单机模式
Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。非分布式即单Java进程,方便进行调试。
Prerequisites
- Ubuntu 20.04
- Java 8
- SSH
# 安装ssh$ sudo apt-get install openssh-server# 配置ssh key$ cd ~$ mkdir .ssh # 如果该文件存在则忽略此命令,不影响$ cd ~/.ssh$ ssh-keygen -t rsa$ cat id_rsa.pub >> authorized_keys
Install Hadoop
# 下载Hadoop软件压缩包$ cd ~/Desktop$ wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz$ sudo tar -zxvf hadoop-3.3.1.tar.gz # 将软件压缩包解压到当前文件夹
检测是否安装成功
如果出现$ cd ~/Desktop/hadoop-3.3.1 # 进入hadoop文件目录# 查看hadoop版本,正确输出版本号则安装成功$ ./bin/hadoop version
JAVA_HOME is not set and could not be found报错执行以下命令:
- 查找jdk包名:
$ ls /usr/lib/jvm

- 打开
.bashrc文件:$ vim ~/.bashrc 在打开文件的末尾追加以下几行内容
export JAVA_HOME=/usr/lib/jvm/<此处填写第一步找到的jdk包名>export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:$PATH

保存并退出,输入
source ~/.bashrc更新即可。重新检测hadoop是否安装成功。
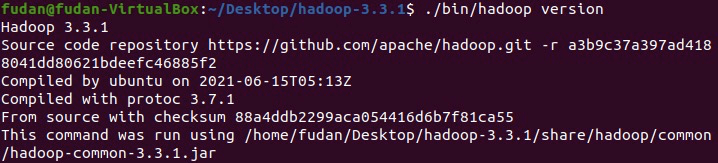
运行示例
hadoop单机模式提供了很多例子供我们尝试
# 输入如下命令会显示hadoop自带的各种例子$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar
wordcount例子演示
$ cd ~/Desktop/hadoop-3.3.1 # 进入hadoop文件目录下$ mkdir input # 创建input文件夹保存需要传入Hadoop中处理的数据$ cp etc/hadoop/*.xml input # 将文件拷贝到input文件夹中,也可以自己生成一些文本文件$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount input output # 运行Hadoop处理input中的数据$ ls output # output文件夹下可以看到运行结果情况$ cat output/part-r-00000 # 查看运行结果
伪分布式模式
Hadoop可以在单个主机上以伪分布式的方式运行,Hadoop进程以分离的Java进程来运行,该主机既作为NameNode也作为DataNode。同时,Hadoop系统现在读取的是HDFS中的文件。
注意:伪分布式模式是在单机模式基础上进行开发,单机模式必须安装测试成功后才能进行伪分布式模式配置。配置步骤(在hadoop-3.3.1文件目录下运行)
修改配置文件
etc/hadoop/core-site.xml, 用于设置HDFS访问路径<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
修改配置文件
etc/hadoop/hdfs-site.xml<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:Your_Hadoop_Folder_Dir/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:Your_Hadoop_Folder_Dir/tmp/dfs/data</value></property></configuration>
修改配置文件
etc/hadoop/hadoop-env.shexport JAVA_HOME=/usr/lib/jvm/<你电脑上所安装的jdk包名># 如果不知道包名可通过 ls /usr/lib/jvm 查看
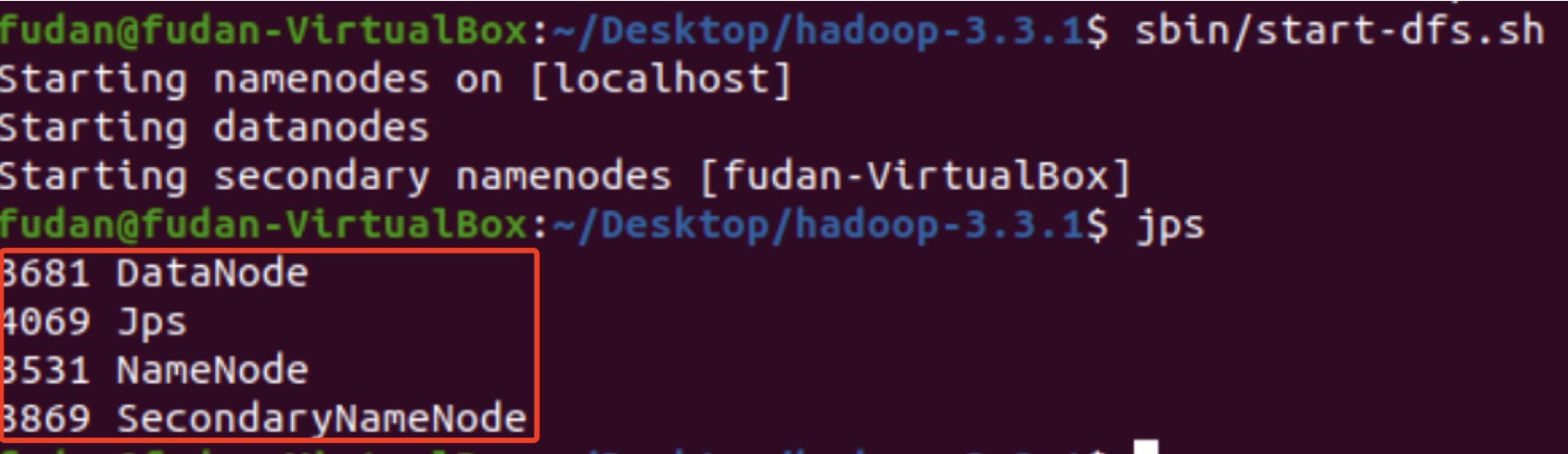
启动Hadoop
$ bin/hdfs namenode -format # namenode格式化$ sbin/start-dfs.sh # 开启守护进行# 判断是否启动成功。若成功启动则会列出如下进程: NameNode、DataNode和SecondaryNameNode。$ jps
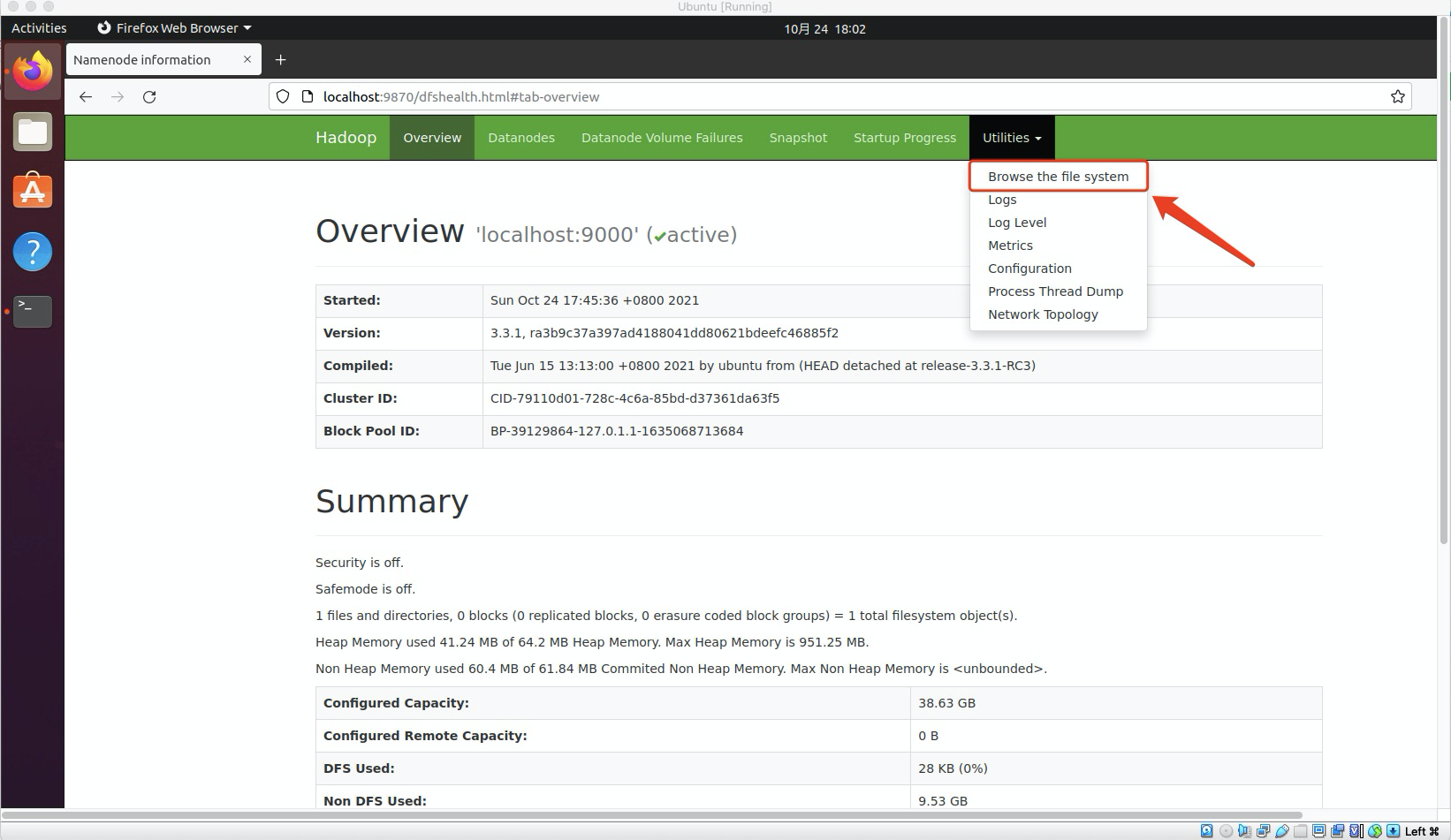
此时打开Ubuntu自带浏览器,输入URL
http://localhost:9870可以查看NameNode,DataNode信息,还可以在线查看HDFS中的文件。
运行示例
创建当前用户的HDFS目录
$ bin/hdfs dfs -mkdir /user$ bin/hdfs dfs -mkdir /user/<your_username>
在HDFS中创建input文件夹并上传数据
$ bin/hdfs dfs -mkdir input$ bin/hdfs dfs -put etc/hadoop/*.xml input
运行wordcount程序
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount input output
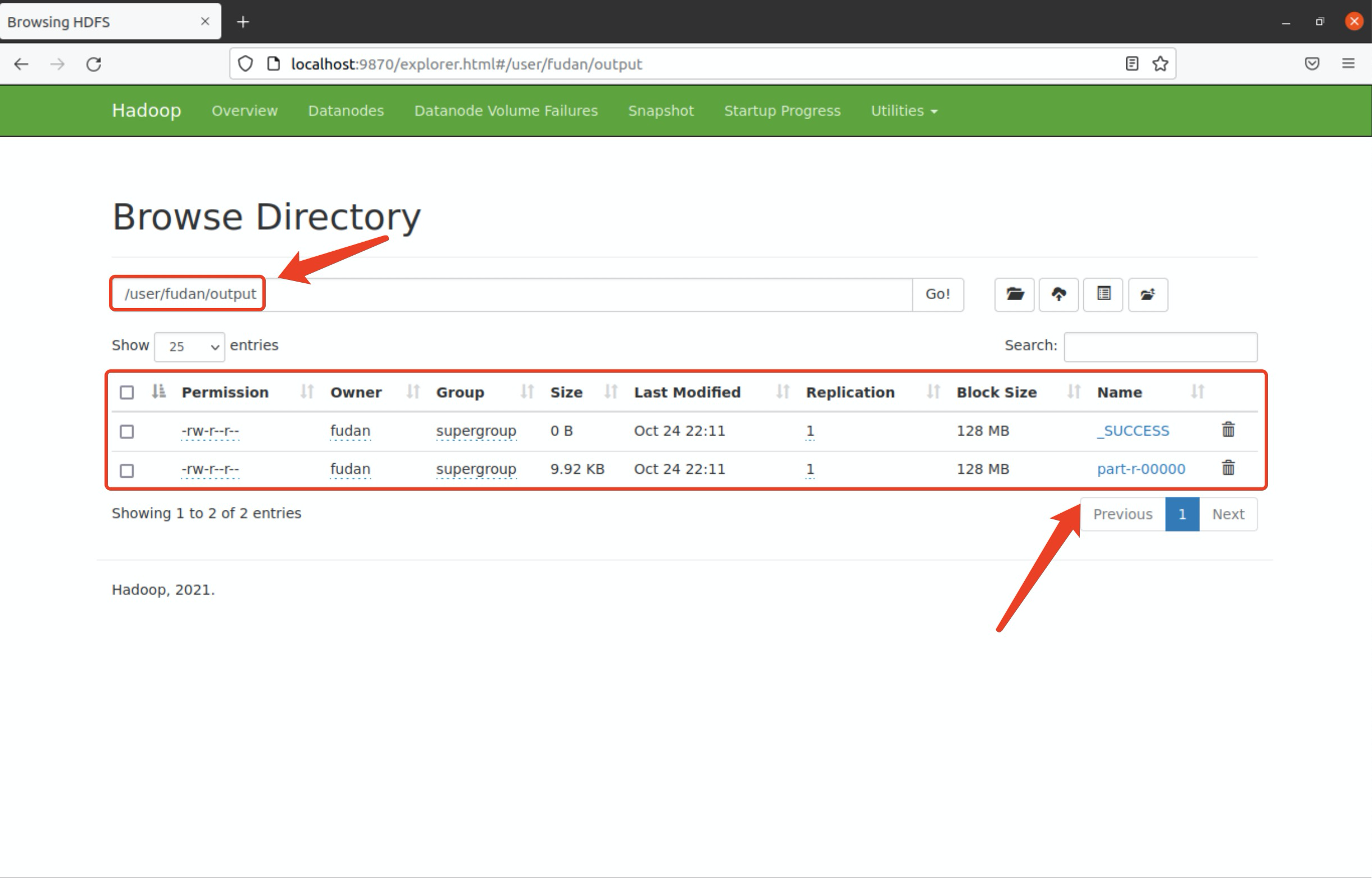
在HDFS中查看运行结果或将结果拷贝至本地
# 在HDFS中查看运行结果$ bin/hdfs dfs -cat output/*# 将运行结果拷贝至本地查看$ bin/hdfs dfs -get output output$ cat output/*
运行结束终止进程
$ sbin/stop-dfs.sh
分布式模式
Prerequisites
- 选定master节点, 在master节点上安装Hadoop, java环境, SSH, 并修改Hadoop配置信息
- 在其他slave节点上安装java环境, SSH
- 将master节点上的hadoop文件夹复制到其他slave节点上
- 在master节点上启动Hadoop, 查看运行状态
网络配置
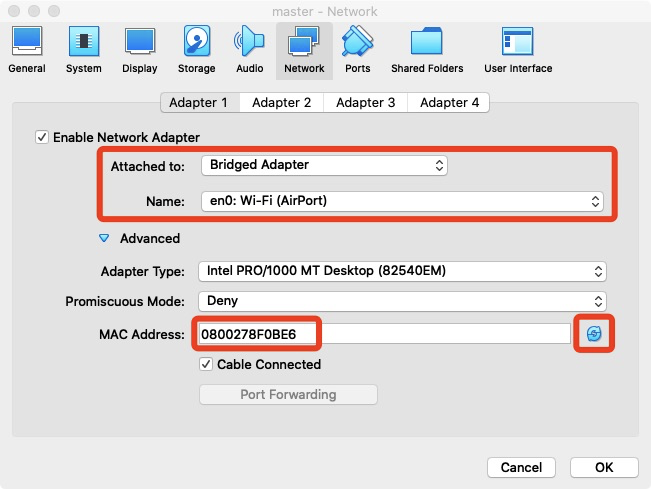
- 因为我们是虚拟机安装的系统, 所以需要更改网络连接方式为桥接(Bridge)模式, 才能实现多个节点互联
- 确保各个节点的MAC地址不同 (可以点右边的按钮随机生成 MAC 地址,否则 IP 会冲突)
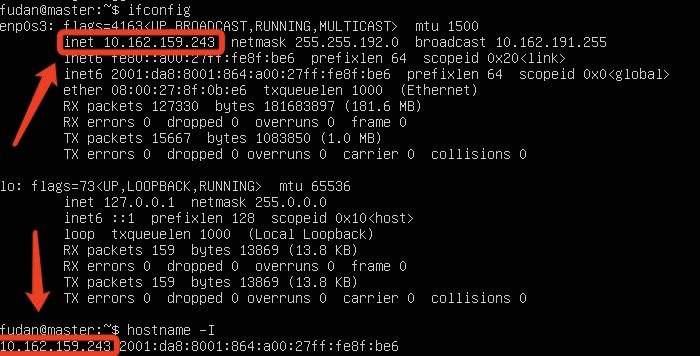
- Linux查看节点IP地址的命令为
ifconfig或hostname -I, 即下图所示的inet地址
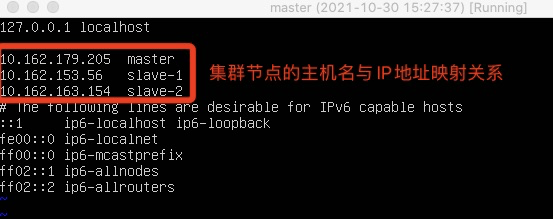
- 为了便于区分每个节点, 我们可以修改各个节点上的主机名, 以方便区分
- 执行命令
sudo vim /etc/hostname修改主机名 - 修改hostname中的配置信息, 更换为你想换成的节点名称即可
- 执行命令
sudo vim /etc/hosts修改自己所用节点的IP映射 - 重启系统
- 执行命令
- 如上所述是单个结点的网络配置, 我们还需要再其他所有节点上完成类似修改
配置成功检验方法: 在各个
ping其他节点, 如果ping的通, 说明配置成功$ ping master -c 5 # -c指定ping的次数$ ping slave1 -c 5
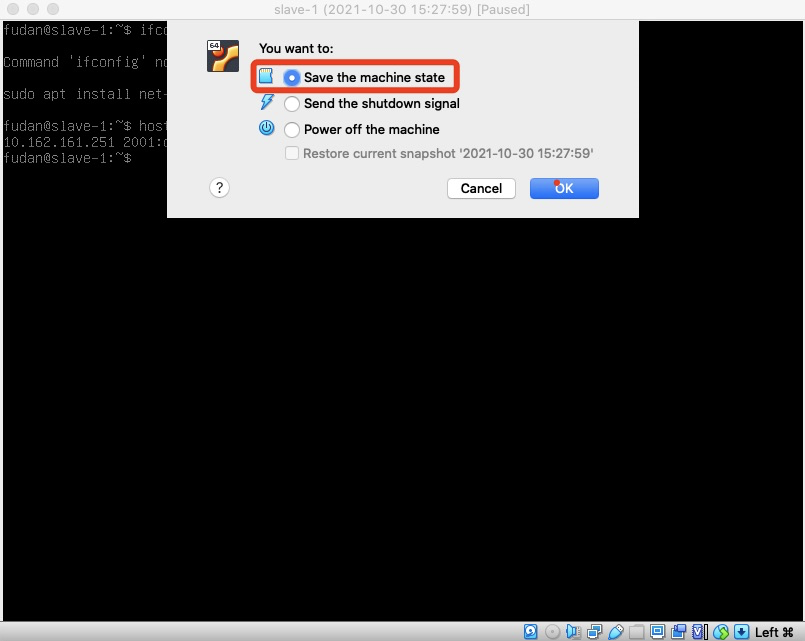
注意: 网络配置成功后, 每次关闭虚拟机不要选择直接关闭, 选择保存当前状态关闭, 不然下次重新打开可能会更换IP, 所有网络配置都需要重新进行!
SSH无密码登录节点
这个操作是要让master节点可以无密码SSH登录到各个slave节点上
首先生成master节点的公钥 (因为改过主机名, 所以还需要删除原有的再重新生成一次), 在master节点上执行如下操作
$ cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost$ rm ./id_rsa* # 删除之前生成的公匙(如果有)$ ssh-keygen -t rsa # 一直按回车就可以
让master节点能无密码SSH本机, 在master节点上执行:
$ cat ./id_rsa.pub >> ./authorized_keys
完成后可以尝试
ssh master验证一下 (成功后执行exit返回原来的终端), 接着在master节点上将公钥传输到各个slave节点$ scp ~/.ssh/id_rsa.pub root@slave1:/home/fudan/
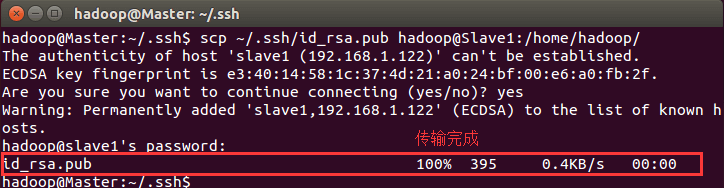
接着在各个slave节点上将ssh公钥加入授权
$ mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys$ rm ~/id_rsa.pub # 用完就可以删掉了
在master节点上验证是否可以无密码ssh到各个slave节点
$ ssh slave1$ ssh slave2
配置集群环境
概述
配置集群环境只需要在master节点中修改即可, 修改完之后复制hadoop文件夹到各个slave节点。
- 配置集群环境需要修改hadoop目录下
etc/hadoop下的5个配置文件, 本文仅设置正常启动所必须的设置项, 更多设置可点击查看官方说明 - 配置好master节点的hadoop配置后, 删除hadoop文件夹中的tmp文件夹和logs文件夹(如果存在), 打包hadoop文件夹分发至slave节点上
master节点配置文件修改
workers文件: 将DataNode的主机名写入该文件, 每行一个slave1slave2
core-site.xml文件: 修改HDFS访问URL<configuration><property><name>hadoop.tmp.dir</name><value>Your_Hadoop_Folder_Dir/tmp</value></property><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property></configuration>
hdfs-site.xml文件: 修改replication, secondary namenode URL, datanode和namenode数据存储路径<configuration><property><name>dfs.namenode.secondary.http-address</name><value>master:50090</value></property><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.name.dir</name><value>file:Your_Hadoop_Folder_Dir/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:Your_Hadoop_Folder_Dir/tmp/dfs/data</value></property></configuration>
mapred-site.xml: 配置MapReduce执行框架, JobHistory信息<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property></configuration>
yarn-site.xml: 配置yarn框架ResourceManager和NodeManager<configuration><property><name>yarn.resourcemanager.hostname</name><value>master</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
处理打包并分发到slave节点
删除hadoop文件夹目录下的logs文件夹和tmp文件夹(如果有)
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件sudo rm -r ./hadoop/logs/* # 删除日志文件
执行namenode的格式化
$ ./bin/hdfs namenode -format
打包hadoop文件夹并分发
在master节点上启动Hadoop即可
$ ./sbin/start-dfs.sh$ ./sbin/start-yarn.sh$ ./sbin/mr-jobhistory-daemon.sh start historyserver
通过
jps查看各个节点所启动的进程
master节点: 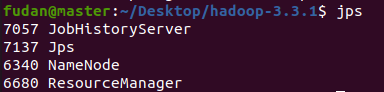
slave1节点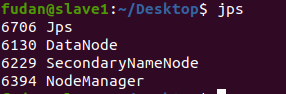
slave2节点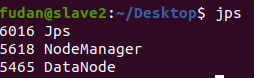
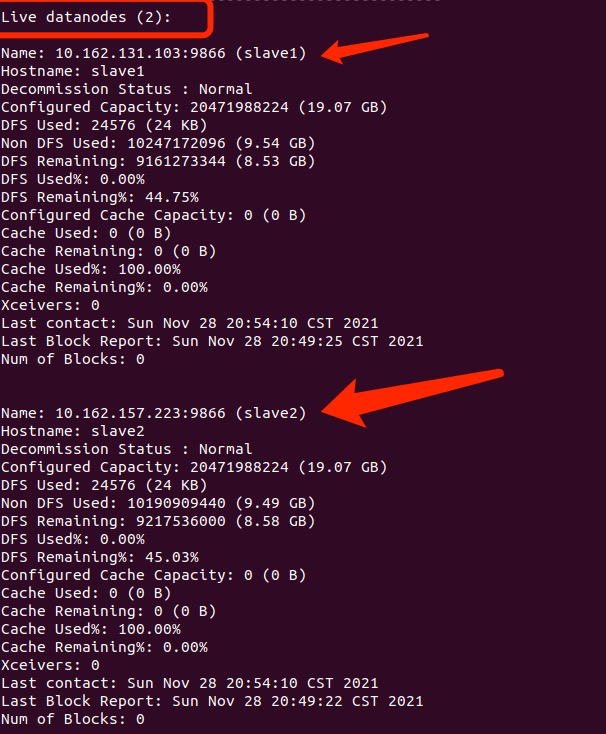
- 在master节点通过
./bin/hdfs dfsadmin -report查看DataNode是否启动正常

若有收获,就点个赞吧
0 人点赞
