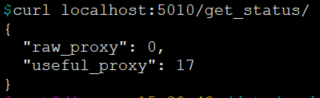
一 代理池服务器搭建

二 为scrapy项目添加代理中间件
1 编写中间件类
随机UA中间件
# proxies/user_agent.pyimport randomclass UA(object):@classmethoddef random_ua(cls):ua_list = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)','Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',]return random.choice(ua_list)class RandomUserAgentMiddleware(object):def __init__(self, crawler):super(RandomUserAgentMiddleware, self).__init__()self.ua = UA.random_ua()@classmethoddef from_crawler(cls, crawler):return cls(crawler)def process_requests(self, request, spider):request.headers.setdefault('User-Agent', self.ua)
获取可用的代理IP
# proxies/pool.pyimport timeimport requestsfrom omim import settingsfrom user_agent import UAclass Pool(object):proxy_url = settings.PROXY_URL@classmethoddef get(cls):url = cls.proxy_url + '/get/'res = requests.get(url).json()if not res:print('proxy pool is empty, wait a minute ...')time.sleep(60)return cls.get()ip = res['proxy']return ip@classmethoddef delete(cls, ip):url = '{}/delete/?proxy={}'.format(cls.proxy_url, ip)requests.get(url)@classmethoddef check(cls, ip):print('checking ip: {} ...'.format(ip))url = 'https://www.omim.org/statistics/entry'proxies = {'https': 'https://{}'.format(ip)}headers = {'User-Agent': UA.random_ua()}try:resp = requests.get(url, proxies=proxies, headers=headers, timeout=15)if '<title>Error 403</title>' in resp.text:return Falsereturn Trueexcept Exception as e:print ereturn False@classmethoddef get_good_proxy(cls):ip = cls.get()if cls.check(ip):return 'https://{}'.format(ip)else:print('delete ip: {}'.format(ip))cls.delete(ip)return cls.get_good_proxy()
代理池中间件编写
from pool import Poolfrom user_agent import UAclass ProxyMiddleware(object):def __init__(self):passdef process_request(self, request, spider):proxy = Pool.get_good_proxy()print '>>> crawling with proxy: {}'.format(proxy)request.meta['proxy'] = proxy
2 开启中间件
# setttings.pyDOWNLOADER_MIDDLEWARES = {# 'omim.middlewares.OmimDownloaderMiddleware': 543,'omim.proxies.ProxyMiddleware': 543,'omim.proxies.user_agent.RandomUserAgentMiddleware': 542,'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,}

若有收获,就点个赞吧
0 人点赞
