Html与css知识需要有基本的了解,这样方便使用xpath获取内容(或者用beautifulsoup)。
举个简单的栗子: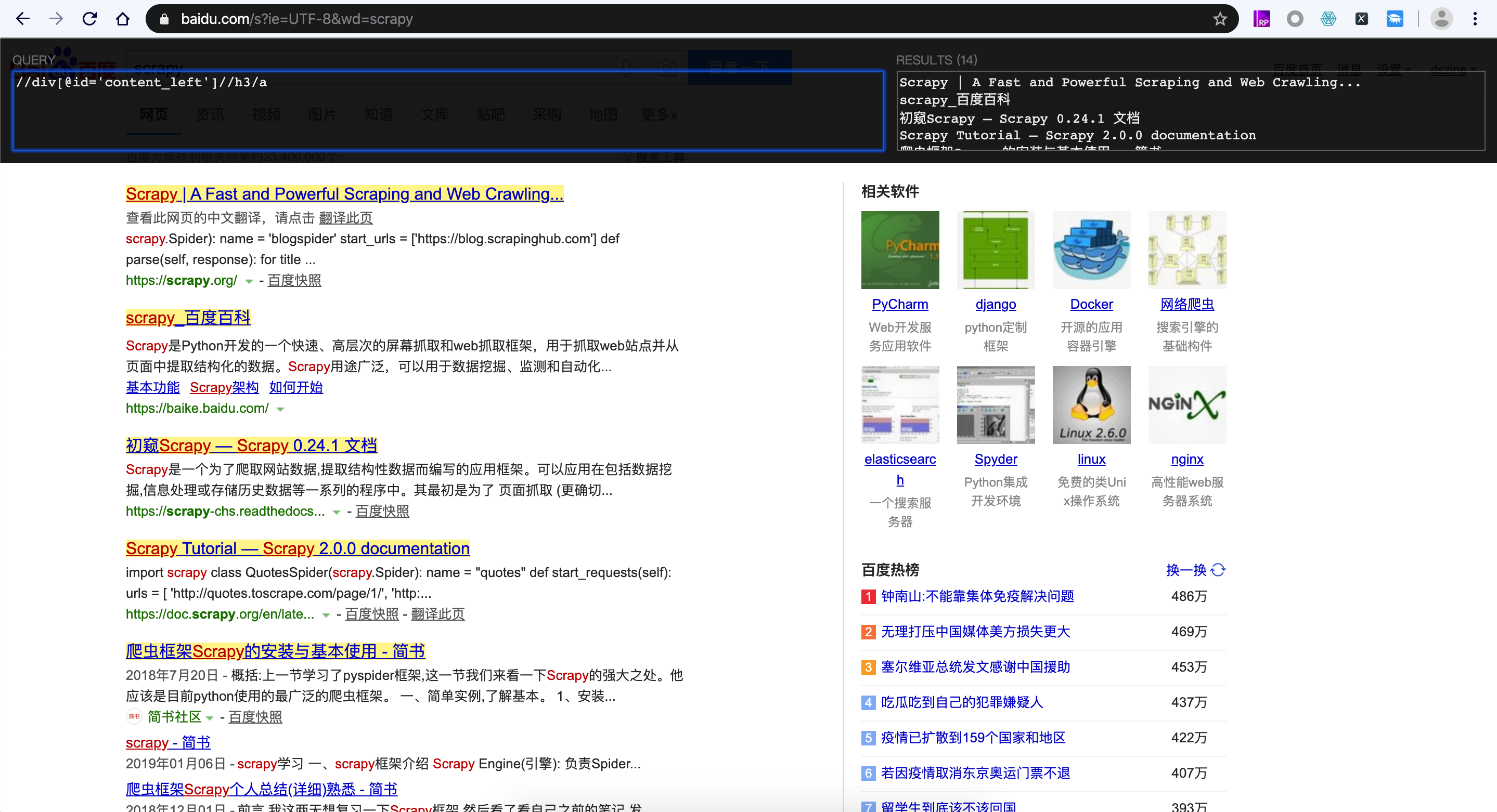
我们可以通过xpath规则获取对应的文本内容。
这样可以把文本传递并保存下来。同理,可以保存各种信息。
手动抓取尝试。目的是为找到爬虫最佳xpath规则
1. 安装chrome插件 (需要kx上网)
2. 进入插件商店搜索:XPath Helper 进行安装
3. 打开目标网站 xin.baidu.com
4. 确定需要找的数据:企业名称、注册资本、成立时间
5. 打开检查元素找到 企业名称的标签,并向上查找。找到唯一的包裹标签。
6. 打开插件写入xpath规则://h3 说明一下 //是指根目录 ,h3 是指html标签
7. 右侧的结果框里,就会看到当前页面的h3 标签的所有内容。
视频如下
点击查看【bilibili】

若有收获,就点个赞吧
0 人点赞
