什么是GC
GC是一种自动的存储管理机制。当一些占用内存的资源不被需要的时候,就应该给予释放,这种存储资源管理,称为垃圾回收。
判断内存是否可以被回收
- 引用计数法
- 可达性分析法 | 算法 | 思想 | 优点 | 缺点 | | —- | —- | —- | —- | | 引用计数法 | 给对象中添加一个引用计数器,每当一个地方引用这个对象的时候,计数器+1;引用失效时,计数器-1 | 判定效率高 | 很难解决对象之间相互引用的情况;开销较大、频繁且大量的引用变化,带来大量的额外运算 | | 可达性分析法 | 通过一系列称为 “GC Roots” 的对象作为起始点,从这些节点向下搜索,当GC Roots 到某个对象不可达时,这个对象就是可回收的 | 更加精确和严谨,可以分析出循环数据结构相互引用的情况 | 实现比较复杂;需要分析大量数据,消耗大量时间 |
目前 主流的jvm都是采用可达性分析法 来管理内存。
引用计数法
最大的问题就是很难解决对象之间的相互引用
- 相互引用
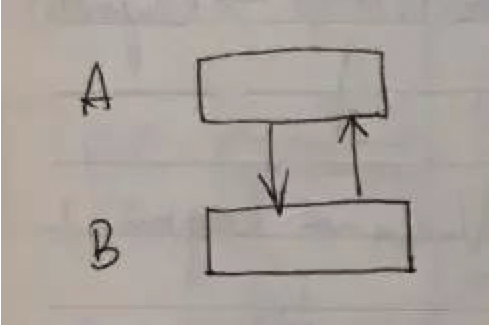
- 循环引用
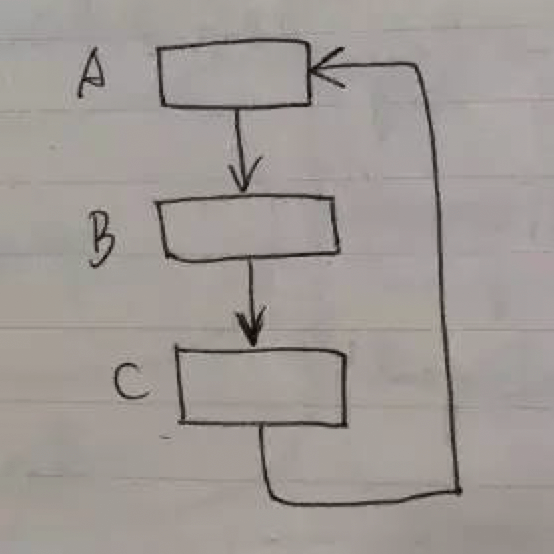
当这些对象整体都无用的时候,由于引用计数并不为0,就无法回收
可达性分析法
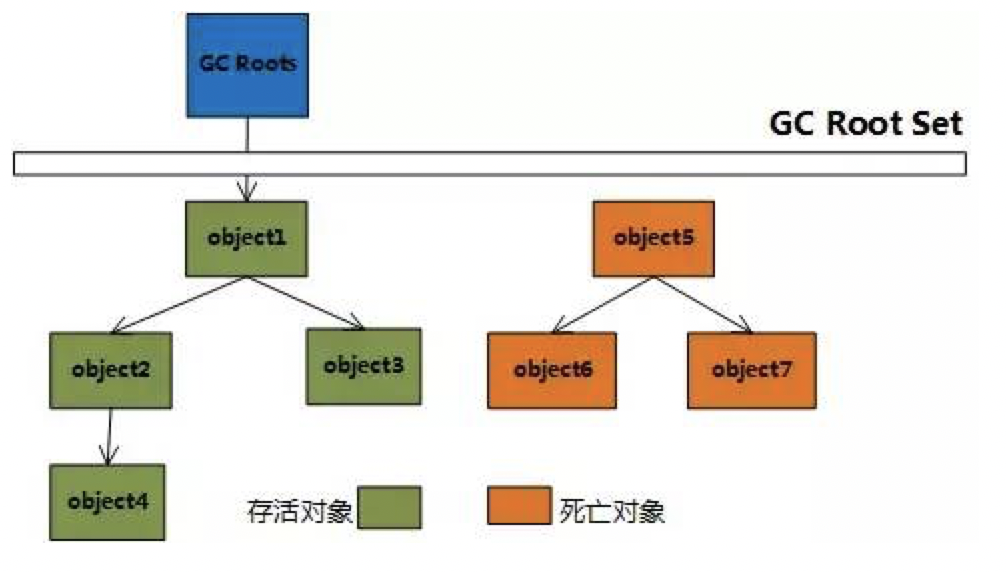
什么对象可以作为 “GC Roots”?
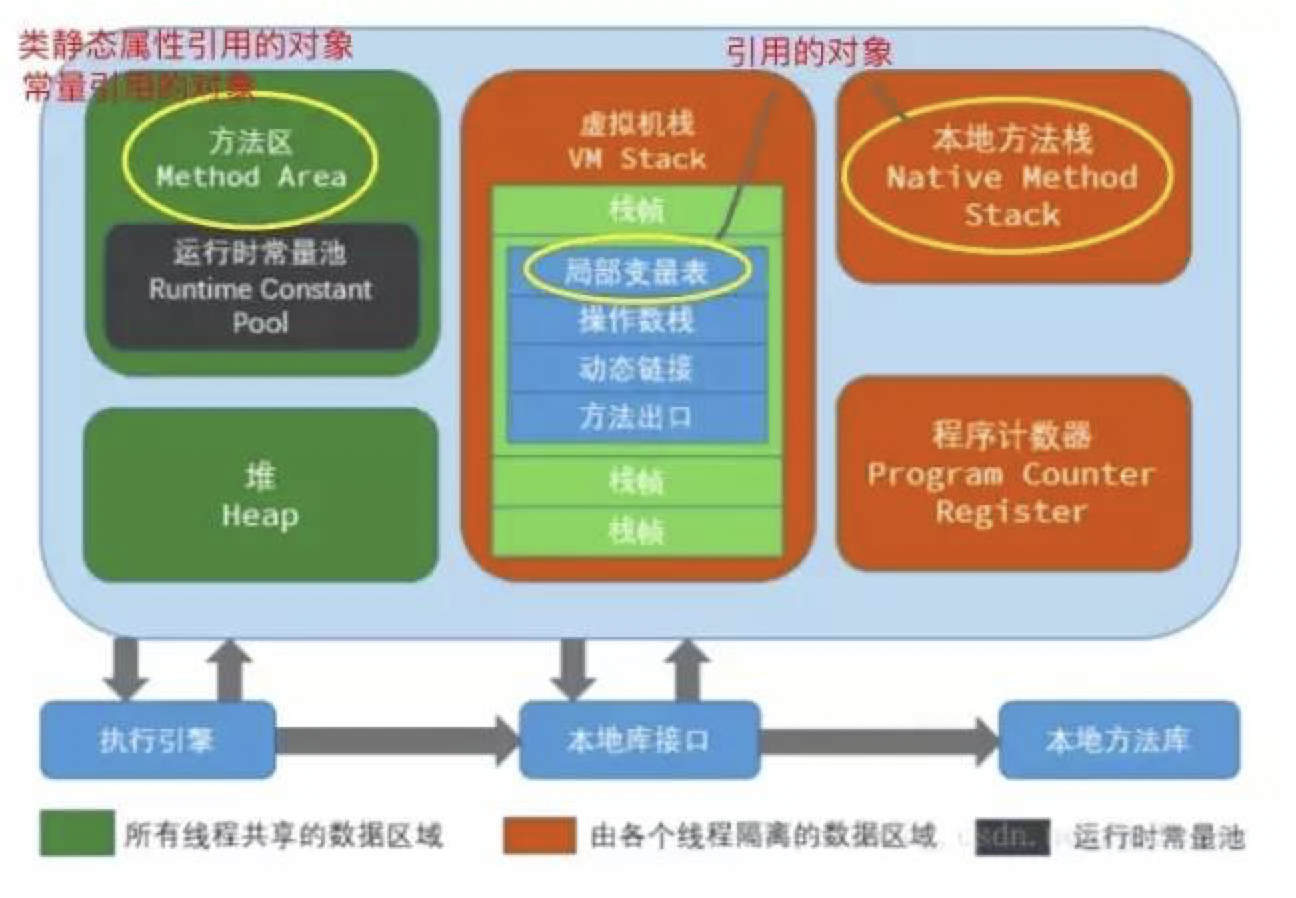

- 方法区的静态属性引用的对象
- 方法区的常量引用的对象
- 虚拟机栈中的局部变量
- 本地方法栈JNI(一般所说的Native方法)中引用的对象
- 虚拟机栈中存放了编译器可知的八种基本数据类型,对象引用,returnAddress类型(指向了一条字节码指令的地址)
- 方法区存与堆一样,是各个线程共享的内存区域,用于存放已被虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据。
- static final 是常量的正确写法
- 成员变量能作为 GC Root 吗?
不能,成员变量也叫实例变量,是存储在堆内存的对象中的,和对象共存亡,不能作为 GC Roots。
引用
为了更灵活的控制对象的生命周期,从JDK1.2开始引入四种引用类型
| 引用类型 | 描述 | 使用情况 | GC时JVM内存足 | GC时JVM内存不足 |
|---|---|---|---|---|
| 强引用(StrongReference) | 类似 “Object o = new Object() 这类引用 | 如果对象具有强引用,垃圾回收器绝不会回收它 | 不回收 | 不回收 |
| 软引用(SoftReference) | 用来描述有用但并非必要的对象 | 如果内存不足(发生 OutOfMemoryError 之前),才会被垃圾回收器回收 | 不回收 | 回收 |
| 弱引用(WeakReference) | 非必要对象 | 只能生存到下一次垃圾回收之前,无论内存是否足够 | 回收 | 回收 |
| 虚引用(PhantomReference) | 幽灵引用或虚幻引用 | 唯一目的就是能在这个对象被回收时收到一个系统通知 |
引用强度比较:
强引用 > 软引用 > 弱引用 > 虚引用
回收(怎么回收?)
- 标记清除法
- 复制算法
- 标记整理算法
- 分代收集算法
标记清除法
分为两个阶段:1. 标记阶段 2. 清除阶段
- 标记阶段
通过根节点,标记所有从根节点开始的可达对象,未标记过的对象就是未被引用过的垃圾对象 - 清除阶段
清除所有未标记的对象。
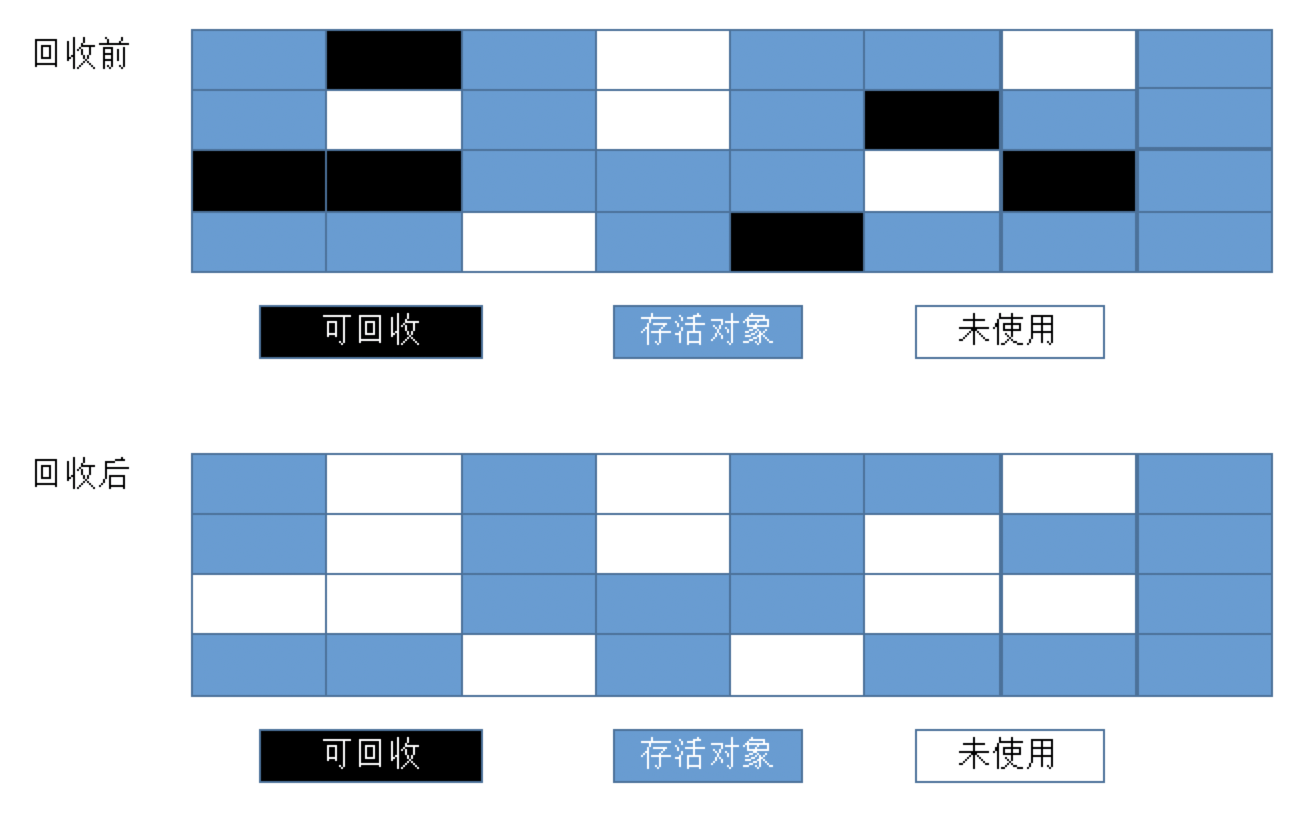
复制算法
为解决效率为题而出现的
将原有的内存空间分为两块,在垃圾回收时,将正在使用的内存中存活对象复制到未使用的内存块,然后清除使用中的内存块。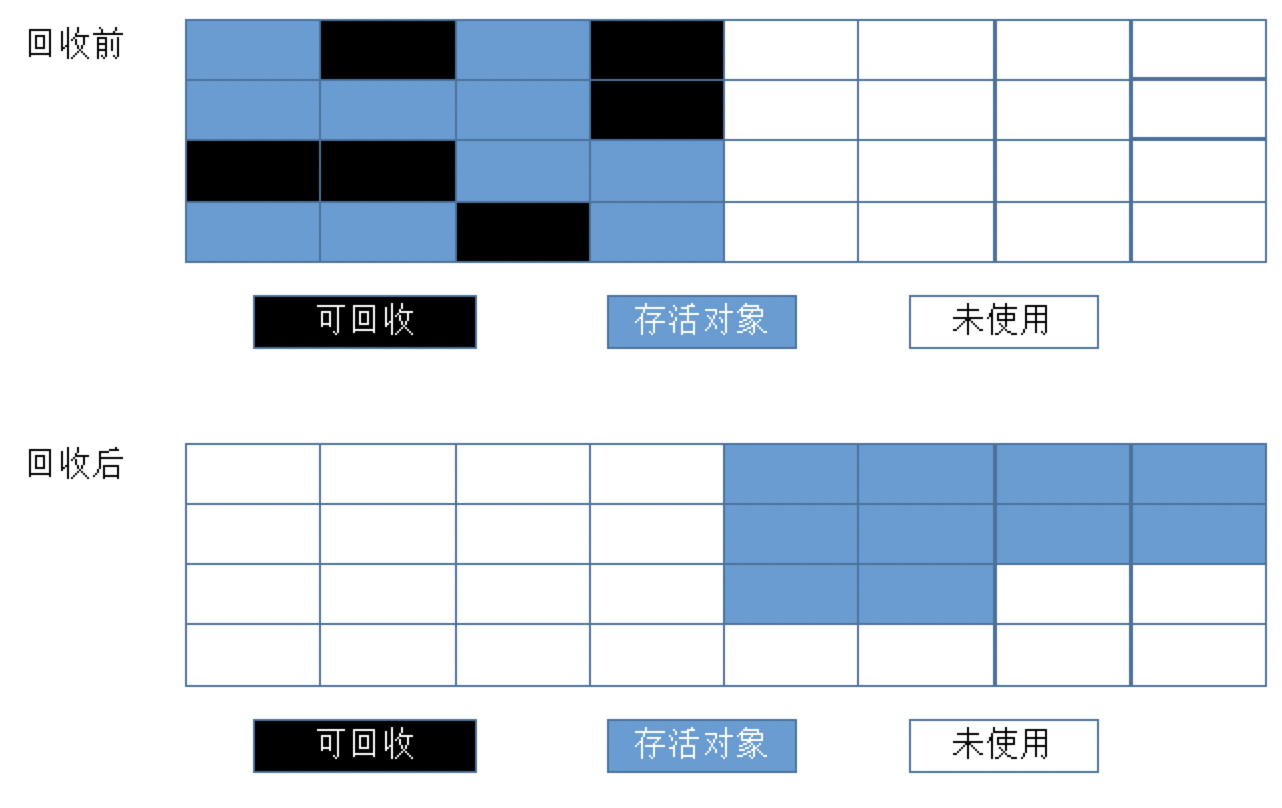
标记整理算法
将所有存活对象都向一端移动,然后直接清除边界以外的内存。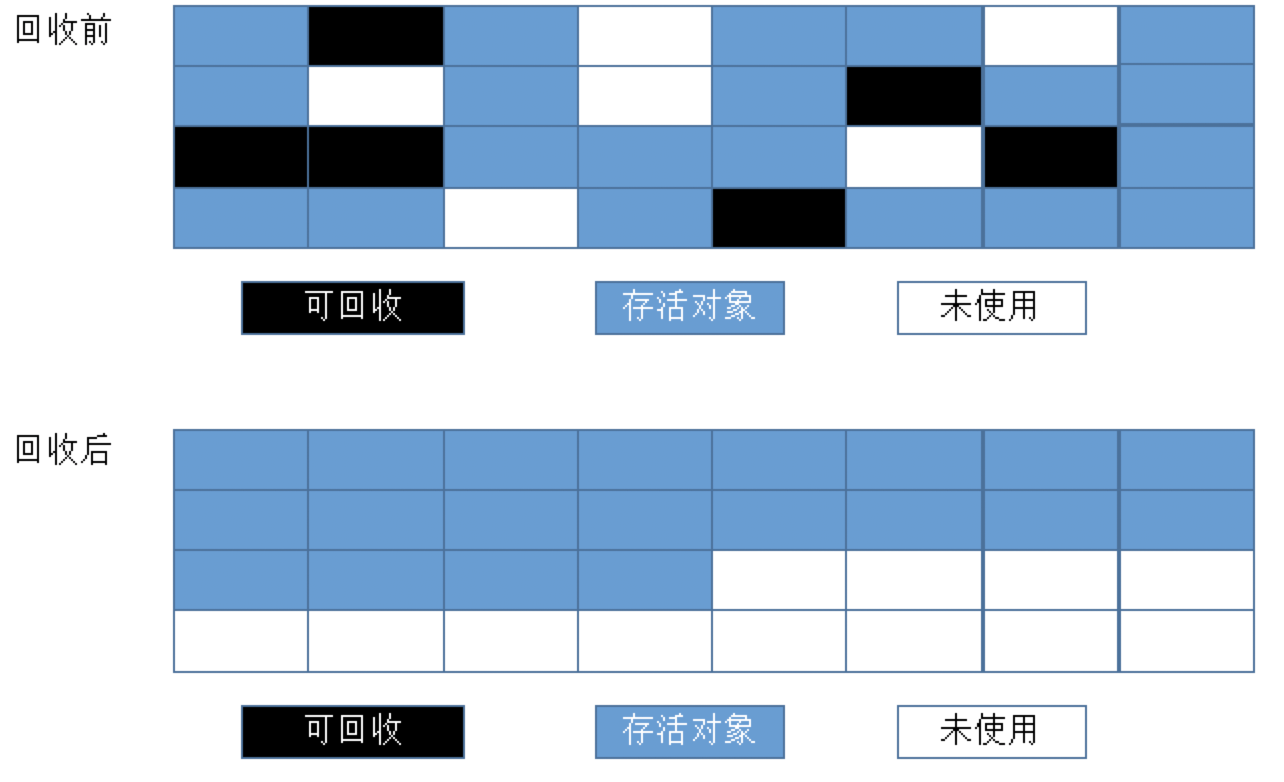
| 算法 | 优点 | 缺点 |
|---|---|---|
| 标记清除法 | 思路简单且实现方便 | 1.效率不高 2. 回收后的状态里,可用内存不连续。当后续需要分配大对象而无法找到连续足够的空间,会提前触发下一次的GC |
| 复制算法 | 回收和分配不用考虑碎片问题,提升效率 | 代价是永远只能使用一半的内存 |
| 标记整理法 | 解决了内存碎片问题,又解决了内存空间的使用率 | 至少两遍 Heap ,牺牲了性能 |
分代收集算法
现代商用虚拟机基本都是采用 分代收集算法 。
分代收集算法融合了上述三种算法思想,根据不同情况采用不同算法。对象存活周期的不同讲内存分为几块。Java堆(java Heap)是JVM 所管理的内存中最大的一块,堆又是垃圾回收器管理的主要区域。这里我们主要分析Java堆的结构。
一般将Java堆分为 新生代 和 老年代。新生代又分为 Eden 和 Survivor区,Survivor又分为 from 和 to 区。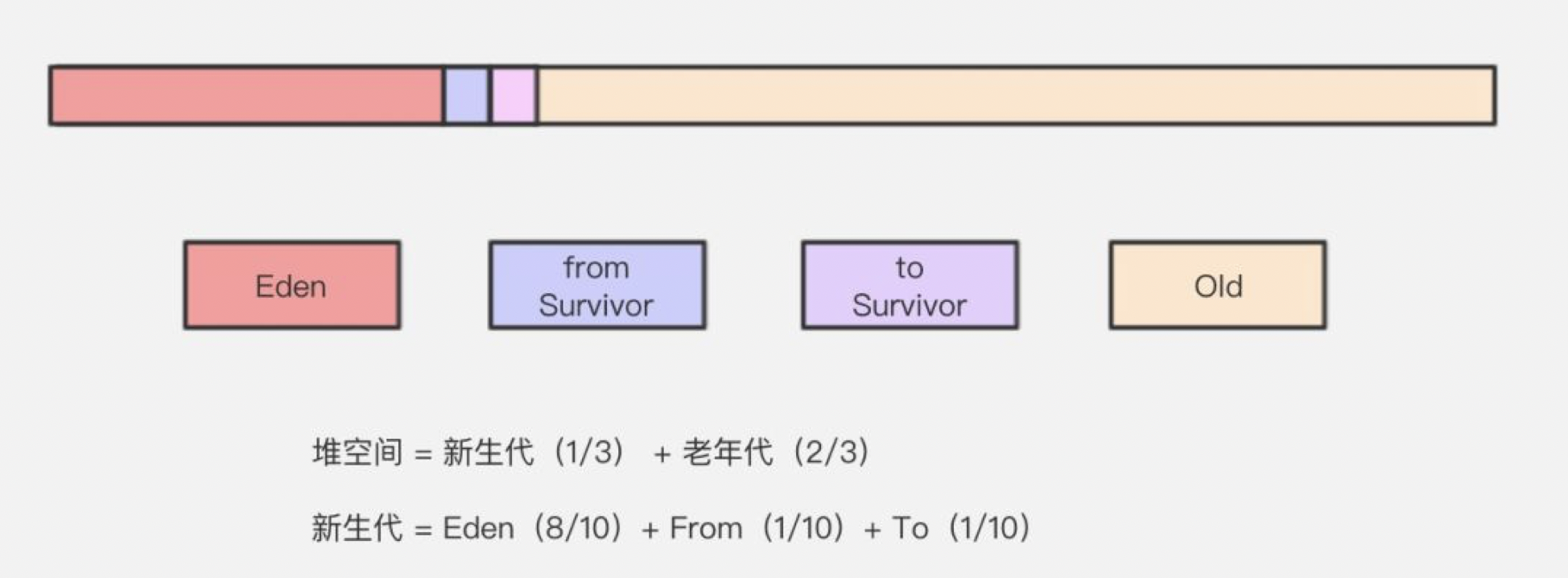
- Eden 区
IBM 公司的专业研究表明,有将近98%的对象是朝生夕死,所以针对这一现状,大多数情况下,对象会在新生代 Eden 区中进行分配,当 Eden 区没有足够空间进行分配时,虚拟机会发起一次 Minor GC,Minor GC 相比 Major GC 更频繁,回收速度也更快。通过 Minor GC 之后,Eden 会被清空,Eden 区中绝大部分对象会被回收,而那些无需回收的存活对象,将会进到 Survivor 的 From 区(若 From 区不够,则直接进入 Old 区)。
由于只有少量存活,那就选用复制算法。 - Survivor 区
Survivor 区相当于 Eden区和 Old区的一个缓冲,类似于我们交通灯的黄灯。Survivor 又分为 From 区和 To 区。每次执行 Minor GC,会将Eden 区和 From区存活对象放到 Survivor的To区(如果To 区内存不够,直接放到 Old区)。
Survivor 区存在意义: 不直接从 Eden区到 Old区的原因是,一些对象虽然一次 Minor GC 没有消灭,但是有可能会在第二次,第三次的时候被清除。这个时候移入 Old 区不是一个明智选择,而且所有的都移入 Old区会导致 Old区很快被塞满。所以 Survivor 的存在意义就是减少送到 Old区的对象,进而减少 Major GC 的发生。Survivor 的预筛选保证,只有经历 16次 Minor GC还能在新生代存活的对象才会被送到老年代。- from 和 to
设置两个 Suvivor区的最大好处就是解决了内存碎片化。我们先假设一下,Survivor 如果只有一个区域会怎样。Minor GC 执行后,Eden 区被清空了,存活的对象放到了 Survivor 区,而之前 Survivor 区中的对象,可能也有一些是需要被清除的。问题来了,这时候我们怎么清除它们?在这种场景下,我们只能标记清除,而我们知道标记清除最大的问题就是内存碎片,在新生代这种经常会消亡的区域,采用标记清除必然会让内存产生严重的碎片化。因为 Survivor 有2个区域,所以每次 Minor GC,会将之前 Eden 区和 From 区中的存活对象复制到 To 区域。第二次 Minor GC 时,From 与 To 职责互换,这时候会将 Eden 区和 To 区中的存活对象再复制到 From 区域,以此反复。
这种机制最大的好处就是,整个过程中,永远有一个 Survivor space 是空的,另一个非空的 Survivor space 是无碎片的。那么,Survivor 为什么不分更多块呢?比方说分成三个、四个、五个?显然,如果 Survivor 区再细分下去,每一块的空间就会比较小,容易导致 Survivor 区满,两块 Survivor 区可能是经过权衡之后的最佳方案。
- from 和 to
- Old 区
老年代占据着2/3的堆内存空间,只有在 Major GC 的时候才会进行清理,每次 GC 都会触发“Stop-The-World”。内存越大,STW 的时间也越长,所以内存也不仅仅是越大就越好。由于复制算法在对象存活率较高的老年代会进行很多次的复制操作,效率很低,所以老年代这里采用的是标记-整理算法。
- 其它直接进入老年代的情况。
- 大对象
大对象指需要大量连续内存空间的对象,这部分对象不管是不是“朝生夕死”,都会直接进到老年代。这样做主要是为了避免在 Eden 区及2个 Survivor 区之间发生大量的内存复制。当你的系统有非常多“朝生夕死”的大对象时,得注意了。 - 长期存活对象
虚拟机给每个对象定义了一个对象年龄(Age)计数器。正常情况下对象会不断的在 Survivor 的 From 区与 To 区之间移动,对象在 Survivor 区中每经历一次 Minor GC,年龄就增加1岁。当年龄增加到15岁时,这时候就会被转移到老年代。当然,这里的15,JVM 也支持进行特殊设置。 - 动态年龄对象
虚拟机并不重视要求对象年龄必须到15岁,才会放入老年区,如果 Survivor 空间中相同年龄所有对象大小的总合大于 Survivor 空间的一半,年龄大于等于该年龄的对象就可以直接进去老年区,无需等待“成年”。
这其实有点类似于负载均衡,轮询是负载均衡的一种,保证每台机器都分得同样的请求。看似很均衡,但每台机的硬件不通,健康状况不同,我们还可以基于每台机接受的请求数,或每台机的响应时间等,来调整我们的负载均衡算法。
- 大对象
文章参考

若有收获,就点个赞吧
0 人点赞
