如果我们已经向一个缓冲区中写入了一些数据,那么该如何读取这些被写入的数据呢?下面依然通过逻辑视图来说明。
分配ByteBuffer缓冲区
代码 分配ByteBuffer缓冲区
// 分配一个ByteBuffer缓冲区ByteBuffer buffer = ByteBuffer.allocate(12);
图示 分配ByteBuffer缓冲区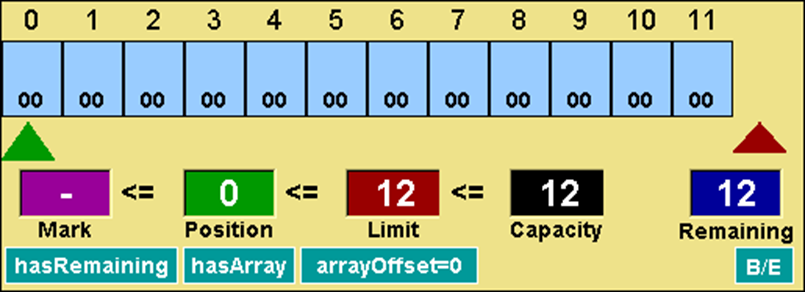
写入ByteBuffer缓冲区
代码 ByteBuffer缓冲区连续6次写入
// 连续6次写入缓冲区buffer.put((byte) 0).put((byte) 1).put((byte) 2).put((byte) 3).put((byte) 4).put((byte) 5);
图示 ByteBuffer缓冲区连续6次写入
此时我们已经向ByteBuffer缓冲区写入了6个字节的数据,现在该如何读出这些数据呢?如果在此之后调用 get ( ) 方法,不但不能读取到缓冲区中的数据,还会将position的位置继续向前推进。那该如何确定缓冲区中有效数据的起始位置和结束位置呢?
如果我们将position的位置值重新设为 0,就可以从正确的位置开始获取数据。现在我们已经知道了缓冲区数据起点,但是又怎样确定哪里才是缓冲区中可读数据的末端呢?为了解决这个问题,引入了limit属性,limit属性指明了缓冲区有效数据的结束位置,因此可以将limit属性设置为当前position指向的位置。这样就构成了一个从0到limit之间的有效数据区间。
使用如下代码可以实现缓冲区有效访问区间的设置,需要注意的是必须先将当前position的位置赋值给limit属性,再将position置0,不能将这个赋值关系弄反了。
代码 设置缓冲区的有效访问区间
buffer.limit(buffer.position()).position(0);
代码中的这个操作被称为缓冲区的翻转,翻转意味着将一个能够继续添加数据元素、并且处于填充状态的缓冲区翻转成一个准备读取数据的状态,并确定好了数据读取的起始索引,与数据读取的结束索引。
为了方便开发者的使用,缓冲区类已经将其封装为一个更为方便的接口:flip( ),flip的实现如下代码所示。相比较上面的代码,flip方法还会处理mark属性,即丢弃mark所在的位置索引,这意味着缓冲区翻转后就没有必要回到mark所在的位置。
代码 flip方法
public Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
我们执行缓冲区的翻转操作,如下代码所示。缓冲区的属性状态被更新为如下图所示,limit(6) = position(6),position = 0,mark = -1。
代码 翻转ByteBuffer缓冲区
buffer.flip(); // 翻转缓冲区
图示 ByteBuffer翻转后的示意图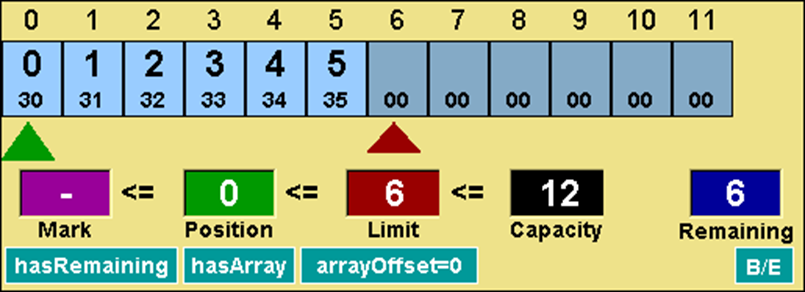
现在可以从正确的位置读取缓冲区中的数据了。如下代码所示,将缓冲区中的数据依次读出。读出缓冲区中的有效数据后,缓冲区的属性状态如下图所示。缓冲区的 position 属性又重新从索引 0 向前推进,直到指向limit所在的位置。
代码 ByteBuffer缓冲区连续6次读取
// 连续6次读取缓冲区
buffer.get( );
buffer.get( );
buffer.get( );
buffer.get( );
buffer.get( );
buffer.get( );
图示 ByteBuffer翻转后读取缓冲区数据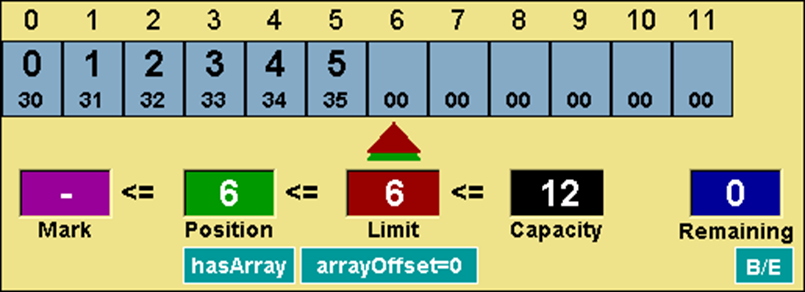

若有收获,就点个赞吧
0 人点赞
