前言
👋 欢迎来到Token的StableDiffusion的知识库
我的微博:https://weibo.com/u/1908661973
我的 B站:https://space.bilibili.com/2608386
软件选择
B站有很多训练脚本可供选择,但是绝大部分都需要部署运行环境,对于非程序员来说存在一定困难,所以建议使用东归初雪UP主的免部署lora训练包
- https://www.bilibili.com/video/BV1ps4y1j7W7
- 注意选择完整版,非完整版可能需要下载额外内容,对网络有一定要求
- 解压后检查一下文件路径有没有中文
还要提前准备好训练用的底模,一般以未修剪过的原版NAI和原版SD1.5为主
- 原版NAI,下载下来是没名字的,建议重命名为animefull-latest.ckpt
- https://huggingface.co/rokuma/animefull-latest/resolve/main/model.ckpt
- 原版SD1.5
- https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.ckpt
训练步骤
一般的训练步骤分为这几个环节
- 数据集收集
- 数据集裁剪
- 数据集打标
- 配置训练文件
- 配置训练参数
- 开始训练
- 训练结束,验收成果
数据集收集
数据集收集一般是整个训练过程最耗时的部分,数据集的质量也直接决定了一个模型质量的上限
不管你训练的是角色,风格,场景还是别的什么概念,要求都是一样的
- 质量优先
- 尽可能高清
- 训练主体能够被清晰识别
- 风格差异不要太大,比如说真人cos和纸片人放在一起
- 数量其次
- 视你训练的概念复杂程度而定,十几张起步
- 有一定多样性,包含不同动作,光照,机位,景别,背景等等
数据集裁剪
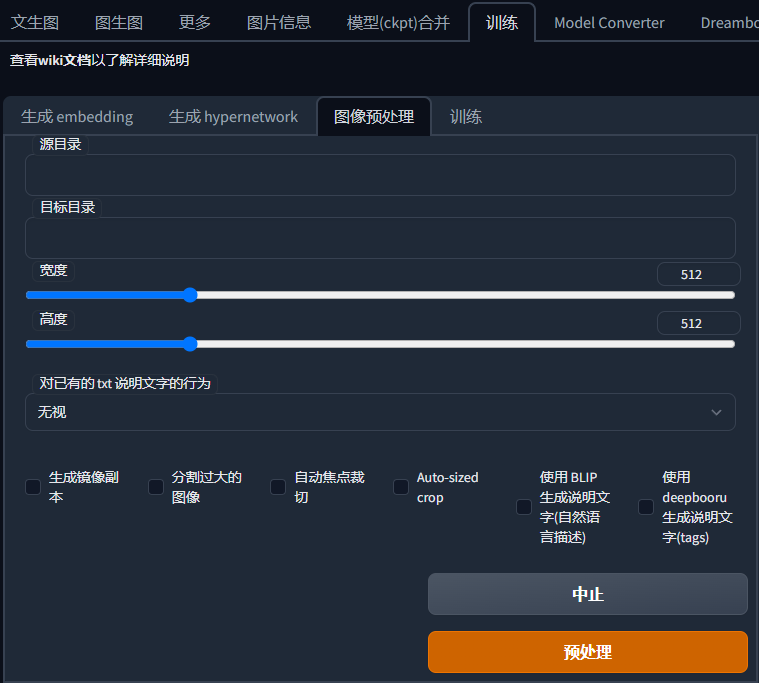
直接使用SDwebui自带的预处理工具即可
- SDwebui-训练-图像预处理
裁剪原则
手动裁剪肯定是优于自动裁剪的,但是目前并没有一个比较方便的裁剪工具,以下是一些裁剪要点
人物
- 避免主体人物被左右分割
- 人物可以被上下分割,但是最好有一定重叠,并且保留未分割的素材
- 装备和头部细节可以单独拆分
- 如果有水印最好手动抹去
场景
- 用预处理工具的分割过大图像和自动缩放直接处理即可
源目录和目标目录
路径不要带中文,以避免可能的问题
源目录和目标目录路径不要相同,否则你的图片库会乱掉
宽度和高度
如果你的显卡给力可以拉高一点,注意宽高都必须是64的倍数,比如640,768,960,1024
这里的数字并不直接决定你的训练分辨率,因为Lora是可以自适应分辨率的,理论上你不裁剪图片也可以训练
生成镜像副本
不要开,如果需要镜像可以直接在Lora训练参数里设置
分割过大图像
如果你的图片很宽或者很长可以开启这个来自动分割,但是如果是人物三视图之类的图片还是建议手动分割,否则会出现人物被剪切的情况
- 图像分割阈值,数字越大越倾向于分割长图,如果你预处理之后发现图片没有被分割,可以尝试调大
- 分割图像重叠的比率,数字越大分割后的图像重叠越多,一般不用去动
自动焦点裁切
如果你要训练的是人像的话建议开启,比较复杂,但总之是一个可以自动检测焦点(比如面部)进行裁切的工具,默认设置即可
Auto-sized crop(自动缩放)
比较常用的功能,因为Lora训练可以自适应分辨率,所以现在不一定需要把图片裁成一样的尺寸和比例,自动缩放可以把不同大小的图片按照设置缩放为训练能够处理的尺寸,注意开启这个功能之后上面的宽高设定就没用了,要以下面的为准
- Dimension lower bound & Dimension upper bound(最短和最长边限制)
- 顾名思义,图片不论宽高都会被缩放在这个范围内,比例不变
- Area lower bound & Area upper bound(最小和最大面积限制)
- 如果你拖动上面的长短限制发现预处理图片达不到你想要的大小,可能是面积超标了,upper bound的默认设置409600其实就是640*640,可以看情况拉大
- 其他选项我也没搞懂有什么用
数据集打标
数据集打标是比较耗精力的地方,但是因为是入门教程所以就直接自动打标了,用来训练头像,画风和场景的话自动打标基本绰绰有余
打标工具会自动为图片生成一个同名的txt文件,里面写了对应的描述和tag,以下两者可以同时使用,会写在同一个txt里,描述在前tag在后
使用 BLIP 生成说明文字(自然语言描述)
他会自动为你的图片生成一段语言描述,比如说
- a classroom with a lot of desks and chairs and a projector screen in the middle of the room
如果是场景,道具等非人对象,建议使用BLIP,在使用的时候SD可能会需要下载一个识别模型,下载还是挺慢的,可以自己单独下载后放在指定位置
- BLIP模型下载地址
- https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_caption_capfilt_large.pth
- BLIP模型放置位置
- *\models\BLIP\
使用 deepbooru 生成说明文字(tags)
deepbooru生成的就是我们常用的1girl开头的提示词格式,比如说
- 1girl, blonde_hair, blurry, blurry_background, brown_eyes, depth_of_field, headphones, hood, jacket, lips, realistic, short_hair, solo, unzipped, upper_body, zipper
用在人物身上效果比BLIP要细致的多,但是如果用在非人对象上就没那么有效了,deepbooru也是需要模型的,但是绝大多数整合包都自带了所以不用单独下载
配置训练文件

主要工作就是把裁剪和打标好的数据集分类放在不同的文件夹里,命名文件夹并标好训练次数,还是注意文件路径不要有中文
文件夹分类
简而言之,不同的对象要分开,同一对象不同景别角度动作等等可以放在一起
- 单个角色训练,不同套装要分开
- 多个角色画风训练,男女老少要分开
- 场景画风训练,不同场景要分开
- 多个角色套装训练,不同主题不同性别不同职业要分开
- 如果图片质量差别很大,高质量图和低质量图要分开
文件夹命名
命名格式是数字,下划线,概念名
- 10_destiny hunter
数字表示每个训练回合的训练次数
- 训练次数没有特别的要求,一般在5~15之间
- 要注意匹配不同概念之间的权重
- 如果一个概念的图比较多而另外一个概念的图比较少,需要通过调整次数*图片数来让两者接近
- 同样如果你希望某个概念权重更高,比如说很多低质量图和少量高质量图,可以给高质量图更高的次数
概念名
- 概念名并没有一定规则,只要是英文并且尽量不要带标点符号即可
- 推荐的命名原则是概念类+概念名,比如说character destinyhunter
配置训练参数
因为是入门教程,所以非常简单,一路照做即可,参数对训练的影响很难量化,有时间还是仔细处理下数据集更好
- 详细可以参考东归初雪Up主的参数讲解
- https://www.bilibili.com/read/cv22022392
列表比较长,实际训练过一次就会很快知道点哪些了
- 你需要载入保存好的预设吗?(否)
- 选择你的基础模型(准备好一开始下好的模型,真人或照片选SD1.5,别的二次元游戏啥的都选NAI)
- 选择你的图像路径(这里选择的图像路径必须是,X_tag 的父文件夹,例如images/7_tags 则选择images)
- 选择你的输出路径(随意,建议建个文件夹把输出,数据集啥的都丢进去)
- 你想保存配置的json预设吗?(可存可不存,不过我存了我也不懂怎么改)
- 你想启用低RAM模式吗?(否)
- 你想要哪个优化器?(lion)
- 你是在一个基于SD2的模型上训练吗?(否)
- 你是在训练一个三次元模型吗?(真人或照片选是,别的选否)
- 你想使用正则化图像吗?(否,以后再专门解释正则化怎么用)
- 你想从一个你保存过的lora文件继续训练吗?(否)
- 你想翻转你所有的图像吗?(如果你的角色左右对称并且图片不多可以选是,但我建议否,特别是真人,因为大部分真人都有轻微的左右不对称)
- 一次性处理的图像数量(batch_size)(看你的显卡能力,开的越高训练越快,可以训练的时候打开任务管理器看下显存占用来测算极限)
- 你想要多少个epoch?(如果前面的训练次数设为10,epoch也设为10一般就够了,也就是一张图训练一百次,觉得不保险可以加到20)
- 你想用什么DIM值?(默认32)
- 你想设置多少alpha?(默认0.5dim)
- 请设置分辨率(分辨率非常吃显存,一般512就够了,显卡很强可以尝试768)
- 请设置学习率 (默认)
- text_encoder_lr和unet_lr (默认)
- 你要使用哪个学习率调度器? (cosine)
- 需要每隔几次保存一次你的输出吗? (推荐2)
- 你需要洗牌描述吗?(否)
- 你需要在描述前保存特殊标记吗?(否)
- 你需要设置学习率预热比例吗?(否)
- 你是否需要改变输出checkpoint的名称?(能改还是要改一下,最好加个批次,因为可能同一模型会训练很多次,比如DestinyCharacter01)
- 你需要在元数据中添加描述吗? (否)
- 你需要仅训练unet和text_encoder吗?(否)
- 你想保存一个txt文件来输出你所有使用的Tag吗?(是,按频率)
- 你想使用caption dropout吗?(否)
- 你想启用noise offset吗?(是,默认0.1)
- 你需要放大图像吗?(否)
- 你想进行另外一个训练吗?(否)
开始训练
开始训练之前记得关掉你的游戏,SD webui等一切会占用显存的东西
训练过程没什么好说的,就是等,loss率啥的一般也看不懂,途中可以打开资源管理器看下显存和cuda占用
模型验收
把训练完的模型都复制到SD的lora文件夹下
- 最好建一个文件夹单独存放自己训练的模型,和下载的模型分开
- 如果选择隔几次保存一次模型,会输出很多模型
- Lora模型路径:*\models\lora
验收过程
- 载入需要的大模型
- 输入提示词起手式
- 打开你保存Lora模型所有使用Tag的txt文件(配置训练参数的第28步),复制前面几个有代表性的Tag在提示词里
- 打开附加网络,刷新,载入你的训练好的最后一个Lora
- 生成批次或者数量可以调高点
- 生成图片,观察结果
验收标准
主要考察这几个性质:稳定性,还原性,泛化性
达不到以下标准并不意味着模型完全不能使用,在一些场景下比如图生图,lora交叉混用等等时候,过拟合模型调低权重也是能达到效果的
稳定性
稳定性主要指模型有没有坏掉
- 模型是否会经常输出和数据集原图近乎一致的图片?
- 模型在一般的cfg(比如5~11)下会不会出现大量的噪点和碎片形状?
- 模型在默认1权重下下会不会出现大量的噪点和碎片形状?
如果出现这些情况,一般就是过拟合,数据集质量低,或者数据集分类过于杂乱
- 过拟合,可以选择保存的前几个epoch来测试
- 数据集质量低,准备更高质量的数据集,也可以尝试删除数据集中低质量的部分
- 数据集分类过于杂乱,比如男女或者不同风格的图片放在同一个文件夹下,需要把不同对象和不同风格的图片分开放置
还原性
还原性主要指能不能画出你要的概念
- 模型能够在默认1权重下绘制出你想要的对象或者风格吗?
- 模型能够还原你想要的对象配色吗?
如果不能,一般是欠拟合,或者数据集打标不够细致
- 欠拟合,可以选择调高训练epoch数,或者调整文件夹命名上的训练次数
- 数据集打标不够细致,其实自动打标是要比自己打标细致的多的,但是打标模型不会识别服装和背景颜色,这个需要自己去手动补充
泛化性
泛化性主要指模型能不能在不同情景下正常使用,这里要测试的比较多了,不仅仅是默认1权重下的表现,还有其他权重下的表现
- 模型是否会重复少数几种构图?
- 模型能否适配不同动作和构图?
- 模型能否在不同大模型下正常运作?能否搭配其他lora使用?
- 模型能否替换背景,着装,颜色等元素?
泛化性主要视你的数据集规模和丰富程度而定,如果只有正视图想要SD画出背面这是几乎不可能的,总之就是扩大你的数据集多样性

若有收获,就点个赞吧
0 人点赞
