1. 简介
知识图谱本质上是语义网络(Semantic Network)的知识库。从实际应用的角度,知识图谱可理解为多关系图
**
1.1 Graph
图是由节点Vertex和边Edge来构成
- 实体(节点):现实中的事物,包括人、地名、概念、药物、公司
- 关系(边):表达不同实体间的联系
1.2 Schema
用于限定待加入知识图谱的数据格式;相当于某个领域内的数据模型,包含概念类型,以及类型属性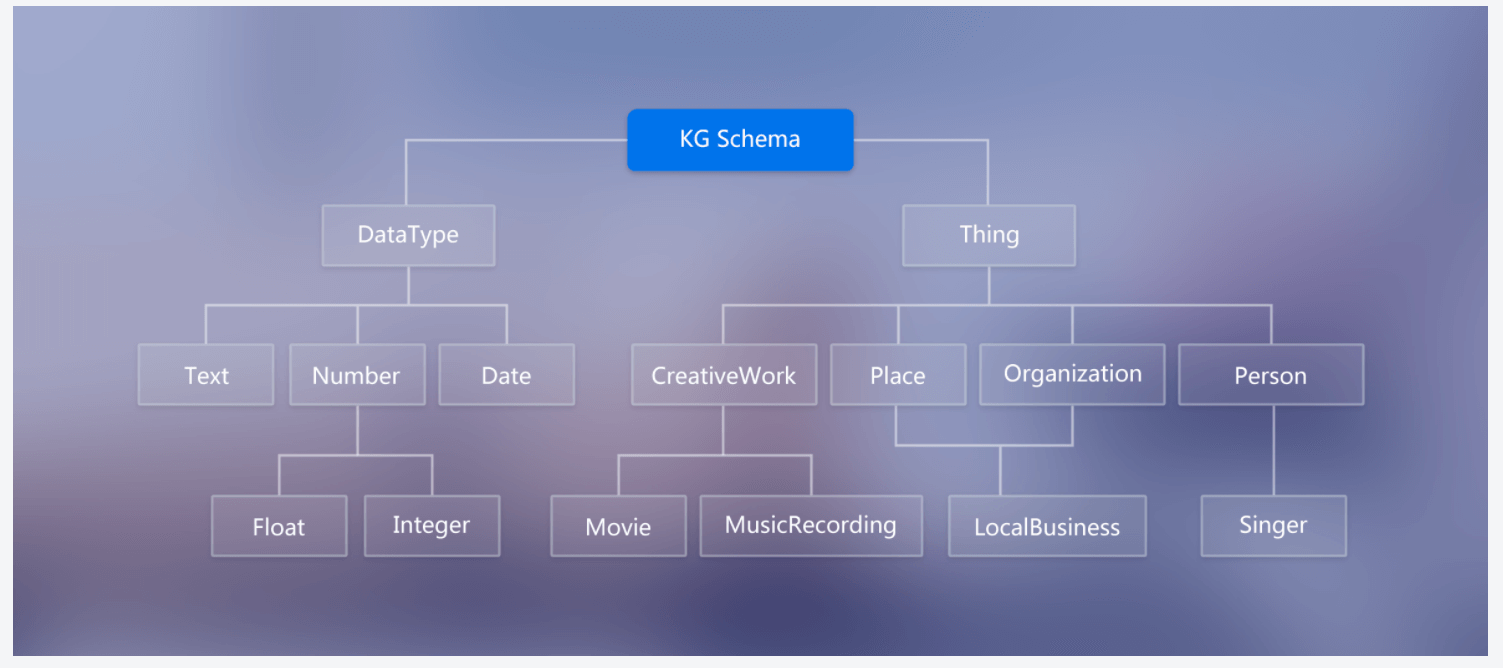
作用:
2. 知识图谱的构建
2.1 数据源
- 业务本身数据
- 网络公开数据(爬虫),需要借助NLP技术来提取结构化信息
2.2 构建所需NLP技术
1. 实体命名识别 (Name Entity Recognition)
从文本中提取出实体,并对每个实体分类/打标签
例如:实体 NYC,类型-Location
(可使用现有工具实现)
2. 关系抽取 (Relation Extraction)
从文本中提取实体之间的关系
e.g. “is”, “in”, “near” …
3. 实体统一 (Entity Resolution)
有些事物具有不同的称呼,但指向同一个实体,需要做合并;实体统一不仅可以减少实体的种类,也可以降低图谱的稀疏性(sparsity)
e.g. NYC/New York
4. 指代消解 (Coreference Resolution/Disambiguation)
对于文本中的代词,确定其指向那个实体
3. 知识图谱的存储
3.1 RDF的存储
(Resource Description Framework)
- 优势:数据的易发布和共享
- 以三元组方式存储数据,但不包含属性信息
-
3.2 图数据库的存储
优势:高效的图查询和搜索
- Neo4j | | RDF | 图数据库 | | —- | —- | —- | | 存储 | 三元组Triple | 节点和关系可以带有属性 | | 标准推理引擎 | 有 | 没有 | | | W3C标准 | 图的遍历效率高 | | 优势 | 易于发布数据 | 事务管理 | | 使用场景 | 学术界 | 工业界 |

若有收获,就点个赞吧
0 人点赞
