日志基础
官网
日志架构 | Kubernetes
系统日志 | Kubernetes
Filebeat
https://segmentfault.com/a/1190000019714761
sidecar模式
ElasticSearch
《2万字详解,彻底讲透 全文搜索引擎 Elasticsearch》
https://mp.weixin.qq.com/s/H-NyIMR8gJmVChKFQq5QuA
云平台
架构
Filebeat ———>>>Kafka———>>> Logstash ———>>>ES ———>>>Kibana

操作方法
云平台上,新建或编辑工作负载,点击开通日志采集;
Kibana
ES
实践案例
《Kubernetes业务日志收集与监控》
日志、监控
https://mp.weixin.qq.com/s/Fo86nTiIonmBfRpHVSWbUg
《使用 EFKLK 搭建 Kubernetes 日志收集工具栈》
Fluentd,Kafka,Logstash,ES,Kibana
https://mp.weixin.qq.com/s/lPeYavvFJ6GdivkT0iwTGw
对于大规模集群来说,日志数据量是非常巨大的,如果直接通过 Fluentd 将日志打入 Elasticsearch,对 ES 来说压力是非常巨大的,我们可以在中间加一层消息中间件来缓解 ES 的压力,一般情况下我们会使用 Kafka,然后可以直接使用 kafka-connect-elasticsearch 这样的工具将数据直接打入 ES,也可以加一层 Logstash 去消费 Kafka 的数据,然后通过 Logstash 把数据存入 ES
安装 Elasticsearch 集群
部署 Fluentd
安装Kafka
Fluentd 配置 Kafka
安装Logstash
《一文彻底搞定 EFK 日志收集系统》
Fluentd ,ES,Kibana
https://mp.weixin.qq.com/s/8WA28Ao6frtLcNvpBmJANw
cluster.name:Elasticsearch 集群的名称,我们这里命名成 k8s-logs。node.name:节点的名称,通过 metadata.name 来获取。这将解析为 es-[0,1,2],取决于节点的指定顺序。discovery.seed_hosts:此字段用于设置在 Elasticsearch 集群中节点相互连接的发现方法。由于我们之前配置的无头服务,我们的 Pod 具有唯一的 DNS 域 es-[0,1,2].elasticsearch.logging.svc.cluster.local,因此我们相应地设置此变量。要了解有关 Elasticsearch 发现的更多信息,请参阅 Elasticsearch 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html。discovery.zen.minimummasternodes:我们将其设置为 (N/2)+1, N是我们的群集中符合主节点的节点的数量。我们有3个 Elasticsearch 节点,因此我们将此值设置为2(向下舍入到最接近的整数)。要了解有关此参数的更多信息,请参阅官方 Elasticsearch 文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html#split-brain。ESJAVAOPTS:这里我们设置为 -Xms512m-Xmx512m,告诉 JVM使用 512MB的最小和最大堆。您应该根据群集的资源可用性和需求调整这些参数。要了解更多信息,请参阅设置堆大小的相关文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html。
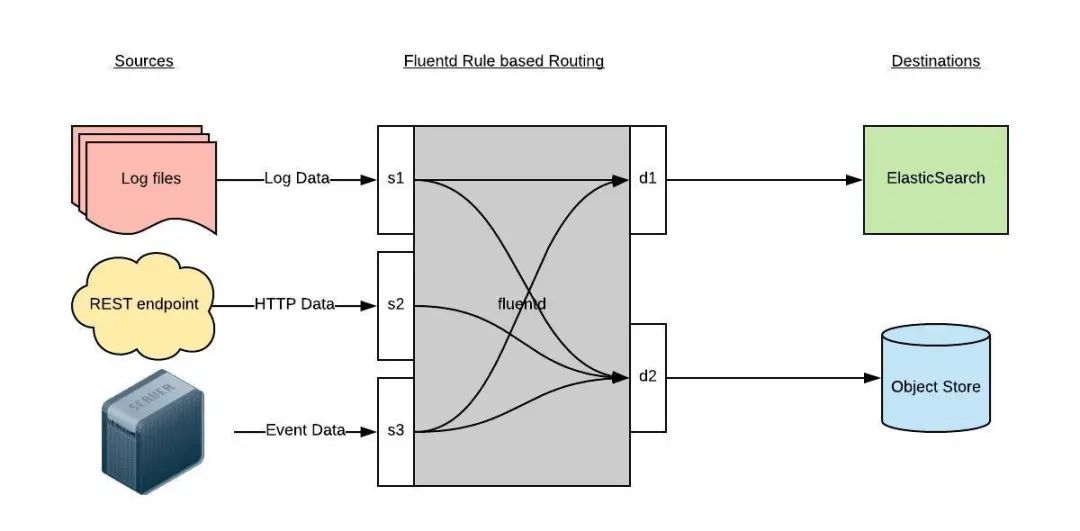
Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等。Fluentd 支持超过300个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下:
- 首先 Fluentd 从多个日志源获取数据
- 结构化并且标记这些数据
- 然后根据匹配的标签将数据发送到多个目标服务去

若有收获,就点个赞吧
0 人点赞
