爬取百度翻译的内容
# -*- coding: UTF-8 -*-import requestsurl = "https://fanyi.baidu.com/sug"s=input('请输入你要翻译的英文')dat = {"kw": s}# 发送post请求,发送的数据必须放在字典中,通过data参数进行链接req = requests.post(url, data=dat)print(req.json())req.close()
爬取豆瓣电影分类排行榜
# -*- coding: UTF-8 -*-
import requests
url = "https://movie.douban.com/typerank"
# 从新封装参数
mer= {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20,
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0'
}
req = requests.get(url=url, params=mer,headers=headers)
print(req.text)
 正则表达式默认只匹配一位字符。
正则表达式默认只匹配一位字符。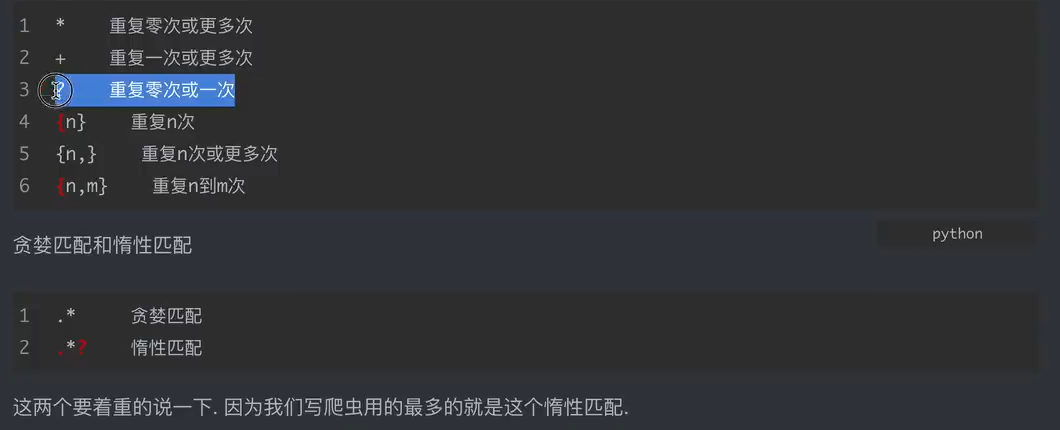

预加载正则表达式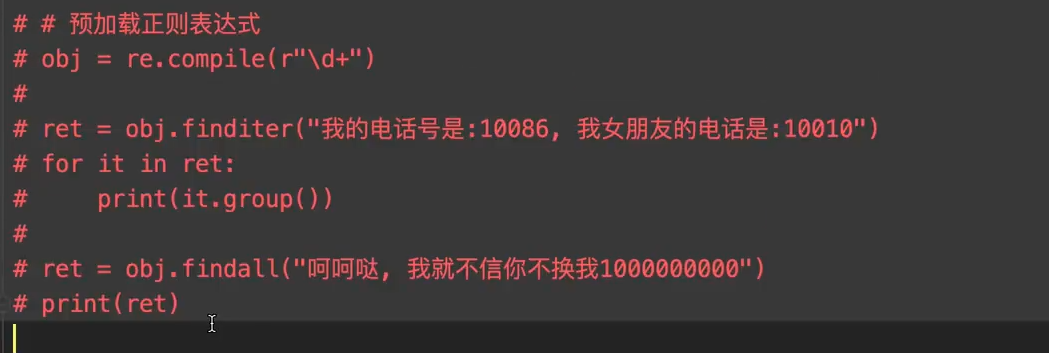
简单提取数据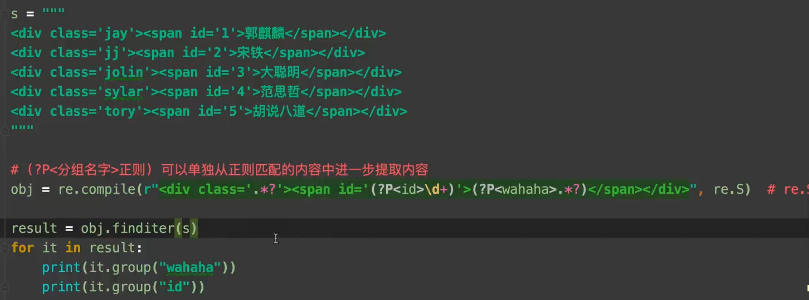
# -*- coding: UTF-8 -*-
import re
obj = re.compile(r"\d+")
s = """
<div class='jay'>≤span id='1'>郭麒麟</span></div>
<div class='jj'><span id='2'>宋铁</span></div>
<div class='joLin'><span id='3'>大聪明</span></div>
<div class='syLar'><span id='4'>范思哲</span></div>
<div class='tory'><span id='5'>胡说八道</ span></div>
"""
#(?P<分组名字>正则) 可以单独冲正则匹配内容中进一步提取内容
obj = re.compile(r"<div class='.*?'><span id='(?P<dd>\d)'>(?P<whh>.*?)</span></div>",re.S) #re.S可以使.匹配换行符。
result = obj.finditer(s)
for i in result:
print(i.groups("dd"))
print(i.groups("whh"))
爬取豆瓣top250的电影名称和评分
# -*- coding: UTF-8 -*-
#拿到页面源代码,requests
#通过re模块提取数据
import re
import requests
import csv
url = "https://movie.douban.com/top250"
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0'
}
resp = requests.get(url,headers=header)
yuanma = resp.text
# 解析数据
obj = re.compile(r' <li>.*? <span class="title">(?P<name>.*?)</span>.*?'
r'<span class="rating_num" property="v:average">(?P<number>.*?)</span>',re.S)
# 处理数据
ret = obj.finditer(yuanma)
f =open("data.csv",mode="w",encoding="utf-8")#打开文件,写入获取的数据。
csvwriter = csv.writer(f)
for i in ret:
print(i.groups("name,number"))
dic = i.groupdict()
csvwriter.writerow(dic.values())
f.close()
print("over")
bs4解析数据
butisup的简单练习
import requests
from bs4 import BeautifulSoup
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0'
}
url = "http://www.xinfadi.com.cn/marketanalysis/0/List/1.shtmL"
resp = requests.get(url, headers=header)
# 解析数据
#1.吧页面交给Beautifusoup进行处理,生成bs对象
page = BeautifulSoup(resp.text, "html.parser")#指定编译器
# 2.从bs4中查找数据
# find (标签,属性=值) 查找一次
# find_all(标签,属性=值) 查找多次
table = page.find("table", class_="hq_table") #class是python的关键字
# table = page.find("table", attrs={"class": "hq_table"}) 和上面的作用是一样的,只不过增加了数组而已
trs = table.find_all("tr")[1:] #取所有行
for tr in trs: #每一行
tds =tr.find_all("td") #拿到每一行的所有的td
name = tds[0].text #.text代表拿到被标签标记的内容
low= tds[1].text
avg = tds[2].text
higt = tds[3].text
gui = tds[4].text
kind = tds[5].text
date = tds[6].text
print(name, low, avg, higt, gui, kind, date)
爬取图片
import requests
from bs4 import BeautifulSoup
import time
url = "https://umei.cc/bizhitupian/weimeibizhi/"
resp = requests.get(url)
resp.encoding = 'utf-8'
#print(resp.text)
main_page = BeautifulSoup(resp.text, "html.parser")
alist =main_page.find("div", class_="TypeList").find_all("a")
#print(alist)
for a in alist:
#print(a.get('href'))# 直接通过get就可以拿到地址
href=a.get('href')
#拿子页面的源代码
child_page_resp = requests.get('https://umei.cc/'+href)
child_page_resp.encoding ='utf-8'
child_page_text =child_page_resp.text
#print(child_page_text)
#从那个子页面拿到下载地址
child_page = BeautifulSoup(child_page_text, "html.parser")
p = child_page.find('p', align='center')
img =p.find('img')
#print(img)
src =img.get('src')
#下载图片
img_resq = requests.get(src)
#img_resq.content 这里拿到的是字节
imgname = src.split("/")[-1] #吧url最后一个/后面部分当作图片名字
with open(imgname, mode="wb") as f:
f.write(img_resq.content)
print("over"+imgname)
time.sleep(1)#休息一秒钟
print("allover")

若有收获,就点个赞吧
0 人点赞
