是UserAgent的部分内容,且是不改变的内容,所以不用考
虑。
salt为时间戳和任意的0~9内的数字相拼接的新字符串。
sign为md5加密字符串, 找出e:启动debug模式,在程序中打断点,结果如下: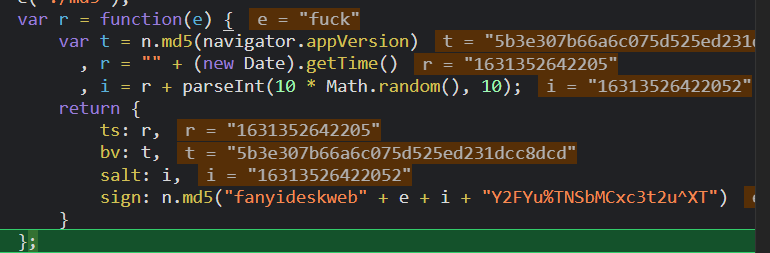
e就是我们在form表单中提交的数据
分析完成!!!
**在python中实现上述步骤:
**
import randomimport timeimport requestsfrom hashlib import md5class YDSpider(object):def __init__(self):self.post_url = 'https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'self.proxies = '193.162.35.34:8080'self.headers = {'Accept': 'application/json, text/javascript, */*; q=0.01','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8','Cache-Control': 'no-cache','Connection': 'keep-alive','Content-Length': '239','Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8','Cookie': 'OUTFOX_SEARCH_USER_ID=629671479@10.169.0.83; JSESSIONID=aaa94ZR08''csTXa2soytVx; OUTFOX_SEARCH_USER_ID_NCOO=1758432576.6255052; ___rl__test__cookies=1631342485045','Host': 'fanyi.youdao.com','Origin': 'https://fanyi.youdao.com','Pragma': 'no-cache','Referer': 'https://fanyi.youdao.com/','sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"','sec-ch-ua-mobile': '?0','Sec-Fetch-Dest': 'empty','Sec-Fetch-Mode': 'cors','Sec-Fetch-Site': 'same-origin','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKi''t/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','X-Requested-With': 'XMLHttpRequest'}def get_ts_salt_sign(self, word):ts = str(int(time.time() * 1000))salt = ts + str(random.randint(0, 9))string = "fanyideskweb" + word + salt + "Y2FYu%TNSbMCxc3t2u^XT"s = md5()s.update(string.encode())sign = s.hexdigest()return ts, salt, signdef attack_YD(self, word):ts, salt, sign = self.get_ts_salt_sign(word)data = {'i': word,'from': 'AUTO','to': 'AUTO','smartresult': 'dict','client': 'fanyideskweb','salt': salt,'sign': sign,'lts': ts,'bv': '5b3e307b66a6c075d525ed231dcc8dcd','doctype': 'json','version': '2.1','keyfrom': 'fanyi.web','action': 'FY_BY_REALTlME'}res = requests.post(url=self.post_url,proxies={'http:': 'http://45.177.109.195:8080','http': 'https://45.177.109.195:8080'},data=data,headers=self.headers)print(res.text)def run(self):word = input('请输入要翻译的单词')self.attack_YD(word)if __name__ == '__main__':spider = YDSpider()spider.run()

若有收获,就点个赞吧
0 人点赞
