分析
分析是CBO的数据来源。
CBO是一个数学模型,需要准确的传入数据。通过精确的数据计算出精确的执行计划。
分析的最终目的是让CBO理解数据。
当创建了一张表,没有分析数据直接查询时,oracle计算cardinality的参数是非常少的:
-- 新创建的表,查询时oracle检测到没有做过分析会自动进行动态采样,添加一个hint使其不做动态采样-- 新创建的表没有做数据分析时,oracle能知道只有user_segments中该段对象的数据块数量select /*+ dynamic_sampling(t 0) */ count(*) from t;
此时oracle计算的Cardinality为:
Cardinality = num_of_blocks * ( block_size - cache_layer ) / avg_row_len
cache_layer是数据块中分配的用来做其他事情的空间,存储着object_id、ITL、SCN等结构性信息。
(block_size - cache_layer)oracle是预估数据块中真正装载的数据的大小。
avg_row_len是oracle设定的一个默认行长 200字节,oracle在不知道表中数据的情况下,认为一行数据大概占200字节。
CBO的数据来源
初始化参数:
- 优化参数
- CPU
- 数据块大小
- 多块读的大小
- ….
数据字典:
user_tables、user_tab_partitionsuser_indexes、user_ind_partitionsuser_tab_col_statistics- ….
DBMS_STATS包和analyze命令
analyze命令已经过时:
- 无法提供灵活的分析选项
- 无法提供并行的分析
- 无法对分析数据进行管理
DBMS_STATS:
- 专门为CBO提供信息来源
- 可以进行数据分析的多种结合
- 可以对分区进行分析
- 可以进行分析数据管理:备份、恢复、删除、设置….
自动信息收集
Oracle11g的一个默认设置,默认就会对表进行自动信息收集。
user_tab_modification跟踪表的DML修改。
当分析对象的数据修改超过10%时,oracle会自动重新分析。
定时任务 GATHER_STATS_JOB每天晚上负责重新定时收集过旧数据的信息。(10g的定时时间和11g不同,11g是每天晚上10点)
oracle信息收集后,可能没有及时的刷到数据字典中,可以执行以下语句手工刷入数据字典中:
exec DBMS_STATS.FLUSH_DATABSE_MONITORING_INFO;
查看GATHER_STATS_JOB的执行记录:
select log_id, job_name, status, to_char(log_date, 'DD-MON-YYYY HH24:MI') log_datefrom dba_scheduler_job_run_detailswhere job_name = 'GATHER_STATS_JOB';
当数据执行计划保持不错的时候,可以依赖自动分析。否则需要手工介入。
DBMS_STATS包
DBMS_STATS包下工具分类:
- Gathering Optimizer Statistics 分析数据搜集
- Setting or Getting Statistics 用户自己设置一些统计值
- Deleting Statistics 删除统计值
- Transferring Statistics 传输统计值
- Locking or Unlocking Statistics 锁定统计值
- Restoring and Purging Statistics History
- User-Defined Statistics
- Pending Statistics
- Comparing Statistics
- Extended Statistics
表数据的收集:
DBMS_STATS.GATHER_TABLE_STATS(ownname varchar2, -- 用户tabname varchar2, -- 表名partname varchar2 default null, -- 分区estimate_percent number default null, -- 百分之多少的行采样block_sample boolean default false, -- 数据块采样率method_opt varchar2 default 'FOR ALL COLUMNS SIZE 1', -- 直方图分析选项degree number default null, -- 并行度granularity varchar2 default 'DEFAULT', -- 力度cascade boolean default false, -- 是否级联分析索引(最好单独进行索引分析)stattab varchar2 default null, -- 建一张表存储统计信息,表名statid varchar2 default null, -- 表的IDstatown varchar2 default null, -- 表的属主no_invalidate boolean default false -- 是否验证有效性);
索引数据的收集:
DBMS_STATS.GATHER_INDEX_STATS(ownname varchar2,indname varchar2,partname varchar2 default null,estimate_percent number default to_estimate_percent_type(GET_PARAM('ESTIATE_PERCENT')),stattab varchar2 default null,statid varchar2 default null,statown varchar2 default null,degree number default to_degree_type(get_param('DEGREE')),granularity varchar2 default get_param('GRANULARITY'),no_invalidate boolean default to_no_invalidate_type(get_param('NO_INVALIDATE')),force boolean default false);
数据分析示例:
-- 表数据收集exec dbms_stats.gather_table_stats(user, 't');-- 索引数据收集exec dbms_stats.gather_index_stats(user, 'idx_t');-- 表数据收集同时级联收集索引信息exec dbms_stats.gather_table_stats(user, 't', cascade => true);
采样百分比
estimate_percent:对多少数据进行采样分析
DBMS_STATS.AUTO_SAMPLE_SIZEoracle自动判断,对大表不建议使用自动判断,有可能分析的很慢- 手工设置(范围 0.000001 到 100),对于大表设置值小一些速度快一些,对小表可以设置100全表分析
数据分析力度
granularity:数据分析的力度。针对分区表有意义,对于分区表或带有子分区的表,在哪个层面进行分析。默认情况下是全局和分区级别都做分析
- global:全局范围(整个表层面)
- partition:分区级别
- subpartition:子分区级别
如果sql查询跨分区,但是没有做全局级别的分析,就可能导致oracle产生错误的执行计划。
oracle 11g时,当表只做了分区分析,没有全局分析信息时,会把分区的分析信息合并作为全局分析信息。但是如果表上已经有全局统计信息,单独对分区分析,不会更新全局信息。
有的表非常大,如果因为多了一个分区而去做全局分析,代价将会非常大。所以在Oracle 11g时,有了增量统计,增量的手机分区信息来更新全局信息。
设置增量统计:
-- 设置增量收集属性 INCREMENTALexec DBMS_STATS.SET_TABLE_PREFS(user, 't', 'INCREMENTAL', 'TRUE');-- 再执行表统计时就会使用增量统计exec DBMS_STATS.gather_table_stats(user, 't');
OLAP系统,在一个很大的分区表中,全局分析的代价是非常昂贵的。OLAP系统除了新加入的数据外,旧的数据基本上是没有变化的,全局分析很浪费资源。
对于很大的分区表,将granularity设置为 partition(oracle 10g)或者 incremental(Oracle 11g)是很有意义的。对于不大的分区表,可以使用默认设置。
分析直方图
method_opt:分析直方图选项。
Oracle对列上的数据分布进行统计分析,对数据倾斜分布时很有用。
直方图收集方式:
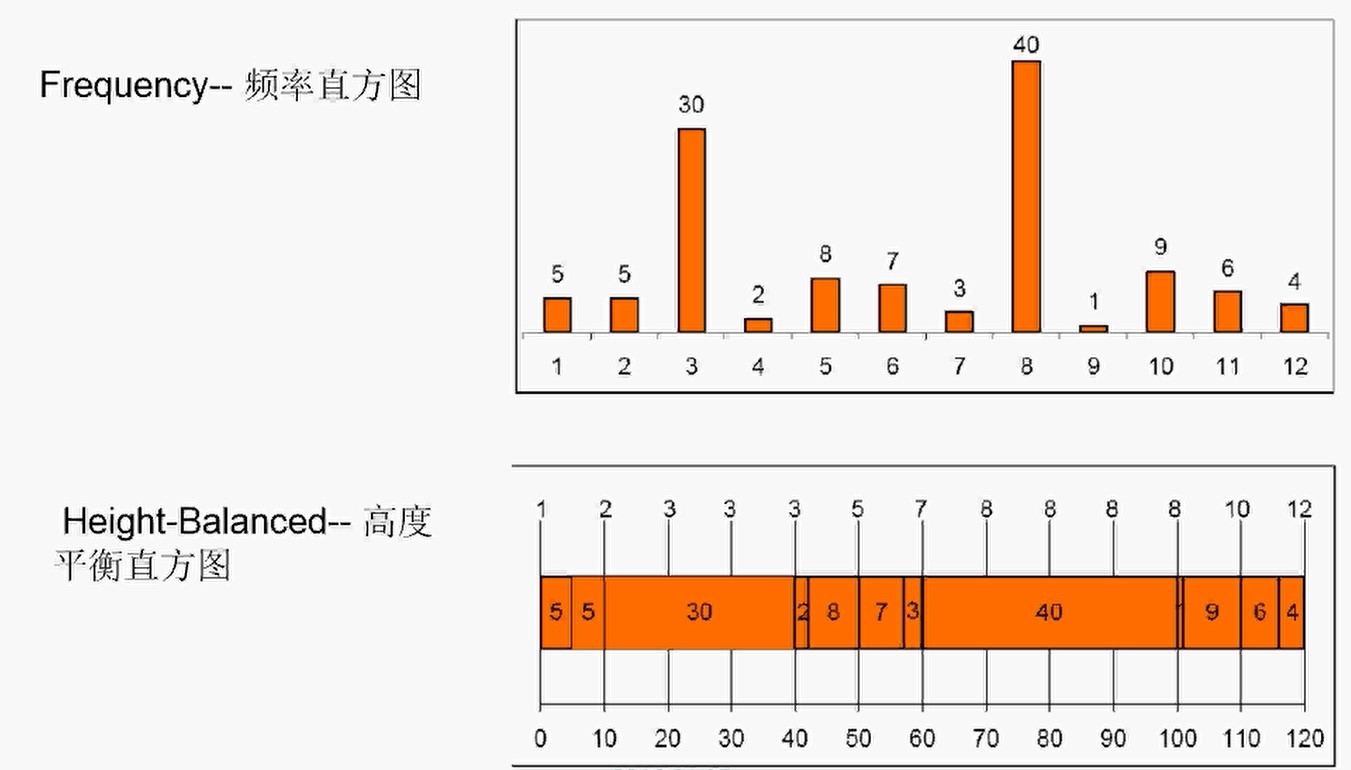
- Frequency:频率直方图。对于重复很多的值的表述方式,给出每个值有多少条记录。如下图,字段共有12种不重复的值,第一种值有5条记录。
- Height-Balance:高度平衡直方图。创建出一个个等宽度的bucket,把数据装在桶里,每个桶里面的数据的量是相同的,但是桶里面的数据值可能不同。如下图,每个桶的宽度是10,第一个桶里装了两个值,每个值有5条数据。第三个值有30条数据,占了3个桶。
示例:
-- 创建一张T表create table t asselect object_Id col1, trunc(rownum/1000) col2from dba_objectswhere rownum < 10000;-- 对所有字段做直方图分析,生成12个bucket来做高度平衡直方图(最大只能设置254个bucket)exec dbms_stats.gather_table_stats(user, 't', method_opt => 'for all columns size 12');-- 查看直方图收集方式-- COL1是HEIGHT BALANCED-- COL2重复项多,是FREQUENCY-- 因为col2的值只有0到9,虽然设置的可以有12个桶,但是分析的时候还是只占用10个桶select column_name, num_distinct, num_buckets, histogramfrom user_tab_col_statisticswhere table_name='T' and column_name='COL1';-- 查看bucket中的数据分布-- 对于高度平衡直方图:endpoint_number是bucket编号,endpoint_value是这个桶里面不重复值的数量-- 对于频率直方图:endpoint_value是字段值,endpoint_number是这个值的个数select endpoint_number,endpoint_valuefrom user_tab_histogramswhere table_name='T' and column_name='COL1';
当表做了数据分析,但是没有进行直方图信息时,得出的执行计划可能也是错的:
-- 将1001以下的数据的col1都更新成1update t set col1=1 where col1<1001;-- 执行表数据分析,但是不收集直方图信息-- 将bucket设置成1,意思是将所有数据都放到一个桶里,和不做直方图收集一样,oracle得不到数据的倾斜信息exec dbms_stats.gather_table_stats(user, 't', method_opt => 'for all columns size 1');-- 此时查看col1=1的语句的执行计划,oracle估算出来的col1=1的记录rows为1条-- 但实际col1=1的记录却是1000条select * from t where col1=1;-- 分配254个bucket进行直方图分析,直方图分析之后oracle便可以估算出非常接近实际的数据条数exec dbms_stats.gather_table_stats(user, 't', method_opt => 'for all columns size 254');
method_opt参数设置:
for all columns:统计所有列的histograms。意义不大,除非该表所有的字段都作为where条件的一部分for all indexed columns:统计所有indexed列的histograms,最常用。for all hidden columns:统计你看不到的列的histograms(伪列、函数等)for columns <list> SIZE <N> | REPEAT | AUTO | SKEWONLY- N取值范围:[1,254]
- REPEAT:上次统计过的histograms
- AUTO:由Oracle决定N的大小
- SKEWONLY:只收集非均匀分布的直方图,系统自动决定bucket数量
Extended Statistics
Oracle 11g出现的技术,解决列的相关性信息。
例如:
-- province='CA'时,counttry_id只会为54790-- 该条sql查询为空select * from customers where province='CA' and country_id=52775;-- 该条sql可以查出来数据select * from customers where province='CA' and country_id=52790;
此时province和country_id两个字段是有相关性的,但是oracle并不知道这种相关性,这样oracle推算出来的rows和实际并不相符。
对字段进行相关性分析:
exec dbms_stats.gather_table_stats(user, 'customers', method_opt =>'FOR ALL COLUMNS SIZE SKEWONLYFOR COLUMNS (PROVINCE, COUNTRY_ID) SIZE SKEWONLY' -- 分析两个字段的相关性);
动态采样
当表上没有分析信息时,oracle会使用动态采样技术。
动态采样发生在SQL硬分析时,oracle在表中随机采集一些有限的数据块,对这些数据块进行分析,根据这些统计信息作CBO计算。实际中,使用动态采样不是可依赖的技术。
oracle使用动态采样时,在trace中可以看到相关信息:
dynamic sampling used for this statement (level=2)
动态采样级别:不同的级别,采样的数据块数量不同。
- level1到level10,采样数据量逐级递增,采样的时间也就越长
- level10 对所有数据进行采样分析
oracle 10g/11g下默认的级别为2
在Oracle 11g出现 Extended Statsitics之前,Oracle 10g使用动态采样分析列的相关性。
动态采样只能作为一种辅助手段。对于海量数据,动态采样的数据块太少,无法准确的反应数据的真实情况。
如果采样率高,会直接影响sql的执行效率。
而DBMS_STATS可以非常灵活的进行数据分析配置(分析比例、分析时间、直方图、分析数据的管理)

若有收获,就点个赞吧
0 人点赞
