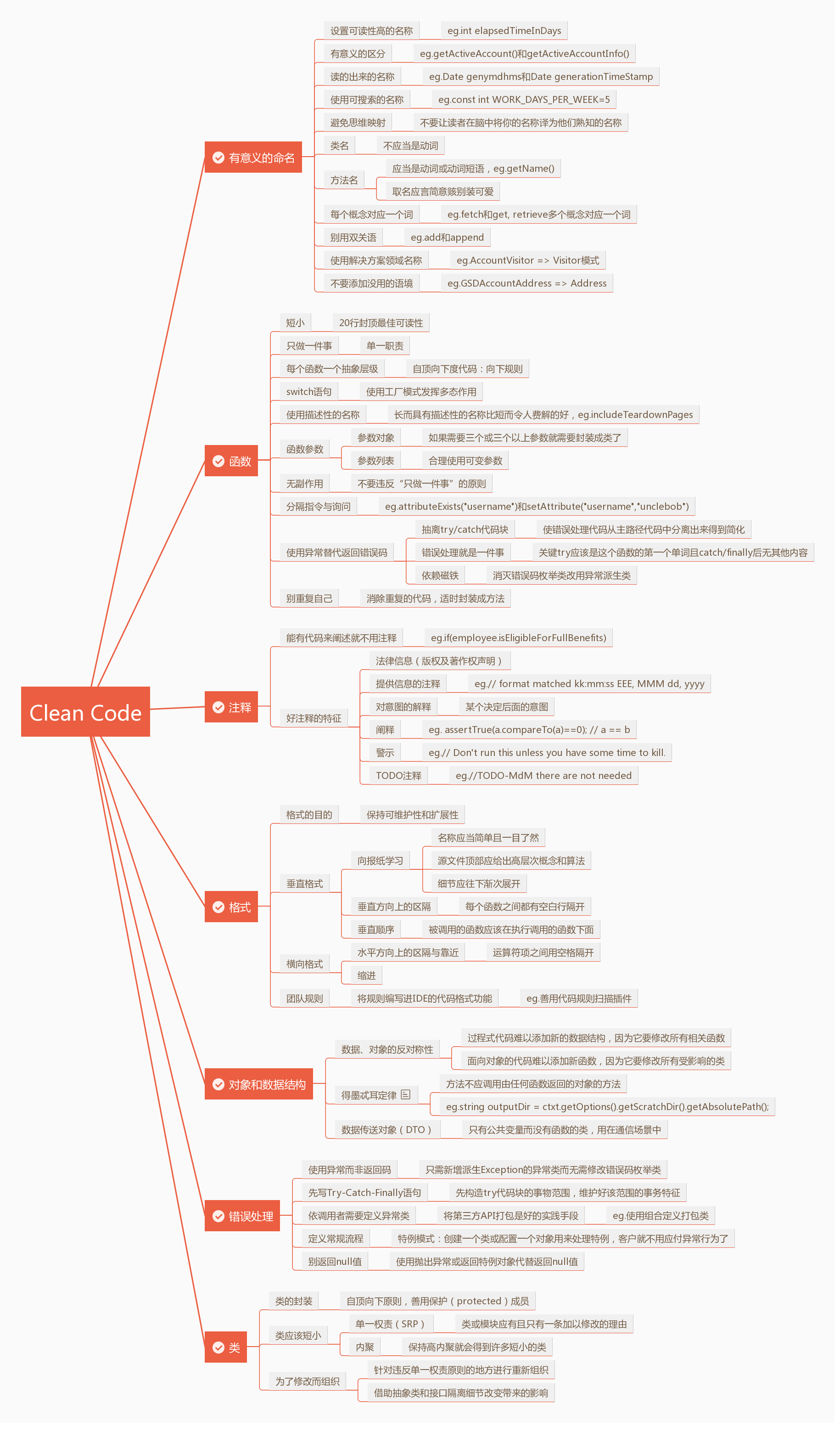
《Clean Code》重点内容总结
1. 有意义的命名
对变量、方法命好名的关键在于:
1) 名副其实,能够通过名称知道变量、方法的作用意义;
2) 避免误导,选用变量(方法)真实含义,并需要有意义地区分不同名称,而非添加数字;
3) 表达明确,不要让读者“翻译”你的名称,适当添加有意义的语境;
4) 避免前缀,概念唯一,注意词性;
1.1. 名副其实
变量、函数或类的名称应该做到能够所有的大问题,因此,注意命名,一有好的名字就换掉旧的,Eclipse的“Ctrl + 2 + R”组合键可以帮上不少忙。
注意,如果名称需要用注释来补充,就不能算是名副其实。int d; // 消逝的时间,以日计
名称d什么也没有说明,因此,我们需要选择指明了计量对象和计量单位的名称: int elapsedTimeInDays; int daysSinceCreation;
1.2. 避免误导
程序员必须避免留下掩藏代码本意的错误线索,避免使用与本意相悖的词。同时,也要提防使用不同之处最小的名称,如:XYZControllerForEfficientHandlingOfStrings与XYZControllerForEfficientStorageOfStrings
1.3. 做有意义的区分
不能只是为了满足编译器的需要而写代码,如随手修改同一作用范围内两样重名的不同变量、函数。 以数字系列命名是依义命名的对立面,这样的名称纯属误导,没有提供作者意图的线索,如:
public static void copyChars(char a1[], char a2[]){for (int i = 0; i < a1.length; i++){a2[i] = a1[i];}}
而若将参数名改为source和destination这个函数会像样许多。
废话也是另一种没意义的区分,ProductInfo与ProductData名称不同但意义却无区别。还有例如Variable永远不应该出现在变量名中,Table也不该出现在表名中。
1.4. 使用可搜索的名称
单字母名称与数字常量有个问题,就是很难在一大篇文字中找出来。找MAX_CLASSES_PER_STUDENT显然比数字7容易得多。
长名称胜于短名称,较易被搜索到,名称的长短应与其作用域大小相对应。
1.5. 避免使用成员前缀
若需要用到成员前缀时,应当考虑是否将类或函数进行划分。
聪明程序员与专业程序员之间的区别在于,专业程序员了解,明确是王道,专业程序员善用其能,编写其他人能够理解的代码。
1.6. 避免思维映射
不应该让读者在脑中把你的名称翻译为他们熟知的名称,这种问题经常出现在选择是使用问题领域术语还是解决方案领域术语时。
1.7. 关于名称词性
类名和对象名应该是名词或名词短语,不该是动词;
方法名应当是动词或动词短语,属性访问器、修改器和断言应该根据其值命名,并加上get、set和is的前缀。
1.8. 每个概念对应一个词
给每个抽象概念选一个词,并且一以贯之。例如,使用fetch、retrieve和get来给多个类中的同样方法命名,要怎么才能记住哪个类中是哪个方法呢?因此,函数名称应当独一无二,而且要保持一致,这样才能不借助多余的浏览就找到正确的方法。
1.9. 添加有意义的语境
很少有名称能够自我说明的,反之,我们需要用有良好命名的类、函数或名称空间来放置名称,给读者提供语境。如果没那么做,给名称添加前缀就是最后一招了。设想有street, houseName, city, state的变量,当它们搁在一块儿,很明确是构成一个地址。不过,假使只在某个方法中看见孤零零一个state变量呢?此时可以添加前缀addr,如addrState等,以此提供语境。 再看如下例子,遍览函数,你会知道number, verb和pluralModifier这三个变量是“测估”信息的一部分,但这是读者推断出来的,第一眼看到这些变量时完全不清楚。
private void printGuessStatistics(char candidate, int count){String number;String verb;String pluralModifier;if (count == 0) {number = "no";verb = "are";pluralModifier = "s";} else if (count == 1) {number = "1";verb = "is";pluralModifier = "";} else {number = Integer.toString(count);verb = "are";pluralModifier = "s";}String guessMessage = String.format("There %s %s %s%s", verb, number, candidate, pluralModifier);System.out.print(guessMessage);}
上列函数有点长,而变量的使用贯穿始终。想要分解,则需要创建一个类GuessStatisticsMessage,将三个变量做成该类的成员字段。这样,它们就在定义上变作GuessStatisticsMessage的一部分。语境的增强也让算法能够通过分解为更小的函数而变得干净利落(如下方代码)。
public class GuessStatisticsMessage {private String number;private String verb;private String pluralModifier;public String make(char candidate, int count) {createPluralDependentMessageParts(count);return String.format("There %s %s %s%s",verb, number, candidate, pluralModifier);}private void createPluralDependentMessageParts(int count) {if (count == 0) {thereAreNoLetters();} else if (count == 1) {thereIsOneLetter();} else {thereAreManyLetters(count);}}private void thereAreManyLetters(int count) {number = Integer.toString(count);verb = "are";pluralModifier = "s";}private void thereIsOneLetter() {number = "1";verb = "is";pluralModifier = "";}private void thereAreNoLetters() {number = "no";verb = "are";pluralModifier = "s";}}
2. 函数
如何写好函数的关键在于: 1) 使用正确描述函数所作事情的长名称;
2) 函数短小(即条件、循环、try catch主语句短小),只做一件事(还需分清是做什么事还是回答什么问题),语句位于同一抽象层级;
3) 参数越少越好,输出作为返回值、参数写成成员避免传递、封装参数;
4) Switch埋在抽象工厂的较低抽象层级上(生产方法);
5) 避免重复;
2.1. 短小
函数的第一规则就是要短小,第二条规则是还要更短小。一般来说,函数20行封顶为佳。 if语句、else语句、while语句等,其中的代码应该只有一行,该行大抵应该是函数调用语句。这样不但能够保持函数短小,而且,因为块内调用的函数拥有较具说明性的名称,从而增加了文档的价值。
2.2. 只做一件事
函数应该做一件事,做好这件事,并只做这一件事。但问题在于很难知道那件该做的事是什么。
如果函数只是做了该函数名下同一抽象层上的步骤,则函数还是只做了一件事,编写函数毕竟是为了把大一些的概念拆分为另一个抽象层上的一系列步骤。另外,要判断函数是否只做了一件事,还有一个方法,就是看是否能够再拆分出一个函数。
2.3. 每个函数一个抽象层级
要确保函数只做一件事,函数中的语句都要在同一抽象层级上。例如,一个函数中包含getHtml()等位于较高抽象层的概念,也有String pagePathName = PathParser.render(pagePath)等位于中间抽象层的概念,还有.append(‘\n’)这样位于相当低的抽象层概念。
#### 向下规则: ####我们要让代码拥有自顶向下的阅读顺序,我们要让每个函数后面都跟着位于下一抽象层级的函数,这样一来,在查看函数列表时,就能按照抽象层级向下阅读了。换一种说法,程序就像一系列TO起头的段落,每一段都描述当前抽象层级,并引用位于下一抽象层级的后续TO起头段落;即:要…(当前抽象层级),我们就要先…,然后…(下一抽象层级)。
2.4. 关于Switch语句
如果无法避免使用switch语句,则确保它位于较低的抽象层级上,可以利用多态来实现这一点。
请看下列代码,它呈现了可能依赖于雇员类型的仅仅一种操作。
public Money calculatepay(Employee e) throws InvalidEmployeeType {switch (e.type) {case COMMISSIONED:return calculateCommissionedPay(e);case HOURLY:return calculateHourlyPay(e);case SALARIED:return calculateSalariedPay(e);default:throw new InvalidEmployeeType(e.type);}}
存在问题:函数太长;做了不止一件事;违反单一权责原则(Single Responsibility Principle, SRP),存在多于一个导致类变更的原因,这样一来当由于职责P1需求发生改变而需要修改类T时,有可能会导致原本运行正常的职责P2功能发生故障;违反了开放闭合原则,即对扩展是开放的,而对修改是封闭的。;最麻烦的是到处都有类似结构的函数,如isPayday(Employee e, Date date), deliverpay(Employee e, Money pay).。
解决方案:将switch语句埋到抽象工厂底下,不让任何人看到。该工厂利用switch语句为Employee派生创建适当的实体,而不同的函数借由Employee接口多态地接受派遣。
public abstract class Employee {public abstract boolean isPayday();public abstract Money calculatePay();public abstract void deliverPay(Money apy);}public class EmployeeFactory {public Employee makeEmployee(EmployeeRecord r)throws InvalidEmployeeType {switch (r.type) {case COMMISSIONED:return new CommissionedEmployee(r);case HOURLY:return new HourlyEmployee(r);case SALARIED:return new SalariedEmployee(r);default:throw new InvalidEmployeeType(r.type)}}}
2.5. 使用描述性的名称
选择较好地描述了函数做的事的名称,如用setupTeardownIncluder.render而不是testableHtml。记住沃德原则:“如果每个例程都让你感到深合己意,那就是整洁代码。”因此,函数越短,功能越集中,就越便于取个好名字。
长而具有描述性的名称,要比短而令人费解的名称好得多。另外,命名方式要保持一致,例如includeSetupAndTeardownPages, includeSetupPages, includeSuiteSetupPage等。
2.6. 函数参数
最理想的参数数量是零,其次是一,再次是二,应该尽量避免三。参数的增多,也会大大增加测试的困难程度。
输出参数比输入参数还要难以理解,读函数时,我们惯于认为新兴通过参数输入函数,然后通过返回值从函数输出,不太希望通过参数输出。
1) 一元函数的普遍形式:例如,对于转换,使用输出参数而非返回值令人困惑。实际上,StringBuffer transform(StringBuffer in)就要比void transform(StringBuffer out)强得多;
2) 标识参数:向函数传入布尔值简直就是骇人听闻的做法,这使得函数不是只做一件事;
3) 二元函数:有两个参数的函数要比一元函数难懂。例如,writeField(name)比writeField(outputStream, name)好懂;
当然,有些时候两个参数正好,但即便是如assertEquals(expected, actual)这样的二元函数也有其问题,两个参数的位置,你有多少次搞错呢?可以在名称上稍作提示,例如assertExpectedEqualsActual(expected, actual)。 我们能够尽量将二元函数转换成一元,例如,可以把writeField方法携程outputStream成员之一,从而这样:outputStream.writeField(name);或者将outputStream写成当前类的成员变量,则无需传递;
4) 参数对象:如果函数看来需要两个、三个或三个以上的参数,就说明一些参数应该封装成类了;
2.7. 分隔指令与询问
函数要么做什么事,要么回答什么事,但二者不可得兼。函数应该修改某对象的状态,或者返回该对象的有关信息,两件都做会导致混乱。
public Boolean set(String attribute, String value);
该函数设定某个属性,如果成功返回true,如果不存在属性则返回false,这样将导致以下语句: if (set(“username”, “unclebob”))… 这到底是在问username属性值是否之前已经设置为unclebob吗?还是在问username属性是否城管设置为unclebob呢? 作者本意,set是个动词,但在if语句的上下文中,感觉像个形容词。解决方法并非将方法改名为setAndCheckIfExists,而是将指令与询问分开:
if (attributeExists("username")) {setAttribute("username", "unclebob");…}
2.8. 使用异常替代返回错误码
不要通过函数返回值判断执行是否成功,而是要在不成功时抛出异常。这样可以将错误处理代码从主路径中分离出来。 而异常的try catch块中的主要部分,最好抽离出来,另外形成函数,如:
public void delete (Page page) {try {deletePageAndAllReferences(page);}catch (Exception e) {logError(e);}}private void deletePageAndAllReferences(Page page) throws Exception {deletePage(page);registry.deleteReference(page.name);configKeys.deleteKey(page.name.makeKey());}private void logError(Exception e) {logger.log(e.getMessage());}
这里,delete函数只与错误处理有关,deletePageAndAllReferences函数只与完全删除一个page有关。
2.9. 避免重复
对于总是出现的代码、算法,有些可能不太容易识别,也不完全相同,但还是需要修改。解决方法是将相同的部分封装成函数,而不同的部分也要写在一个函数中,该函数可以调用刚刚封装的函数。
2.10. 如何写出这样的函数
作者的话:“我写函数时,一开始都冗长而复杂。有太多缩进和嵌套循环。有过长的参数列表。名称是随意取的,也会有重复代码。不过我会配上一套单元测试,覆盖每行丑陋的代码。
然后我打磨这些代码,分解函数、修改名称、消除重复。缩短和重置方法,有时还拆散类,同时保持测试通过。
最后,遵循本章列出的规则,我组装好这些函数。”
3. 注释
不准确的注释要比没注释坏的多,它们满口胡言,它们预期的东西永远不能实现,它们设定了无需也不应再遵循的旧规则。
真实只在一处地方有:代码。只有代码能够忠实地告诉你它做的事,那是唯一真正准确的信息来源。所以,尽管有时需要注释,我们也该多花心思尽量减少注释量。
3.1. 用代码来阐述,而非注释
你,愿意看到这个:
// check to see if the employee is eligible for full benefitif ((employee.flags & HOURLY_FLAG) && (employee.age > 65))
还是这个?
if (employee.isEligibleForFullBenefits())
3.2. 好注释
有些注释是必须的,也是有利的。来看看一些我认为值得写的注释,不过要记住,唯一真正好的注释是你想办法不去写的注释。
3.2.1. 法律信息
有时公司代码规范要求编写与法律有关的注释,位于每个源文件的开头,不过,IDE会把它们卷起这样不会显得凌乱。
3.2.2. 提供信息的注释
例如,以下注释解释了某个抽象方法的返回值:
// Returns an instance of the Responder being testedprotected abstract Responder responderInstance();
当然,更好的方式是利用函数名称传达信息,比如,本例中将函数重命名为responderBeingTested,注释就多余了。
3.2.3. 解释信息
注释可以提供某个决定后面的意图,也可以将某些晦涩难明的参数或返回值的意义翻译为某种可读的形式。
例如:
assertTrue (a.compareTo(a) == 0); // a == a
3.2.4. 警示
3.2.5. TODO注释
有理由用// TODO形式在源代码中放置要做的工作列表。TODO是程序员认为应该做的,但由于某些原因还没有做的工作。
3.2.6. 放大
注释可以放大某种看起来不合理之物的重要性。
3.3. 坏注释
大多数注释都属于此类。通常,坏注释都是糟糕代码的支撑或借口,或者对错误决策的修正,基本上等于程序员自说自话。
3.3.1. 多余的注释
如下所示的简单函数,其头部位置的注释全属多余。读这段注释花的时间没准比读代码花的时间长。
// Utility method that returns when this closed is true.// Throws an exception if the timeout is reached.public synchronized void waitForClose(final logn timeoutMillis)throws Exception{if (!closed){wait(timeoutMillis);if (!closed) {throw new Exception("MockResponseSender could not be closed");}}}
3.3.2. 误导性注释
又如上例,在closed变为true时,方法并没有返回。方法只在判断到closed为true时返回,否则就是等待超时,然后如果判断closed还是非true,则抛出异常。这一细微的误导信息,放在比代码本身更难阅读的注释里面,有可能导致其他程序员调用这个函数并期望在closed变为true时立即返回,而这不可能实现。
3.3.3. 循规式注释
如果要求每个函数都有Javadoc则会得到类似如下面目可憎的代码:
/*** @param title The title of the CD* @param author The author of the CD* @param tracks ...* @param durationInMinutes ...*/public void addCD(String title, String author,int tracks, int durationInMinutes) {…}
此外,还有日志式注释,废话注释,位置标记,归属与署名以及注释掉的代码等,都是坏注释的代表。
4. 格式
4.1. 垂直格式
源文件也要像报纸排版,名称应该一目了然,其本身应该能够告诉我们是否存在于正确的模块中。源文件最顶部应该给出高层次的概念和算法,细节应该往下逐次展开,直到找到源文件中最底端的细节。
4.1.1. 垂直方向上的间隔
在封包声明,导入声明和每个函数之间都需要有空白行隔开,往下读代码时,目光总是会停留在空白行之后的那一行。如下列代码,后者比前者的格式清楚得多:
public class BoldWidget extends ParentWidget {public static final String REGXP = "'''.+?'''";private static final Pattern pattern = pattern.compile(REGXP);public BoldWidget(ParentWidget parent, String text) throws Exception {super(parent);Matcher match = pattern.matcher(text);match.find();addChildWidgets(match.group(1));}public String render() throws Exception {StringBuffer html = new StringBuffer("<b>");html.append(childHtml()).append("</b>");return html.toString();}}public class BoldWidget extends ParentWidget {public static final String REGXP = "'''.+?'''";private static final Pattern pattern = pattern.compile(REGXP);public BoldWidget(ParentWidget parent, String text) throws Exception {super(parent);Matcher match = pattern.matcher(text);match.find();addChildWidgets(match.group(1));}public String render() throws Exception {StringBuffer html = new StringBuffer("<b>");html.append(childHtml()).append("</b>");return html.toString();}}
4.1.2. 垂直方向上的靠近
如果说空白行隔开了概念,靠近的代码则暗示了它们之间的紧密关系,所以联系紧密的代码应该相互靠近。如下列代码所示,后者比前者的关系清晰很多:
public class ReporterConfig {/*classname of the student*/private String m_className;/*properties of the student*/private List<Property> m_properties = new ArrayList<Property>();/*add a property*/public void addProperty(Property property) {m_properties.add(property);}}public class ReporterConfig {private String m_className;private List<Property> m_properties = new ArrayList<Property>();public void addProperty(Property property) {m_properties.add(property);}}
4.1.3. 建议
1) 变量声明应该尽可能靠近其使用位置,因为函数很短,本地变量应该在函数的顶部出现。另外,循环中的变量声明应该总是在循环中出现。
2) 实体变量应该在类的顶部声明,在设计良好的类中,它们如果不是被该类所有方法也是被大多数方法所用。
3) 相关函数,若某个函数调用了另外一个,就应该将它们放在一起,而且调用者应该在被调用者之上。
4.2. 横向格式
对于横向格式,则应该遵循无需拖动滚动条到右边的原则。
赋值操作周围加上空格字符,以此达到强调目的,如下:
int lineSize += line.length();totalChars = totalChars + lineSize;
另外,函数名和左括号之间不加空格,因为函数与参数联系密切,而参数则一一隔开,强调逗号,表示参数是分离的。
public class Quadratic {public static double root1(double a, double b, double c) {double determinant = determinant(a, b, c);return (-b + Math.sqrt(determinant)) / (2*a);}public static double root2(int a, int b, int c) {double determinant = determinant(a, b, c);return (-b - Math.sqrt(determinant) / (2*a));}private static double determinant(double a, double b, double c) {return b*b - 4*a*c;}}
其中,乘法因子间无空格因为优先级较高,而加减较低则用空格隔开。
5. 对象和数据结构
5.1. 隐藏实现细节
下列两段代码都表示笛卡尔平面上的点:
public class Point {public double x;public double y;}public interface Point {double getX();double getY();double getR();double getTheta();void setPolar(double r, double theta);}
第二段代码的漂亮之处在于,你不知道实现会在极坐标系中还是二维坐标系中,这很好地隐藏了实现细节。
然而,隐藏实现并非只是在变量之上加上一层函数那么简单,隐藏实现关乎抽象!类并不简单地用取值器和赋值器将其变量推向外界,而是暴露抽象接口,以便用户无需了解数据结构就能操作数据本体。
例如下面两段代码,前者使用具象手段与机动车的燃料层通信,而后者则采用百分比抽象:
public interface Vehicle {double getFuelTankCapacityInGallons();double getGallonsOfGasonline();}public interface Vehicle {double getPercentFuelRemaining();}
明显,后者为佳,我们不愿暴露数据细节,更愿意以抽象形态表述数据,并且要以最好的方式呈现某个对象包含的数据。
5.2. 过程式代码与面向对象代码
过程式代码的数据结构暴露其数据,没有提供有意义的函数;而面向对象的代码将数据隐藏于抽象之后,暴露操作数据的函数。
过程式代码便于在不改动既有数据结构的前提下添加新函数,面向对象代码便于在不改动既有函数的前提下添加新类;也就是说,过程式代码难以添加新数据结构,因为必须修改所有函数,面向对象的代码难以添加新函数,因为必须修改所有类。
5.3. The Low of Demeter
模块不应了解它所操作对象的内部情形,这意味着对象不应通过存取器暴露其内部结构。 方法不应调用由任何函数返回的对象的方法,如取得临时目录的绝对地址:
final String outputDir = ctxt.getOptions().getScratchDir().getAbsolutePath();
这类连串的调用通常被认为是肮脏的风格,应该避免,最好做类似如下切分:
Options opts = ctxt.getOptions();File scratchDir = opts.getScratchDir();final String outputDir = scratchDir.getAbsolutePath();
不过这些代码是否违反The Low of Demeter,取决于ctxt, Options 和ScrathchDir是对象还是数据结构。若是对象,则它们的内部结构应当隐藏而不是暴露,而有关其细节的只是就明显违反。但如果是数据结构,没有任何行为,则它们自然会暴露其内部结构,该定律就不再适用。 现在,我们假设上文提到的是三个对象,我们可能会采用:
ctxt.getAbsolutePathOfScratchDirectoryOption();
或者
ctx.getScratchDirectoryOption().getAbsolutePath();
第一种方案可能导致ctxt对象中方法的暴露,而第二种假设getScratchDirectoryOption()返回一个数据结构而不是对象,这两种都无法令人满意。
我们可以从取得临时目录绝对路径的目的入手,如是为了创建指定名称的临时文件,则可以直接让ctxt来完成:
BufferedOutputStream bos = ctxt.createScratchFileStream(classFileName);
这下就隐藏了内部的结构和实现细节,并且也更符合对象的行为了!

若有收获,就点个赞吧
0 人点赞
