- 第一讲
- header、版本和重要资源">1.header、版本和重要资源
- 2.STL体系结构介绍
- 3. 容器的结构与分类
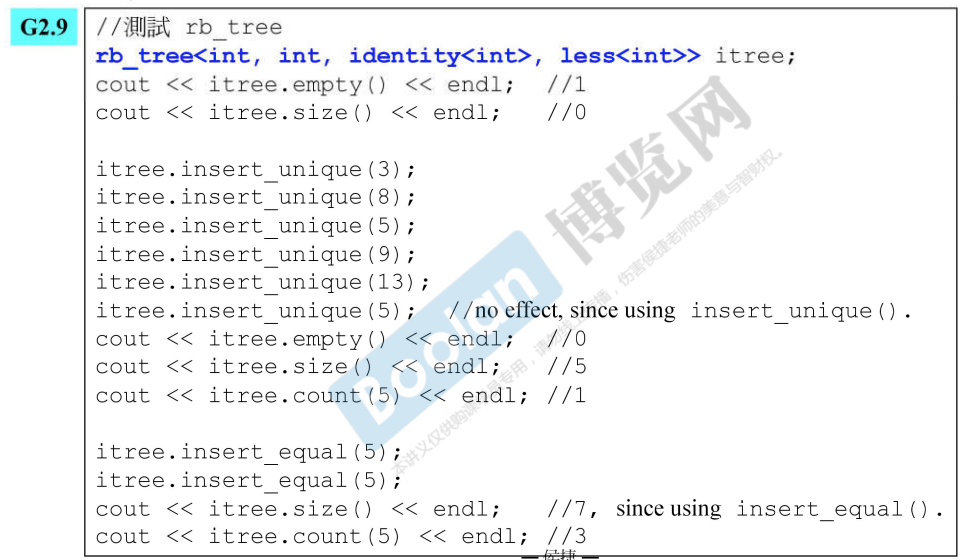
- 4.各种STL容器的测试
- 5.分配器allocator的测试
- 第二讲
- 第三讲
- 第四讲
- include
- include
//snprintf() - include
//RAND_MAX - include
//strlen(), memcpy() - include
C++ Standard Template Library and Generic Programming
(体系结构与内核分析)C++ Standard Library —— architecure & sources
- C标准库是功能相互独立的函数库;
- C++标准库分为6个主要部件(容器、算法、迭代器、分配器、适配器、仿函数),彼此关系紧密。
第一讲
1.header、版本和重要资源
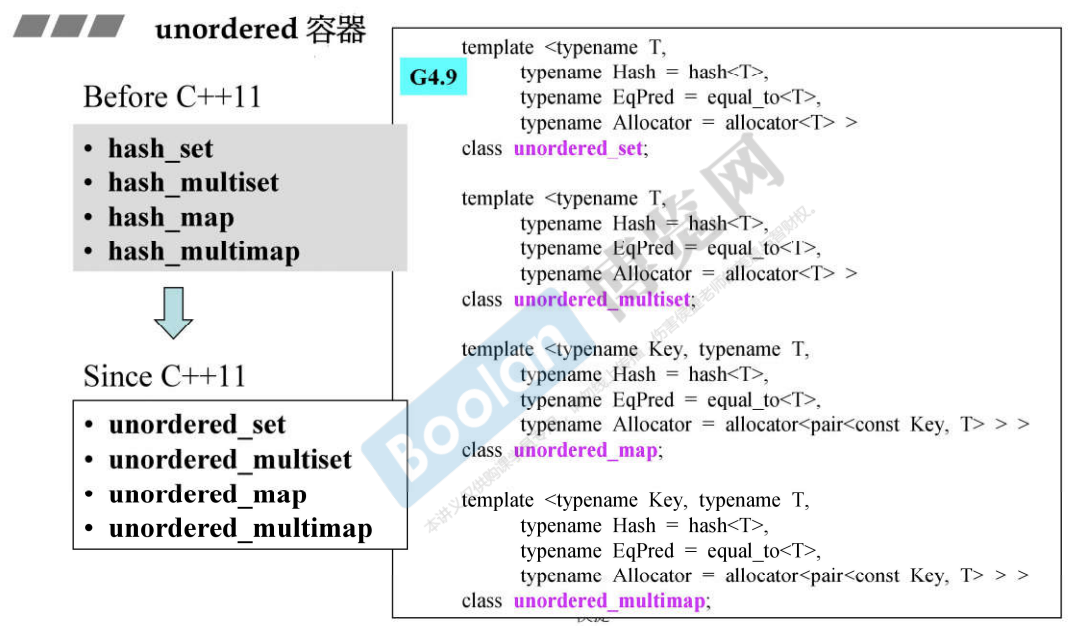
C++标准库(C++ Standard Library) vs. C++标准模板库(C++ Standard Template Library)
注:C++标准模板库主要为6大部件,C++标准库除6大部件外还包括其它内容。
C++标准库以头文件(header files)的形式呈现。
- C++标准库的头文件不带后缀名.h,例如#include
- 新式C的头文件不带后缀名.h,例如#include
- 旧式C的头文件带后缀名.h仍然可以使用,例如#include
- 新式头文件内的组件封装在命名空间std中:
- using namespace std;
- using std::cout;或std::vector
vec;
- 旧式头文件内的组件不封装在命名空间std中。
[
](https://blog.csdn.net/newson92/article/details/122164204)
2.STL体系结构介绍
2.1 STL六大部件(Components)
- 容器(Containers)
- 算法(Algorithms)
- 分配器(Allocators)
- 迭代器(Iterators)
- 适配器(Adapters)
- 仿函数(Functors)
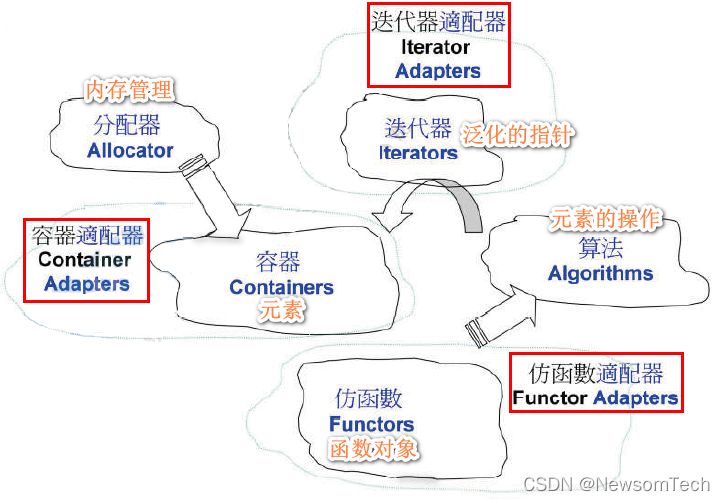
容器与分配器:分配器管理容器元素的内存。
容器与算法、迭代器:算法是操作或处理容器元素的模板函数;迭代器是容器和算法之间的桥梁,是泛化的指针。
2.2 STL容器的前闭后开区间
[ ):迭代器位置包左不包右
begin():迭代器指向容器第1个元素的位置
end():迭代器指向容器最后1个元素的下一个位置
迭代器相当于泛化的指针,可使用指针的操作:++、—、*、->。
2.3 基于范围的for循环 ranged-base for
for( decl : coll ) {statement}for( 声明 : 容器 ) {语句}
//示例1for(int i : {1, 3, 5, 7, 9}) {std::cout << i << std::endl;}//示例2std::vector<int> vec;.../* 传值:pass by value */// 拷贝容器中的元素并赋值给局部变量elem——不影响容器中的原有元素for(auto elem : vec) {std::cout << elem << std::endl;}/* 传引用:pass by reference */// 对容器中的元素进行操作——影响容器中的原有元素for(auto& elem : vec) {elem *= 3;}
2.4 auto
使用auto关键字声明变量或对象时,编译器自动对其类型进行推导
使用auto关键字声明变量或对象的同时,必须进行定义(显式赋值操作)。
/* 正常写法 */list<string> c;...list<string>::iterator ite;ite = find(c.begin(), c.end(), targetStr);/* 使用auto关键字 */list<string> c;...auto ite = find(c.begin(), c.end(), targetStr);
3. 容器的结构与分类
3.1 序列式容器(Sequence Containers)
按照元素的存储顺序依次排列。
- 数组(Array):容量大小固定
- 向量(Vector):单端进出,容量大小可动态扩展
- 双端队列(Deque):双端可进可出
- 双向链表(List):双向循环链表
- 单向链表(Forward-List):内存占用少于双向链表【C++11新增】
栈stack和队列queue底层依赖于deque容器,本质上属于容器适配器。
3.2 关联式容器(Associative Containers)
包括键和值,适合快速查找。
- 集合(Set/Multiset):由红黑树(高度平衡二叉树)实现
- 映射表(Map/Multimap):由红黑树(高度平衡二叉树)实现
3.3 不定序容器(Unordered Containers)
底层使用哈希表实现。
- 无序集合(Unordered Set/Multiset):由哈希表实现
- 无序映射表(Unordered Map/Multimap):由哈希表实现
注1:哈希表包括若干个bucket,每个bucket对应一个链表。哈希冲突时,应避免每个bucket对应的链表长度过长而导致元素搜索时间较长。
注2:g++编译器提供非标准的hash_set/hash_multiset/hash_map/hash_multimap,与标准库提供的unordered_set/unordered_multiset/unordered_map/unordered_multimap基本一致,使用时需包含头文件#include 
4.各种STL容器的测试
4.1 vector容器的测试
- vector容器的容量支持动态扩容,且扩展后的容量是当前容量的2倍,并将扩容前旧容器的原有元素拷贝至扩容后的新容器中。
- STL算法中的::find()函数是全局函数,且是顺序查找。
- vector容器扩容时容量成倍增长,可能会造成内存的浪费。
- sort()全局函数,循序查找
4.2 list和forward_list容器的测试
- 当STL和容器类均提供用于排序的sort()函数时,优先使用容器类的sort()函数,效率更高。list就有成员函数l.sort()
- 单向链表forward_list不存在成员函数back()和size()。
- g++编译器提供非标准的单向链表slist,与标准库提供的forward_list基本一致,使用时需包含头文件#include
- list容器扩容时每次新增1个节点,内存利用率较高,但查找效率较低。
非标准的单向传递容器 slist,包含在#include
中的abort()用于抛出异常后退出。
4.3 deque容器的测试
deque容器包括中央控制器和若干分段连续的缓冲区(buffer)。
当deque容器向前或向后填充元素时,先查看对应缓冲区是否还有剩余空间,当不存在剩余空间时,会申请额外的缓冲区且中央控制器的指针指向新的缓冲区。deque容器扩容时,每次扩充1个缓冲区大小。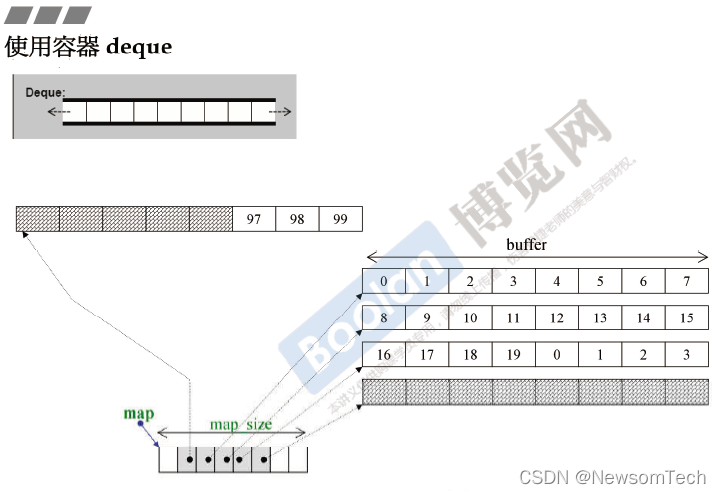
4.4 stack和queue的测试
栈stack和队列queue底层依赖于deque容器,本质上属于容器适配器。
stack有 成员函数 top() push_back() pop_back()
queue有成员函数 front() back() push() pop()
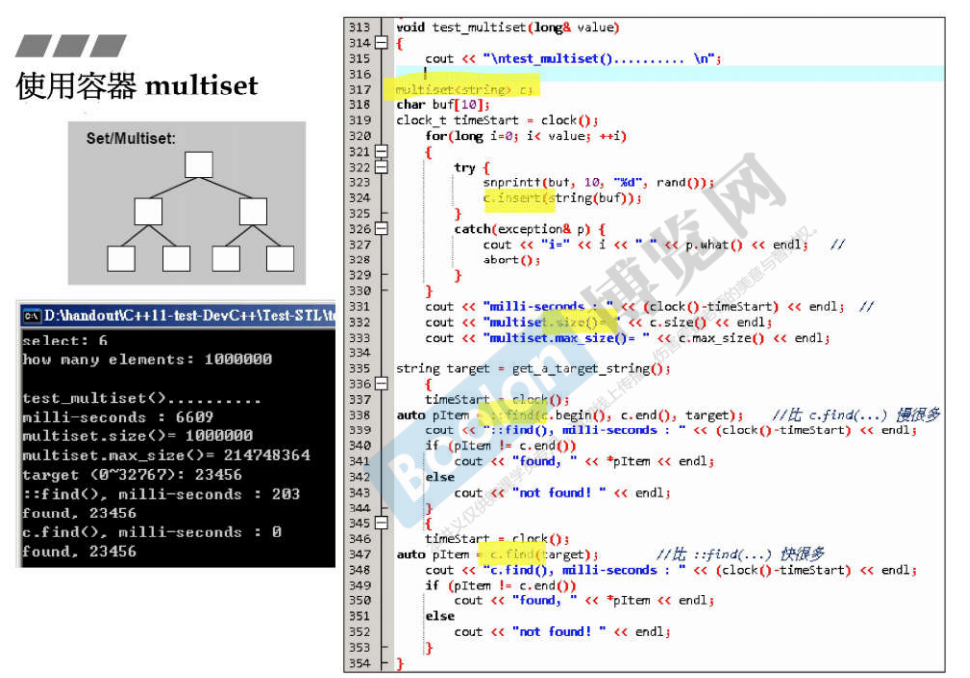
4.5 multiset和multimap的测试
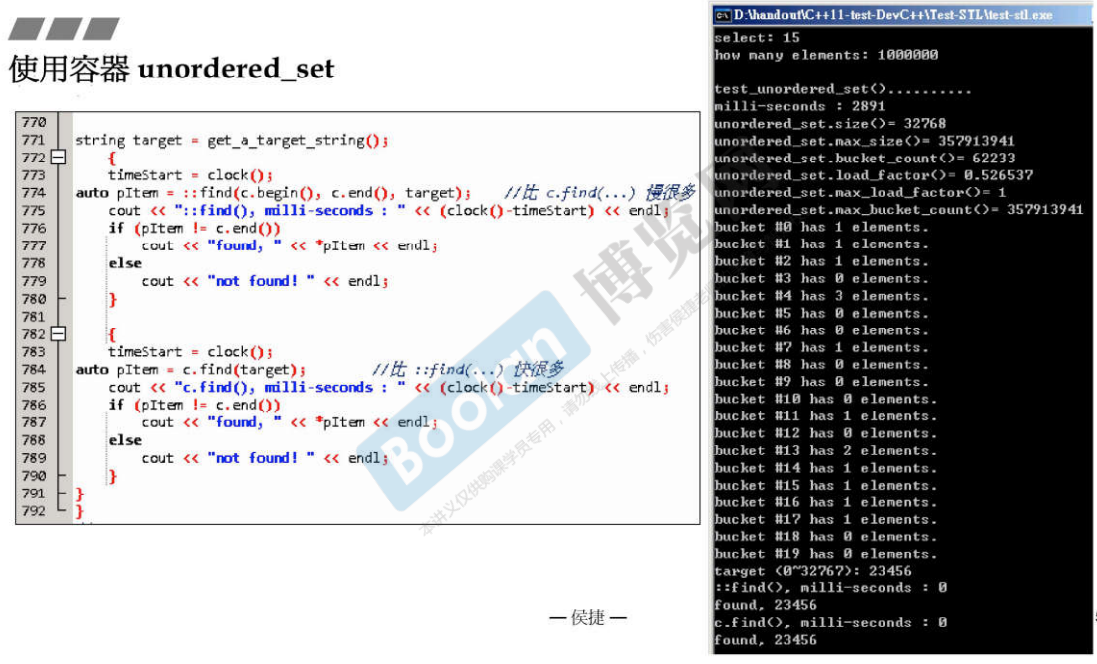
- 当STL和容器类均提供用于查找的find()函数时,优先使用容器类的find()函数,效率更高。
- multimap插入元素时,不可使用[],例如mmp[0] = 1; mmp[0] = 2;,编译器不知道是插入2个键相同的键值对或修改键对应的值。
4.6 unordered_multiset和unordered_multimap的测试
哈希表包括若干个bucket,每个bucket对应一个链表。
哈希冲突时,应避免每个bucket对应的链表长度过长而导致元素搜索时间较长。
经验法则:当元素个数大于等于bucket个数时,bucket个数会扩充至约原先的2倍。故bucket数量一定多于元素数量。
成员函数有 bucket_count()、load_factor()、 max_load_factor()、 max_bucket_count() 、find()
5.分配器allocator的测试
容器包含默认的分配器(模板参数使用默认值)。
示例:
template<typename _Tp, typename _Alloc = std::allocator<_Tp>> // 使用默认参数class vector : protected _Vector_base<_Tp, _Alloc>template<typename _Tp, typename _Alloc = std::allocator<_Tp>> // 使用默认参数class list : protected _List_base<_Tp, _Alloc>template<typename _Tp, typename _Alloc = std::allocator<_Tp>> // 使用默认参数class deque : protected _Deque_base<_Tp, _Alloc>template<typename _Key, typename _Compare = std::less<_Key>,typename _Alloc = std::allocator<_Key>>class set ...template<typename _Key, typename _Tp, typename _Compare = std::less<_Key>,typename _Alloc = std::allocator<std::pair<_Key, _Tp>>class map ...template<class _Value, class _Hash = hash<_Value>,class _Pred = std::equal_to<_Value>, class _Alloc = std::allocator<_Value>>class unordered_set ...template<class _Key, class _Tp, class _Hash = hash<_Key>,class _Pred = std::equal_to<_Key>,class _Alloc = std::allocator<std::pair<_Key, _Tp>>class unordered_map ...
示例:直接使用分配器管理内存(不建议, 释放内存时需释放对应大小的内存。)
/* 测试不同类型分配器的allocate()和deallocate()函数 */#include <ext\...> // 包含各类分配器的头文件int *p;/* 默认分配器:allocator<T> */allocator<int> a1;p = a1.allocate(1); // 分配1个int大小的空间a1.deallocate(p, 1); // 需要同时释放指针和对应的内存大小/* malloc分配器:malloc_allocator<T> */__gnu_cxx::malloc_allocator<int> a2;p = a2.allocate(2); // 分配2个int大小的空间a2.deallocate(p, 2); // 需要同时释放指针和对应的内存大小/* new分配器:new_allocator<T> */__gnu_cxx::new_allocator<int> a3;p = a3.allocate(3); // 分配3个int大小的空间a3.deallocate(p, 3); // 需要同时释放指针和对应的内存大小/* 池分配器:__pool_alloc<T> */__gnu_cxx::__pool_alloc<int> a4;p = a4.allocate(4); // 分配4个int大小的空间a4.deallocate(p, 4); // 需要同时释放指针和对应的内存大小/* 多线程分配器:__mt_alloc<T> */__gnu_cxx::__mt_alloc<int> a5;p = a5.allocate(5); // 分配5个int大小的空间a5.deallocate(p, 5); // 需要同时释放指针和对应的内存大小/* bitmap分配器:bitmap_allocator<T> */__gnu_cxx::bitmap_allocator<int> a6;p = a6.allocate(6); // 分配6个int大小的空间a6.deallocate(p, 6); // 需要同时释放指针和对应的内存大小
第二讲
6. STL源代码的分布(VC++ 6.0、g++ 4.9.2)
Visual C++编译器的STL源码路径:
…\include (如C:\Program Files (x86)\Microsoft Visual Studio 10.0\VC\include)
g++编译器的STL源码路径:
- STL:…\include\c++\bits
- 扩展:…\include\c++\ext
7. OOP(Object-Oriented programming)与GP(Generic Programming)
- OOP: Object-oriented programming 面向对象的编程 ,例如C++中的类和对象。
- GP:Generic Programming 泛型编程 ,例如C++中的模板。
7.1 OOP(面向对象编程)
企图将datas和methods关联在一起,比如标准库中的list:
list定义了一个自己的成员函数,那么为什么list不能使用::sort()进行排序呢,我们先来看一下::sort()的源码: ```cpp templatetemplate <class T,class Alloc = alloc>class list{......void sort();};
inline void sort(RandomAccessIterator first, RandomAccessIterator last){ if(first != last){
} }__introsort_loop(first, last, value_type(first), __lg(last - first) * 2);__final_insertion_sort(first, last);
template
**发现::sort()支持的迭代器是随机访问迭代器,**随机访问迭代器除了可以递增递减之外,还支持类似c.begin() + k的操作,**而list中的迭代器不是随机访问迭代器,所以也就不提供这个操作**。这样设计是合理的,因为list是链表,无法在线性时间内得到递增或递减k次的结果。
<a name="hYvQv"></a>
#### 7.2 GP(泛型编程)是将datas和methods分开来
**采用GP的好处:**<br />(1) **容器**(Containers)和**算法**(Algorithms)可各自独立实现,提供统一的对外接口即可,两者以**迭代器**(Iterator)作为桥梁。<br />(2) **算法**(Algorithms)通过**迭代器**(Iterator)确定操作范围,并通过**迭代器**(Iterator)获取和使用**容器**(Containers)元素。
**所有的算法,其内最终涉及元素本身的操作,无非就是比大小。**
```cpp
/* max函数的重载 */
template <class T>
inline const T& max(const T& a, const T& b) {
return a < b ? b : a;
}
// Compare 自定义的比较规则
template <class T, class Compare>
inline const T& max(const T& a, const T& b, Compare comp) {
return comp(a, b) ? b : a;
}
8. 操作符重载、模板(泛化、全特化、偏特化)
8.1 操作符重载
操作符重载规则
操作符重载在一定条件下,可作为成员函数或全局函数。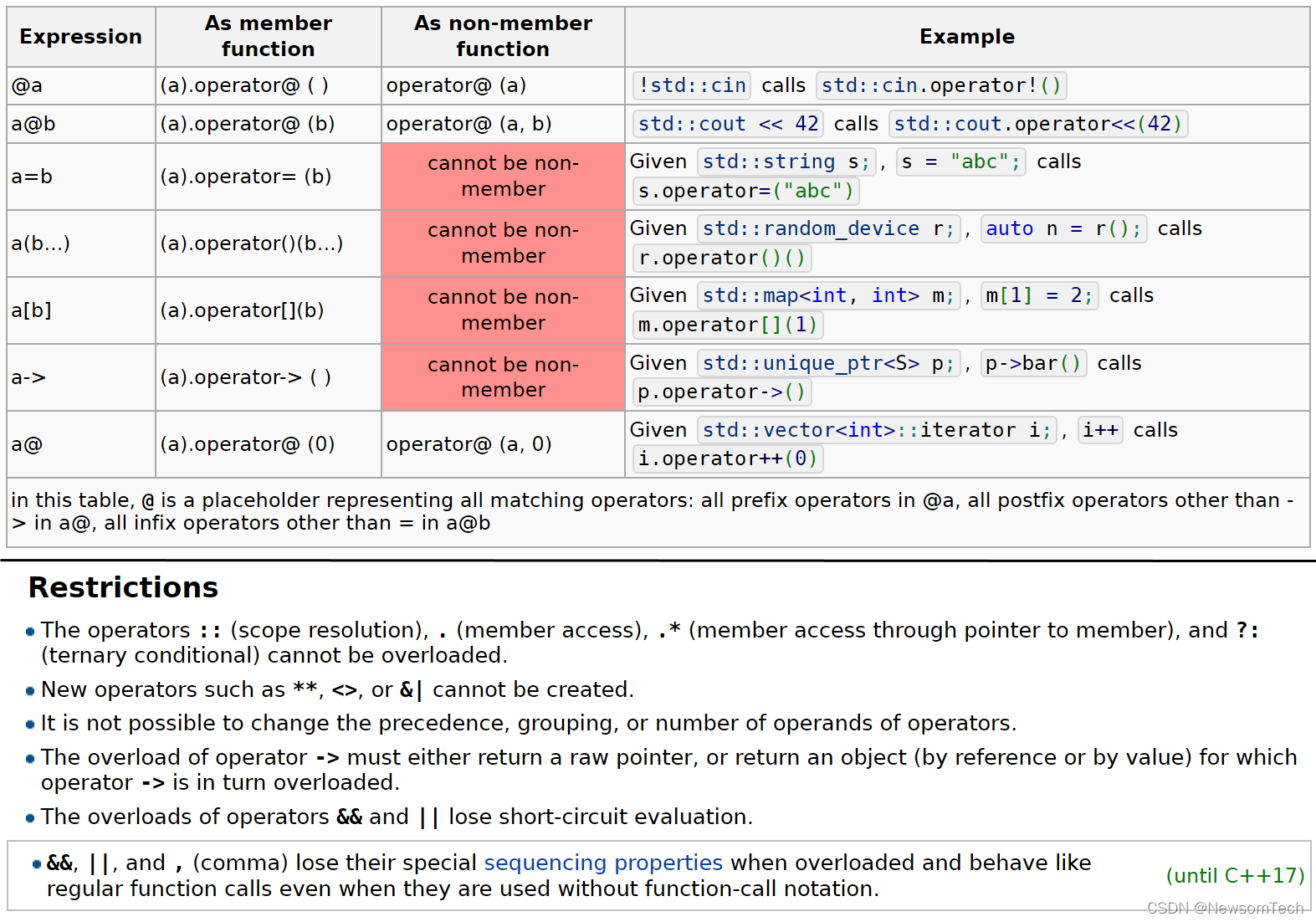
示例:链表迭代器的操作符重载
8.2 模板(泛化、全特化、偏特化)
class template
类模板使用时,需显式指定具体的泛型类型。编译器不会对它进行类型推导。
function template
- 关键字class可替换为typename。
- 函数模板使用时,不必显式指定具体的泛型类型。编译器会对函数模板进行实参推导/类型推导(argument deduction)。类模板使用时,需显式指定具体的泛型类型。
member template
成员模板:类模板中的成员(函数/属性)也为模板。
template <class T1, class T2>
struct pair {
typedef T1 first_type;
typedef T2 second_type;
// 成员变量
T1 first;
T2 second;
// 构造函数
pair() : first(T1()) , second(T2()) {} // 匿名对象T1()、T2()
pair(const T1& a, const T2& b) : first(a), second(b) {} // 有参构造
/* 成员模板 */
template <class U1, class U2>
pair(const pair<U1, U2>& p) : first(p.first), second(p.second) {} // 拷贝构造
};
应用场景:STL中的拷贝构造函数和有参构造函数常设计为成员模板。
成员模板的泛型类型是类模板的泛型类型的子类。
注:成员模板的泛型类型U1/U2,继承自类模板的泛型类型T1/T2。反之不成立。
class Base1 {};
class Derived1 : public Base1 {};
class Base2 {};
class Derived2 : public Base2 {};
pair</* U1 */Devired1, /* U2 */Devired2> p;
pair<Base1, Base2> p2(p);
/* 等价写法 */
// 使用成员模板创建匿名对象,用于类的拷贝构造函数
pair</*T1*/Base1, /*T2*/Base2> p2(pair</*U1*/Devired1, /*U2*/Devired2>());
示例:智能指针类成员模板的应用
智能指针子类shared_ptr有参构造函数的参数(被包装的指针),是智能指针父类__shared_ptr有参函数构造函数的参数(被包装的指针)的子类。
template<typename _Tp>
class shared_ptr : public __shared_ptr<_Tp>
{
...
/* 成员模板 */
template<typename _Tp1>
// 构造函数
// 子类构造函数shared_ptr的参数__p,对父类构造函数__shared_ptr<_Tp>赋值
explicit shared_ptr(/*Devired*/_Tp1* __p) : __shared_ptr</*Base*/_Tp>(__p) {}
...
};
/* 指针类的多态 */
Base1 *ptr = new Devired1; // 向上转型up-cast
/* 智能指针类的多态 */
// 使用子类对象
shared_ptr<Base1*> sptr(new Devired1); // 模拟向上转型up-cast
8.3 特化 specialization
- 泛化(generalization):使用时再指定模板参数的具体类型。
- 特化(specialization):将模板泛化的部分进行局部的特征化。显式指定部分或全部模板参数的具体类型。
- 全特化(full specialization):显式指定全部模板参数的具体类型。
- 偏特化/局部特化(partial specialization):指定部分模板参数的具体类型。
注1:特化的优先级高于泛化。当存在合适的特化版本时,编译器优先调用相应的特化版本。 注2:全特化的所有模板参数均被指定,故模板参数列表为空,即template <>。

偏特化/局部特化:
- 个数的偏特化
- 对若干数量的模板参数进行特化(显式指定类型)
- 偏特化的模板参数,必须从左到右连续指定(如偏特化第1/2/3个),而不能穿插指定(如偏特化第1/3/5个),类似于默认参数必须从参数列表的最右侧往左连续。
- 偏特化仅指定部分模板参数,剩余未被指定的模板参数需存在于模板参数列表,否则报错。
/* 泛化的类模板 */
template<typename T, typename Alloc = .../*默认参数*/> // 模板参数
class vector
{
...
};
/* 偏特化的类模板-个数的偏特化 */
// 通过偏特化/局部特化,模板参数的2个泛型类型变为1个
// 偏特化仅指定部分模板参数,剩余未被指定的模板参数需存在于模板参数列表
template<typename Alloc = .../*默认参数*/>
class vector<bool, Alloc> // 偏特化/局部特化:使用指定的bool类型,绑定泛型类型T
{
...
};
- 范围的偏特化
将模板参数类型的表示范围缩小:
- 将泛型类型T缩小为对应的指针类型T*;
- 将泛型类型T缩小为const限定符修饰T const。
/* 泛化的类模板 */
template<typename T> // 模板参数
class C
{
...
};
/* 偏特化的类模板-范围的偏特化:指针类型偏特化 */
template<typename T> // 模板参数
class C<T*>
{
...
};
// 等价写法
template<typename U> // 模板参数
class C<U*>
{
...
};
/* 偏特化的类模板-范围的偏特化:const偏特化 */
template<typename T> // 模板参数
class C<T const>
{
...
};

9. 分配器
9.1 实质
分配器操作内存的实质还是调用C Runtime Library的malloc和free(可以说c++的new以及任何其他上层操作内存的方式最终一层层调用都是回归到malloc和free这两个函数上),这两个函数再根据不同平台再去调用各自的System API。
每次申请的内存后系统分配给我们的远远大于我们实际申请的空间,因为系统要给这块内存附加一定的标识(也可叫做cooking或者额外开销),以方便释放操作,因为附加的部分是固定的,也就说我们申请的内存越大,附加部分占用的比重就越小。
9.2 源码实现
- VC6标椎库allocator实现原理
使用示例,如下容器使用的分配器是标准库中的allocator

- 分配内存的时候调用的是allocator的allocate函数,调用流程就变成了:allocate -> Allocate -> operator new -> malloc;
- 回收内存的时候调用的是allocator的deallocate函数,调用流程:deallocate -> operator delete -> free;
- 直接使用分配器就是如图中所示的“分配512 ints”,allocator
()生成一个匿名对象,使用该对象进行函数的调用; - VC的分配器没有做任何独特的设计,只是调用了 C 的malloc和free来分配和释放内存,且接口设计并不方便程序员直接使用,但是容器使用就没问题。
- BC5 STL对allocator的使用
使用示例,BC5 STL中的一下容器使用的分配器是标准库的allocator:

和VC一样,allocator最终也是通过 C 的 malloc 和 free来分配和释放内存的。
- G2.9 STL对 allocator的使用

说明:G2.9 标准库中的allocator 和 VC、BC一样,最终都是调用malloc和free进行内存的分配和释放。但是G2.9的STL中并没有使用标准库中的分配器,这个文件并没有被包含在任何STL头文件中,G2.9的STL容器使用的是alloc分配器。
G2.9 STL容器使用的分配器是alloc:
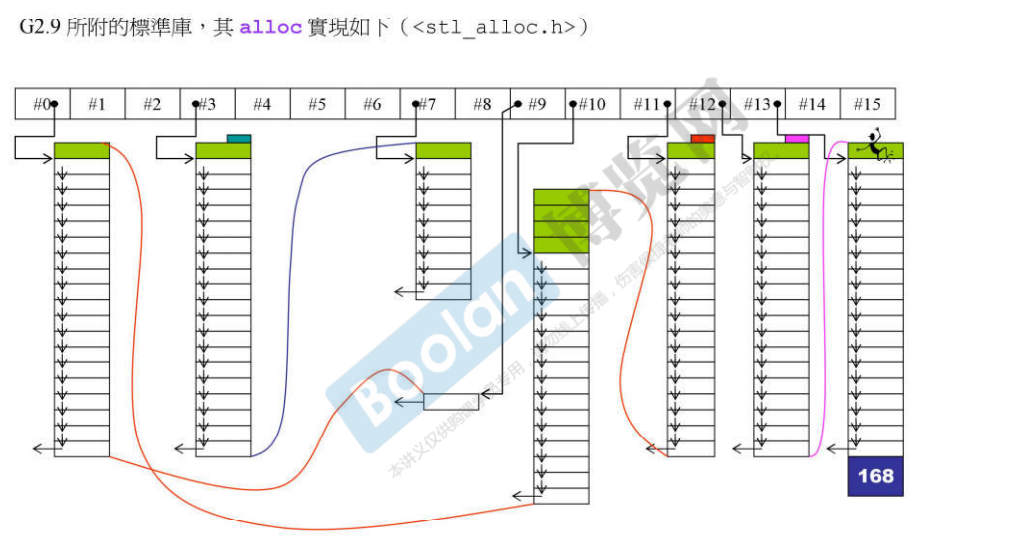
说明:
- 这个alloc分配器的主要目的是减少malloc被调用的次数,因为malloc会带着额外开销;
用分配器而不直接用C RunTime Library提供的malloc函数,其本质上是减少内存的额外开销,也就是说分配器会预先开好一定的空间,尽量减少malloc的使用次数,它不是需要多少开多少,也就是我们常说的内存池设计。
- 设计了16条链表,每条链表负责不同大小区块的内存,#0负责8bytes大小的区块,#1负责16bytes大小的区块,以此类推…,超过这个分配器能管理的最大的区块128bytes,就仍然要调用malloc函数分配;
- 所有的容器,当它需要内存的时候都来向这个分配器要内存;容器中元素的大小会被调整为8的倍数;
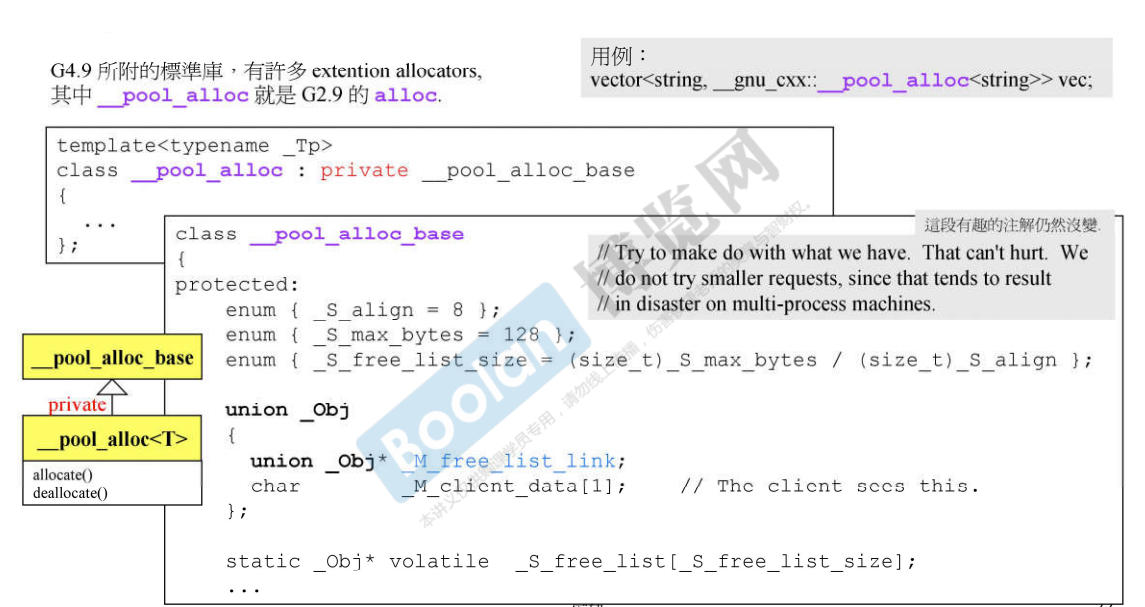
- G4.9 STL对allocator的使用

说明:
- 这个分配器也是直接调用的malloc和free进行内存的分配和回收,没有其他操作。
- G4.9 的STL的容器使用的分配器是标准库的allocator分配器,而没有使用G2.9中的alloc分配器,G2.9中的alloc分配器在G4.9中还在,只是名称变了,名称现在是__pool_alloc.
- 之所以说__pool_alloc就是G2.9的alloc,因为相关的数值都仍然存在:管理8的倍数的区块,最大可以管理128字节的区块,有16条链表;
- 这种比较好的分配器仍然是可以使用的,使用方式如图中所示的“用例”,第二个模板参数指定分配器,pool_alloc所在的命名空间为gun_cxx;
10. 容器的结构分类介绍

说明:
- 如图中的注释说明,缩排表达的关系是复合,就是set 里面有rb_tree,map里面有rb_tree,multiset/multimap里面有rb_tree;
- 同理,heap中有vector,priority_queue中有vector,priority_queue中有heap;stack和queue中都有一个deque;
- 图中的左右两侧表示的是容器要操作数据必须有的指针或元素,这个整体的大小,不包括数据,通过sizeof计算
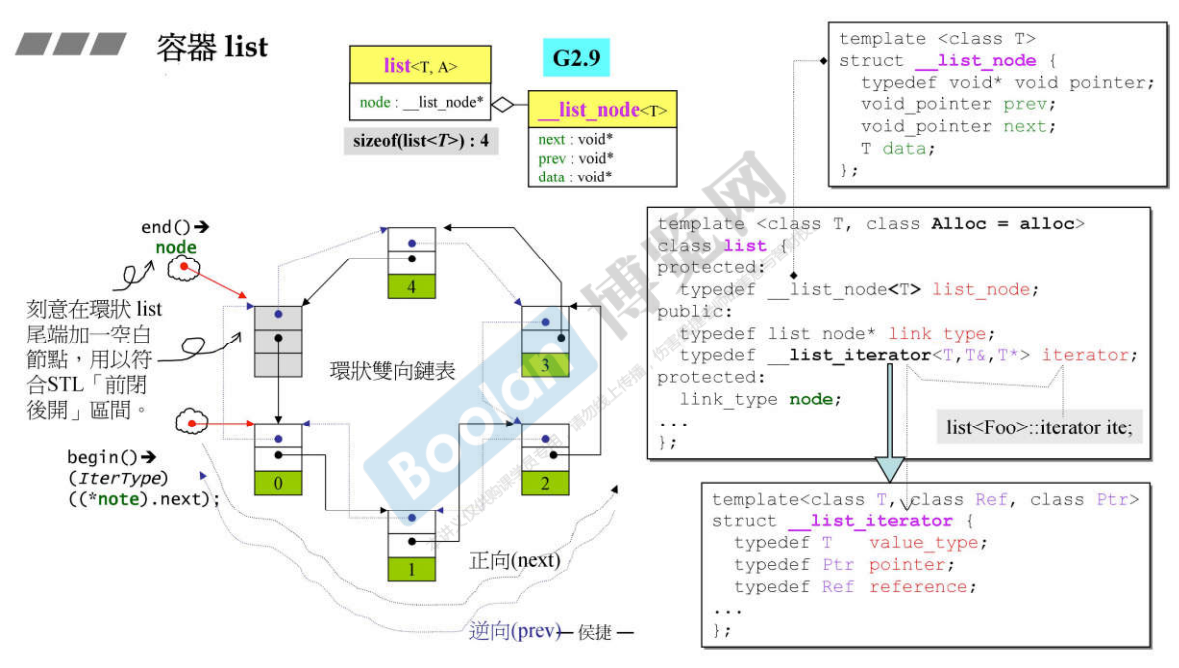
11. 深度探索list
11.1 G2.9的list
- G2.9版本,list的设计是双向环状链表,每个节点是一个指针,这个节点又由两个指针(一个向前指一个向后指)和数据部分data组成;
- list整体数据部分是node,而node是list_node类型,list_node是list的一个节点,所以list占用的内存大小是4(在32位机器上),当list从allocate拿内存时是以节点为单位的,也就是说除了数据data部分,还要有两个指针;prev和next,以及数据data,所以这就是一个双向链表,注意这里的prev和next指针是void类型的,这种写法可以使用,但是必须进行强转型,这种方式不太好,在G4.9中已经进行了改善,这两个指针就指向__list_node类型;
- 最后一个节点的下一个节点一定要加一个空白节点(图中的灰色节点),为了符合STL的「前闭后开」区间;不但是双向的,而且是环状的。
- 链表是非连续的空间,所以它的Iterator不能是指针,因为Iterator模拟指针,就要能进行++这些操作,但是如果list的Iterator进行++ 操作不知道指到哪里去了;所以Iteartor必须足够聪明,当进行++操作的时候知道要指向list的下一个节点;
- 除了vector和array外的所有容器的iterator都必须是class,它才能成为一个智能指针;
list’s iterator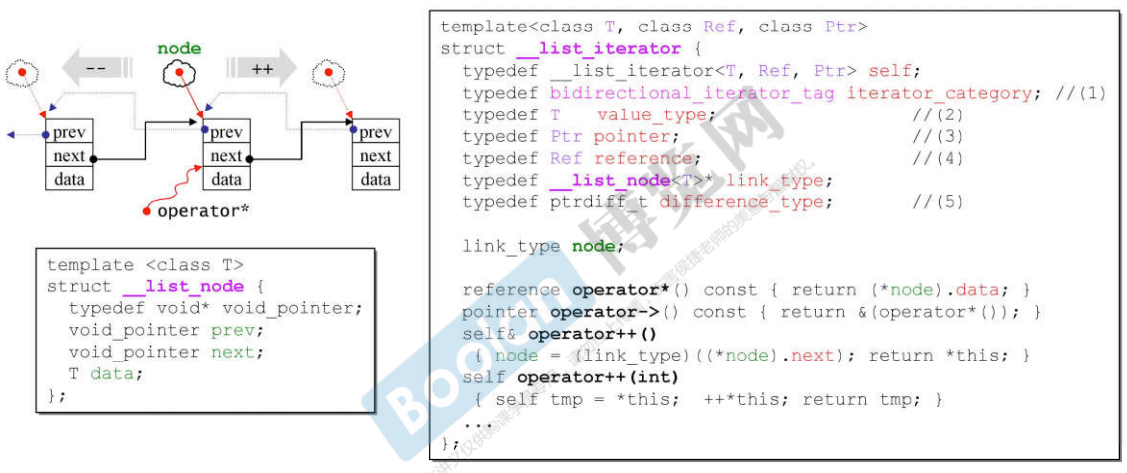
说明:
- iterator要模拟指针,所以有大量的操作符重载;
- 所有的容器中的iterator都要做5个typedef,如上图中的所示的(1)(2)(3)(4)(5);
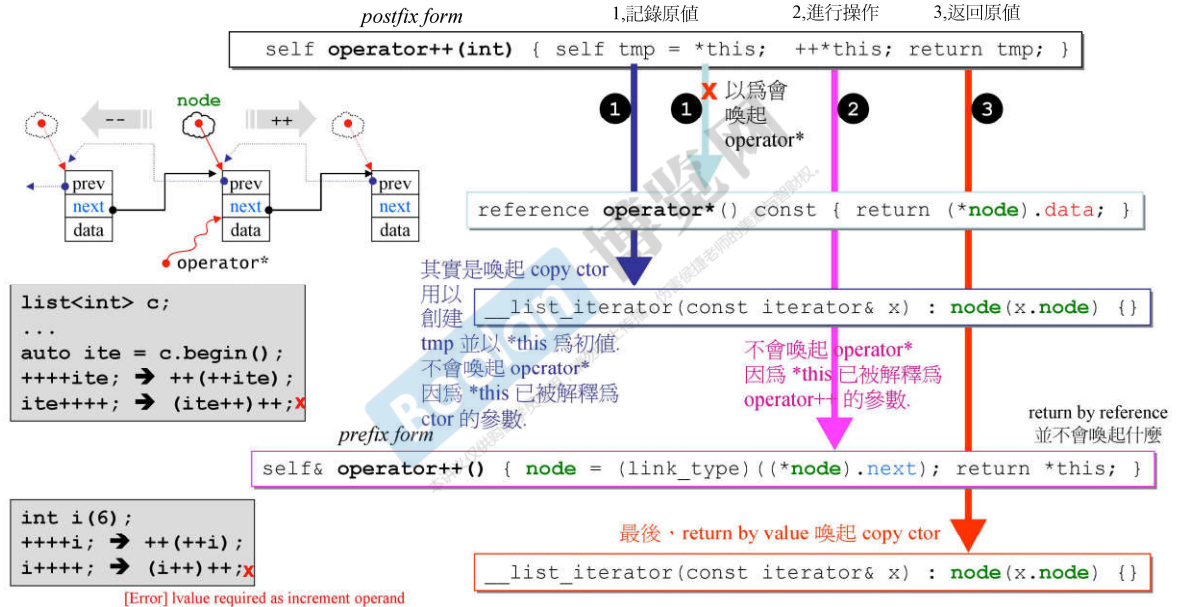
说明:
- i++叫做postfix form,++i叫做prefix form,因为无论是前缀还是后缀形式,都只有i 这个参数,C++中为了区分这种情况,规定了operator++()无参表示前缀,此时的i已经变成调用这个函数的对象本身了;operator++(int)有参表示后缀;
- self& operator++()函数可以成功的将node进行移动,指向下一个节点;
而self operator++(int)函数的流程是先记录原值,然后进行操作,最后返回原值。注意:
- 此时的记录原值的操作:self tmp = this;并不会调用重载的operator函数,因为这行代码先遇到了=运算符,所以会调用拷贝构造函数,此时的*this已经变成了拷贝构造函数里面的参数;
- ++*this 调用了重载的operator++()函数;
- 注意返回值的差别。之所以有差别是向整数的++操作看齐:整数里面是不允许进行两次后++的,所以这里iterator的operator++(int)为了阻止它做两次后++操作,返回值不是引用;整数中是允许做两次前++的操作,所以iterator的opeartor++()返回值是引用。c++语法不允许后++加两次,因为后加加操作符重载后返回的不是引用(后加加里面有临时变量)
iterator的*和->操作符的实现
说明:
- operator* 就是获得node指针指向的节点的data数据;
- operator->获取node指针指向的节点的data数据的地址;
小结
- list是个双向链表,因为每个节点除了有data,还有next和prev指针;
- 所有的容器的iterator都有两大部分:(1)一些typedef;(2)操作符重载
11.2 G4.9的list
- G4.9相比G2.9的改进:
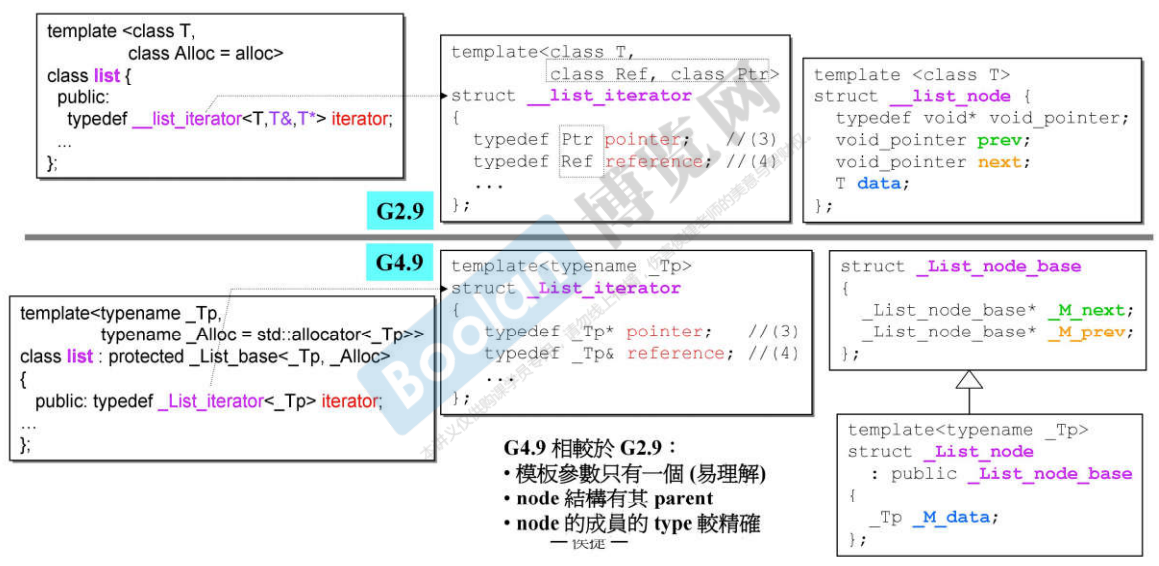
说明:
- iterator的模板参数只有一个,容易理解;
- G4.9中的指针prev和next是本身的类型,而不再是void*;
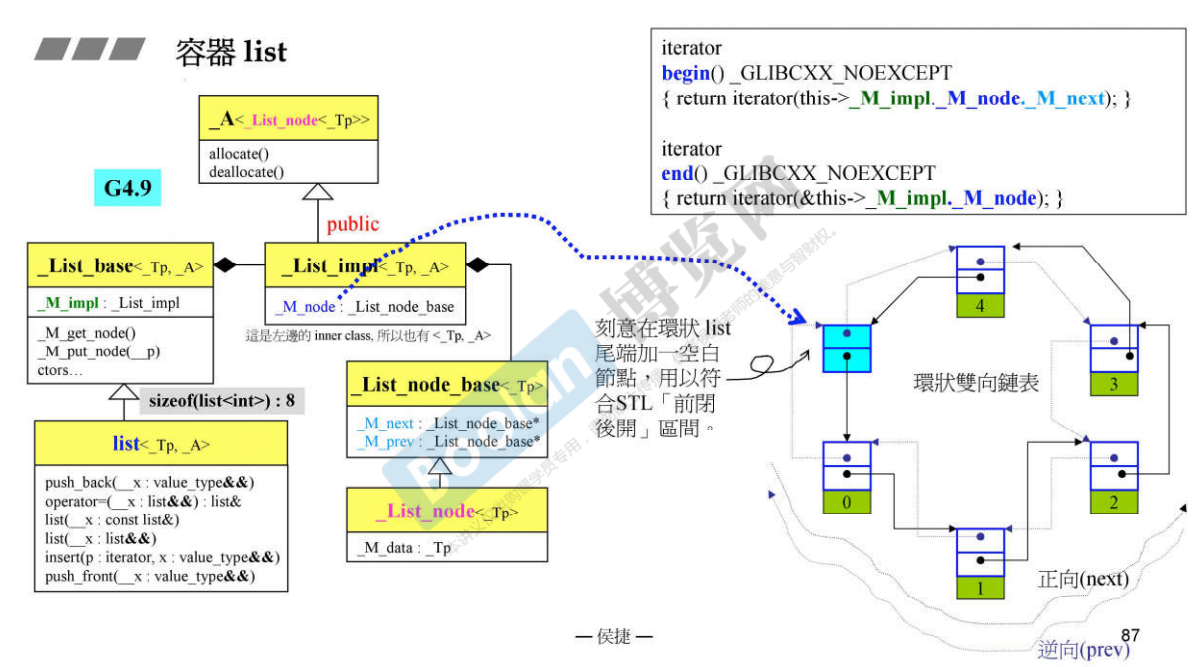
说明:
在G2.9的list图中看到了,sizeof(list)在G2.9中是4,因为只有一个指针;而在G4.9中是8,为什么是8呢?
G4.9的list中本身没有数据,所以size = 0;但是它有父类_List_base,所以父类多大,它就多大;
- _List_base中的数据为_M_impl,所以这个数据多大,_List_base就多大;
- _M_impl类型为_List_impl,而_List_impl中的数据类型是_List_node_base;
- _List_node_base中有两个指针,所以sizeof(list) = 8。
11.3 迭代器的设计原则和Iterator Traits的作用与设计
设计Traits实现希望你放入的数据,能够萃取出你想要的特征。标准库中有好几种Traits,针对type的有type traits;针对characters,就有char traits;针对pointer,有pointer traits,… 。这里,只看iterator traits。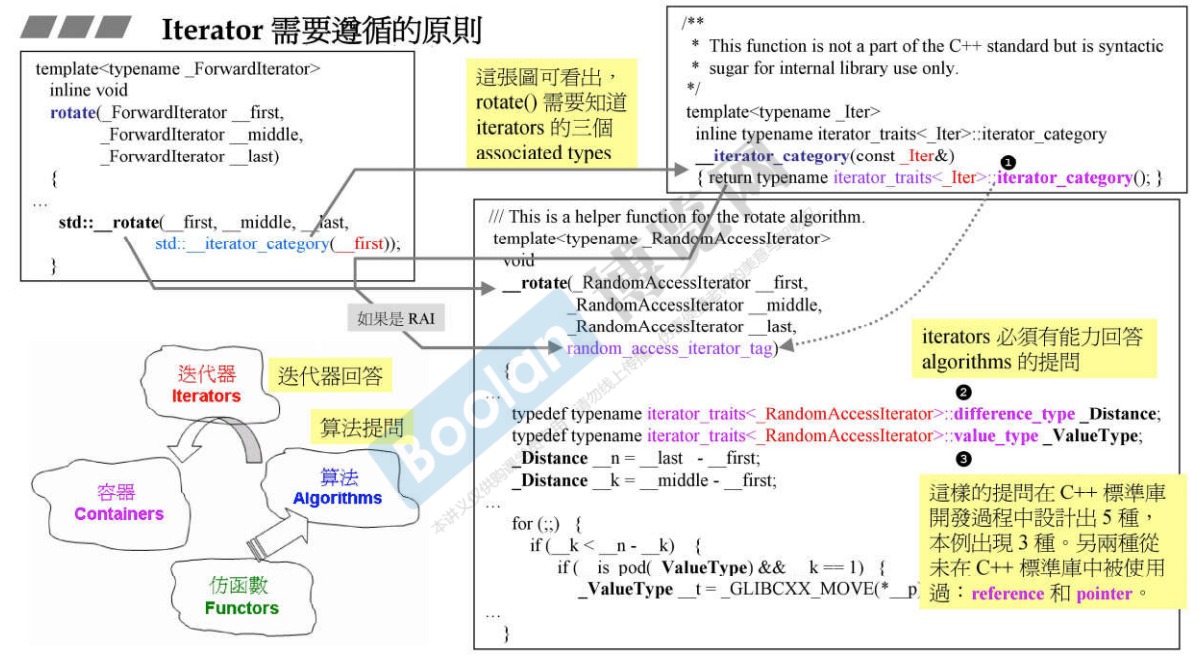
迭代器是算法和容器的桥梁,它是类模板的设计,迭代器必须有能力回答算法提出的问题才能去搭配该算法的使用。
举例:有一个rotate算法,会想要知道iterator的哪些属性?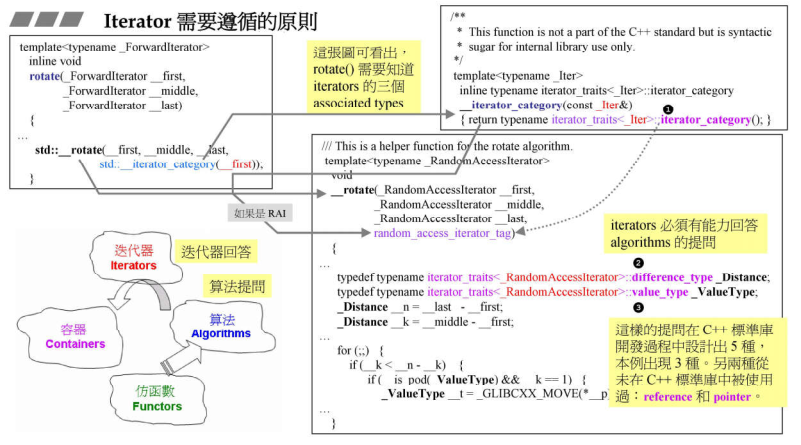
- 想要知道iterator的分类(iteartor_traits<_Iter>::iterator_category()),有的迭代器只能++,或者只能–,有的可以跳着走,得到分类以便可以选取最佳的操作方式;
- 想要知道iterator的difference_type,两个iterator之间的距离;
- 想要知道iterator的value_type,指的是迭代器指向的元素的类型,比如在一个容器中放了10个string类型的元素,那么这个value_type就是string;
深刻分析迭代器的associated types
C++标准规定,所有的迭代器必须提供5种相关类型(associated types)以便回答算法的提问。
- iterator-category:迭代器的类型,标准库提到了5中迭代器类型
- value_type:迭代器的数据类型,放入的是哪种迭代器;
- difference_type:两个迭代器间的距离;
- pointer:迭代器的指针(算法目前没有使用);
- reference:迭代器的引用(算法目前没有使用);
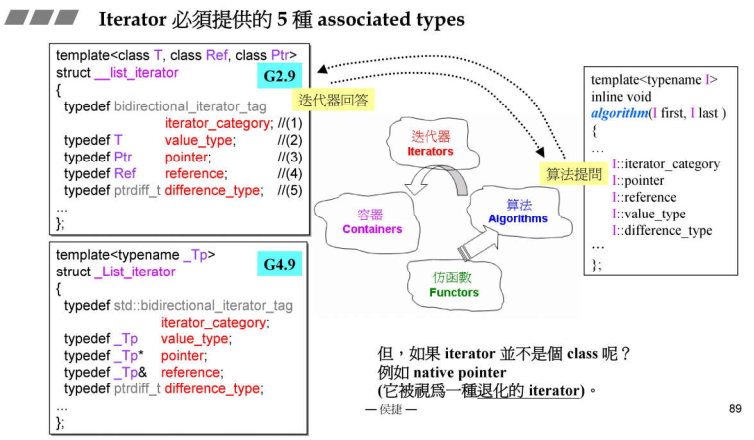
说明:
- 标准库中用ptrdiff_t来表示两个迭代器之间的距离,这个ptrdiff_t也是C++中定义的,但是如果实际存放的元素的头和尾的距离超过了这个ptrdiff_t类型表示的范围,那这就失效了;
- 因为list是个双向链表,所以这里使用了bidirectional_iterator_tag来表示iterator_category;
- 可以看到,这里并没有traits,那么为什么还要谈到iterator traits呢?因为如果 iterator 不是 class,就不能进行typedef,如果iterator是native pointer,即C++中的指针,它被视为一种退化的 iterator。所以当调用算法的时候,传入的可能是个指针,而不是泛化指针,不是个迭代器,那此时算法怎么提问呢?此时,才需要设计出 traits。
Traits,特性,特征,特质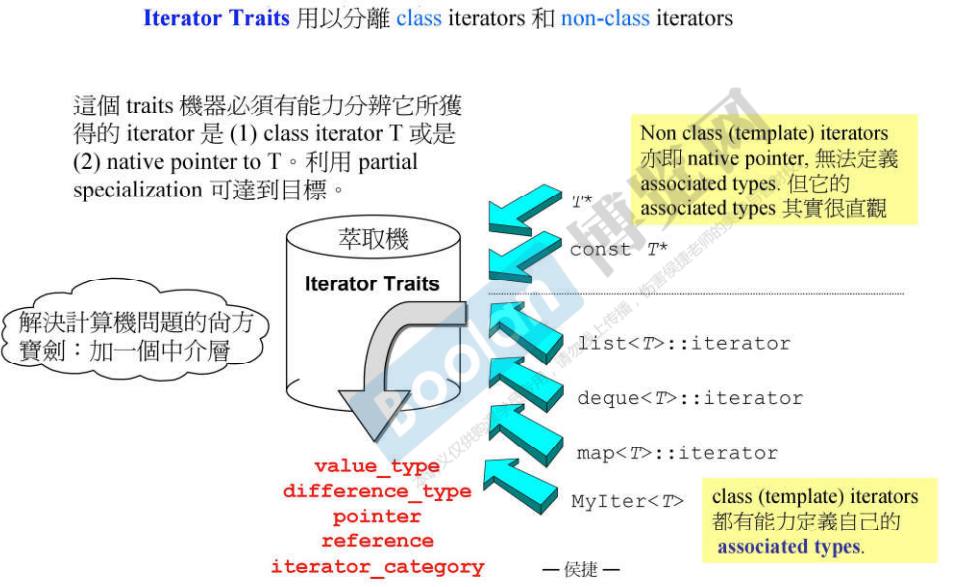 图中的“萃取机”必须能区分它所收到的iterator,到底是以class设计的iterator还是native pointer的iterator;
图中的“萃取机”必须能区分它所收到的iterator,到底是以class设计的iterator还是native pointer的iterator;
说明:
- 因为算法不知道iterator是什么类型,所以不能直接提问,而是间接问。将iterator放入traits,算法问traits:value type是什么?
- 然后traits问iterator或指针:value type是什么?
- 若traits要问的对象是class iterator,则进入图中的①
- 若traits要问的对象是 pointer,则进入②或者③
- 为了应付指针的形式,增加了中间层 iterator traits,利用了偏特化分离出指针和const指针;
- 这一页回答了算法的value_type的提问;
完整的iterator_traits
说明:如果是iterator,则进入泛化版本;如果是指针,则进入偏特化版本。算法问traits,当traits发现手上的东西是指针的时候,就由traits替它回答。

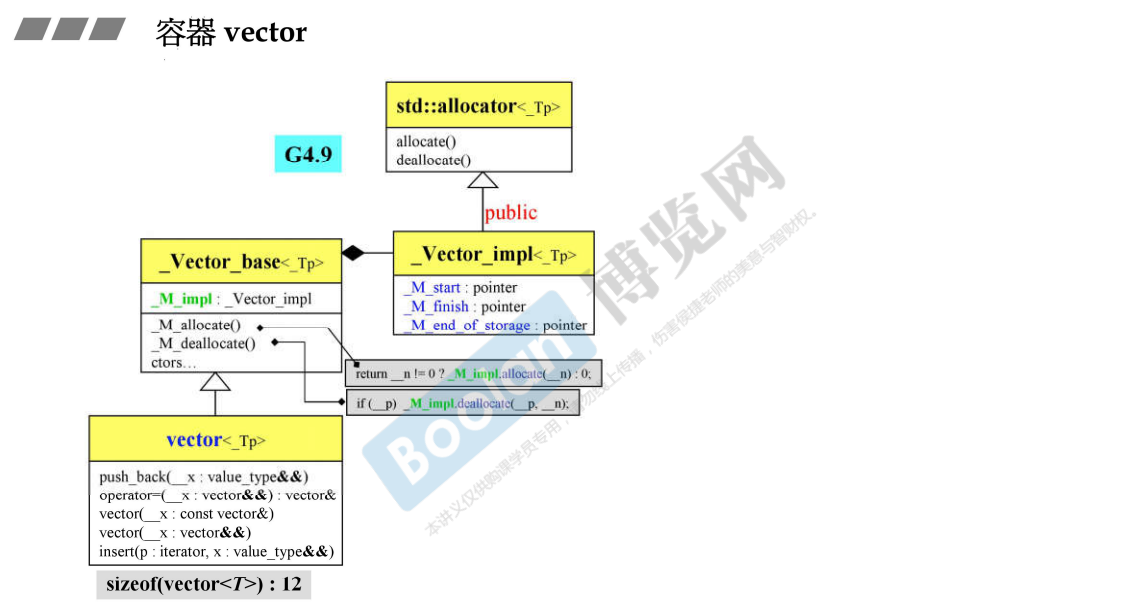
12. 深度探索vector
12.1 内部实现
- Vector是自增长的数组,其实在标准库中没有任何一种容器能原地扩充,它给人假象的扩充只是在内存的另外一个地方找到一个大的空间,再把原来的数据搬过去;
- Vector只需要3根指针start、finish、end_of_storage就能完全控制内存的增长,所以在32位机器上sizeof大小为3*4=12
- 号称连续增长的容器都必须实现中括号[]的运算符重载

12.2 增长模型
使用push_back放元素时它会检查当前是不是有足够空间。创建Vector时,它的大小就是0,所以第一次内存扩充为1,在这个之后如果需要扩充那就扩充到2*现在容器size的大小,之后调用分配器扩充内存,再把原来内容拷贝到新的地方,接着把新的元素安插到末尾,还要进行删掉之前地方的元素释放空间
之所以在insert_aux函数中也做了finish == end_of_storage的判断,是因为insert_aux除了被push_back函数调用外,还可能被其他函数调用,在那种情况下,就需要做检查;
说明:
- 没有备用空间的时候,先记录下原来的size,分配原则:如果原大小为0,则分配1;如果原大小不为0,则分配原大小的2倍,前半段用来放置元数据,后半段准备用来放新数据;
- 确定了长度之后,使用分配器的allocate函数进行内存空间的分配;
- 然后将原来vector的内容拷贝到新的vector;
- 为新的元素设定初值;(要放入的第9个元素);
- 因为insert操作也会使得空间发生增长,也会调用到这个insert_aux,所以要把安插点之后的内容也进行拷贝;
- 每次成长都会大量调用拷贝构造函数和析构函数(析构原来vector中的元素),需要很大的成本;
[
](https://blog.csdn.net/u011386173/article/details/122289750)
12.3 迭代器
G2.9
算法调用迭代器进行操作时,会调用萃取机询问相关的类型。
- vector的空间是连续的,可以直接使用指针作为迭代器,vector类中的iterator是指针。
- 当算法要提问iterator的时候,就通过iterator_traits进行回答;当前的iterator是个指针,当它丢给萃取机萃取的时候,就是图中箭头指向的T,因此萃取机就会进入偏特化的版本——struct iterator_traits<T> ;
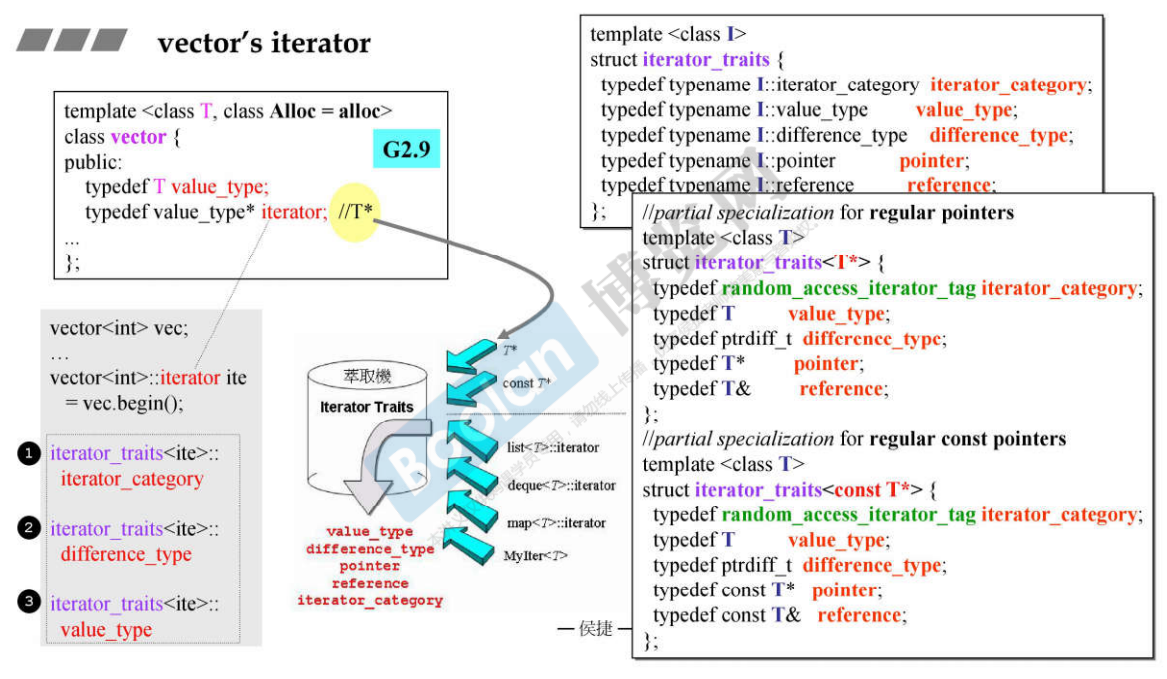
G4.9
- G4.9的vector也有三个指针,_M_start、_M_finish、_M_end_of_storage,所以 sizeof(vector) = 12;
G4.9的vector的iterator经过层层推导就是T*外包裹一个iterator adapter,使得能支持 5 种 associated types;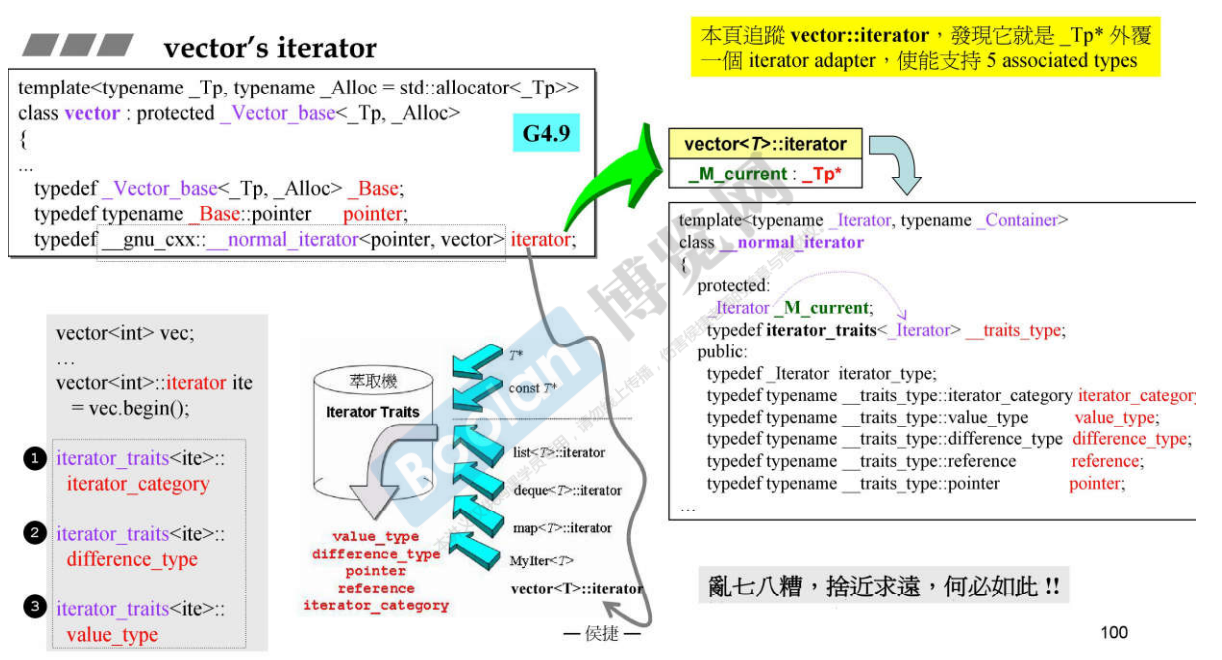
算法向iterator提问的时候,将iterator放入萃取机中,因为此时的iterator是个object,所以走图中的灰色细箭头这一条路径;而在iterator内部本身就定义了 5 种 associated types;
[
](https://blog.csdn.net/u011386173/article/details/122289750)
13. 深度探索array
- Array就是C语言中数据的包装类,正因为有了这层包装,Array才能享受标准库给予6大部件的便利;
Array必须初始化给定空间大小,期间不允许改变大小,也是连续空间,只要是连续空间其迭代器就可以用自然指针来询问。
13.1 TR1版本
technique report 1版本,介于C++1.0与2.0之间的过渡版本。

没有ctor, dtor。
- 迭代器可以用指针来单纯的指针来表现,不用再设计单独的class,因为是连续的。
13.2 G4.9

数组的写法:
即此处的_M_elems变量是个数组;int a[100]; //OK int[100] b; //fail typedef int T[100]; T c; //OK
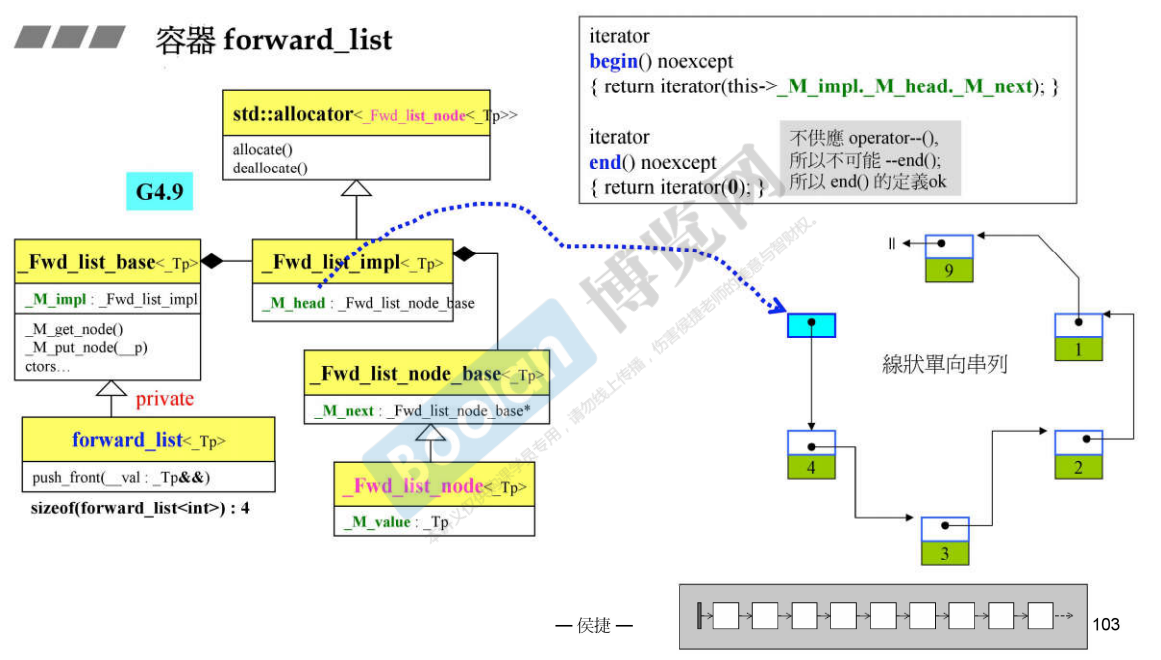
14. 深度探索forward_list
15. 深度探索deque、queue和stack
几乎所有的容器都维护了两个迭代器start和finish,分别指向头和尾;几乎所有的容器都提供两个函数,begin() 和 end(),其中begin()传回start,end()传回finish;
15.1 G2.9的deque
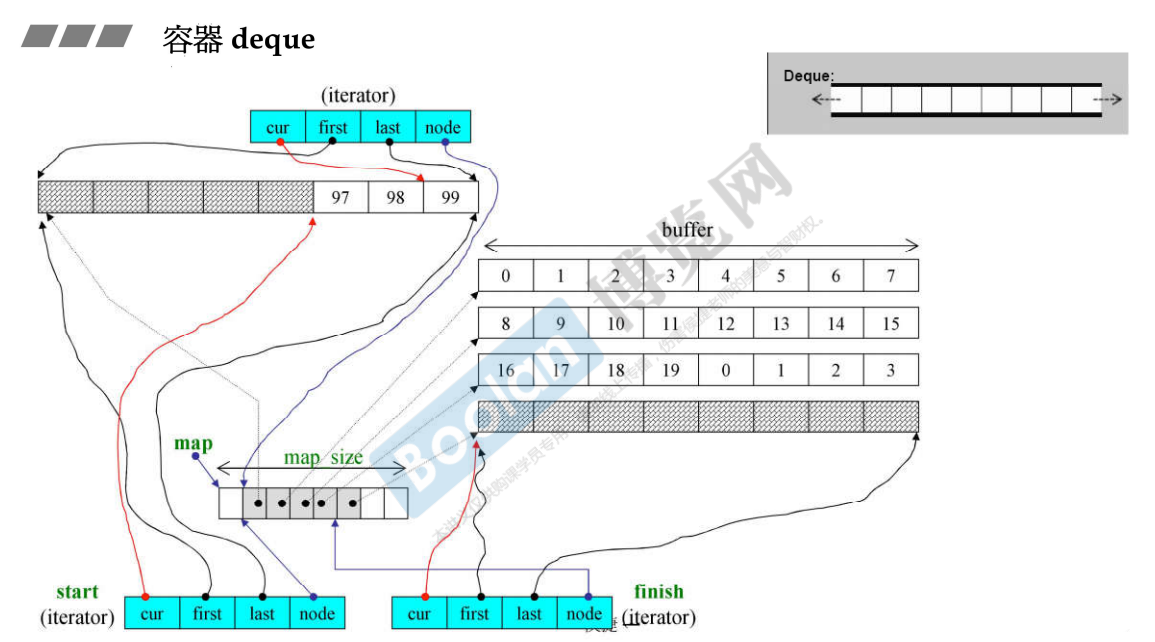
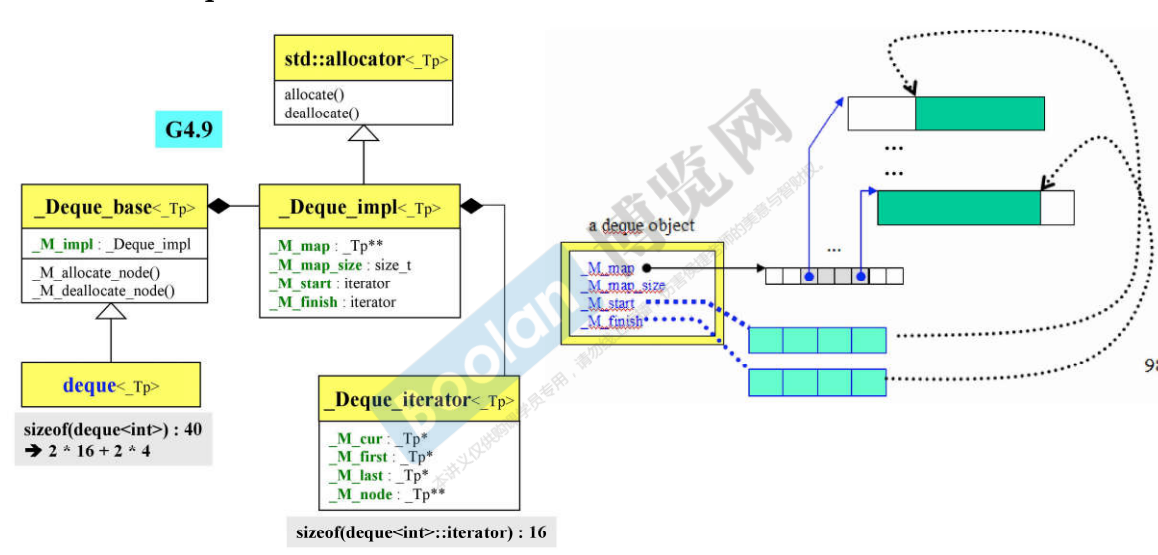
- Deque(双向队列)也号称连续空间(假象),分段连续,deque是个vector,其中的每个元素都是一个指针,这些指针分别指向不同的buffer;
- 如果当前空闲的最后一个buffer使用完了,要继续push_back,那么新分配一个buffer,并将其deque当前图上的倒数第二个空白位置指向这个buffer即可,这就是往后扩充;也可以向前扩充。
- Deque的迭代器有4个指针,其中node表示在控制中心的位置(也就是在Vector中的位置),first表示node所指的buffer的头,last表示node所指的buffer的尾,first和last是边界的标兵,它们时不会变的,cur表示迭代器当前指向的哪个元素;
- deque的迭代器是class,其中包含了cur、first、last和node四个部分:
- 其中的node指的就是图中deque中指向buffer的指针,为控制中心。一个迭代器能知道控制中心在哪里,当迭代器要++或–的时候就能够跳到另一个分段,因为分段的控制全部在这里;
- first和last指的是node所指向的buffer的头和尾(前闭后开),标识出buffer的边界,如果走到了边界,就必须依靠node指针回到控制中心(Vector)再跳到下个buffer
- cur就是当前迭代器指向的元素;
- 每个缓冲区大小:512字节除以放入数据的字节大小,比如放int,缓冲区大小=512/sizeof(int)
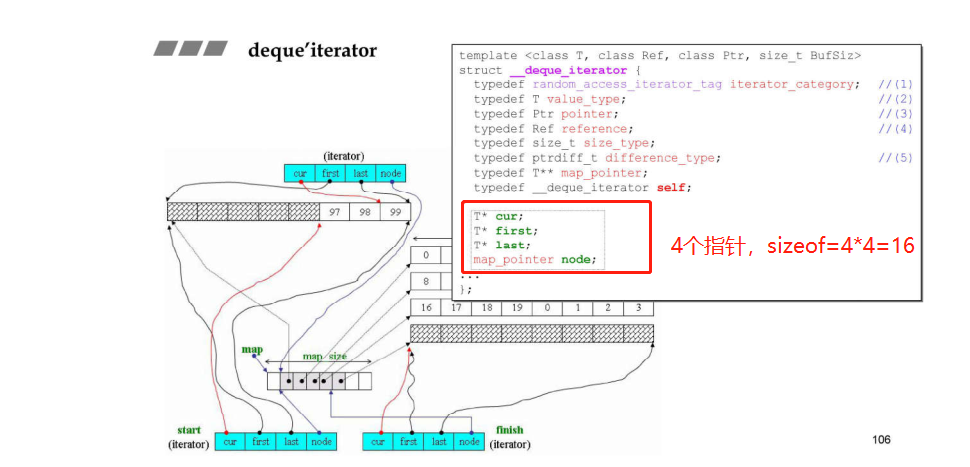
说明:
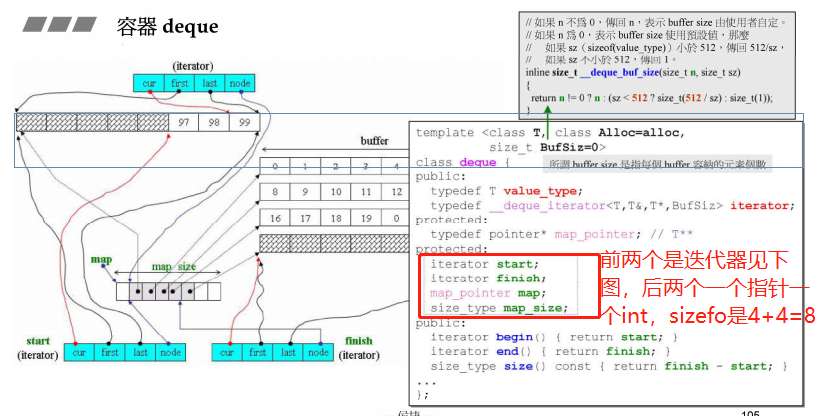
- 数据部分的map的类型是T**,占 4 个字节;
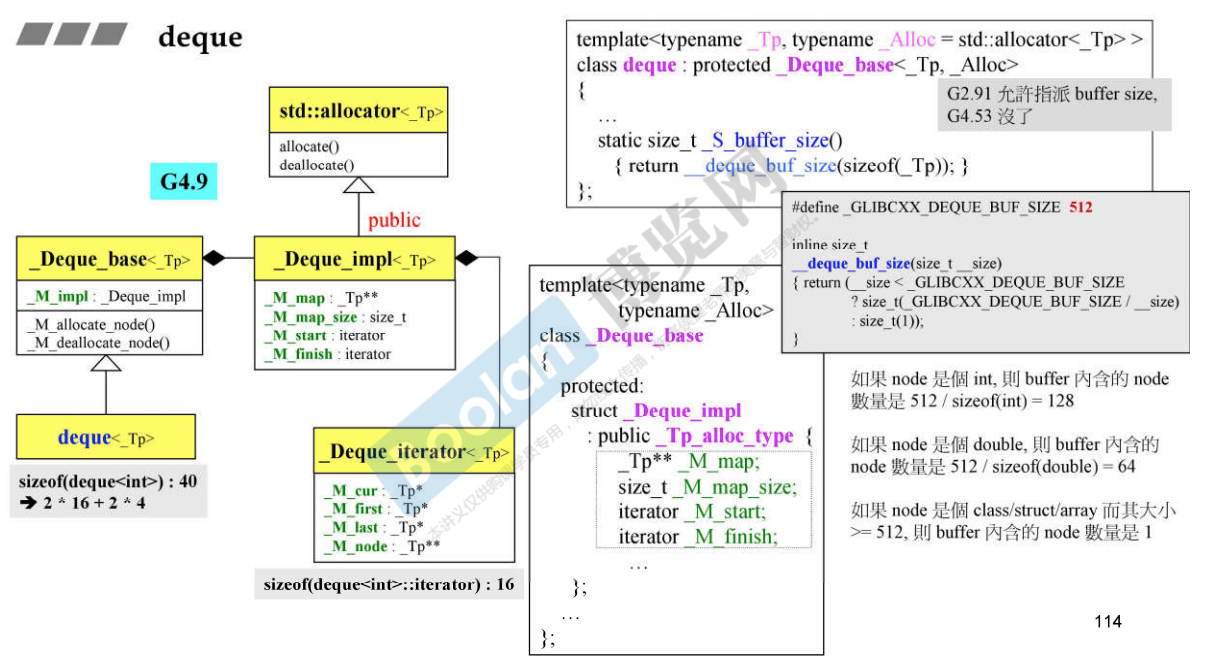
- iterator中的数据为下图的deque’s iterator中所示的cur、first、last和node,都是指针,所以迭代器大小为 16 字节,那么一个deque的大小为“两个迭代器 + map + map_size” = 16 * 2 + 4 + 4 = 40 bytes;
- deque是个模板类,有三个模板参数,第一个参数表示元素类型,第二个参数是分配器的类型,第三个参数是指每个buffer容纳的元素个数,允许指定buffer容纳的元素个数,默认值为0,deque_buf_size函数会根据该模板参数决定buffer中能容纳的元素具体个数;
deque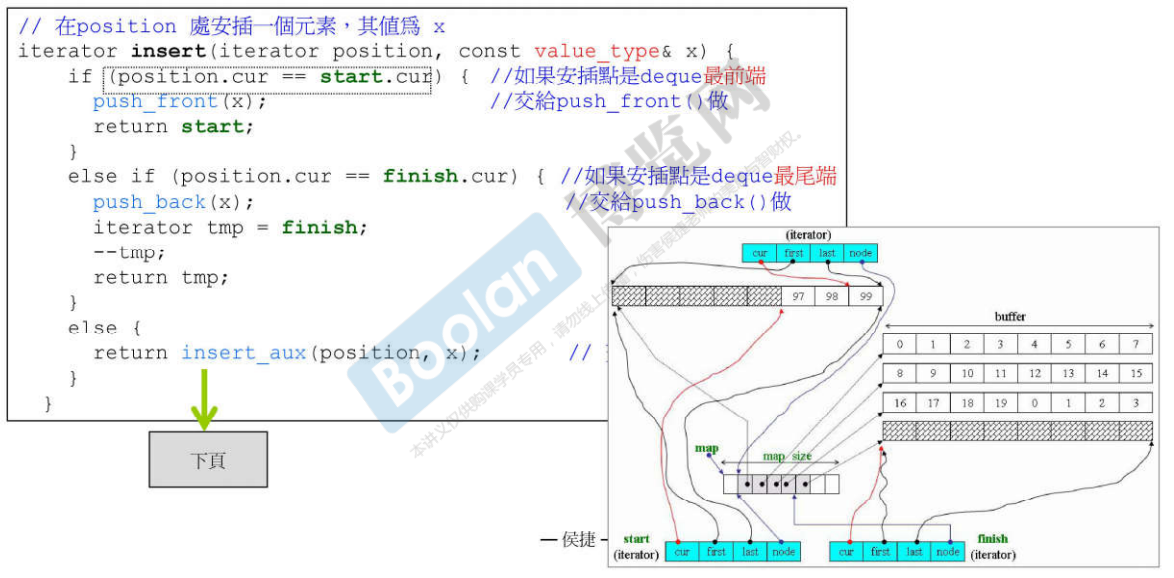
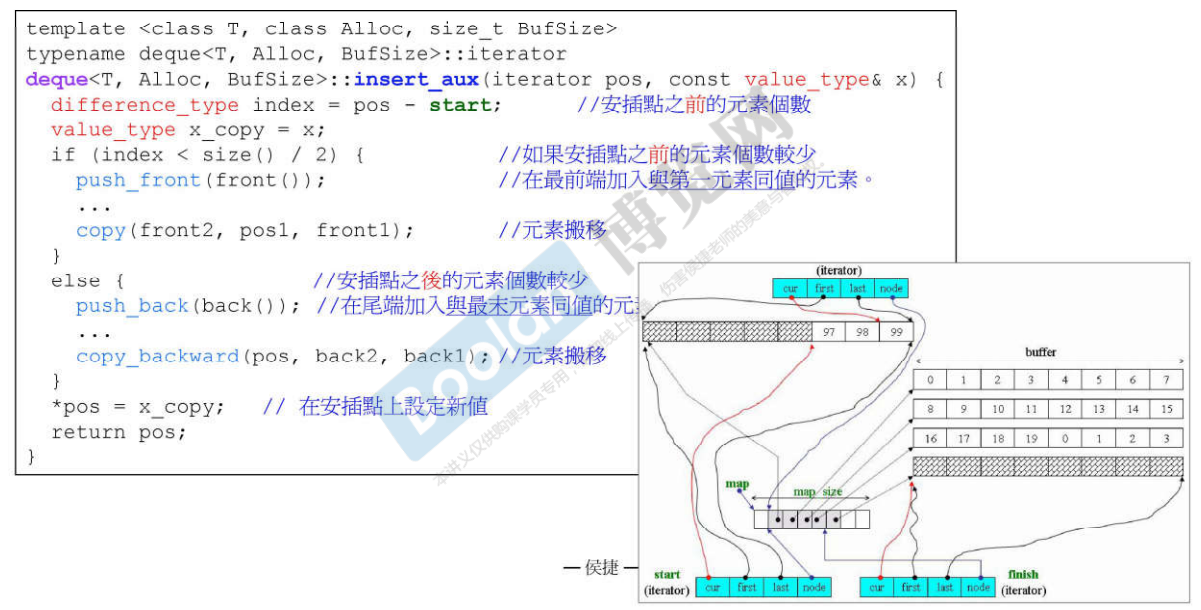
说明:
由于Deque是可以两端进行扩充的,插入元素又会引入元素移动问题,进而带来拷贝构造的开销,所以在插入时首先进行判断插入位置距离首位哪边比较短,移动距离较短的一边,最大化的减少开销。
如何实现所谓的连续空间
分段连续,那么连续空间就是要模拟连续空间提供的功能,比如自增、自减、跳跃等动作,这就是迭代器的功劳。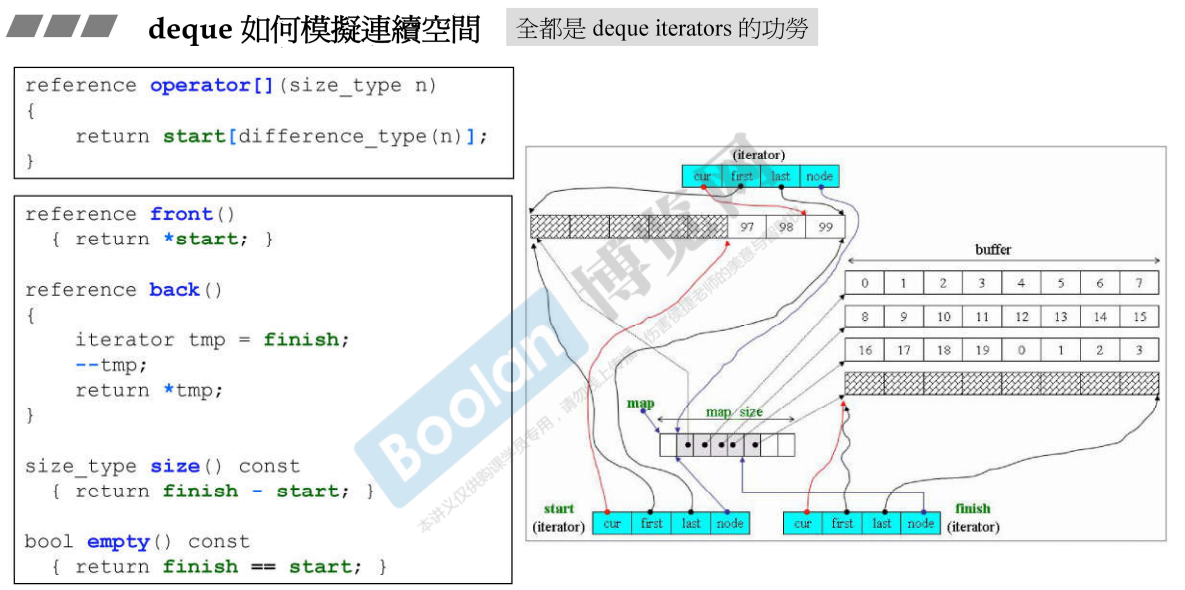
跳跃和加减操作都要注意当前缓冲区是否到边界的问题,如果到了边界要先回到控制中心(通过node指针),再进而转到下一个缓冲区
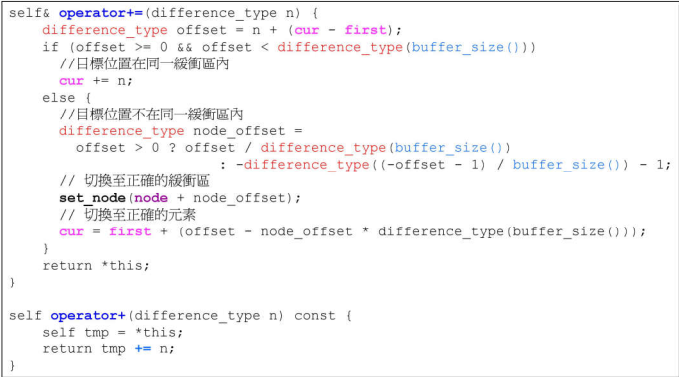
operator+=就是移动多个位置,先判断是否会跨越buffer;如果跨越buffer,要先计算跨越几个,然后退回控制中心,跨越之后再决定有几个要走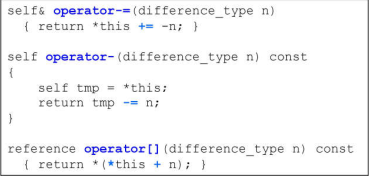
operator-=利用了operator+=
15.2 G4.9的deque
说明:
- G4.9版本相比G2.9版本,从单一的class变成了复杂的多个class;每个容器的新版本都会设计为如图的这种继承和组合的关系;
- 此时的 sizeof(deque
) = 40,和G2.9版本的大小一样,就是数据成员_M_impl的大小,即_Deque_impl类中的数据成员的大小; - G4.9的 deque 的模板参数只有两个,不允许指派buffer size;
- _M_map指向的是控制中心,它是用vector来存放指向不同buffer的指针的,当它的空间不够的时候,会二倍增长,将当前的vector拷贝到新的空间的中段,为了让左边和右边有空闲,使得可以向前和向后扩充;
[
](https://blog.csdn.net/u011386173/article/details/122289750)
15.3 queue
deque是双向进出,stack是先进后出,queue是先进先出,那么只需要在queue和stack中内含deque,然后封锁住其中某些动作。所以我们不把queue称之为容器,把它称为容器适配器
queue类中的数据成员是deque类型,所有的操作都是转去调用deque的接口来完成;
15.4 stack
和queue类似,stack 内含了一个 deque,所有的操作都是转调用deque的接口完成
15.5 queue和stack的 iterator 和底层结构
- stack或queue都不允许遍历,也不提供iterator

说明:
- stack 和 queue 都可以选择 list 或 deque 作为底层结构,默认是 deque,如图中所示,选择 list 作为底层结构也是可以的,可以成功编译和执行;
- stack和queue都 不允许 遍历,也不提供 iterator,因为stack的行为是先进后出,queue的行为是先进先出,如果允许任意插入元素的话就会干扰了这个行为模式,而stack和queue的行为是被全世界公认的,所以不允许放元素,而放元素要靠迭代器,所以根本就不提供迭代器,要取东西的时候只能从头或者尾拿;
- queue不可选择vector作为底层结构,stack可选择vector作为底层结构

说明:
- stack 可以选择vector作为底层结构;
- queue不可以选择vector作为底层结构;部分接口不能转调用vector,如图中所示的pop(),不能成功转调用,因为vector中没有pop_front这个成员函数,部分失败了;
- 通过queue测试使用vector作为底层结构的启示:使用模板的时候,编译器不会预先做全面的检查,用到多少检查多少。
[
](https://blog.csdn.net/u011386173/article/details/122289750)
- stack和queue都不可选择set或map作为底层结构

因为转调用的时候,调用不到正确的函数的话,这个结构就剔除了,不能作为候选;编译无法通是因为map使用的时候是key和value都要设置,这里使用错误,所以编译无法通过。
16. 深度探索RB_tree
关联容器我们可以看做是一个小型的数据库,它就是用key找value,编译器底层对于关联容器的实现有两种:红黑树(Red-Block tree)和哈希表(hash table,散列表)。
16.1 介绍
红黑树是高度平衡二叉树,左子树和右子树都是保持高度平衡的,不会出现某一个分支太长,并提供有迭代器,便利迭代器时红黑树是排好序的,,也就是说我们用红黑树做map和set的底层结构能够很方便的查找。
说明:
- Red-Black tree(红黑树)是平衡二叉查找树(balanced binary search tree)中常被使用的一种。平衡二叉查找树的特征:排列规则有利于 search 和 insert,并保持适度平衡——无任何节点过深。
- rb_tree 提供 ”遍历“ 操作及 iterators。按正常规则(++ite) 遍历,便能获得排序状态(sorted)。【注:begin()记录的是最左的节点,end()记录最右的节点】
- 不应使用 rb_tree 的 iterators 改变元素值(因为元素有其严谨排列规则)。编程层面(programming level)并未阻绝此事。如此设计是正确的,因为 rb_tree 即将为 set 和 map 服务(作为其底部支持),而 map 允许 元素的data 被改变,只有元素的key 才是不可被改变的。
rb_tree 提供两种 insertion 操作: insert_unique() 和 insert_equal()。前者表示节点的key一定在整个 tree 中独一无二,否则安插失败;后者表示节点的 key 可重复。
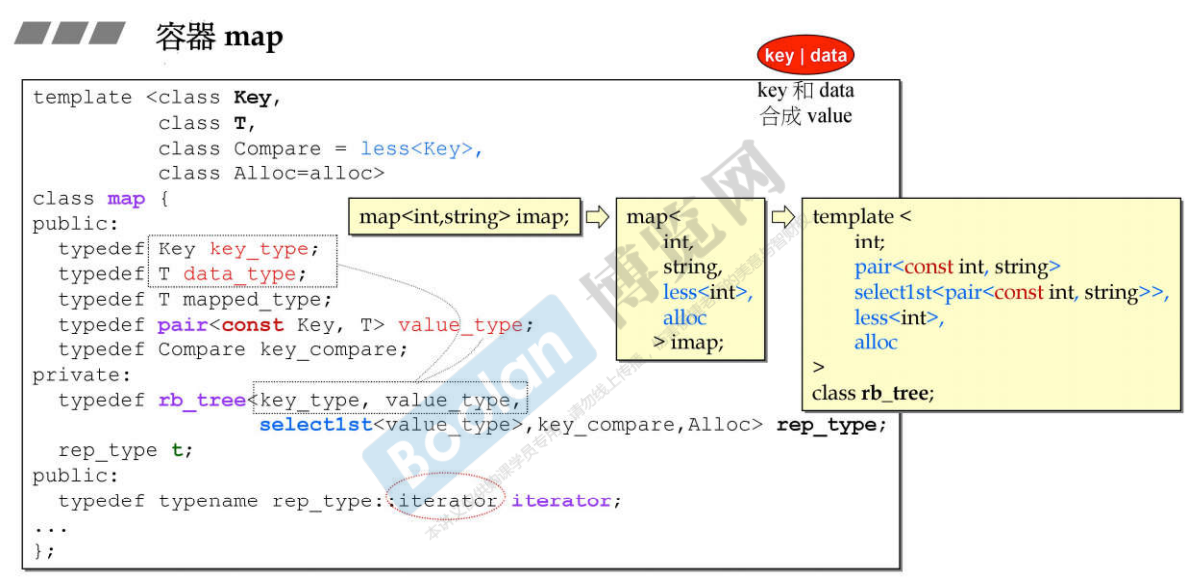
16.2 G2.9 容器rb_tree
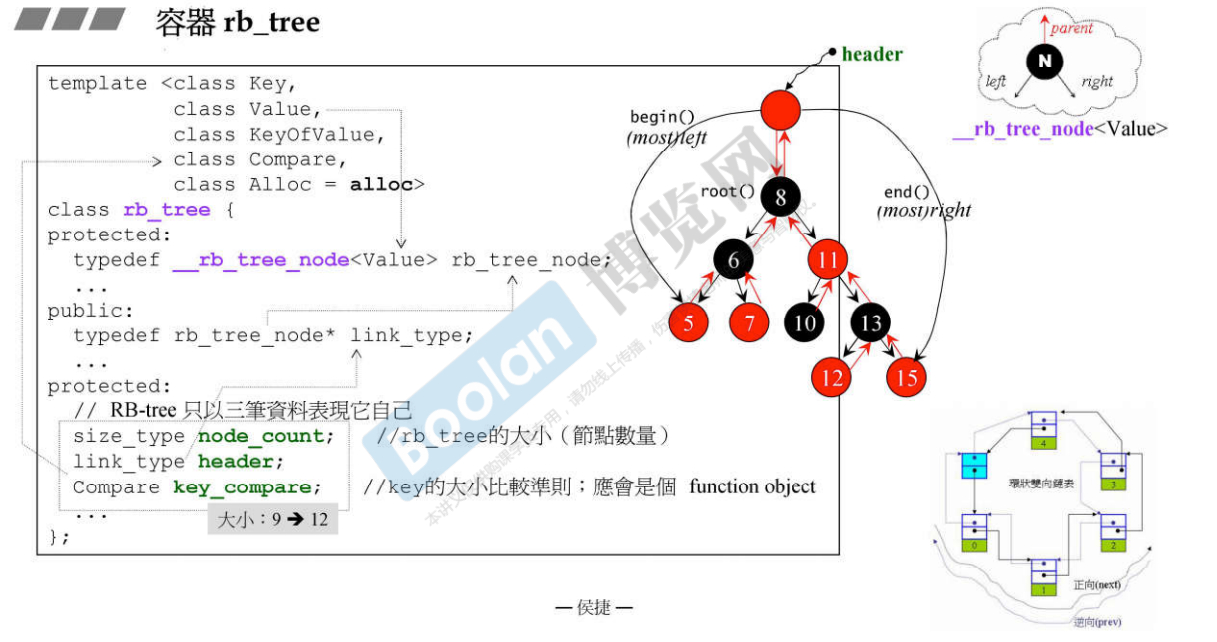
说明:rb_tree是一个模板类,模板参数:
- Value:key 和 data 合成 value,其中的data也可能是其他的数据合起来的;
- KeyOfValue:如何取出value中的key;
- Compare:比较函数/仿函数;
- Alloc:分配器,默认为alloc;
- 数据部分:
- node_count:rb_tree中的节点数量;
- header:指向rb_tree_node的指针;
- key_compare:key的大小比较规则;Compare仿函数,没有数据成员,所以大小为0,任何的编译器,对于大小为0的class,创建出来的对象的size一定为1
- 所以数据部分一共的大小是 9,但是因为内存对齐,以4的倍数进行对齐,所以 9 要调整为 12;
- 图中的双向链表中的天蓝色节点,是一个虚空节点,为了做「前闭后开」区间,刻意放入的,不是真正的元素;红黑树中的header也是类似的,刻意放入的,使得代码实现更加简单;

示例:
rb_tree<int,
int,
identity<int>, //仿函数,重载了operator()函数,告诉红黑树要如何取得key,GNU C 独有的,不是标准库的一部分
less<int>, //key比较大小的方式,less是标准库的一部分
alloc>
myTree;
16.3 G4.9 容器_Rb_tree
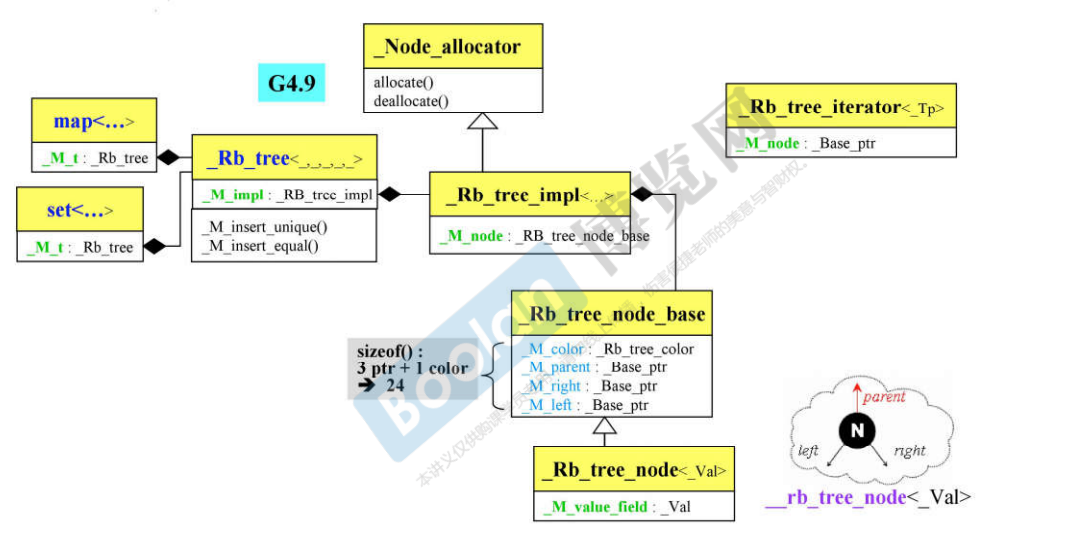
说明:
- G4.9版本相比G2.9版本,类结构发生了变化;
- OO思想里面,类中包含一个指针指向另一个类,主体本身不做任何事情,都是通过指针指向的另一个类做事情,这中手法叫做Handle-Body;
- set和map里都各有一个_Rb_tree;
- 此时的_Rb_tree的数据的大小取决于_M_impl这个数据成员的大小,而_M_impl类型是_Rb_tree_impl;Rb_tree_impl中的数据成员_M_node的类型是_Rb_tree_node_base,其中包含了四个数据成员:3 个指针,1个_Rb_tree_color(enum枚举类型) = 24 bytes;
使用:G4.9版本相比于G2.9部分名称发生了改变,如下红色的部分就是改变的部分:

17. 深度探索set,multiset

说明:
- set/multiset 以 rb_tree为底层结构,因此有「元素自动排序」特性。排序的依据是 key,而set/multiset 元素的 value 和 key 合一:value 就是 key。
- set/multiset 提供 ”遍历“操作及 iterators。按正常规则(++ite) 遍历,便能获得排序状态(sorted)。
- 无法 使用 set/multiset 的 iterators 改变元素值(因为key 有其严谨排列规则)。set/multiset 的 iterator 是其底部的 RB tree 的 const_iterator, 就是为了禁止 user 对元素赋值。
- set 元素的 key 必须独一无二,因此其 insert() 用的是 rb_tree 的 insert_unique()。
multiset 元素的 key 可以重复,因此其insert() 用的是 rb_tree 的 insert_equal()。
17.1 set GNU C
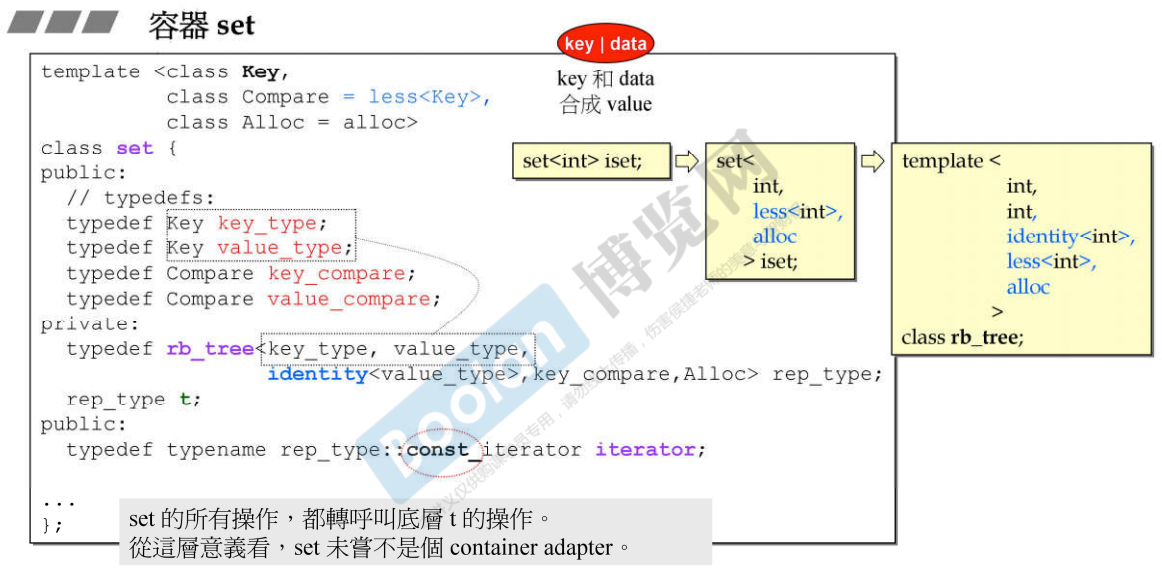
说明:
- set的模板参数有三个:Key的类型;Key的大小比较规则,默认值为less
;分配器,默认值为alloc; - set中有个红黑树变量t;从set中拿 iterator 的时候拿的是 rb_tree 的 const_iterator,这个迭代器是不允许对元素进行修改的;set的所有操作,都转调用底层 t 的操作。从这层意义来看,set 未尝不是个 container adapter;
- 之前说到 key 和 data 合起来这一整包是 value,从 value 中取出 key 用identity,set 里面取出 key 也就需要用 identity;identity 是GNU C中才有的;
17.2 VC6 容器set
- VC6 不提供 identity(),如何使用 RB-tree?自己实现了一个内部类_Kfn,写法和 GNU C 中的identity 的实现是一样的,即自己实现。

18. 深度探索map,multimap

每个元素即value包含了key 和 data,key不能修改,但是 data 可以修改;
18.1 G2.9 的容器map
说明:select1st:从value中取出第一个,即取出key;map拿出key的方式就是select1st;
- map的迭代器就是红黑树的迭代器,map自动地将key设置成 const,所以 key 放入之后不能被修改。set 中不能修改 key 是因为使用的迭代器是红黑树的 const_iterator,而map不允许通过迭代器修改key,是因为包装成 pair的时候将key设置成了 const;
-
18.2 VC6 的容器map
VC6 不提供 select1st(),自己实现一个和select1st功能一样的类_Kfn,重载operator() 函数,所以是个函数对象/仿函数,将pair 的 first 数据传回;

使用: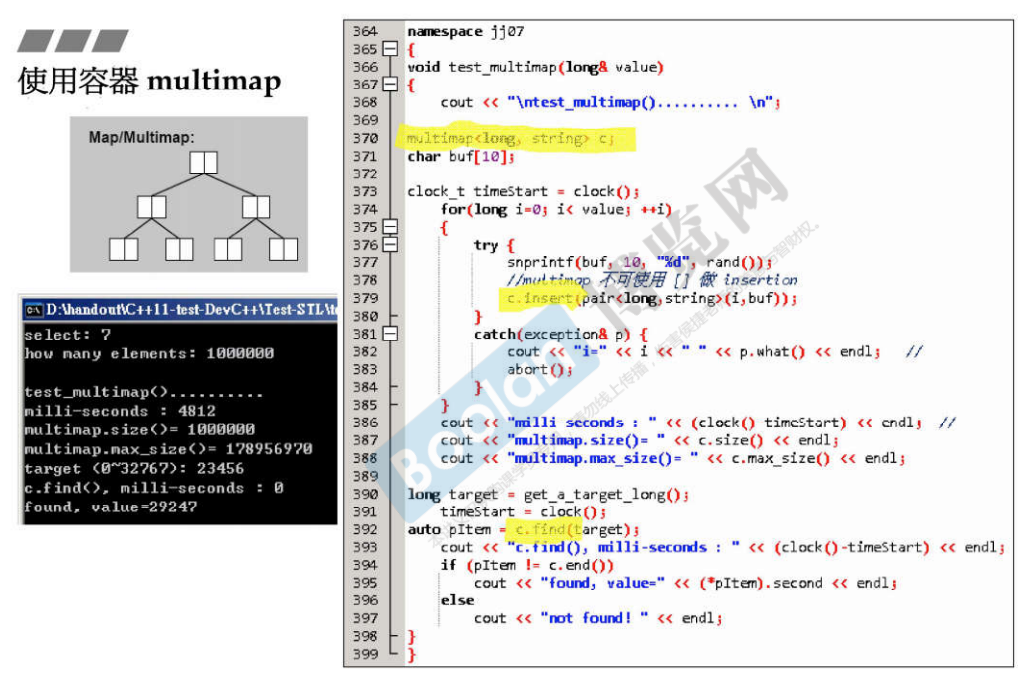
18.3 容器map,独特的operator[]
multimap不可以使用下表操作符[],而map可以使用。
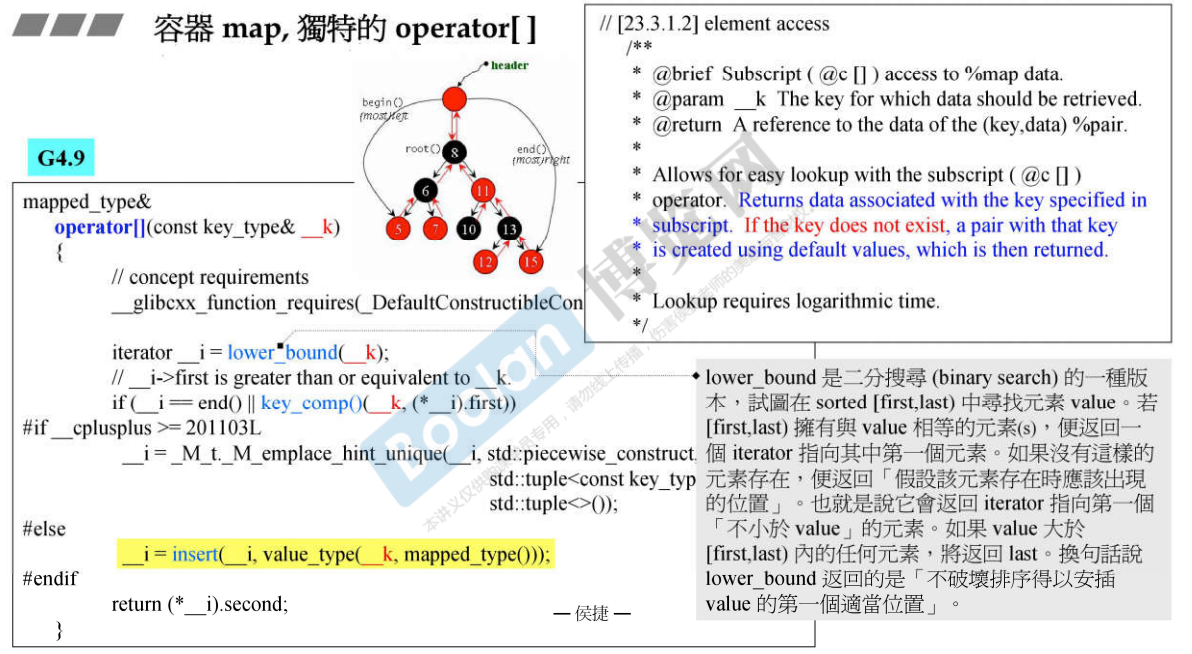
说明: map的 []操作:如果key存在,则返回 key 对应的 data;如果key不存在,那么会创建一个pair,使用默认值作为data,当前的key为key;
- 使用lower_bound查找元素value,如果找到了,则返回一个iterator指向其中第一个元素;如果没有,就返回该元素应该插入的位置,即返回iterator指向第一个「不小于value」的元素。
使用:
[]和insert哪个效率高?
insert效率高于中括号,因为中括号其实是先进行了lower_bound(二分搜寻)之后,再调用insert插入元素。
19. 深度探索hashtable
19.1 引入
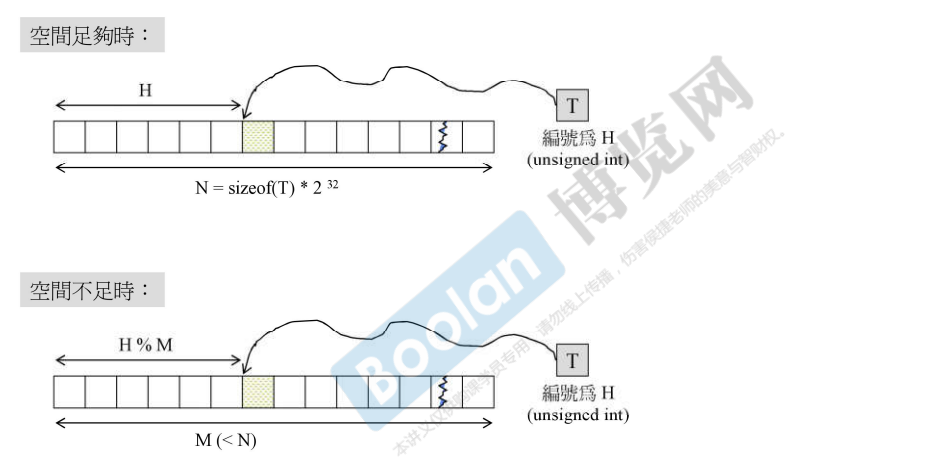
假设有N个object,每个有一个对应的编号,当空间足够的时候,就将object放到对应编号的位置上;当空间不足的时候,object的编号 % 表的长度,此时就可能出现多个object应落在同一个位置,出现了碰撞。
- Separate Chaining 解决碰撞

说明:
- 如果发生碰撞,就使用链表串起来,这种方法叫做 Separate Chaining;
- 如果链表很长,那么搜索速度就很慢,所以就需要一个方法来判断链表是否很长,如果很长就需要打散重新放置;
判断链表很长的方法,不涉及到数学,纯由经验所得:如果元素个数比bucket个数多,就需要打散。打散方法:GNU C中,bucket增加到比原来size2倍大的附近的质数,重新计算元素应该落在哪个bucket中。
19.2 GNU C中hashtable的实现
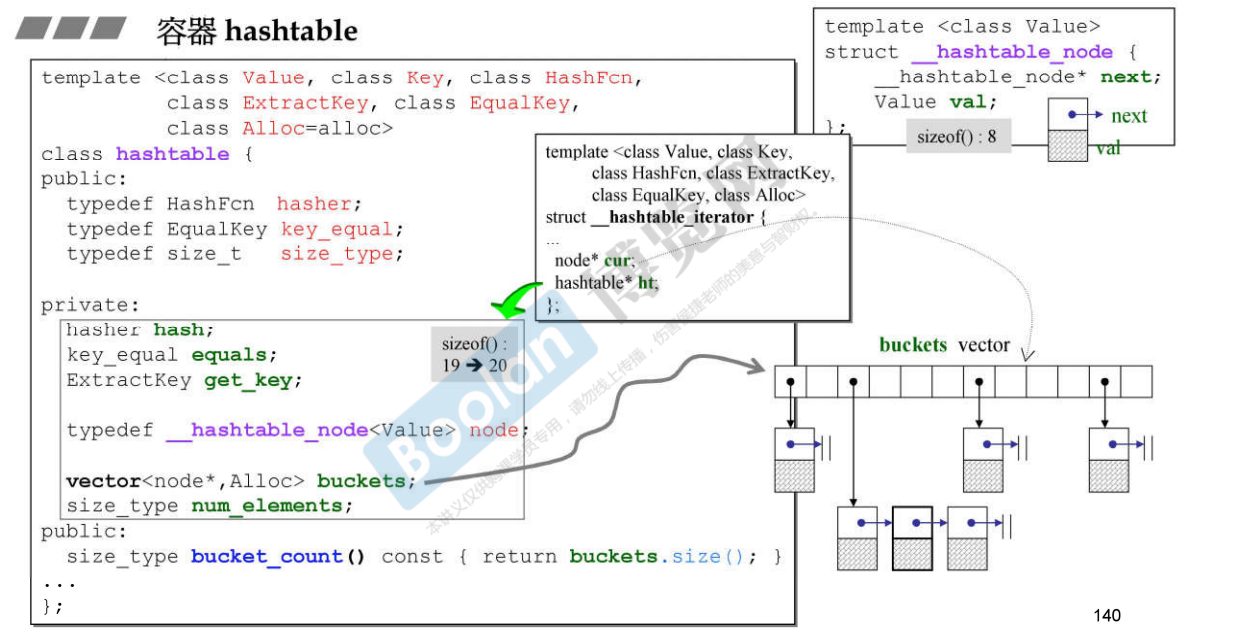
说明:模板参数:
- HashFcn : 每个元素通过什么方法得到编号,是个函数或者仿函数,计算出来的编号叫做hashCode;
- ExtracKey:提取出key;
- EqlKey:Key比较大小的方式;
- 数据成员:
- 三个函数对象:hash、equals、get_key ,理论值大小都为0,但是因为实际的某些因素,只能为1,所以一共是3bytes;
- vector类型的buckets,vector中有3个指针,所以本身是12 bytes;
- num_elements:元素个数,4bytes
- 所以一共:4 + 12 + 3 = 19bytes,内存对齐,调整为4的倍数,所以为20bytes;
- GNU C中的串联元素的链表是单向链表;
- 迭代器必须有能力在走到链表的尽头的时候回到buckets中,找到下一个bucket;
使用: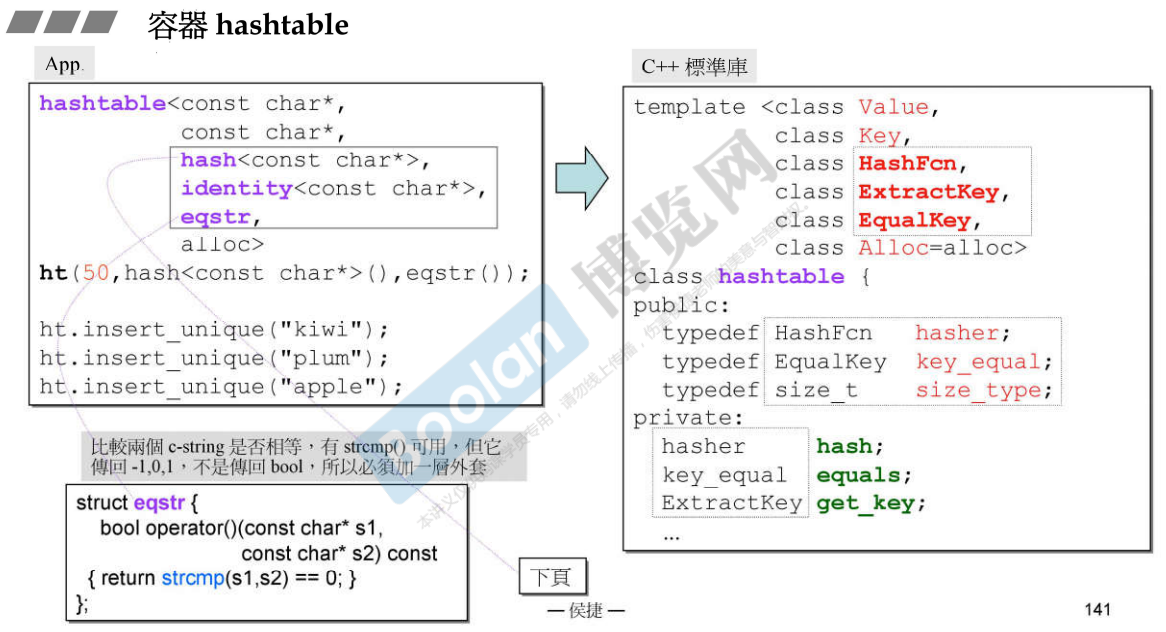
说明:
- eqstr规定字符串比较内容,而不是比较指针;
- 决定元素的编号的方法是hash-function;本例子中使用的是hash
,处理C风格的字符串,转成编号,这个就是指定如下的特化版本中的__STL_TEMPLATE_NULL struct hash 这个特化版本。
hash-function, hash-code
hash-function传出来的东西就叫做hash-code。
hash方法的泛化和特化版本: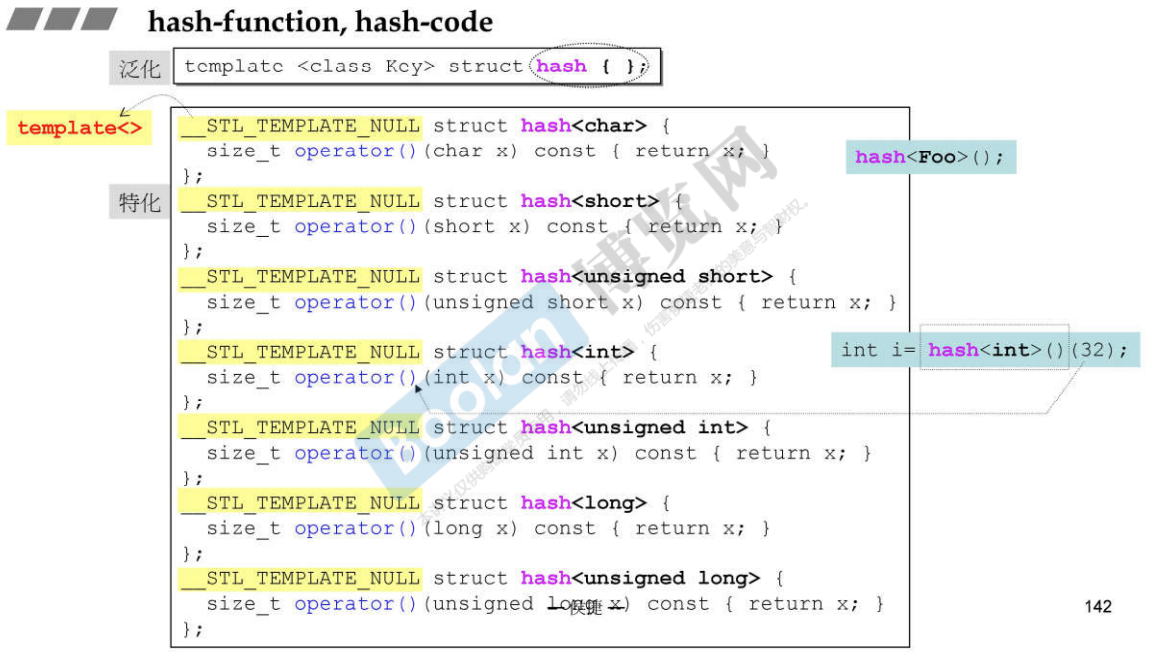

说明:
- 接收是数值时,hash-function就将数值当做编号;
- 接收是字符串时,调用__stl_hash_string函数生成对应的编号,C++标准库中针对字符串的情况已经设计好了hash-function;
- 如果放入的元素不是已经特化的版本,就要自己实现,标准库G2.9中没有提供现成的hash
modulus运算
说明:
- modulus运算就是模运算,计算得到余数。
- hashtable中的函数,计算元素要落在哪个bucket中,最后都是通过hash(key) % n 决定
G2.9 使用:
G4.9 使用:

19.3 unorder容器
- 到了C++11,以hash_xx开头的容器都更名为unordered_xx
使用:
说明:buckets size一定大于元素数量;
第三讲
20. 算法的形式
只有算法是function template 其他都是 class template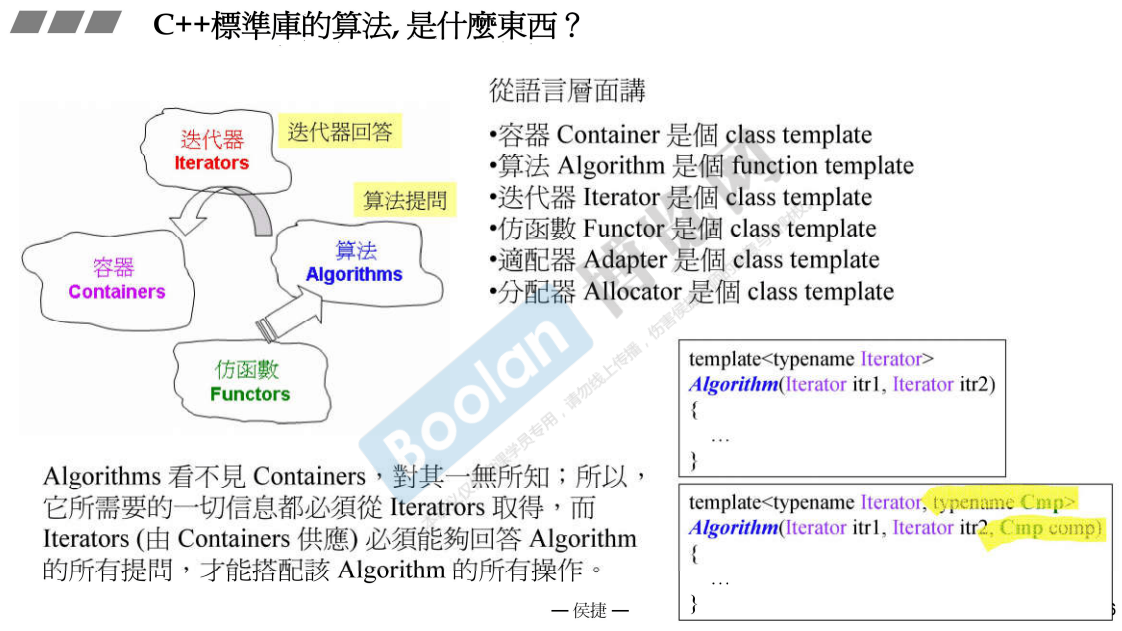
说明:
- 算法Algorithm 是个 function template,标准库中的算法都长成如下这样:
```cpp
template
Algorithm(Iterator itr1, Iterator itr2) { … }
template
2. 算法看不见容器,对其一无所知;所以,它所需要的一切信息都必须从Iterators取得,而Iterators(由Containers供应)必须能够回答Algorithm的所有提问,才能搭配该 Algorithm 的所有操作;如果算法提问,迭代器无法回答,那么编译到那一行就会报错;
<a name="rcAAS"></a>
### 21. 迭代器
<a name="GYQO1"></a>
#### 21.1 分类
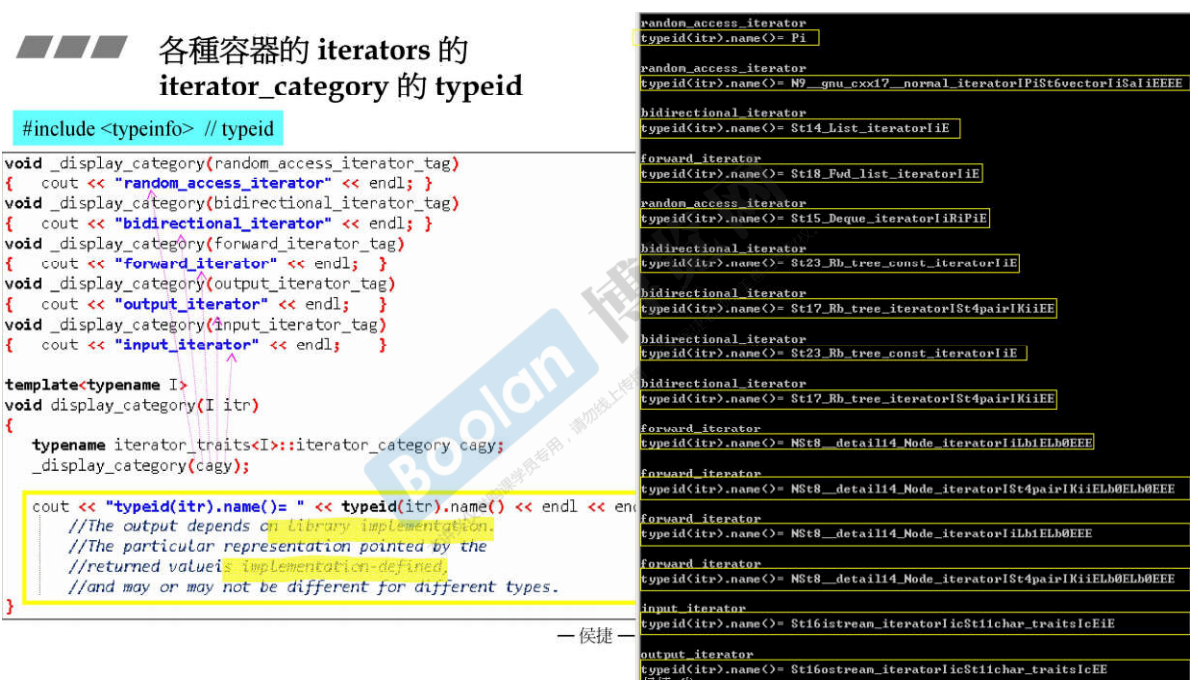
各种容器的iterators的iterator_category<br /><br />说明:
1. 迭代器是由容器提供的.
- Array和Vector都是连续空间,所以它们的迭代器应该是Random_Access;
- Deque是分段连续的,是假的连续,但是给使用者的感觉是真的连续,所以它的迭代器也应该是Random_Access;
- list是双向链表,空间不是连续的,所以它的迭代器是bidirection, 可以往前,也可以往后,但是不能跳跃;
- forward_list是单向链表,所以它的迭代器是forward_iterator;
- set/map/multiset/multimap底层结构都是红黑树,红黑节点之间是双向的,所以它们的迭代器都是bidirection这种类型;
- unordered系列的容器底层是Hashtable,每个bucket下是一个链表,所以要看这个链表是单向还是双向的,才能决定hashtable是forward 还是 bidirection类型;
2. 容器提供的迭代器的分类,是如下所示的这种对象。五种iterator category,都是类,且存在继承关系:
- input_iterator_tag
- forward_iterator_tag
- bidirectional_iterator_tag
- random_access_iterator_tag
- output_iterator_tag
**打印**<br /><br />说明:
1. 传入各种容器的迭代器给dispaly_category(I itr)函数,其中类似array<int,10>::iterator()的形式是个临时对象,没有名称.
1. iterator_traits<I>::iterator_category就是向iterator_traits提问迭代器的类型;
1. display_category(xx_iterator_tag)是重载函数,这里就说明了为什么分类不用整数,而是用对象来表示,因为category不论是什么,往上调用display_category函数自然而然编译器就会找到是哪个,如果是整数,就无法写得这么漂亮;
```cpp
template <typename I>
void display_category(I itr) {
typename iterator_traits<I>::iterator_category cagy;
display_category(cagy);
}
21.2 typeid
要包含
上面的程序是人为进行了些加工,指定了要打印的字符串,但是通过typeid可以直接打印出iterator_category.
#include<typeinfo>
cout << "typeid(itr).name() = " << typeid(itr).name() << endl << endl;
21.3 istream_iterator的iterator_category

说明:
- 接口必须相同,实现可以不同
G2.9版本的istream_iterator有两个模板参数,G3.3版本有4个模板参数,但是后面两个都有默认值;G4.9版本也是4个模板参数;各个版本都定义了自己的iterator_category为input_iterator_tag;
21.4 ostream_iterator的iterator_category

和istream_iterator类似,各个版本都是在定义自己的iterator_category为output_iterator_tag;
22. 迭代器分类对算法的影响
22.1 distance算法
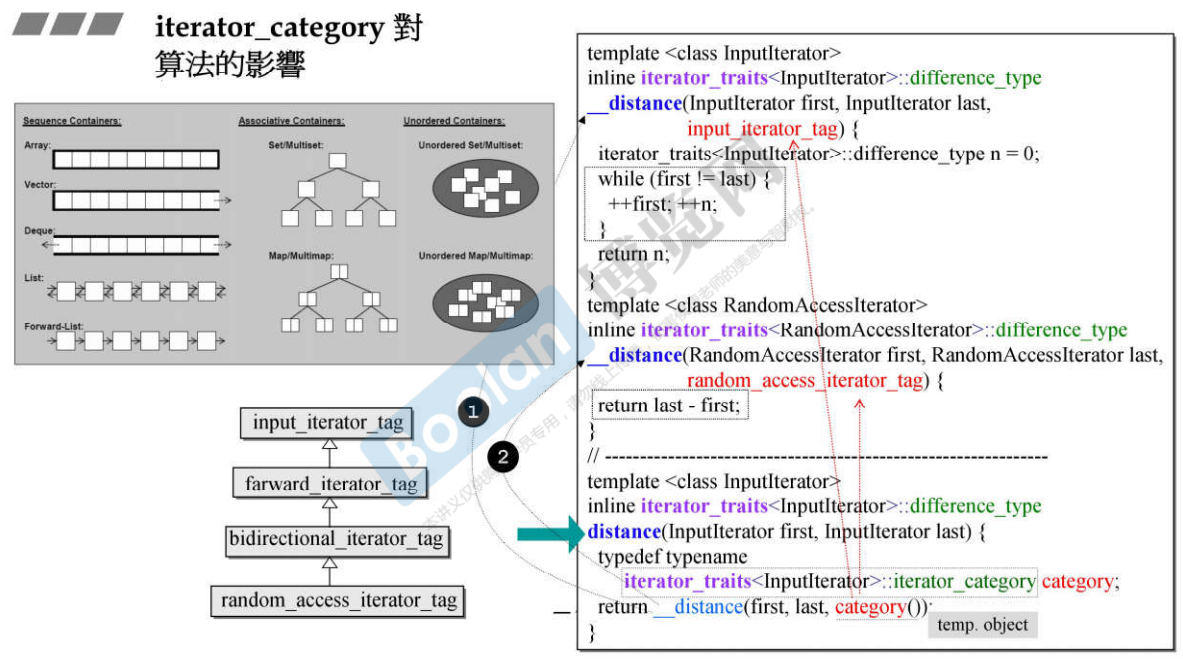
说明:
- distance算法是计算两个指针之间的距离:
- 如果是连续空间,可以直接相减,调用__distance(RandomAccessIterator first, RandomAccessIterator last, random_access_iterator_tag)函数;
- 如果不是连续空间,则将first一直往后走直到和last重合,这个往后走的步数,就是两个迭代器之间的距离,调用的是__distance(InputIterator first, InputIterator last, input_iterator_tag)函数;
- distance算法的返回值要通过询问iteartor_traits获得difference_type,传入的Iterator的category也要通过询问iterator_traits获得;category()是个临时对象,记住这种写法typename()是创建临时对象;
- 如果两个迭代器之间有100万个元素,那么这两个__distance函数的效率截然不同;
22.2 advance算法
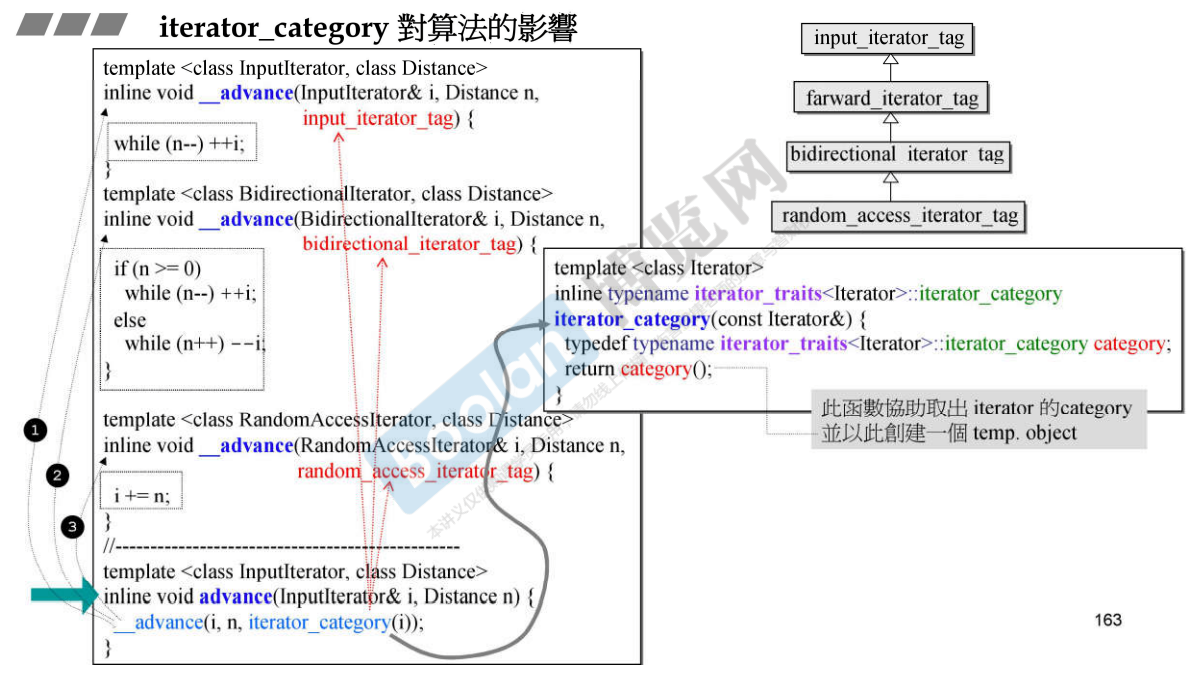
说明:
- advance算法,根据iterator_category的不同调用不同的__advance函数;
- iterator_category(const Iterator&)函数就是将传入的迭代器参数丢给iterator_traits,询问其对应的iterator_category是什么,即如图中的解释:协助取出iterator的category并以此创建一个临时对象;
- 迭代器的分类之所以没有使用整数来表示,而是使用对象,是因为这些分类之间有继承关系,如果问出来的分类是forward_iterator_tag,代码中并没有专门为其设计的版本,因为forward_iterator_tag是input_iterator_tag的子类,那么就会进入input_iteartor_tag的版本;
22.3 copy算法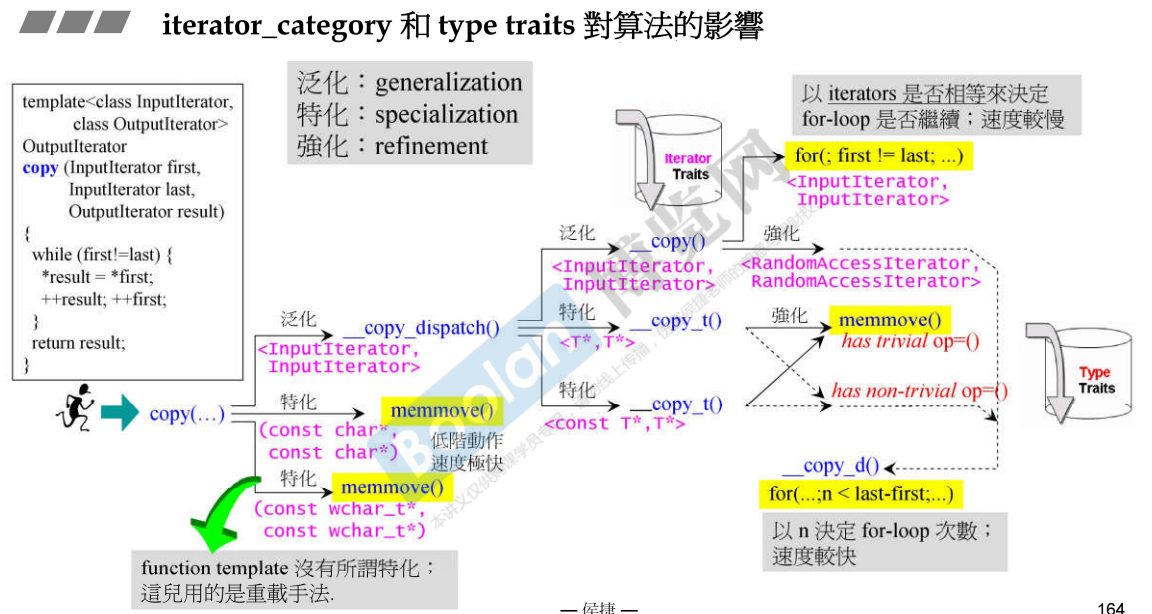
说明:
- copy算法就是复制,需要知道来源端的起点、终点以及目的端的起点;
- copy中不断地在检查它所接收到的迭代器是不是特属于某种类型而决定是否要做特别的动作来加快速度;
- 如果迭代器first和last是const char*类型,则调用memmove(),直接传到目的端;
- 如果迭代器是const wchar_t*类型,也是直接做memmove();
- 如果迭代器是InputIterator类型,则调用copy_dispatch();在copy_dispatch()函数中又去检查迭代器的类型:
- 如果是指针类型,则调用copy_t()函数,判断是否有重要的拷贝构造函数,如果有不重要的拷贝构造函数,就调用memmove()函数;如果有重要的拷贝构造函数,就调用copy_d()函数,用尾减头确定要拷贝的元素个数,减少了循环次数,速度较快;
- 如果是
类型,调用__copy()函数,并在该函数中继续判断迭代器的类型: - 如果是InputIterator类型,则从头开始一个个拷贝,直到拷贝到尾,速度很慢;
- 如果是RandomAccessIterator类型,则调用__copy_d()函数,用尾减头确定要拷贝的元素个数,减少了循环次数,速度较快;
22.3 destroy算法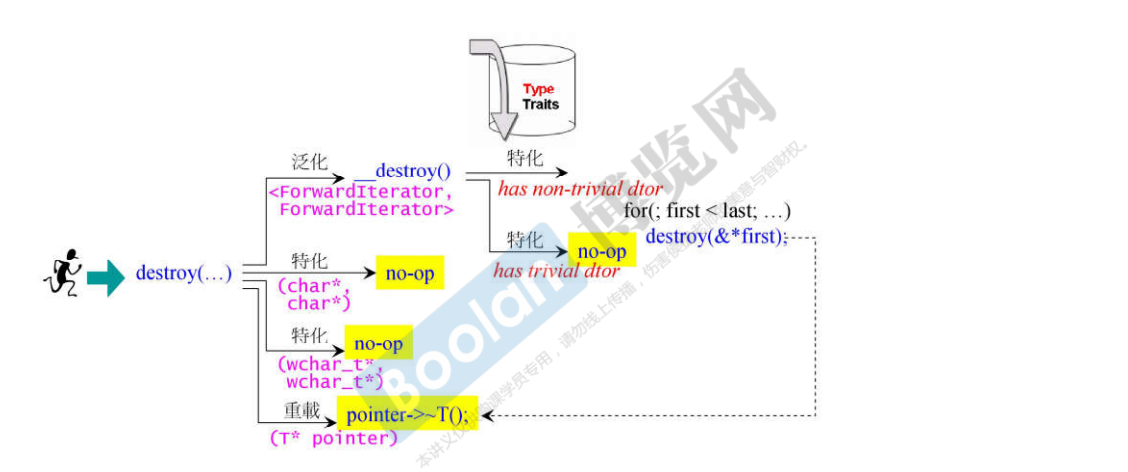
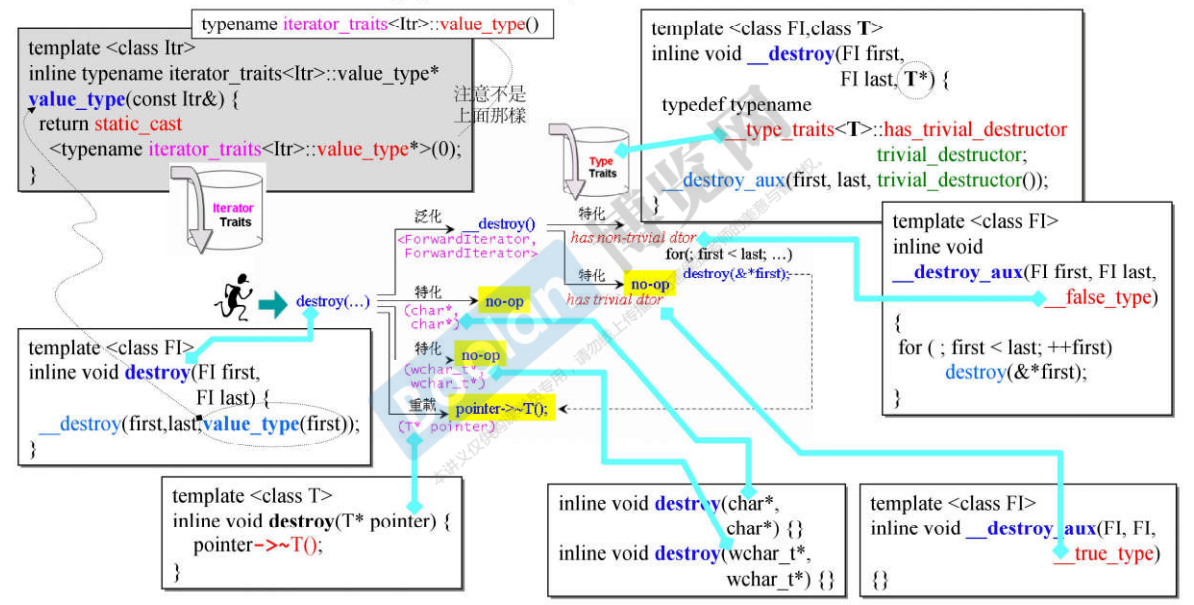
说明:
- 和前面讲解的算法一样,根据传入的迭代器的类型做不同的操作,以使得速度变快;
- 如果要销毁的元素的析构函数不重要,则什么都不做;否则,调用析构函数;
22.4 unique_copy算法
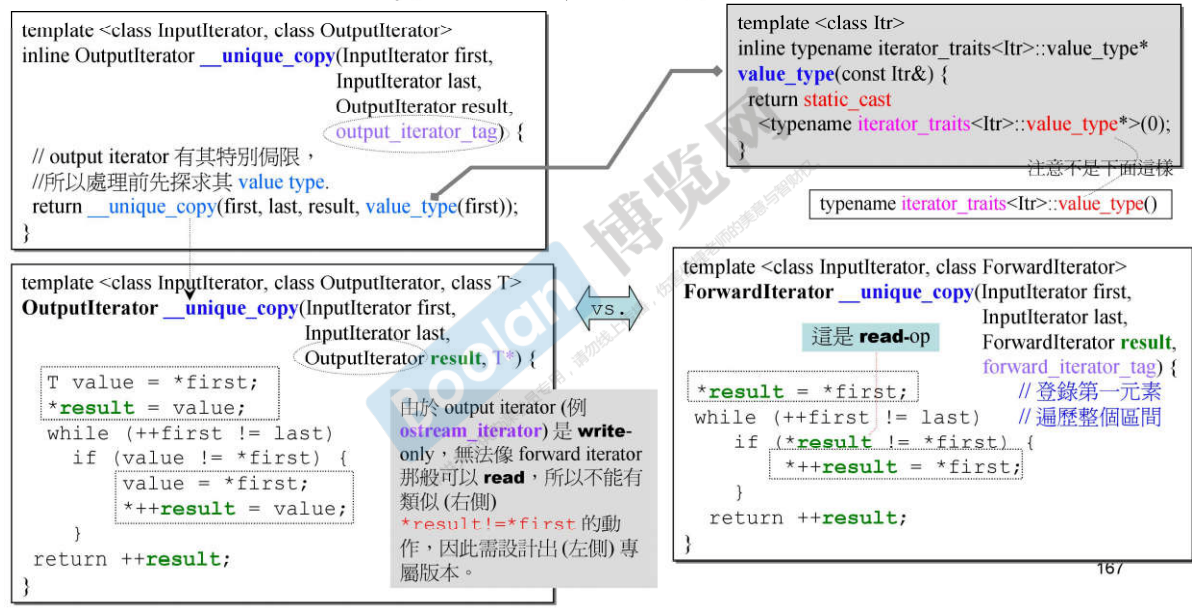
由于output_iterator是write-only的,无法read,所以不能有result!=first。22.5 算法源码中对iterator_category的”暗示”
算法是模板函数,即可以接受各种类型。typename可以看出来暗示。 说明:
说明:
- sort算法的typename命名为RandomAccessIterator就是暗示接受的迭代器为RandomAccessIterator,此处的这个typename可以命名为其他的,之所以命名为当前这个,就是一种”暗示“;
- distance算法暗示接受的迭代器是InputIterator都可以;
- find算法暗示接受InputIterator;
- rotate算法暗示接受ForwardIterator;
- reverse_copy算法暗示接受BidirectionalIterator;
23. 算法源码剖析
算法要满足模板函数的类型才是C++标准库提供的算法。qsort和bsearch算法是C中的函数,不是标准库中提供的算法。而count_if、find和sort算法是C++标准库中提供的算法。23.1 accumulate算法

说明:
accumulate算法的功能是累计,图上有两个版本:
for_each算法对first到last范围的每个元素做f操作,参数f可以是任何东西,只要能被()调用起来;
C++11开始新的for循环形式:
for (decl : coll) { statement }23.3 算法replace,replace_if,replace_copy

说明:replace函数的参数:头、尾、旧值、新值;条件是元素值和旧值相同;
- replace_if函数表示需要给定一个条件,参数:头、尾、条件、新值;符合pred(*first)作为条件;
replace_copy函数功能是将旧区间的等于旧值的都以新值的形式放到新区间中;
23.4 算法count,count_if

说明:左边是标准库的算法,全局的,泛化的;右边是说明容器中是否有该同名的成员函数;
- 容器不带成员函数count():
- array
- vector
- list
- forward_list
- deque
- 容器带有成员函数count(): 使用的时候就要使用容器中的count,针对这种类型的容器做了特别的处理

- set/multiset
- map/multimap
- unordered_set/unordered_multiset
- unordered_map/unordered_multimap
这8个,是associated container,可以用key找到data,小型的数据库,有严谨的结构,内部使用红黑树或哈希表实现,有自己比较快的计数方式;
23.5 find find_if
说明:
- find查找,循序查找;
- find_if查找符合条件的元素;
- set/multiset、map/multimap、unordered_set/unordered_multiset和unordered_map/unordered_multimap因为有自己严谨的结构,所以使用这些结构,不需要调用全局的find;
23.6 sort算法
说明:
- set/multiset、map/multimap、unordered_set/unordered_multiset和unordered_map/unordered_multimap不带sort,因为遍历自然就形成了sorted状态;
- 默认的排序方法也是从小到大排序;
list和forward_list中带有成员函数sort(),因为全局的sort要求是RandomAccessIterator,可以跳跃,但是list和forward_list容器都不能跳跃;
23.5 关于reverse iterator,rbegin(),rend()
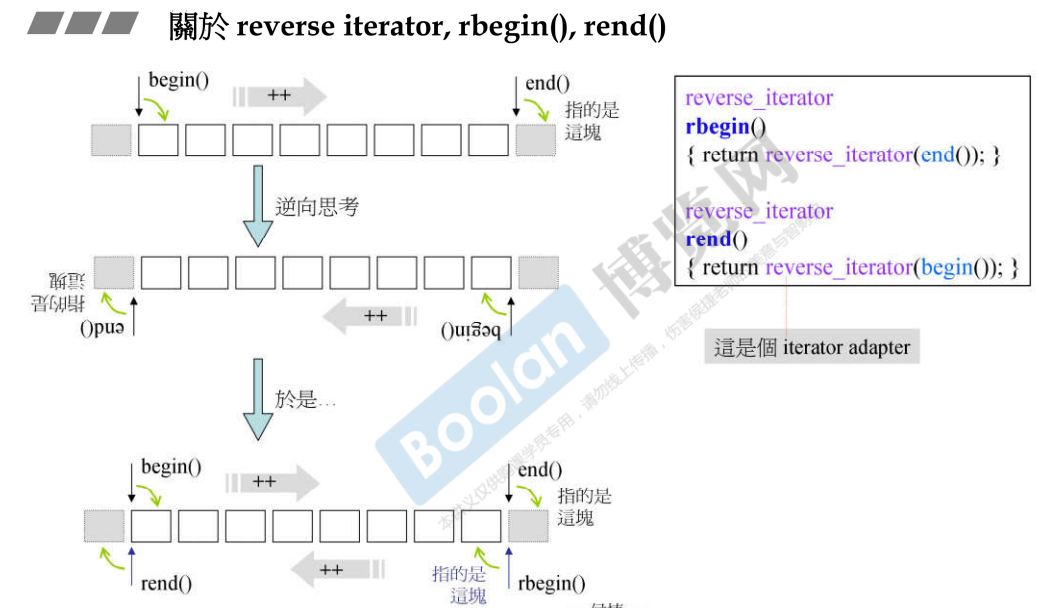
说明:图中的绿色小箭头表示如果对迭代器取值得到的元素;
rbegin()对应的就是end()的指针,rend()对应的就是begin()的指针,但是需要改变它们的行为,所以加了一个iterator adapter——reverse_iterator,使得取值的时候和原来的指针取值方式变得不同;
23.6 算法binary_search
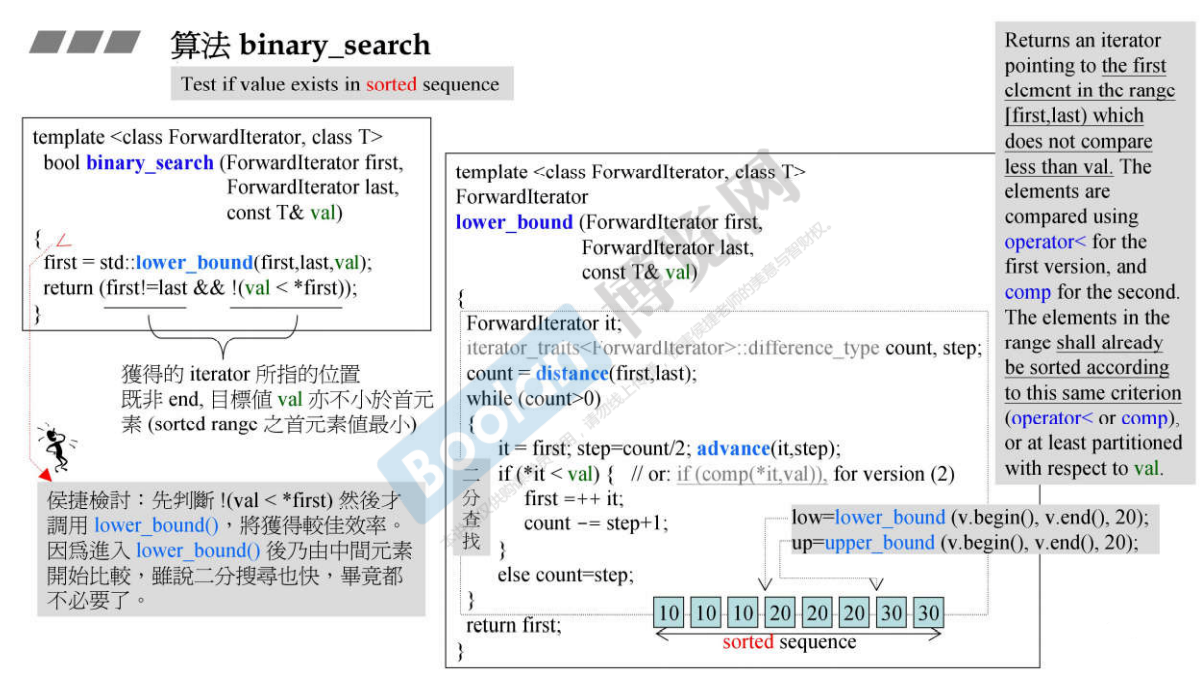
说明:binary_search算法一定是在排序的序列中使用;
- binary_search就是通过调用lower_bound函数来完成查找;
- lower_bound找到的是在不违反排序的情况下,找到的能安插要查找的数的最低点,upper_bound是最高点,即返回的是能安插的位置;
24. 仿函数和函数对象
24.1 仿函数functors

说明:
- 仿函数只为算法服务;
- 仿函数就是要模仿函数,必须重载(),图中是标准库提供的三大分类的functor;
- 之所以要将这些操作设计成函数,是为了将这些动操作传到算法中,所以要写成函数或仿函数;
- 每个标准库提供的仿函数都继承了binary_function;

说明:
- identity/select1st/select2nd 是GNU C++独有的,C++标准库的规格里并没有规定必须有这些;
- G4.9中这三个仿函数的名称变了,变成了_Identity/_Select1st/_Select2nd

说明:
// using explicitly default comparison (operator <):
sort(myvec.begin(), myvec.end(), less<int>());
sort(myvec.begin(), myvec.end(), greater<int>());
- 和sort(myvec.begin(), myvec.end());是一样的,从小到大排序,只是将默认的比较方法写出来了,less
是类型,less ()产生了一个临时对象;使用greater ()就变成了逆向排序,从大到小进行排序; 此处自己编写的仿函数struct myclass没有继承binary_function,就没有融入STL中,那么未来就没有被改造的机会;如果希望自己写的functor能够和STL的体系结构如何的话,就必须选择”适当者“(unary_function或binary_function)继承
24.2 仿函数functors的可适配(adaptable)条件

说明:binary_function就是两个操作数的操作(+,-,…),unary_function就是一个操作数;
- binary_function和unary_function的相同点是接受模板参数并将参数换了个名称,没有data,没有function,所以它们的大小都是0(理论值,实际上可能是1),如果作为父类,那它的大小一定是0;
- STL规定每个Adaptable Function都应挑选适当者继承之(因为Function Adapter将会提问)。所谓的”可适配(adaptable)”的意思就是可以被修改、适配或调整。如果你希望你写的functor是适配的,那么就要挑选一个”适当者“继承,因为当你被Adapter改造的时候,Adapter可能会来问这些问题,类似算法问迭代器问题。例如less是两个操作的数的操作,所以它要继承binary_function,这里只是继承了typedef,并没有增加额外的开销(没有数据和方法)。
- 仿函数如果要可适配的条件是能Adapter回答问题,为了能回答Adapter的问题就必须继承”适当者“;
- 小结:仿函数就是一个类中重载了(),这样的类创建出来的对象就叫做函数对象或者仿函数,之所以叫做函数对象,是因为创建出来的对象是一个对象,但是它像一个函数;
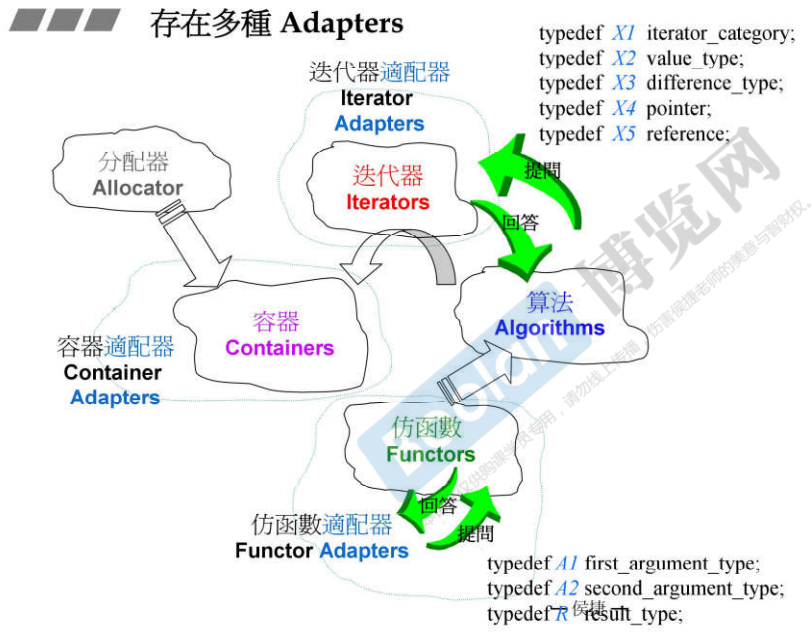
24.3 存在多种Adapter
说明:
- 根据Adapter需要修饰或改造的东西的名称则将其命名为什么:
- Function Adapters:改造Functor;
- Iterator Adapters: 改造Iterator;
- Container Adapters: 改造Container;
- 所有的Adapter都是用复合而非继承的方式来使用所要改造的东西的功能;
- 回顾:算法不知道容器,能够看到的只有迭代器,而迭代器是由容器提供,所以算法想要知道的一切问题都要通过5种typedef来询问迭代器,所以迭代器必须有这5种type;
- Adapter是仿函数和算法之间的桥梁,Function Adapter可能想要知道Functors的一些特性,也是通过问和答来实现的,通过3或2个typedef来询问;
25. 容器Adapter

stack和queue都内含了一个Sequence,默认是个deque,隐藏了某些deque的操作,这是一种改造,修改了函数名称也是一种改造:
- stack:push_back -> push; pop_back->pop;
- queue: push_back -> push; pop_front->pop;
26. 函数Adapter
26.1 binder2nd

说明:
binder2nd类中的typename Operation::second_argument_type value;就是在提问:binder2nd这个Adapter在修饰改造一个动作Operation(如之前的less),询问Operation的second_argument_type是什么,就是Adapter向Functor提问,Functor要回答;
count_if(vi.begin(), vi.end(), not1(bind2nd(less<int>(), 40))); //bind2nd是将第二个参数绑定为特定值,此处是40 //less<int>():less<int>是类型,加上()产生了临时对象,并不是调用 要准确区分()是创建对象还是函数调用bind2nd实际上调用了binder2nd;
binder2nd的op会记录less
调用流程就是:count_if->bind2nd->binder2nd->operator();
- 辅助函数bind2nd的作用是根据实参推导出Opeartion的类型;
binder2nd
- 函数对象(图中是less
())必须能够回答second_argument_type、first_argument_type和result_type才能和binder2nd这个Adapter完美搭配使用,如果能回答则说这个functor是可适配(adaptable)的,可适配的条件就是要继承binary_function;如果binder2nd这个functor要可适配的话,就要继承unary_function,而它的操作数就是bind2nd这个结果; typename的作用是帮助编译器通过编译,在编译的时候,还没有被使用,所以Operation是什么不知道,因此也不知道Operation::second_argument_type是什么,它到底是什么东西,将来是否会出错,都是编译器会考虑的,所以编译器会犹豫不决,正常来讲编译到这里的时候不应该通过编译,而加了typename就是坚定编译器的决心,这是个问答形式,告诉编译器Operation::second_argument_type就是个typename,让它编译通过吧;这种很长的提问前面一般都会加typename;
26.2 not1

说明:not1(bind2nd(less
(), 40))就是不小于40的数; bind2nd(less
(), 40)会作为实参传入not1函数中,函数模板会进行实参推导,推导出Predicate是什么类型,推导出来之后创建临时对象,即调用unary_negate类的构造函数; 26.3 bind
右侧的已经过时了,现在使用左侧的替代


bind是从C++11开始提供的适配器,可以绑定:
- 函数
- 函数对象
- 成员函数:_1必须是某个object地址,其中的_1是占位符(placeholder)
- 数据成员:_1必须是某个object地址 ```cpp //binding functions: auto fn_five = bind(my_divide, 10, 2); //绑定my_divide函数,绑定它的两个参数为10和2
auto fn_half = bind(my_divide, _1, 2); //绑定my_divide函数第二参数为2,第一参数留着 cout << fn_half(10) << ‘\n’; //因为只绑定了一个参数,所以调用的时候还需要传入一个参数,传入的参数落在_1位置上
auto fn_invert = bind(my_divide, _2, _1); //绑定my_divide函数,两个参数都空置 cout << fn_invert(10, 2) << ‘\n’; //10是第一实参,会落在_1的位置上;2是第二实参,会落在_2这个位置上;
auto fn_rounding = bind
(my_divide, _1, _2); //指定了模板参数,就改变return type为int cout << fn_rounding(10,3) << ‘\n’; ```cpp //binding members: MyPair ten_two{10,2}; //设定对象并给定初值 //成员函数其实有个参数:this auto bound_memfn = bind(&MyPair::multiply, _1); //绑定MyPair的成员函数multiply,_1空闲,占位this参数 cout << bound_memfn(ten_two) << '\n'; //调用的时候指定 auto bound_memdata = bind(&MyPair::a, ten_two); //调用的时候绑定了this参数 cout << bound_memdata() << '\n'; //取得a auto bound_memdata2 = bind(&MyPair::b, _1); //调用的时候绑定了this参数 cout << bound_memdata2(ten_two) << '\n'; //取得bvector<int> v{15, 37, 94, 50, 73, 58, 28, 98}; //cbegin()表示返回的迭代器是不可以更改的,c是const的意思 int n = count_if(v.cbegin(), v.cend(), not1(bind2nd(less<int>(), 50))); //用bind替换bind2nd auto fn_ = bind(less<int>(), _1, 50); cout << count_if(v.cbegin(), v.cend(), fn_) << endl; cout << count_if(v.begin(), v.end(), bind(less<int>(), _1, 50)) << endl;27. 迭代器Adapter
27.1 迭代器适配器:reverse_iterator

说明:reverse_iterator的关键就是operator*,对逆向迭代器取值,就是对「对应的正向迭代器」退一位取值;
-
27.2 迭代器适配器:inserter
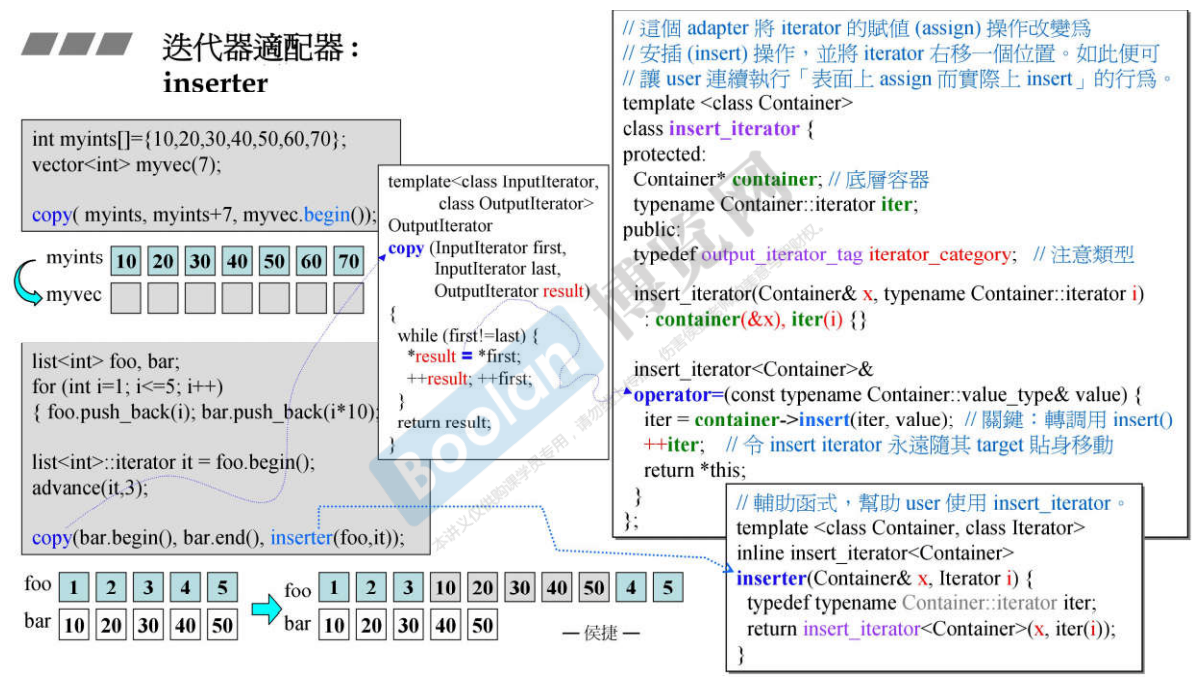
说明: copy操作是将源端的数据拷贝到目的端,first和last分别是源端的迭代器的头和尾,result是目的端的起始位置,所以将数据拷贝到目的端的时候,目的端的空间是否足够、是否合法,copy操作是不知道的,所以copy和一般的迭代器的搭配的时候拷贝动作是进行”赋值“,有隐患;
我们希望在要插入的位置自己准备空间,放一个元素则创建一个新的空间,而不是进行”赋值“;而copy中的实现是”赋值“,如何变成我们希望的创建新空间呢?可以使用inserter,将目的端的迭代器改成是插入的动作,insert_iterator中进行了operator=函数的重载,所以使得copy中调用的result = first操作变成了调用容器的insert操作,而容器的insert操作就会自己开辟一块空间存放数据;
27.3 X Adapter
之所以叫做X Adapter,因为不知道要归到哪一类中。
ostream_iterator
说明:std::ostream_iterator
out_it(std::cout, “,”); 是将迭代器的第一参数绑定到cout上,即放入的数据都显示到屏幕上;第二参数绑定为字符串,作为分隔符号使用; - ostream_iterator 中通过操作符重载operator=使其能够使用cout输出出来;
- ostream_iterator是ostream的适配器;
istream_iterator
说明:
- std::istream_iterator
eos;调用无参构造函数,std::istream_iterator iit(std::cin); 调用有参构造函数,istream_iterator将cin记录到in_stream中; - ++iit调用istream_iterator的operator++()函数,读入数据;
- iit调用istream_iterator的operator函数,返回读入的数据;

说明:
- iit在创建的时候就已经读入了值,所以*first的时候可以取出值了;while循环中一边读入数据,一边返回数据;
第四讲
28. 一个万用的Hash Function
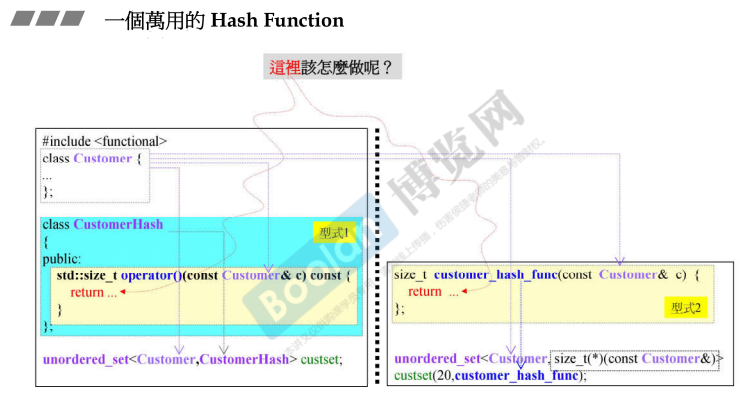
#include <functional>
class Customer {
...
};
//形式1
class CustomerHash {
public:
std::size_t operator()(const Customer& c) const {
return ...
}
};
//第二个模板参数传入的是类型
unordered_set<Customer, CustomerHash> custset;
//形式2
size_t customer_hash_func(const Customer& c) {
return ...
}
//第二个模板参数为函数类型
unordered_set<Customer, size_t(*)(const Customer&)> custset(20, customer_hash_func);
28.1 方案一
因为基本类型都具有自己的hash function,所以想着将Customer中的所有数据拆开为基本类型,然后对各种类型进行hash,最后结果合在一起:
class CustomerHash {
public:
std::size_t operator()(const Customer&) const {
return std::hash<std::string>()(c.fname) +
std::hash<std::string>()(c.lname) +
std::hash<long>()(c.no);
}
};
28.2 方案二
使用variadic templates(可变化的模板)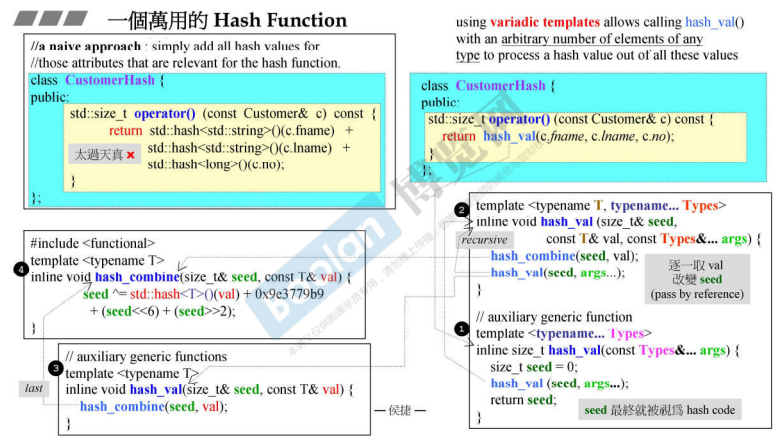 x09e3779b9 是黄金比例:
x09e3779b9 是黄金比例:
class CustomerHash {
public:
std::size_t operator()(const Customer&) const {
return hash_val(c.fname, c.lname, c.no); //将Customer的数据都放入
}
};
template <typename... Types> //接受任意个数的模板参数,语法"typename..."
inline size_t hash_val(const Types&... args) {
size_t seed = 0;
hash_val(seed, args...);
return seed;
}
template <typename T, typename... Types> //可以接受任意个数的模板参数
inline void hash_val(size_t& seed, const T& val, const Types&... args) {
hash_combine(seed, val);
hash_val(seed, args...); //递归调用本身,拆分参数,每次都取一个参数进行hash_combine,直到取到只有一个元素调用hash_val(size_t&, const T&)函数
}
//上面两个函数的区别是第一个实参的类型
#include <functional>
template <typename T>
inline void hash_combine(size_t& seed, const T& val) {
//最终获得的seed就是Customer的hash-code
seed ^= std::hash<T>()(val) + x09e3779b9 + (seed << 6) + (seed >> 2);
}
template <typename T>
inline void hash_val(size_t& seed, const T& val) {
hash_combine(seed,val);
}


28.3 方案三
以 struct hash 偏特化形式实现 Hash Function
针对自定义的类型实现偏特化的Hash function:如下是对MyString类型进行特化的版本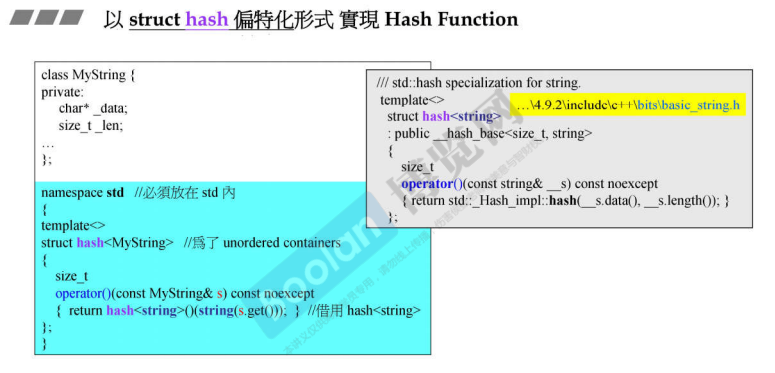
G4.9中所有的基本类型都有自己的hash function,G2.9中没有对string类型进行特化。
29. Tuple用例
tuple:一堆东西的组合,可以指定任意类型的任意个元素为一个整体结构。
//create tuple with make_tuple()
auto t2 = make_tuple(22, 44, "stacy"); //编译器会进行实参推导出类型
//assign second value in t2 to t1
get<1>(t1) = get<1>(t2);
如下是参数数量可变的模板应用到tuple,variadic templates语法自动把n个参数分解为1和n-1,再把n-1分解为1和n-2,…,不断递归直到没有参数,所以variadic templates一定是有一个主体,有一个终止条件。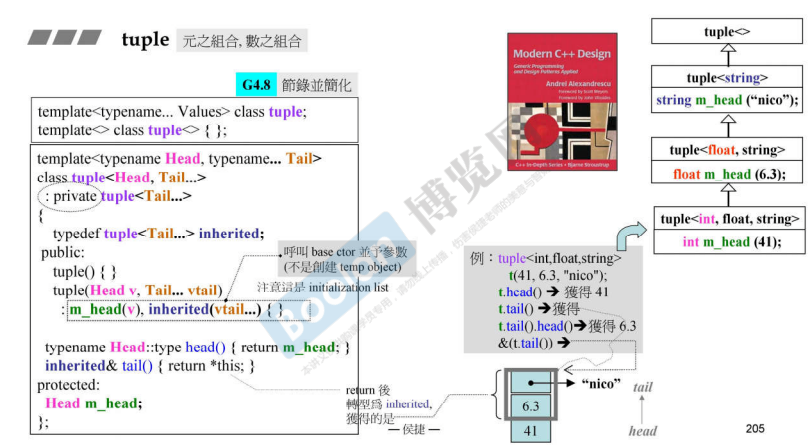
tuple继承了自己(每次成分减少一个),variadic template会自动将其处理为继承的关系,如上图右边所示。当参数为0个的时候,使用特化的版本template<> class tuple<>{};。子类的大小 = 子类本身的数据 + 父类的数据.
30. type traits
30.1 初探
- G2.9版本的type traits

struct __true_type {};
struct __false_type {};
//泛化版本
template <class type>
struct __type_traits {
typedef __true_type this_dummy_member_must_be_first;
typedef __false_type has_trivial_default_constructor; //默认构造函数是否重要,默认情况下是重要的
typedef __false_type has_trivial_copy_constructor; //拷贝构造函数是否重要,默认情况下是重要的
typedef __false_type has_trivial_assignment_operator; //赋值操作是否重要,默认情况下是重要的
typedef __false_type has_trivial_destructor; //析构函数是否重要,默认情况下是重要的
typedef __false_type is_POD_type; //Plain Old Data,C中的structure,没有function,只有data
};
//特化版本
//如果明确知道上面提问的那些函数不重要,那么就可以为这个泛化版本写特化版本,来说明答案不是默认的答案,而是有自己的答案
//对于整数这种type,所提问的那些函数都不重要
template<> struct __type_traits<int> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type; //Plain Old Data
};
//特化版本
template<> struct __type_traits<double> {
typedef __true_type has_trivial_default_constructor;
typedef __true_type has_trivial_copy_constructor;
typedef __true_type has_trivial_assignment_operator;
typedef __true_type has_trivial_destructor;
typedef __true_type is_POD_type; //Plain Old Data
};
//自定义的类型,可以照着这种写法自己实现自定义类型的特化版本,自己判断那些函数是否重要,自己回答
//比如“复数类”,没有指针,只有实部和虚部,可以不用写构造函数和析构函数,因为编译器有默认版本,所以那些函数都是不重要的。
__type_traits<Foo>::has_trivial_destructor //算法要通过__type_traits询问Foo:你有不重要的析构函数吗
- C++11版本的type traits
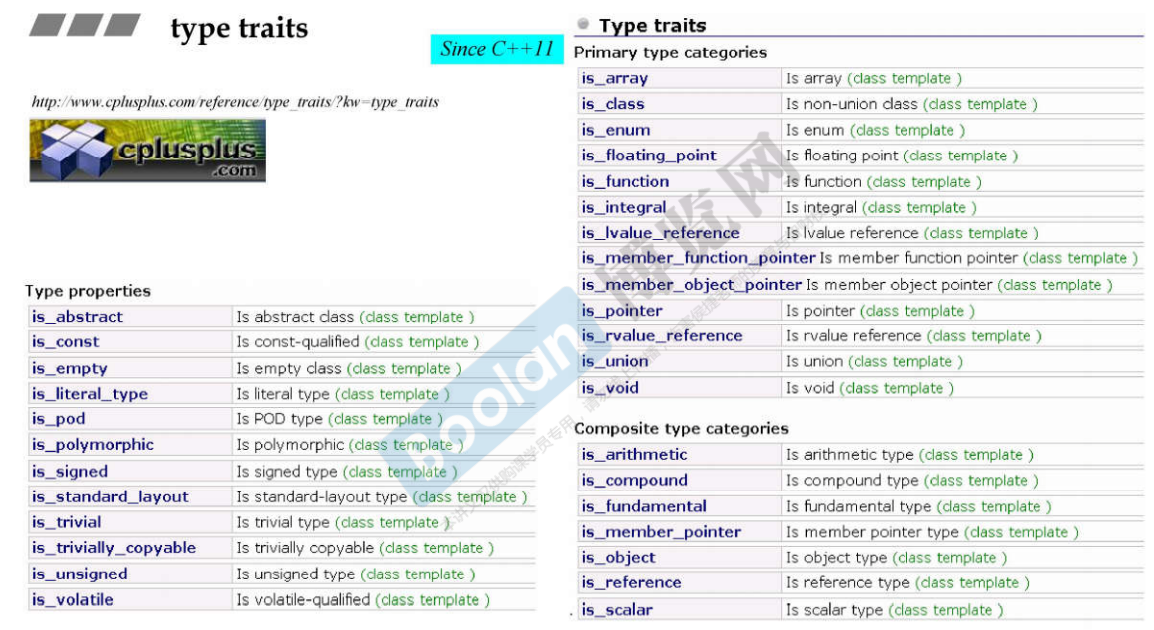

新版本不需要对自己的自定义类型实现特化版本,而且可以询问的东西更多了。
30.2 测试

class Foo {
private:
int d1, d2;
};
type_traits_output(Foo());
Foo 中没有 function,只有data,所以它是pod type;
class Goo { public: virtual ~Goo { } private: int d1, d2; }; type_traits_output(Goo());说明:
Goo中有虚析构函数,所以has_virtual_destructor结果是true;
is_polymorphic是否为多态,“多态”类是声明或继承了virtual 方法,Goo中声明了 virtual function,所以它是多态的;
class Zoo { public: Zoo(int i1, int i2): d1(i1), d2(i2) { } //构造函数 Zoo(const Zoo&) = delete; //拷贝构造 Zoo(Zoo&&) = default; //move constructor Zoo& operator=(const Zoo&) = default; //拷贝赋值 Zoo& operator=(const Zoo&&) = delete; //move assignment virtual ~Zoo() { } private: int d1, d2; }; type_traits_output(Zoo(1, 2));说明:
因为自己编写了构造函数,所以没有默认构造函数;
- 拷贝构造函数被delete了,所以没有拷贝构造函数;
说明:
- is_void

说明:
- 都是使用“模板”对类型做操作;
- remove_cv是先将关键字const和volatile拿掉;
- struct remove_const<_Tp const> 是偏特化,范围的偏特化;
- is_void模板类先利用remove_cv将const和volatile去除,然后进入__is_void_helper,如果是 void,则返回真,否则返回假;
- is_integral

说明:
- is_integral判断是否为整数类型;
- is_integral会先将const和volatile关键字拿掉,然后进入__is_integral_helper中,根据类型不同进入不同的偏特化版本;
- is_class,is_union,is_enum, is_pod

说明:
- 蓝色的这些没有在C++标准库的源代码中,可能是编译器编译的时候整理出来的结果;
- is_move_assignable

说明:
- 和上面一样,is_reference已经不在C++标准库源代码中;
- type traits就是一个类型萃取机;
30. cout

说明:
- cout是个对象,extern表明外界可以使用它;
- 通过cout输出对象,因为它对不同类型产生的对象进行了重载operator<<,如果没有出现在重载的类型中,就需要自己重载operator<<
- 标准库中对<<的操作符重载:

31. moveable元素对容器速度效能的影响
31.1 vector

说明:
- 上面的是moveable 元素的测试,300万个元素放入vector中,调用了0次copy constructor,但是调用了7194303次move constructor。花费的时间是8547ms;
- 下面的是non-moveable元素的测试,同样300万个元素,放入vector中,调用了7194303次copy constructor,调用了0次move constructor,花费的时间是14235ms;
- M c11(c1);是拷贝构造;M c12(std::move(c1));是move copy;
不同类型的容器调用相同的一份代码测试插入300万个元素:
for (long i = 0; i < value; ++i) { snprintf(buf, 10, "%d", rand()); auto ite = c1.end(); c1.insert(ite, V1type(buf)); }vector的特性是当空间不够用的时候,就要2倍增长空间,并且将原来的数据拷贝到新的空间,这个过程会调用拷贝构造或拷贝赋值,因此,多出了很多的构造函数的调用;
31.2 list
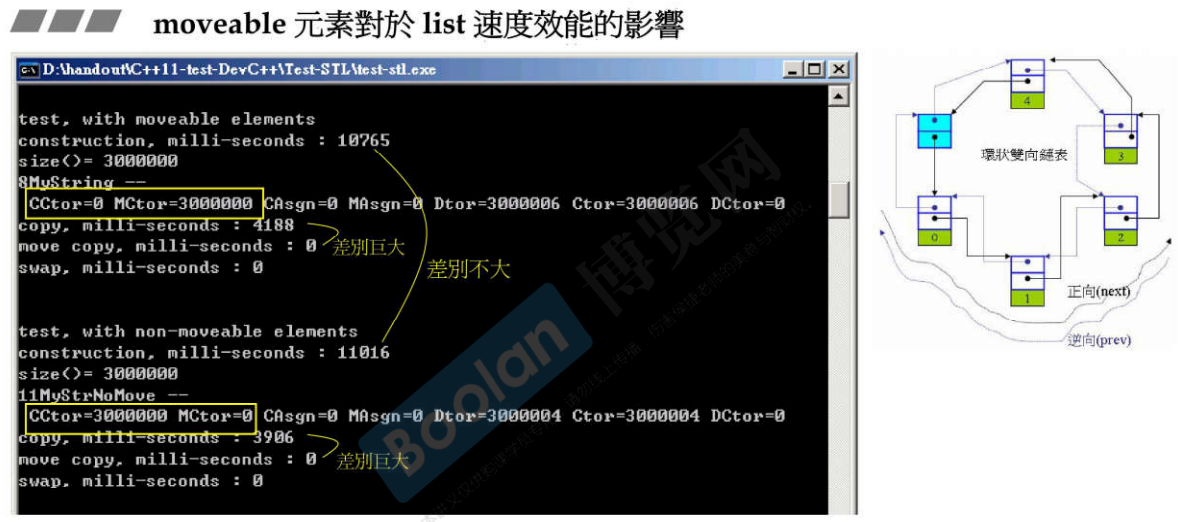
说明:不同于vector,list没有扩充或增长的行为,放300万个元素就调用300万次构造函数;
- 后面的容器也是相同的行为模式
31.3 deque
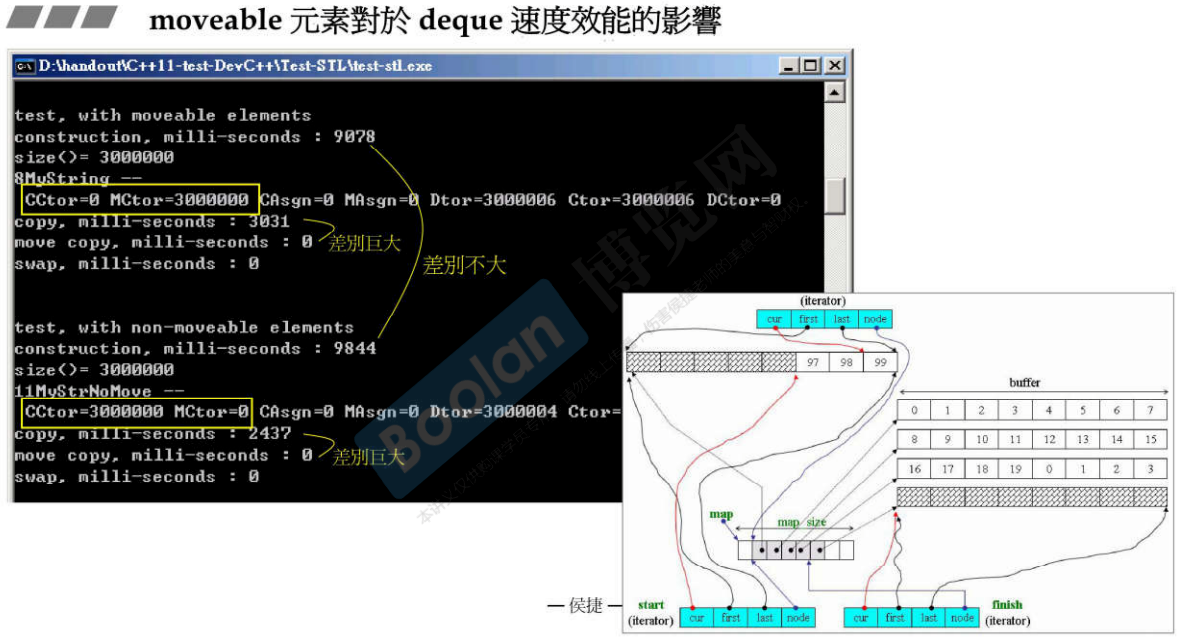
31.4 multiset
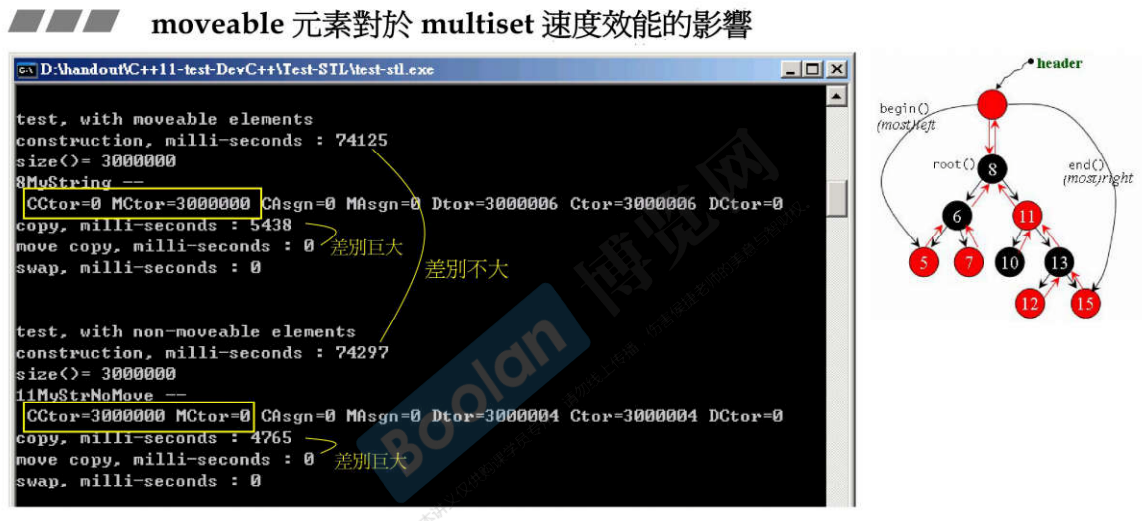
31.5 unordered_multiset
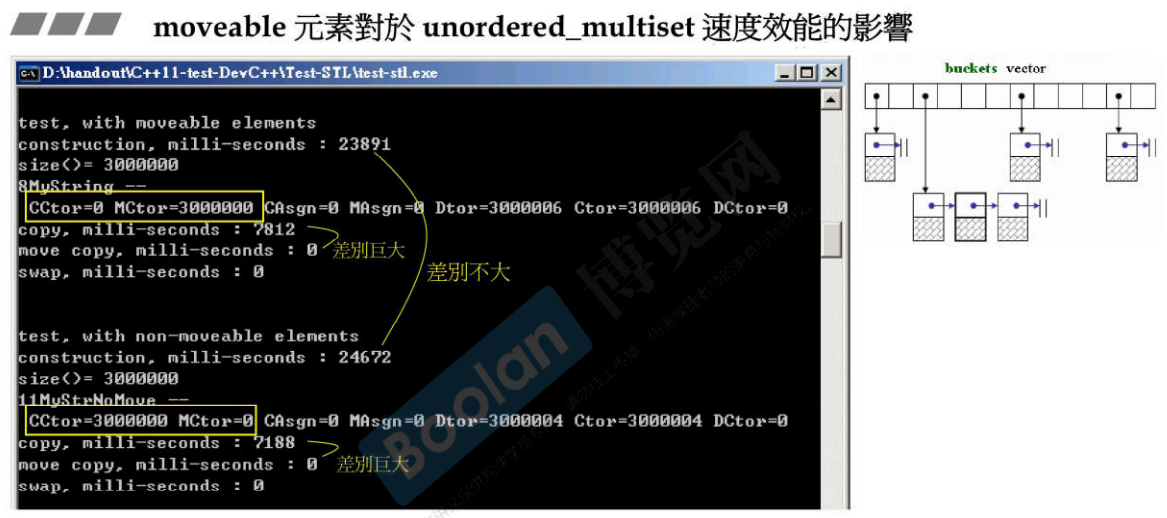
31.6 写一个moveable class

 ```cpp
```cppinclude
include
//snprintf() include
//RAND_MAX include
//strlen(), memcpy() include
using std::cin; using std::cout; using std::string;
//以下 MyString 是為了測試 containers with moveable elements 效果.
class MyString {
public:
static size_t DCtor; //累計 default-ctor 的呼叫次數
static size_t Ctor; //累計 ctor 的呼叫次數
static size_t CCtor; //累計 copy-ctor 的呼叫次數
static size_t CAsgn; //累計 copy-asgn 的呼叫次數
static size_t MCtor; //累計 move-ctor 的呼叫次數
static size_t MAsgn; //累計 move-asgn 的呼叫次數
static size_t Dtor; //累計 dtor 的呼叫次數
private:
char _data;
size_t _len;
void _init_data(const char s) {
_data = new char[_len+1];
memcpy(_data, s, _len);
_data[_len] = ‘\0’;
}
public:
//default ctor
MyString() : _data(NULL), _len(0) { ++DCtor; }
//ctor
MyString(const char* p) : _len(strlen(p)) {
++Ctor;
_init_data(p);
}
// copy ctor
MyString(const MyString& str) : _len(str._len) {
++CCtor;
_init_data(str._data); //COPY
}
//move ctor, with "noexcept", 和copy ctor的区别在于参数有两个&,只是拷贝指针
MyString(MyString&& str) noexcept : _data(str._data), _len(str._len) {
++MCtor;
str._len = 0;
str._data = NULL; //避免 delete (in dtor)
}
//copy assignment
MyString& operator=(const MyString& str) {
++CAsgn;
if (this != &str) {
if (_data) delete _data;
_len = str._len;
_init_data(str._data); //COPY!
}
else {
// Self Assignment, Nothing to do.
}
return *this;
}
//move assignment
MyString& operator=(MyString&& str) noexcept {
++MAsgn;
if (this != &str) {
if (_data) delete _data;
_len = str._len;
_data = str._data; //MOVE!
str._len = 0;
str._data = NULL; //避免 deleted in dtor
}
return *this;
}
//dtor
virtual ~MyString() {
++Dtor;
if (_data) { //
delete _data;
}
}
bool
operator<(const MyString& rhs) const //為了讓 set 比較大小
{
return std::string(this->_data) < std::string(rhs._data); //借用事實:string 已能比較大小.
}
bool
operator==(const MyString& rhs) const //為了讓 set 判斷相等.
{
return std::string(this->_data) == std::string(rhs._data); //借用事實:string 已能判斷相等.
}
char* get() const { return _data; }
};
//在class之外给static数据定义
size_t MyString::DCtor=0;
size_t MyString::Ctor=0;
size_t MyString::CCtor=0;
size_t MyString::CAsgn=0;
size_t MyString::MCtor=0;
size_t MyString::MAsgn=0;
size_t MyString::Dtor=0;
namespace std //必須放在 std 內
{
template<>
struct hash
//借用現有的 hash

```cpp
class MyStrNoMove {
public:
static size_t DCtor; //累計 default-ctor 的呼叫次數
static size_t Ctor; //累計 ctor 的呼叫次數
static size_t CCtor; //累計 copy-ctor 的呼叫次數
static size_t CAsgn; //累計 copy-asgn 的呼叫次數
static size_t MCtor; //累計 move-ctor 的呼叫次數
static size_t MAsgn; //累計 move-asgn 的呼叫次數
static size_t Dtor; //累計 dtor 的呼叫次數
private:
char* _data;
size_t _len;
void _init_data(const char *s) {
_data = new char[_len+1];
memcpy(_data, s, _len);
_data[_len] = '\0';
}
public:
//default ctor
MyStrNoMove() : _data(NULL), _len(0) { ++DCtor; _init_data("jjhou"); }
//ctor
MyStrNoMove(const char* p) : _len(strlen(p)) {
++Ctor; _init_data(p);
}
// copy ctor
MyStrNoMove(const MyStrNoMove& str) : _len(str._len) {
++CCtor;
_init_data(str._data); //COPY
}
//copy assignment
MyStrNoMove& operator=(const MyStrNoMove& str) {
++CAsgn;
if (this != &str) {
if (_data) delete _data;
_len = str._len;
_init_data(str._data); //COPY!
}
else {
// Self Assignment, Nothing to do.
}
return *this;
}
//dtor
virtual ~MyStrNoMove() {
++Dtor;
if (_data) {
delete _data;
}
}
bool
operator<(const MyStrNoMove& rhs) const //為了讓 set 比較大小
{
return string(this->_data) < string(rhs._data); //借用事實:string 已能比較大小.
}
bool
operator==(const MyStrNoMove& rhs) const //為了讓 set 判斷相等.
{
return string(this->_data) == string(rhs._data); //借用事實:string 已能判斷相等.
}
char* get() const { return _data; }
};
size_t MyStrNoMove::DCtor=0;
size_t MyStrNoMove::Ctor=0;
size_t MyStrNoMove::CCtor=0;
size_t MyStrNoMove::CAsgn=0;
size_t MyStrNoMove::MCtor=0;
size_t MyStrNoMove::MAsgn=0;
size_t MyStrNoMove::Dtor=0;
namespace std //必須放在 std 內
{
template<>
struct hash<MyStrNoMove> //這是為了 unordered containers
{
size_t
operator()(const MyStrNoMove& s) const noexcept
{ return hash<string>()(string(s.get())); }
//借用現有的 hash<string> (in ...\4.9.2\include\c++\bits\basic_string.h)
};
}
#include <ctime> //clock_t, clock()
template<typename M, typename NM>
void test_moveable(M c1, NM c2, long& value)
{
char buf[10];
//測試 move
cout << "\n\ntest, with moveable elements" << endl;
typedef typename iterator_traits<typename M::iterator>::value_type V1type;
clock_t timeStart = clock();
for(long i=0; i< value; ++i)
{
snprintf(buf, 10, "%d", rand());
auto ite = c1.end();
c1.insert(ite, V1type(buf)); //所有容器都提供insert, V1type(buf)是个临时对象,右值,所以编译器会调用其move版本
}
cout << "construction, milli-seconds : " << (clock()-timeStart) << endl;
cout << "size()= " << c1.size() << endl;
output_static_data(*(c1.begin()));
timeStart = clock();
M c11(c1); //将整个容器拷贝到c11,深拷贝。 c1不是临时对象
cout << "copy, milli-seconds : " << (clock()-timeStart) << endl;
timeStart = clock();
M c12(std::move(c1)); //move copy,浅拷贝。
cout << "move copy, milli-seconds : " << (clock()-timeStart) << endl;
timeStart = clock();
c11.swap(c12); //交换
cout << "swap, milli-seconds : " << (clock()-timeStart) << endl;
//測試 non-moveable
cout << "\n\ntest, with non-moveable elements" << endl;
typedef typename iterator_traits<typename NM::iterator>::value_type V2type;
timeStart = clock();
for(long i=0; i< value; ++i)
{
snprintf(buf, 10, "%d", rand());
auto ite = c2.end();
c2.insert(ite, V2type(buf));
}
cout << "construction, milli-seconds : " << (clock()-timeStart) << endl;
cout << "size()= " << c2.size() << endl;
output_static_data(*(c2.begin()));
timeStart = clock();
NM c21(c2);
cout << "copy, milli-seconds : " << (clock()-timeStart) << endl;
timeStart = clock();
NM c22(std::move(c2));
cout << "move copy, milli-seconds : " << (clock()-timeStart) << endl;
timeStart = clock();
c21.swap(c22);
cout << "swap, milli-seconds : " << (clock()-timeStart) << endl;
}
move之后原来的东西不再使用,才可以选择使用move copy,否则可能会带来隐患:两个指针指向同一块内存
31.7 vector的copy ctor和move ctor

说明:
- M c11(c1)这是vector的深拷贝,即如上图的流程;
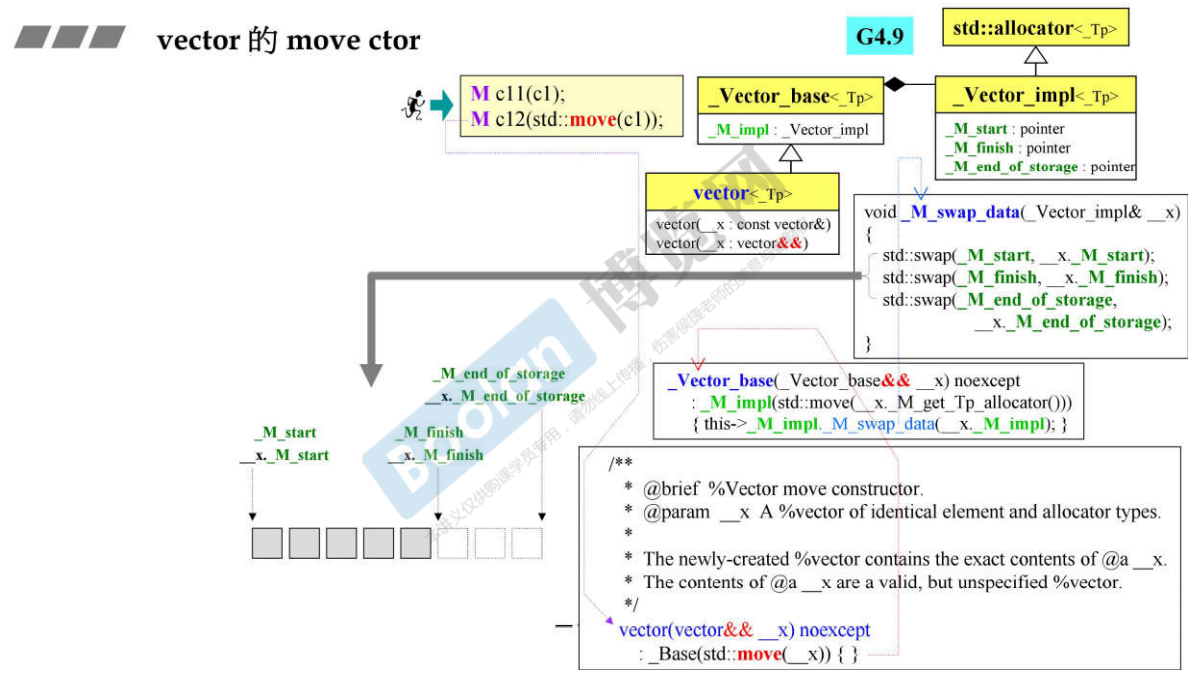
说明:


若有收获,就点个赞吧
0 人点赞
