题目:
212. 单词搜索 II [困难]
应用
Trie (发音为 “try”) 或前缀树是一种树数据结构,用于检索字符串数据集中的键。这一高效的数据结构有多种应用:
自动补全

图 1. 谷歌的搜索建议拼写检查
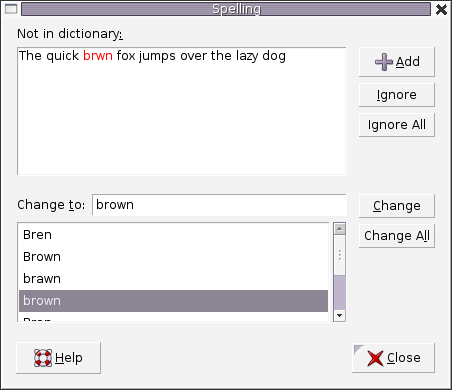
图2. 文字处理软件中的拼写检查IP 路由 (最长前缀匹配)
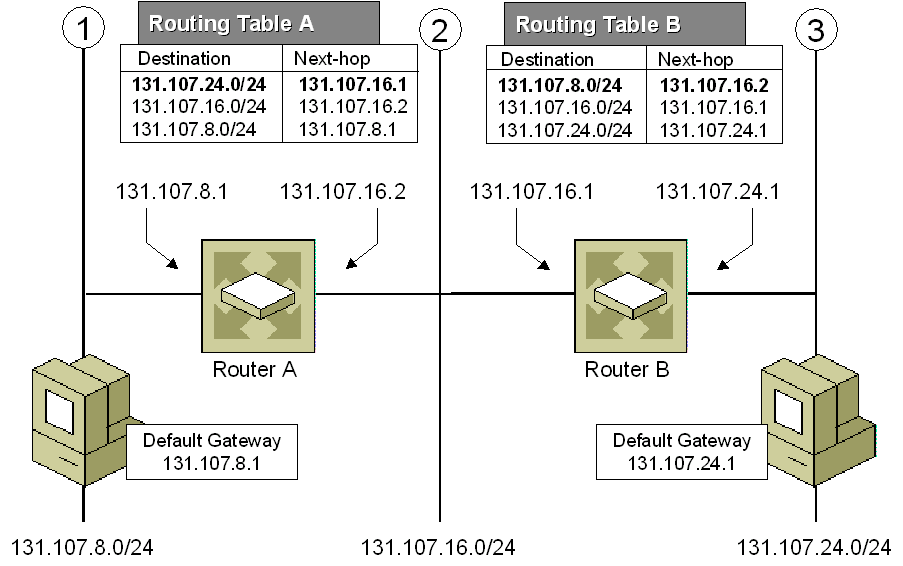
图 3. 使用Trie树的最长前缀匹配算法,Internet 协议(IP)路由中利用转发表选择路径T9 (九宫格) 打字预测
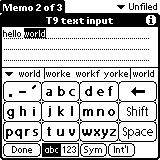
图 4. T9(九宫格输入),在 20 世纪 90 年代常用于手机输入
- 单词游戏

图 5. Trie 树可通过剪枝搜索空间来高效解决 Boggle 单词游戏
还有其他的数据结构,如平衡树和哈希表,使我们能够在字符串数据集中搜索单词。为什么我们还需要 Trie 树呢?尽管哈希表可以在 O(1)O(1) 时间内寻找键值,却无法高效的完成以下操作:
- 找到具有同一前缀的全部键值。
- 按词典序枚举字符串的数据集。
Trie 树优于哈希表的另一个理由是,随着哈希表大小增加,会出现大量的冲突,时间复杂度可能增加到 O(n)O(n),其中 nn 是插入的键的数量。与哈希表相比,Trie 树在存储多个具有相同前缀的键时可以使用较少的空间。此时 Trie 树只需要 O(m)O(m) 的时间复杂度,其中 mm 为键长。而在平衡树中查找键值需要 O(m \log n)O(mlogn) 时间复杂度。
Trie 树的结点结构
Trie 树是一个有根的树,其结点具有以下字段:。
最多 RR 个指向子结点的链接,其中每个链接对应字母表数据集中的一个字母。
本文中假定 RR 为 26,小写拉丁字母的数量。
布尔字段,以指定节点是对应键的结尾还是只是键前缀。

图 6. 单词 “leet” 在 Trie 树中的表示
class TrieNode {/** 该节点下的子节点 */private links: TrieNode[] = []/*** 本地存一个 map, 用于在 O(1) 的时间进行元素查找* 注意: 这些查询操作,期望时间复杂度是 O(1),但是如果遍历数组进行查找时间复杂度是 O(n)。* 而在实际应用中,例如对用户输入单词的预测补全,每层所需要搜索的都是固定的 26 个字母,通过预制一个本地 map,我们是完全可以通过 O(1) 的时间复杂度来完成查询的。* 这里假设在节点初始化时,这份完整的 map 就已经存在了*/private searchMap: Map<string, number> = new Map<string, number>()/** 当前节点是否为词缀的结束节点 */private isEnd: boolean = falsepublic containsKey(val: string): boolean {return this.searchMap.get(val) ? true : false}public get(val: string): TrieNode | undefined {return this.links[this.searchMap.get(val)!] // map 中一定能搜索到}public put(val: string, node: TrieNode) {this.links[this.searchMap.get(val)!] = node}public setEnd() {this.isEnd = true}public getEnd() {return this.isEnd}}
Trie 树中最常见的两个操作是键的插入和查找。
向 Trie 树中插入键
我们通过搜索 Trie 树来插入一个键。我们从根开始搜索它对应于第一个键字符的链接。有两种情况:
链接存在。沿着链接移动到树的下一个子层。算法继续搜索下一个键字符。
链接不存在。创建一个新的节点,并将它与父节点的链接相连,该链接与当前的键字符相匹配。
重复以上步骤,直到到达键的最后一个字符,然后将当前节点标记为结束节点,算法完成。
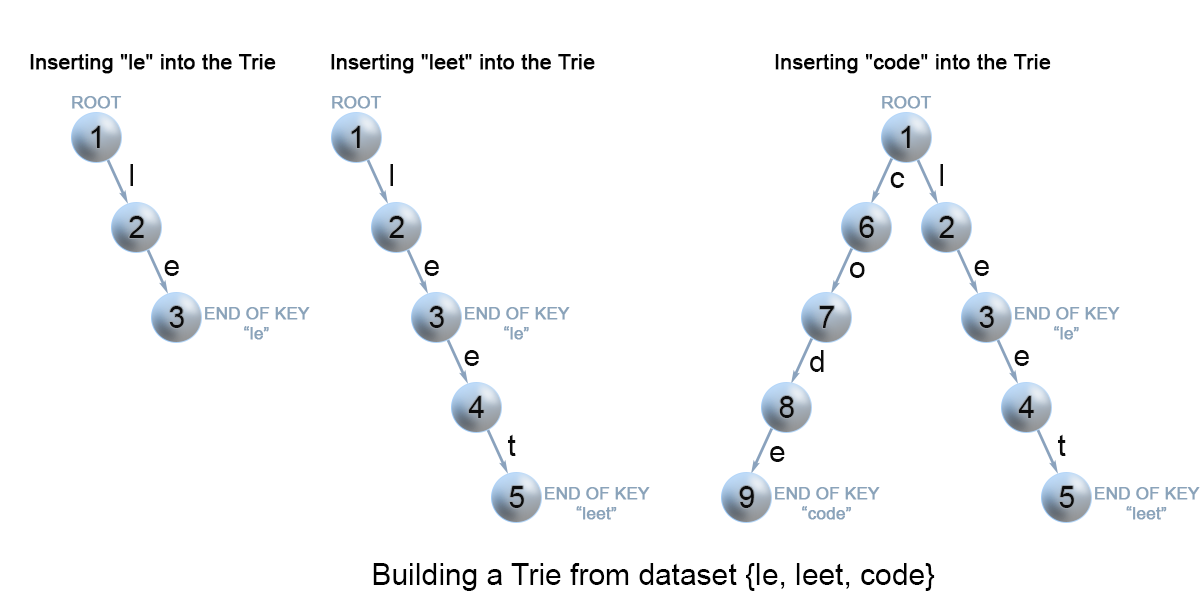
图 7. 向 Trie 树中插入键
class TrieTree {
private root = new TrieNode()
/** 在一棵前缀树中插入一个单词 */
public insert(word: string) {
let curHead = this.root
for (let i = 0; i < word.length; i++) {
if (!curHead.containsKey(word[i])) {
curHead.put(word[i], new TrieNode())
}
curHead = curHead.get(word[i])!
}
curHead.setEnd()
}
}
复杂度分析
时间复杂度:O(m),其中 m 为键长。在算法的每次迭代中,我们要么检查要么创建一个节点,直到到达键尾。只需要 m 次操作。
空间复杂度:O(m)。最坏的情况下,新插入的键和 Trie 树中已有的键没有公共前缀。此时需要添加 m 个结点,使用 O(m) 空间。
在 Trie 树中查找键
每个键在 trie 中表示为从根到内部节点或叶的路径。我们用第一个键字符从根开始,。检查当前节点中与键字符对应的链接。有两种情况:
- 存在链接。我们移动到该链接后面路径中的下一个节点,并继续搜索下一个键字符。
- 不存在链接。若已无键字符,且当前结点标记为 isEnd,则返回 true。否则有两种可能,均返回 false :
- 还有键字符剩余,但无法跟随 Trie 树的键路径,找不到键。
- 没有键字符剩余,但当前结点没有标记为 isEnd。也就是说,待查找键只是Trie树中另一个键的前缀。
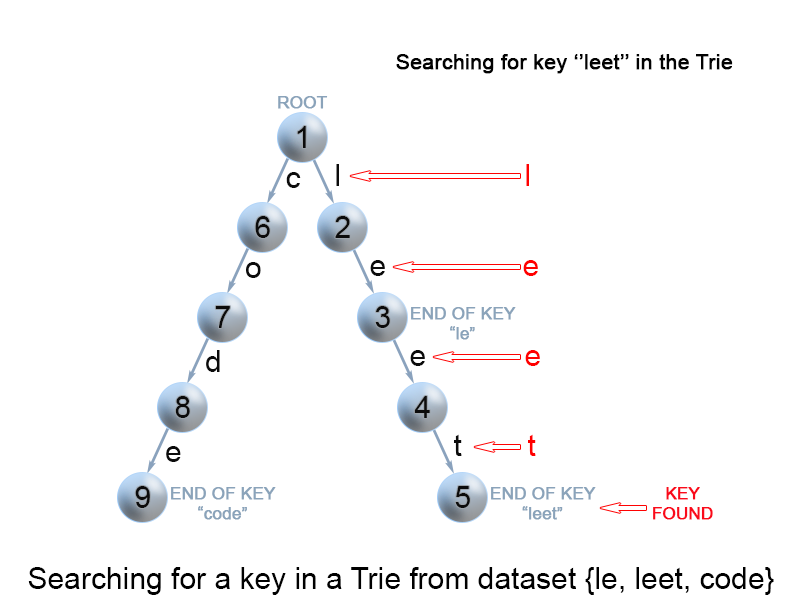
图 8. 在 Trie 树中查找键
class TrieTree {
private root = new TrieNode()
/** 在一棵前缀树中插入一个单词 */
public insert(word: string) {
let curHead = this.root
for (let i = 0; i < word.length; i++) {
if (!curHead.containsKey(word[i])) {
curHead.put(word[i], new TrieNode())
}
curHead = curHead.get(word[i])!
}
curHead.setEnd()
}
/** 查找操作 */
public search(word: string) {
let curHead = this.root
for (let i = 0; i < word.length; i++) {
if (!curHead.containsKey(word[i])) {
return false
}
curHead = curHead.get(word[i])!
}
return curHead.getEnd()
}
}
复杂度分析
时间复杂度 : O(m)。算法的每一步均搜索下一个键字符。最坏的情况下需要 m 次操作。
空间复杂度 : O(1)。
查找 Trie 树中的键前缀
该方法与在 Trie 树中搜索键时使用的方法非常相似。我们从根遍历 Trie 树,直到键前缀中没有字符,或者无法用当前的键字符继续 Trie 中的路径。与上面提到的“搜索键”算法唯一的区别是,到达键前缀的末尾时,总是返回 true。我们不需要考虑当前 Trie 节点是否用 “isend” 标记,因为我们搜索的是键的前缀,而不是整个键。
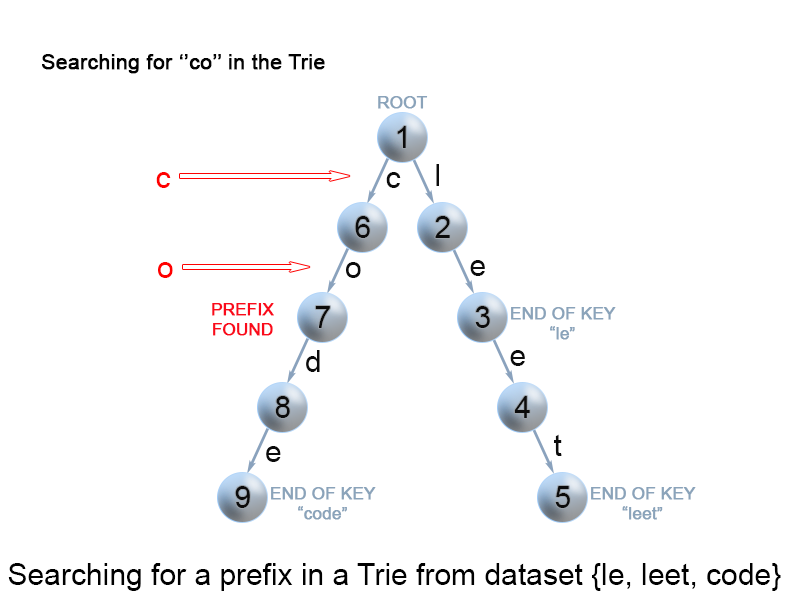
图 9. 查找 Trie 树中的键前缀
class TrieTree {
private root = new TrieNode()
/** 在一棵前缀树中插入一个单词 */
public insert(word: string) {
let curHead = this.root
for (let i = 0; i < word.length; i++) {
if (!curHead.containsKey(word[i])) {
curHead.put(word[i], new TrieNode())
}
curHead = curHead.get(word[i])!
}
curHead.setEnd()
}
/** 查找操作 */
public search(word: string) {
let curHead = this.root
for (let i = 0; i < word.length; i++) {
if (!curHead.containsKey(word[i])) {
return false
}
curHead = curHead.get(word[i])!
}
return curHead.getEnd()
}
/** 只查找前缀 */
public searchPrefix(preWord: string) {
let curHead = this.root
for (let i = 0; i < preWord.length; i++) {
if (!curHead.containsKey(preWord[i])) {
return false
}
curHead = curHead.get(preWord[i])!
}
return true
}
}
复杂度分析
时间复杂度 : O(m)。
空间复杂度 : O(1)。

若有收获,就点个赞吧
0 人点赞
