*类名称必须与文件名称保持一致。
*Java语言有着明确的要求,定义类名称的时候必须每一个单词的首字母大写。
*Java的主方法名称定义非常的长:public static void main(String[] args){ 程序的代码由此开始执行}
*输出之后追加换行:Ssytem.out.println(输出内容);
*输出之后不追加换行:System.out.print(输出内容)、ln(line、换行);
*JVM解释程序的时候需要得到CLASSPATH的支持。
*CALSSPATH的默认设置为当前加载类文件。
*SET CLASSPATH=. ———-从当前所在路径加载类
面试题:请问PATH与CLASSPATH的区别?
PATH:是操作系统提供的路径配置,定义所有可执行程序的路径;
(Java定义的,在Java程序解释时使用的)CALSSPATH:是由JRE提供的,用于在定义Java程序解释时类加载路径,默认设置的为当前所在目录加载,可以通过“SET CLASSPATH=路径”的命令形式进行定义;
-关系:JVM→CLASSPATH定义的路径→**加载字节码文件
*注释:(对于一些重要的类与方法—文档注释)
本质:编译器在进行程序编译的时候如果发现有注释的内容将不对此部分进行编译处理,在Java语言里面对于注释一共有三类形式:
1.单行注释://;
2.多行注释:/ …/;
3.文档注释:/…/,文档里面注释(一般开发工具去控制)
**标识符与关键字:
对于结构的说明实际上就是标识符:字母、数字、_、$ 所组成,不能使用数字开头、Java中的保留字。 **最简单的定义:使用英文字母开头数字和下划线为辅。
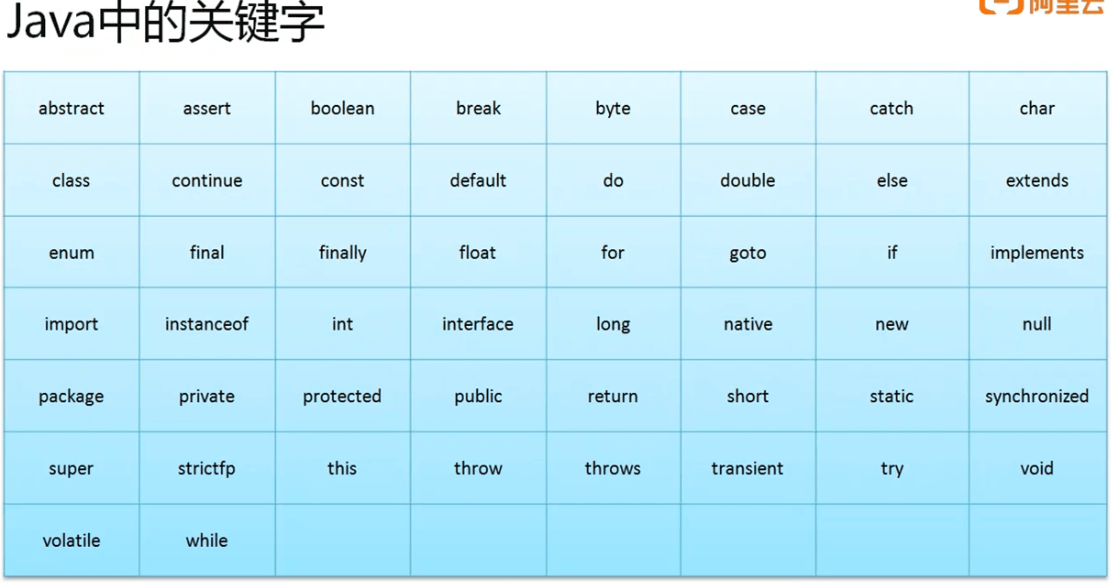
*说明:
- JDK 1.4 的时候出现有assert 关键字,用于异常处理上;
- JDK 1.5 的时候出现有enum 关键字,用于枚举定义上;
- 未使用到的关键字:goto、const;
- 有一些属于特殊含义的单词,严格来讲不算是关键字:ture 、false 、null;
数据类型:
- 基本数据类型:描述的是一些具体的数字单元。
1.数值型:
a.整型(从小到大):byte、short、int、long; **→ **默认值:0
注:只要是整型常量 **→ **int;
//int max = Integer.MAX_VALUE; //获取int的最大值;
当超过int计算能力:最大值 + 1=最小值;
超过了最大保存范围,出现了循坏现象,称为数据溢出;**→ **1.预估;2.追加在“L”或变成long型
- 程序支持有数据转换,但如果不是必须的情况下不建议这种转换;
- byte类型特别需要注意,首先这个类型的范围是:-128~127之间,保存的数据量很小;
注:如果没超过byte范围的常量可以自动用int变为byte,如果超过就必须进行强制转换;
**对于常量可以自动适配转换,但对于变量必须进行强制转换
b.浮点型:float、double; → 默认值:0.0
注:描述小数建议 → double;**float时需要强制转型;
2.布尔型:boolean; → 默认值:false
3.字符型:char; → 默认值:’\u0000’
注:字符都可以与int进行互相转换;
大写字母的范围:“A”(65) ~ “Z”(97);
小写字母的范围:“a”(97) ~ “z”(122); 大小写差了32个数字的长度;
“数字的范围”:‘0’(48)~‘9’(57);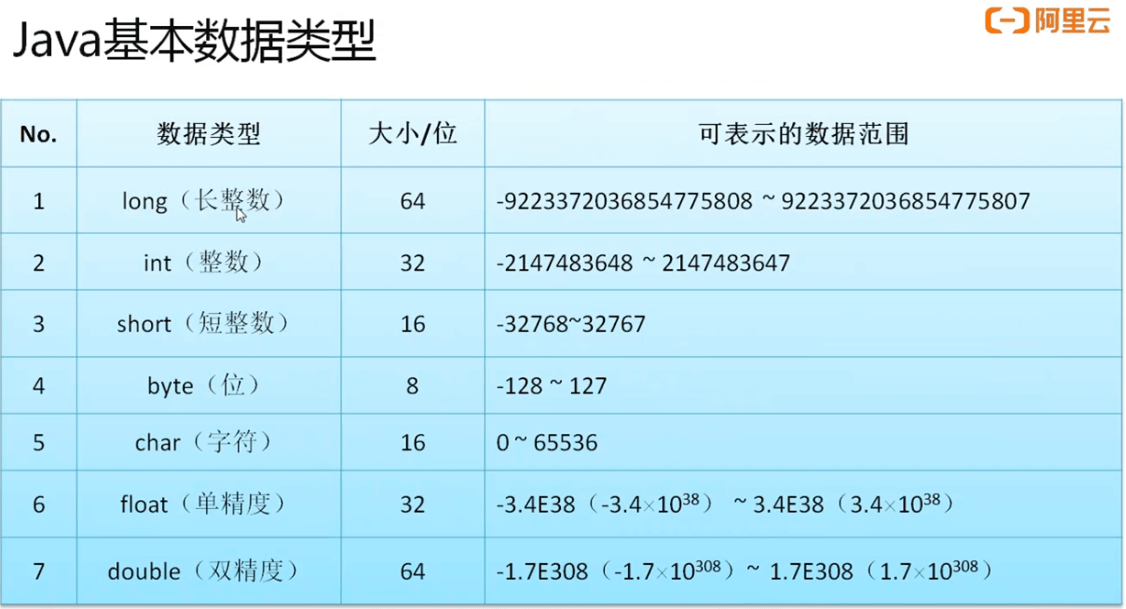
注:*char可以保存中文
*整型不保存小数点
*数据类型进行自动转型的时候都是由小类型向大类型进行自动转换处理;
描述数字一般首选:*int(整数)、double(小数);
进行数据传输或者进行文字编码转换使用**byte(二进制处理操作);
** 处理中文的时候最方便的操作是char(可选概念)类型;
内存或文字大小、描述表的主键列(自动增长)**long;
String字符串:作为字符串的定义,可以像普通变量采用直接赋值的方式来进行字符串的定义,且使用“”进行描述。
可以使用“+”进行字符串的连接;
如果有String字符串无条件转变String字符串;*
- 引用数据类型:**牵扯到内存关系的使用;**
数组、类、接口。 **→ **默认值:null
运算符:**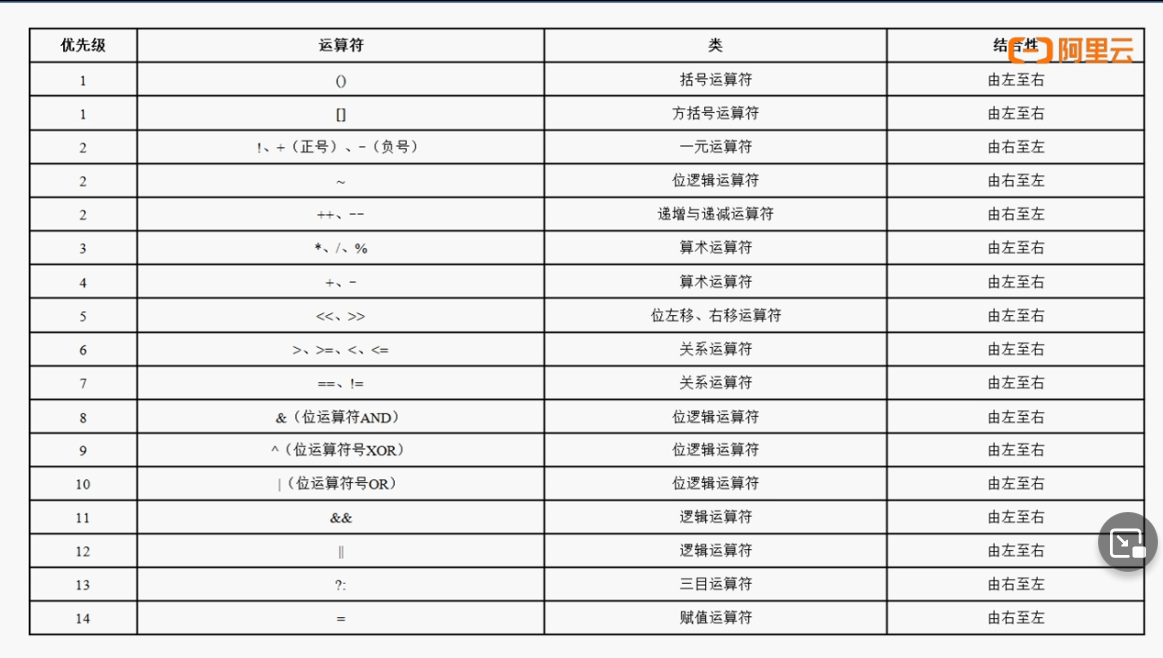
- ++变量、—变量:先进行变量的自增或自减,而后再进行数字的计算;
- 变量++,变量—:先使用变量进行计算,而后再进行自增或自减;
- 所有的关系运算返回的都是布尔类型
三目运算:关系运算?关系满足时的内容:关系不满足时的内容;
位运算:与(&)、或(|)、异或(^)、反码(~)、移位处理。
十进制与二进制的转换处理逻辑!
面试题:请解释&和&&、|和||的区别?
&和|两个运算符可以进行关系运算与逻辑运算;**
- 在进行逻辑运算的时候所有的判断条件都要执行;
- 在进行位运算的时候只是针对于当前的数据进行与和或处理
在逻辑运算上还可以使用&&、||;
- &&:在若干个条件判断的时候,如果前面的条件返回了false,后续所有的条件都不再判断最终的结果就是false;
- ||:在若干个条件判断的时候,如果前面的条件返回了true,后续所有的条件都不再判断最终的结果就是true;
**Java程序逻辑控制(顺序、分支、循坏)——if分支结构
- 顺序结构:所有的程序将按照定义的代码顺序依次执行。
if分支结构:
if分支结构主要是针对关系表达式进行判断处理的分支操作。分支语句:if、else
if判断;**if(布尔表达式){条件满足时执行;}
if else判断;**if(布尔表达式){条件满足时执行;}else if (布尔表达式){条件满足时执行} 【 else {条件不满足时执行;}】**(可以循环一直写!)
多条件判断;
Switch分支语句(字符串是JDK1.7以后才支持的):
Switch是一个开关语句,它主要是根据内容来进行的判断,需要注意的是Switch中可以判断的只能够是数据(int、char、枚举、String)而不能使用逻辑判断。
** Switch(数据){ case 数值:{ 数值满足时执行 ; 【break】} case 数值 :数值满足时执行 ; 【break】 【default:所以判断都不满足时执行; 【break;】】}
Switch语句在进行设计的时候,如果你在每一个case后面没有追加break语句,那么会在第一个匹配的case之后继续执行,一直到全部的Switch中的后续代码执行完毕或者遇见break。
Switch重要的语句break
while循环结构:
所谓的循环结构指的是某一段代码被重复执行的处理操作,在程序之中提供有while语句来实现循环的定义,该语句有两类型;
** 1、 while(布尔表达式){条件满足时执行 ; 修改循环条件;}
** 2、do {条件满足时执行; 修改循环条件;} while(布尔表达式);
while循坏与do…while循坏的最大差别:
**while循坏是先判断后执行,而do…while先执行一次后判断。开发中能见到do…while循坏的几率几乎为1%,首选的肯定是while循坏。
for循坏结构:
for循坏也是一种常规的使用结构。
** 1、for(定义循坏的初始化数值;循坏判断;修改循环数据){循环语句的执行;}
对于while和for循环的选择只有一个参考标准:
- 在明确确定循环次数的情况下优先for循环;
- 在不知道循环次数但是知道循环结束条件的情况下使用while循环;
达到大大王打打我的达瓦大大王
循环控制
**

若有收获,就点个赞吧
0 人点赞
