Performance Tuning
延迟,吞吐量和资源消耗是性能调优中涉及的三个关键维度。在以下部分中,我们将讨论可用于调整这些维度并理解权衡的设置。
重要的是要了解这些设置可能会根据拓扑,硬件类型和拓扑使用的主机数量而有所不同。
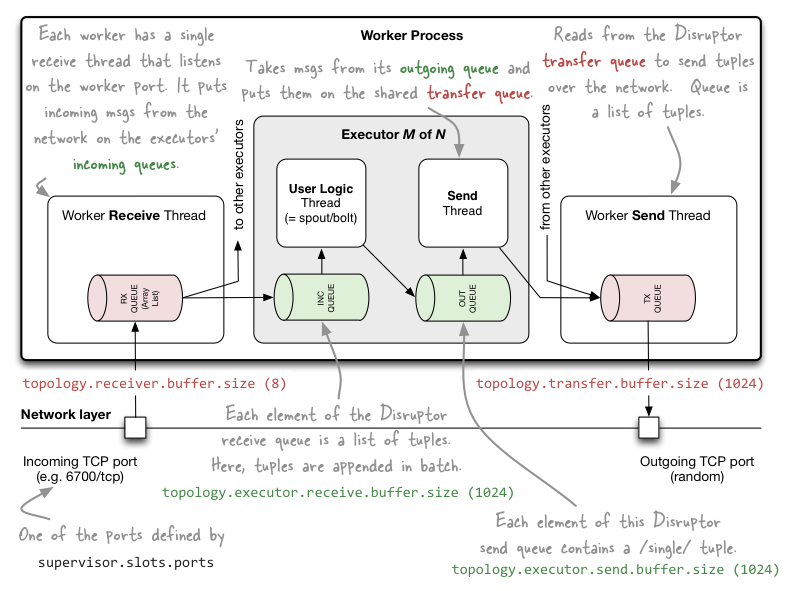
1. Buffer Size(缓冲大小)
Spouts和Bolts使用消息传递来实现异步操作。用于此目的的消息队列具有固定但可配置的大小。缓冲区大小是指这些队列的大小。每个消费者都有自己的接收队列。消息在队列中等待,直到消费者准备好处理它们。根据消费者是否比生产者为其生成消息的速度更快或更慢地运行,队列通常几乎为空或几乎满。Storm队列总是有一个消费者,可能还有多个生产者。有两个感兴趣的缓冲区大小设置:
topology.executor.receive.buffer.size: This is the size of the message queue employed for each spout and bolt executor.topology.transfer.buffer.size: This is the size of the outbound message queue used for inter-worker messaging. This queue is referred to as the Worker Transfer Queue.
注意:如果指定的缓冲区大小不是2的次幂,则它在内部向上舍入到下一个2的次幂。
Guidance
非常小的消息队列(size<1024)可能会因消费者和生产者之间没有提供足够的隔离而妨碍吞吐量。这可能会影响处理的异步性质,因为生产者可能会发现下游队列已满。
非常大的消息队列也不适合处理慢消费者。最好在额外的CPU内核上使用更多的消费者(即bolt)。如果队列很大并且通常已满,则消息将在处理的每个步骤中在这些队列中等待更长时间,从而导致在Storm UI上报告较差的延迟。大队列也意味着更高的内存消耗,特别是如果队列通常已满。
2. Batch Size(批次大小)
生产者可以将一批消息写入消费者的队列,也可以单独编写每条消息。可以配置batch size。将消息批量插入下游队列有助于减少插入所需的同步操作数。因此,这有助于实现更高的吞吐。但是,在将缓冲区刷新到下游队列之前,有时可能需要一点时间才能填充缓冲区。这意味着缓冲的消息将需要更长的时间才能对等待处理它们的下游消费者可见。这可能会增加这些消息的平均端到端延迟。如果批量大并且拓扑没有经历高流量,则延迟会变得非常糟糕。
topology.producer.batch.size: The batch size for writes into the receive queue of any spout/bolt is controlled via this setting. This setting impacts the communication within a worker process. Each upstream producer maintains a separate batch to a component’s receive queue. So if two spout instances are writing to the same downstream bolt instance, each of the spout instances will have maintain a separate batch.topology.transfer.batch.size: Messages that are destined to a spout/bolt running on a different worker process, are sent to a queue called the Worker Transfer Queue. The Worker Transfer Thread is responsible for draining the messages in this queue and send them to the appropriate worker process over the network. This setting controls the batch size for writes into the Worker Transfer Queue. This impacts the communication between worker processes.
Guidance
对于低延迟:将batch size设置为1.这基本上禁用批处理。这可能会降低交通繁忙时的峰值可持续吞吐量,但在低/中交通情况下不太可能影响吞吐量。
对于高吞吐量:设置batch size> 1.尝试使用10,100,1000甚至更高的值,看看是什么产生了拓扑的最佳吞吐量。超过某一点,吞吐量可能会变得更糟。
不同的吞吐量:拓扑通常会在一天内出现波动的传入流量。其他topos可能在某些路径中经历更高的流量并且在其他路径中同时降低吞吐量。如果不考虑延迟,则小的batch size(例如10)并且与正确的冲洗频率相结合可以为这种情况提供合理的折衷。要满足更严格的延迟SLA,请考虑将其设置为1。
3. Flush Tuple Frequency(刷新元组频率)
在低/中等流量情况下或当batch size太大时,batch可能花费太长时间来填满,因此消息可能花费不可接受的长时间以使下游组件可见。在这种情况下,需要定期刷新批次以保持消息移动,并避免在启用批处理时影响延迟。
topology.flush.tuple.freq.millis : 此设置控制生成刷新元组的频率。Flush tuples are not generated if this configuration is set to 0 or if (topology.producer.batch.size=1 and topology.transfer.batch.size=1).
Guidance
刷新间隔可用作工具,以保持批处理的更高吞吐量优势,并避免批处理消息长时间停留等待他们。批量填写。优选地,该值应该大于拓扑中bolt的平均执行等待时间。尝试比生成消息所花费的时间更频繁地刷新队列可能会损害性能。了解每个bolt的平均执行延迟将有助于确定两次刷新之间队列中的平均消息数。
For Low latency: A smaller value helps achieve tighter latency SLAs.
For High throughput: When trying to maximize throughput under high traffic situations, the batches are likely to get filled and flushed automatically. To optimize for such cases, this value can be set to a higher number.
Varying throughput: If latency is not a concern, a larger value will optimize for high traffic situations. For meeting tighter SLAs set this to lower values.
4. Wait Strategy(等待策略)
等待策略用于通过牺牲一些延迟和吞吐量来节省CPU使用率。它们适用于以下情况:
4.1 Spout Wait: In low/no traffic situations, Spout’s nextTuple() may not produce any new emits. To prevent invoking the Spout’s nextTuple too often, this wait strategy is used between nextTuple() calls, allowing the spout’s executor thread to idle and conserve(节省) CPU. Spout wait strategy is also used when the topology.max.spout.pending limit has been reached when ACKers are enabled. Select a strategy using topology.spout.wait.strategy. Configure the chosen wait strategy using one of the topology.spout.wait.* settings.
4.2 Bolt Wait: : When a bolt polls it’s receive queue for new messages to process, it is possible that the queue is empty. This typically happens in case of low/no traffic situations or when the upstream spout/bolt is inherently slower. This wait strategy is used in such cases. It avoids high CPU usage due to the bolt continuously checking on a typically empty queue. Select a strategy using topology.bolt.wait.strategy. The chosen strategy can be further configured using the topology.bolt.wait.* settings.
4.3 Backpressure Wait : Select a strategy using topology.backpressure.wait.strategy. When a spout/bolt tries to write to a downstream component’s receive queue, there is a possibility that the queue is full. In such cases the write needs to be retried. This wait strategy is used to induce some idling in-between re-attempts for conserving CPU. The chosen strategy can be further configured using the topology.backpressure.wait.* settings.
Built-in wait strategies:
这些等待策略可用于所有上述等待情况。
- ProgressiveWaitStrategy : This strategy can be used for Bolt Wait or Backpressure Wait situations. Set the strategy to ‘org.apache.storm.policy.WaitStrategyProgressive’ to select this wait strategy. This is a dynamic wait strategy that enters into progressively deeper states of CPU conservation if the Backpressure Wait or Bolt Wait situations persist. It has 3 levels of idling and allows configuring how long to stay at each level :
- Level1 / No Waiting - The first few times it will return immediately. This does not conserve any CPU. The number of times it remains in this state is configured using
topology.spout.wait.progressive.level1.countortopology.bolt.wait.progressive.level1.countortopology.backpressure.wait.progressive.level1.countdepending which situation it is being used. - Level 2 / Park Nanos - In this state it disables the current thread for thread scheduling purposes, for 1 nano second using LockSupport.parkNanos(). This puts the CPU in a minimal conservation state. It remains in this state for
topology.spout.wait.progressive.level2.countortopology.bolt.wait.progressive.level2.countortopology.backpressure.wait.progressive.level2.countiterations. - Level 3 / Thread.sleep() - In this level it calls Thread.sleep() with the value specified in
topology.spout.wait.progressive.level3.sleep.millisortopology.bolt.wait.progressive.level3.sleep.millisortopology.backpressure.wait.progressive.level3.sleep.millis. This is the most CPU conserving level and it remains in this level for the remaining iterations.
- ParkWaitStrategy : This strategy can be used for Bolt Wait or Backpressure Wait situations. Set the strategy to
org.apache.storm.policy.WaitStrategyParkto use this. This strategy disables the current thread for thread scheduling purposes by calling LockSupport.parkNanos(). The amount of park time is configured using eithertopology.bolt.wait.park.microsecortopology.backpressure.wait.park.microsecbased on the wait situation it is used. Setting the park time to 0, effectively disables invocation of LockSupport.parkNanos and this mode can be used to achieve busy polling (which at the cost of high CPU utilization even when idle, may improve latency and/or throughput).
5. Max.spout.pending
设置topology.max.spout.pending限制了spout级别的未确认元组的数量。一旦spout达到此限制,在收到未完成的发射的某些ACK之前,不会调用喷口的nextTuple()方法。如果禁用ACKing,则此设置不会产生任何影响。它是一种可以影响吞吐量和延迟的spout限制机制。将其设置为null会禁用storm-core拓扑。对吞吐量的影响取决于拓扑及其并发性(workers/executors),因此需要进行实验以确定最佳设置。延迟和内存消耗通常会随着越来越高的值而增加。
6. Load Aware messaging
When load aware messaging is enabled (default), shuffle grouping takes additional factors into consideration for message routing. Impact of this on performance is dependent on the topology and its deployment footprint (i.e. distribution over process and machines). Consequently it is useful to assess the impact of setting topology.disable.loadaware.messaging to true or false for your specific case.
7. Sampling Rate
采样率用于控制在Spout和Bolt执行器上计算某些度量的频率。这是使用topology.stats.sample.rate配置的。将其设置为1意味着,将为每个发出的消息计算统计信息。例如,每1000条消息采样一次,可以设置为0.001。通过降低采样率可以提高吞吐量和延迟。
8. Budgeting CPU cores for Executors
在为它们预算CPU核心时要考虑三种主要类型的执行程序(即线程)。Spout Executors,Bolt Executors,Worker Transfer(处理出站消息)和NettyWorker(处理入站消息)。前两个用于运行spout,bolt和acker实例。Worker Transfer线程用于序列化并向其他worker发送消息(在多工作模式下)。
Executors由于处理大量消息,或者因为它们的处理本身就是CPU密集型( CPU intensive),预计会保持忙碌的执行程序应分配1个物理核心。为CPU密集型执行程序分配逻辑核心(而不是物理核心)或少于1个物理核心会增加CPU争用并且性能会受到影响。预计不会繁忙的执行程序可以分配一小部分物理核心(甚至是逻辑核心)。为不太可能使CPU饱和的执行程序分配完整的物理内核可能不经济。
系统bolt通常每秒处理非常少的消息,因此需要非常少的CPU(通常少于物理核心的10%)。
9. Garbage Collection
对于延迟或吞吐量敏感的拓扑,GC的选择是一个重要问题。建议尝试CMS和G1收集器。收集器的性能特征可以在单工作模式(single worker)和多工作模式(multi worker)之间变化,并且取决于硬件特性,例如CPU数量和存储器位置。GC线程数也会影响性能。有时较少的GC线程可以产生更好的性能。建议选择一个收集器并通过模拟类似于生产中使用的硬件上的预期峰值数据速率来调整它。
10. Scaling out with Single Worker mode
工作进程(worker)内执行程序之间的通信非常快,因为既不需要序列化和反序列化消息,也不涉及通过网络堆栈进行通信。在多工作模式(multiworker )下,消息通常跨越工作进程边界。对于性能敏感的情况,如果可以将拓扑配置为运行尽可能多的单工作者实例(例如,每个输入分区一个工作者)而不是一个多工作程序实例,则可能会在同一硬件上产生明显更好的吞吐量和延迟。这种方法的缺点是它增加了监视和管理许多实例的开销,而不是一个多工作实例。
11. 关于并行度
The Storm UI has also been made significantly more useful. There are new stats “#executed”, “execute latency”, and “capacity” tracked for all bolts. The “capacity” metric is very useful and tells you what % of the time in the last 10 minutes the bolt spent executing tuples. If this value is close to 1, then the bolt is “at capacity” and is a bottleneck in your topology. The solution to at-capacity bolts is to increase the parallelism of that bolt. (…)
from —-><https://storm.apache.org/releases/2.0.0/Performance.html

若有收获,就点个赞吧
0 人点赞
