Raft 协议被广泛实现或者参照,准确理解这个协议很有意义。
先上重要的参考链接:
- 理解其如何工作: http://thesecretlivesofdata.com/raft/#overview
官方用动图讲解其如何工作。 - 了解更多细节特性: https://cloud.tencent.com/developer/article/1826594
作者参考官方论文做的总结,可以快读掌握精髓。 - 进一步掌握其细节,阅读论文原文: https://raft.github.io/raft.pdf
- Raft 是一个共识算法, 所谓共识算法,是对某个事件达成一致的看法。
- Raft 算法包含三个方面:
- 选举算法 (leader election)
- 日志复制 (log replication)
- 一致性和安全性 (safety)
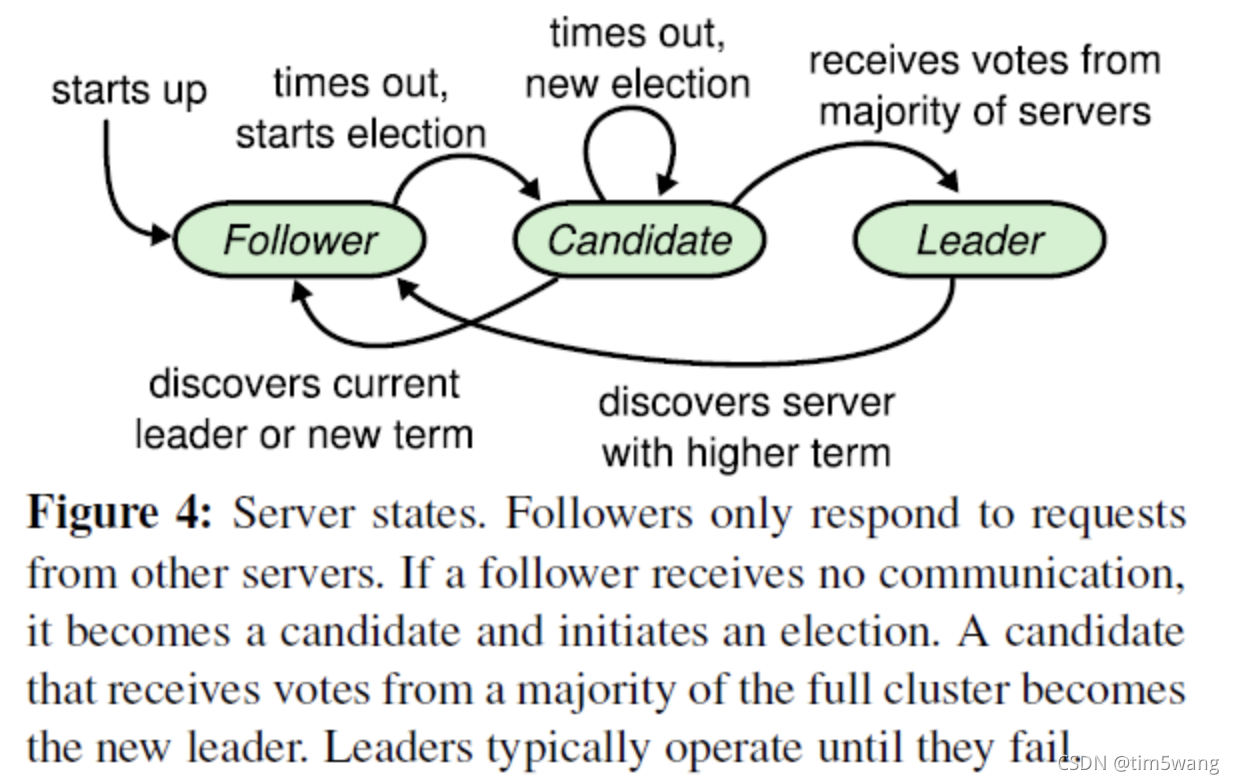
- 节点角色
- Leader 主节点,所有请求的处理者,接收客户端发起的操作请求,写入本地日志后同步到其他集群其他节点
- Candidate 候选节点,当 Follower 一段时间收不到 Leader 的心跳,就会称为候选节点,发起选主
- Follower 从节点,接收主节点的日志,同步主节点的数据
选举过程
- 所有节点启动时都是 follower 状态, 在 一段时间(每个节点会有一个长度具有随机性的超时时间)如果没有收到来自 leader 的心跳,follower 切换为 candidate , 并发起选举。
- 如果收到了 majority 的选举票(包含自己的一票),那么切换为 leader 状态。
- 如果发现其他节点比自己更新,则主动切换为 follower
- 系统中只会存在一个 leader, 如果一段时间内没有 leader, 那么大家通过选举的方式选出 leader. leader 不停的向 follower 发出心跳,表面 leader 的存活状态, 如果 l leader 故障,follower 会切换成 candidate 选举出新 leader。
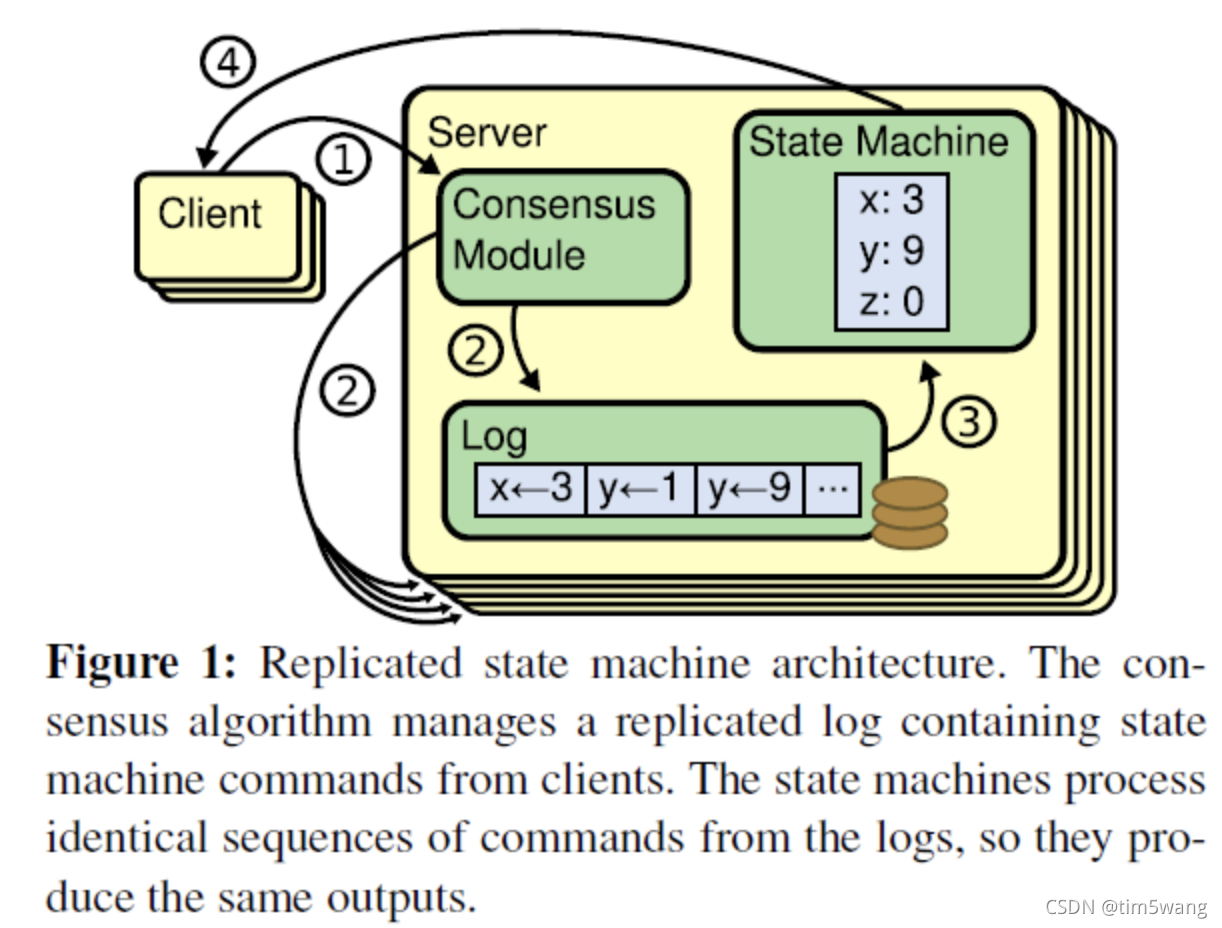
日志复制
相同的初始状态 + 相同的输入 = 相同的结束状态
因此同步的过程会先同步日志(输入),然后 Leader 一声令下,Apply 到各自本地
leader 选举出来后,就承担了领导整个集群的责任,开始接受客户端请求,并将操作包装成日志,发送给其他节点。
- leader 为客户端提供服务, 客户端的每个请求都包含一条被状态复制机执行的指令。
- leader 把该指令作为一个新的日志附加到自身的日志集合。然后向其他节点发起附加请求条目(AppendEntries RPC)。来要求其他节点将日志附加到自己的本地日志集合中。
- 当这条日志确保被安全复制,即 (N/2 +1) 节点有复制后,leader 将该日志 apply 到他本地的状态机中,然后把操作成功的结果返回给客户端。
https://blog.csdn.net/sinat_34820292/article/details/120121881

若有收获,就点个赞吧
0 人点赞
