1 背景介绍
不管你是做什么的,应该听说过云计算这个词。如果你是搞技术的,你应该还听说过云计算的基础技术 - 虚拟化,最起码应该知道vmware虚拟机。如果你是搞云计算的,那么应该也了解过vmware esxi,xen,kvm,OSv,Microsoft hyper-v,Oracle virtualbox,cloudstack,eucalyptus,openstack,vmware vcenter,lxc,docker,kubernetes,hyper,clearcontainer,katacontainer,firecracker, gvisor等不断涌现的新概念、新技术。
以上云计算相关技术大致归为2大类(有些不好归类),
- IaaS(Infrastructure as a Service)
IaaS是面向基础设施(主要是计算,存储,网络、安全四大基础设施)的池化与抽象,提供统一、弹性、可自定义的以VM为中心的资源服务,IaaS给用户提供了清晰的使用、对接接口,对业务和运维基本透明。IaaS在软件层次上主要分为两层,另外还有一些配套的软件基础设施,
- 云管理平台层
上面列的cloudstack,eucalyptus,openstack,vmware vcenter都属于,他们的核心功能就是对整个集群的物理资源进行池化、抽象,然后统一去管理、分配这些资源,在这些资源之上抽象出以VM为中心的各种虚拟资源
- 虚拟化层
上面列的esxi,xen,kvm,hyper-v,virtualbox都属于这一层,他们的核心功能就是在物理机上提供VM。
- 配套软件基础设施
主要是给VM提供的后端网络和存储支持的部分,比如分布式虚拟路由(DVR),分布式/共享存储(例如ceph,OCFS2,glusterfs)等
- PaaS(Platform as a Service)(叫PaaS不知道是否合适)
PaaS主要是面向应用开发、打包、交付、运维、调度、服务编排治理等,利用image机制在应用的打包,交付,部署,升级等运维方面提供了标准化的机制、规范,利用上层的调度编排系统(比如k8s)提供了灵活的调度、扩缩容、服务治理等。从软件层次上来看,PaaS主要也分为两层,上面是调度编排层,比如上面提到的kubernetes,下面就是容器层,比如docker,katacontainer,gvisor等。
另外,PaaS作为一个Platform,或者说作为一个cloud OS,会提供业务开发需要的各种cloud-wide基础服务或者lib,比如业务间通信用的MQ,任务调度系统,各种数据库服务,4/7层负载均衡服务,配置管理服务,日志服务,权限控制服务,各种存储后端,APM服务,计费服务等。普通OS是通过系统调用或者封装后的posix接口提供服务,而PaaS上,可以通过各种标准化的REST/RPC API提供丰富的服务,API是业务与服务间的唯一接口,并且基本会保证API stability,PaaS上提供的服务可以独立演进,而使用它们的业务却不需要去适配。PaaS的目标就是让开发只关注自己的业务逻辑,提高业务开发效率。
PaaS作为一个cloud OS,也面临提供的服务的API标准化的问题,最好能够做成类似SQL这么标准的接口。
2 kvm虚拟化介绍
2.1 虚拟化技术发展历史
提起虚拟化大家首先想到的可能是VMWare,它是现代意义上的虚拟化技术做的比较早的一家公司,但是虚拟化的思想其实很早就有了,比如单处理器上的多任务支持,虚拟内存等,这些是在OS层级直接复用cpu、内存资源,让每个任务都觉得有自己的cpu和内存资源,其实是大家共享的,这时就有了资源的overcommit。资源复用方式一般分为两种,time-sharing和space-sharing/space-mapping,比如cpu、gpu、网卡这些都是time-sharing,虚拟内存属于space-sharing/space-mapping。JVM应该属于应用级的虚拟化技术(不懂java)。话说,计算机技术的发展不就是分层抽象、自下而上的逐层屏蔽(欺骗)嘛。
VMWare这种提供Virtual Machine的虚拟化技术有别于上面提到的OS级的资源复用技术,先贴一个VMWare 虚拟化平台ESXi的框架图
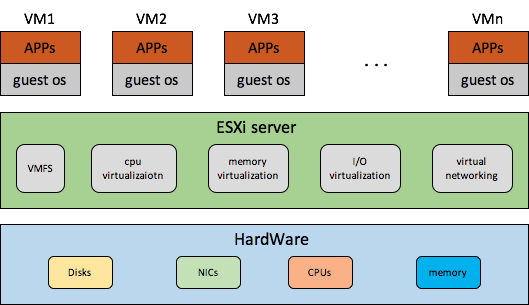
VMWare搞的VM这种虚拟化技术,xen和kvm跟vmware是类似的,都是直接在物理机上跑一个虚拟化的hypervisor/VMM,hypervisor会虚拟出virtual machine,也就是VM,在VM之上再运行OS,也就是guest OS,从guest OS角度来看VM跟普通的物理机并没有什么本质区别(PV下,guest OS还是知道自己运行在VM中的,但是HVM下,技术上已经可以感知不到自己运行在VM中,为了性能上的一些优化,HVM下的guest os也会做些虚拟化相关的适配,比如kvm clock,PVEOI等)。
在VMWare火起来后,后面又出现了xensource搞出来的xen,xen是第一个开源的虚拟化技术,所以很受学术圈待见,并且早期的云厂商的虚拟化平台大都是基于xen的,比如AWS,阿里云,华为云,这应该跟AWS的标杆作用分不开的,AWS开始都是用的XEN。后面kvm逐渐成熟,阿里云、华为云就慢慢往kvm上切了,最终AWS也忍不住开始往kvm切了。借用下xen官网的架构图
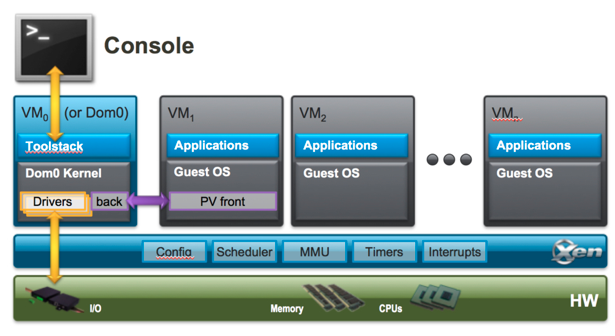
从上图可以看出,xen也是在hardware machine上先跑一个xen hypervisor,xen的特殊之处就是xen hypervisor主要管cpu,内存等硬件,但I/O设备硬件基本还是交给一个特殊的domain(即Dom0)来管,xen上的设备模拟也是靠QEMU去做的,可以说是Dom0+xen hypervisor基本类似vmware的ESXi server。
在介绍kvm之前,先说下xen作为第一个开源的虚拟化平台,为什么会被后来的kvm所赶超。按我的理解主要有以下两方面的原因,
- xen hypervisor另起炉灶,没有背靠强大的linux社区力量
xen hypervisor有自己的社区,独立于linux社区,导致其没法充分利用linux强大的社区力量
- 比较重的虚拟化架构
xen的整个虚拟化功能由Dom0和xen hypervisor构成,其I/O路径是比较长的,上下文切换也比较多,涉及DomU(运行业务的VM),hypervisor和Dom0三者之间的交互,另外,xen的grant-table的操作效率也比kvm的内存共享效率要低(印象中grant-table还有一个大锁问题),event-channel的通知路径(hypercall+virtual interrupt injection)也比较长(生产者-消费者模型下生产者不必每个request都通知消费者,如果判断出消费者还有未处理完pending的request,就不必再发通知),这些都造成了xen的I/O性能相对比较差些。以DomU的收包为例大致展示下Xen的I/O路径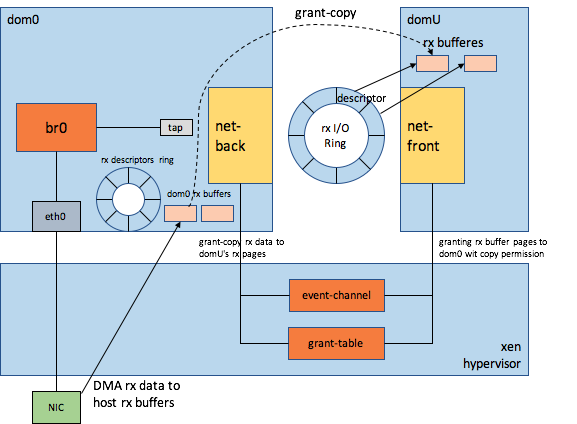
2.2 kvm技术原理介绍
kvm虚拟化平台是我们要介绍的重点,前面已经说过,kvm虚拟化平台是一种类似xen和VMware ESXi的虚拟化平台,通过hypervisor在物理机硬件资源之上提供可定制的VM,然后在VM中跑guest os,业务跑在guest os之上,如下图所示
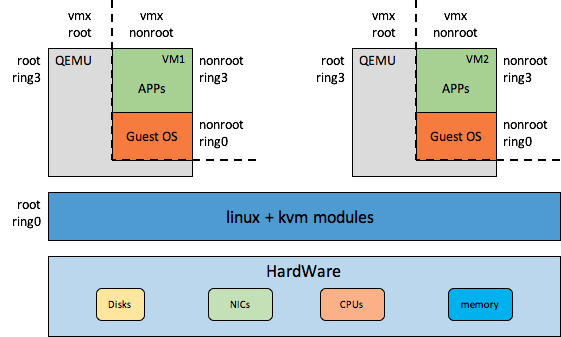
上图中虽然只画了2个VM,其实是可以虚拟出很多VM的,具体数量取决于物理机硬件配置以及VM配置规格。
kvm虚拟化平台加上云管理平台,比如openstack,可以提供以下大家常提到的一些好处,
- 通过提供虚拟机粒度的隔离部署环境及集群规模的动态负载均衡,可以提高硬件资源使用率,降低采购成本
- 对cpu,内存,存储,网络等资源做了更细粒度的灵活划分,提高资源利用率
- 通过提供统一的资源管理、调度、配置,降低客户的部署、维护成本
- 快速交付,快速的响应客户的新增机器需求
- 提供虚拟CPU、内存、磁盘、网卡热插拔功能,可以快速响应客户已部署业务对计算、网络、存储服务能力的扩展需求
- 基于共享存储,提供虚拟机HA能力,一旦虚拟机所在的物理机出现故障,可以在其他物理机上秒级恢复上面的虚拟机
- 提供虚拟机热迁移功能,可以提高客户业务的可服务性,降低客户业务的downtime,例如需要硬件维护时,并不会中断该服务器上业务,可以把上面的虚拟机迁移到另一台服务器上。如果使用了共享存储(比如ceph)还可以大大缩短迁移的总时间,如果使用了overlay网络,可以在IDC内部,甚至在IDC之间迁移虚拟机。
- 提供虚拟机镜像机制,方便一个部署到镜像中的业务或者业务组合,一次部署到处运行,也可以提供公共的基础镜像
- 提供对业务透明的虚拟存储备份功能,大大提高客户数据的可靠性
- 提供更加灵活地运维手段,提高运维自动化水平
- 利用overlay跟物理网络解耦,业务网络的规划可以不必考虑物理网络组网,尤其是网络拓扑的限制
下面介绍下kvm的一些基本的技术原理,先看下官方的(kvm框架图)[https://wiki.qemu.org/Documentation/Architecture],如下所示
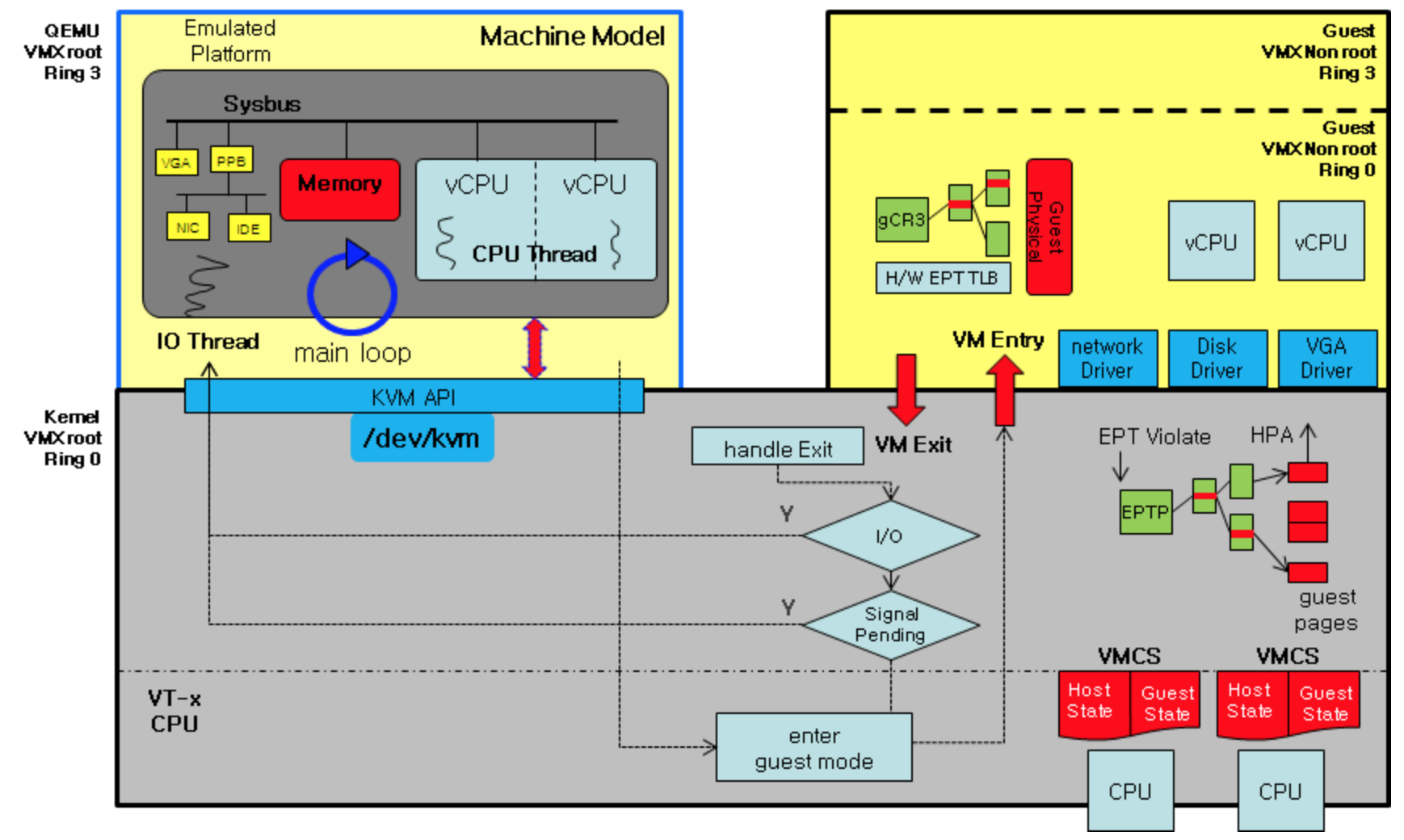
下面详细的介绍上图中的各个部分,
2.2.1 CPU
上图中关于cpu虚拟化主要涉及两部分,一部分是通过vcpu线程在不同空间/上下文的切换来给guest os提供cpu计算能力以及服务Guest OS中的一部分请求;另一部分是是通过cpu硬件虚拟化能力(VT-x,上图中的VMCS是相应的控制结构)使cpu在root模式(host模式)和non-root模式(guest模式)之间高效的切换,并可以精确控制cpu在guest模式下的一些行为。
下图介绍了vcpu线程的初始化,以及vcpu在不同空间/上下文的执行flow,
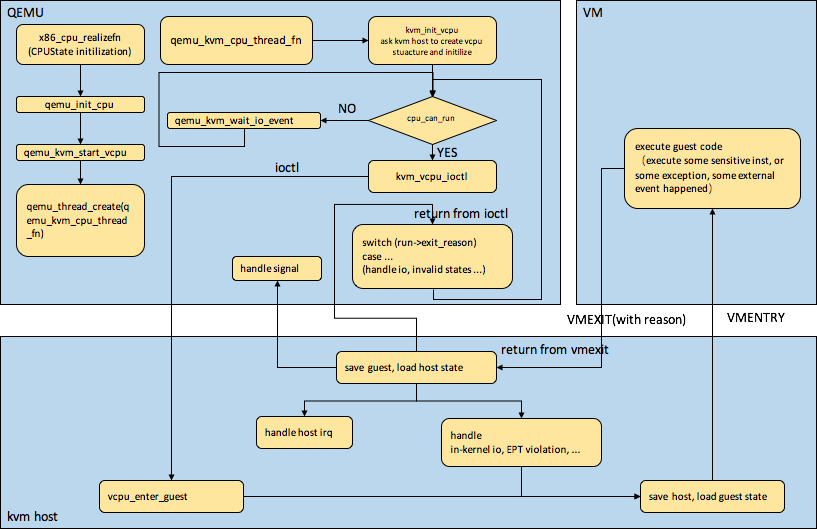
vcpu线程及vcpu初始化
在创建虚拟机时,qemu模拟了vcpu以供bios、guestos感知到,但是vcpu毕竟只是模拟的一个数据结构,但是如何通过vcpu给guest提供真正的物理机cpu的计算能力,这个是通过vcpu线程来做到的。在创建虚拟机时,qemu根据配置的虚拟cpu个数,给每个虚拟cpu创建一个vcpu线程,vcpu线程在执行时会先做一些初始化工作,比如请求内核中的kvm模块创建vcpu结构体并做一些相关的初始化工作。
下图展示了vcpu,vcpu线程,物理cpu,host中普通线程,guest中线程之间的大致关系
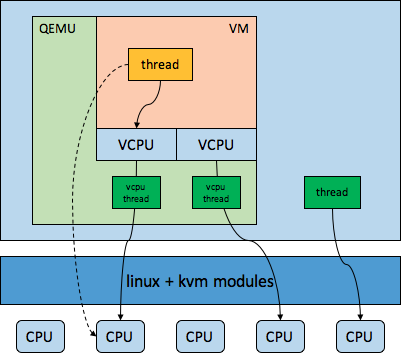
hypervisor通过vcpu线程占用了物理cpu,vcpu线程通过执行vmlaunch/vmresume指令将物理cpu切换到了noonroot模式给guest用,所以从hypervisor的角度来看,guest中的cpu开销都会算到vcpu线程身上。在guest中,看到(或者说discover)的是vcpu,但是实际使用的还是物理cpu,guest中的线程看起来是跑在vcpu上,实际还是跑在物理cpu上。如果guest中执行了某些敏感指令或者发生了某些异常或者某些外部事件,会导致处于noonroot模式的物理CPU发生vmexit,返回到root模式(host空间),将物理cpu再交给host用。就是说物理cpu既会给host提供计算服务也会给guest提供计算服务,但是host和guest不会同时使用同一个物理cpu,物理cpu通过vmentry/vmexit来完成不同空间(vmx root和vmx nonroot)的切换以分时服务host和guest。
vcpu线程的执行flow
在完成vcpu的初始化之后,vcpu线程通过IOCTL系统调用陷入到内核态,这时候就会执行kvm模块中的相关代码,比如vmlaunch/vmresume代码,这时vcpu线程所在的物理cpu就会从root模式切换到noonroot模式,然后初始化或者恢复之前noonroot模式的上下文,noonroot模式的cpu就可以给guest提供用服务,可以执行guest中系统启动代码,也可以执行普通线程代码等,但是从hypervisor的角度,不管执行guest中什么代码,处于noonroot模式的cpu开销都会算到相应的vcpu线程上。在guest中执行了某些敏感指令或者产生某些异常或者外部事件时(比如EPT violation)就会产生VMEXIT(是否产生VMEXIT大都是可控制的,后面会介绍到),物理cpu从noonroot模式切换到root模式,然后恢复前面进入noonroot模式前的上下文(host上下文中要恢复的数据中很大部分是固定的),hypervisor会检查产生VMEXIT的原因,如果自己可以处理,那么在自己处理好之后可以继续执行vmentry切换到noonroot模式,如果自己处理不了,就会判断是否需要交给其他内核组件处理(比如vhost_net) ,如果内核部分都处理不了,那么就会返回之前的IOCTL系统调用到QEMU上下文,QEMU会进一步判断exit_reason,然后做相应的处理,处理完了之后继续执行IOCTL系统调用陷入到内核中的kvm模块。vcpu线程就是在这样的循环中反反复复,直至死去。
vcpu的上下文切换
从上面的vcpu线程的执行flow来看,涉及两类上下切换,一类是QEMU用户进程和host kernel之间,一类是host kernel和guest之间。
- QEMU和host kernel之间
这类上下文切换就是普通的系统调用/返回切换
- host kernel和guest之间(此章节严重依赖intel x86开发手册中的VMX部分,感兴趣的可以直接看intel手册)
这类上下文切换涉及cpu的root模式和nonroot模式切换,它是靠cpu的VT-x特性(这里是针对intel x86来说的)来完成的,intel的VT-x(VMX)特性中关于cpu硬件辅助虚拟化这块有一个重要的控制结构就是VMCS(Virtual Machine Control Structure),VMCS有4KB大小,每个vcpu对应一个VMCS,当vcpu得到调度时,其对应的VMCS的64位物理地址就会被load到该vcpu所要运行的物理cpu(官方叫做logical processor)的VMCS pointer中,每个物理cpu下一般会有多个处于actvie状态的VMCS,这就跟每个cpu的runq中有多个待调度的线程是一样的。所以物理cpu,vmcs,vcpu的对应关系如下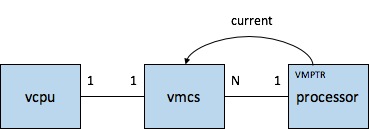
vcpu线程像普通的linux线程一样,是可以不在不同的processor之间迁移的。
VMCS结构如下所示(来自intel开发手册)
其中重点是data部分,包含6个区域,
从上面上各个区域的解释,大致就可以理解vmx如何通过VMCS来控制cpu在root模式(host kernel)和nonroot模式(guest)之间切换的,guest-state area主要用于做guest空间上下文的save/restore,host-state area主要用户做host空间上下文的save/restore,当发生VMEXIT时,就会将当前guest空间的上下文保存到guest-state area,然后从host-state area读出之前保存的上下文数据进行恢复host空间的上下文,反之亦然,注意这里的上下文切换比系统调用的上下文切换保存/恢复的内容要多,开销也更大。vm-execution control fields主要用来精确的控制cpu处于noonroot模式时的行为,来设置哪些行为或者事件会导致vmexit,这对hypervisor来控制vcpu的行为非常重要,vm-execution control area支持非常多的自定义配置,我们平常可能会修改的一般都是这个区域的配置,比如I/O bitmap, Exception bitmap, MSR bitmap, PLE, PML,APICV相关配置等。vm-exit control fields和vm-entry control fileds主要控制在执行vmexit/vmentry后要做哪些事情,主要是哪些数据要保存,哪些数据要恢复,vmentry control fileds可以配置在最后阶段deliver虚拟中断的一些配置。vm-exit information fileds主要用户保存vmexit产生的一些信息,hypervisor会利用这些信息根据不同的vmexit原因做相应的处理。
2.2.2 memory
在kvm中,虚拟机cpu和内存资源的分配与使用,从host os的角度来看,都是算到QEMU进程中的,比如前面提到的vcpu的使用是统计到QEMU的vcpu线程处于nonroot上下文时的开销,虚拟机的内存完全是通过QEMU进程申请的,所以虚拟机内存开销也是统计到QEMU中的。
下图通过以下三个方面介绍下kvm的内存虚拟化
QEMU中虚拟机内存管理
下图显示了在QEMU中针对Guest内存的三种管理视角以及他们之间的关系(借用了Stefan Hajnoczi的图),
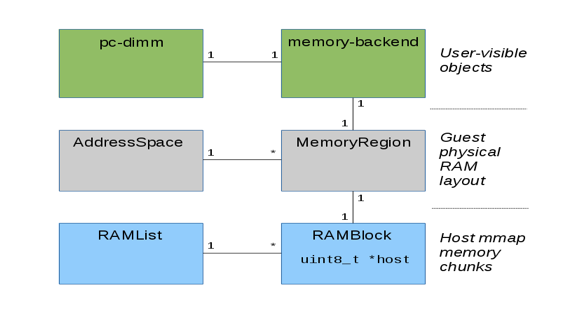
- 一个是针对用户配置的,就是使用qemu 命令行配置的,一个DIMM可以认为是一个内存条,插在虚拟的slot中,支持插拔等操作(其实VM的initial memory也可以不配置成pc-dimm),跟物理机上的内存条是类似的。在qemu中会有一个memory-backend跟虚拟DIMM对应,该backend就是用来承载DIMM对应的实际内存的,可以是匿名映射也可以是file-backed映射,比如backend可以是一个tmpfs file。如果memory-backend使用file-backed内存映射,那么可以通过它
- 使用hugetlbfs大页内存,只要这个backend file是在hugetlbfs中的即可
- 在VM间,或者VM与host间做共享内存,这个很有用,比如可以用于DPDK与QEMU之间共享内存,也可以利用本地热迁移(bypass shared-memory)做qemu的in-place热升级,如下图所示,
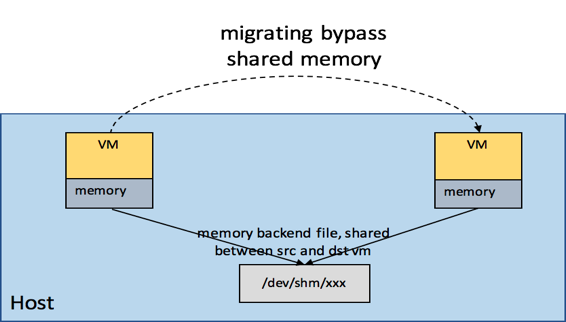
相比使用普通热迁移做qemu热升级,使用基于bypass共享内存的in-place热升级有以下好处
* 迁移非常快,因为不需要迁移内存了* 中断时间非常短,几十ms级* 不需要给轮转升级预留资源了,节省了成本,针对小规模的集群,有时是找不到空闲的资源轮转升级的* 没有额外的网络带宽开销,因为不用传输数据了,另外cpu开销也非常小
- 一种在qemu中给虚拟机内存申请的内存块的管理
这里说的ramblock,其实就是用来管理上面memory backend对应的mmap内存的,通过一个ramlist把所有的ramblock管理起来
- 一种是连接guest物理地址空间和qemu中的虚拟地址空间
guest物理地址空间包含一系列的memory region,如果memory region是一快RAM region,那么该memory region就会对应一个ramblock,memory region是用来连接guest物理地址空间和QEMU中对应的ramblock维护的虚拟地址快。memory region和ramblock之间是紧密相连,可以互相访问。
注:memory region是QEMU中对guest的内存管理的一种通用机制,不光用来管理普通的内存,还用来管理设备的MMIO空间
虚拟机物理内存的的layout是连续的,也就是说GPA肯定都是连续的,这跟我们的物理机是类似的,在QEMU中每个guest memory region(RAM region)对应一块ramblock,这个ramblock是qemu的虚拟内存(HVA),如果guest有多块memroy region,对应的ramblock的虚拟地址快之间就不是连续的了,如下图所示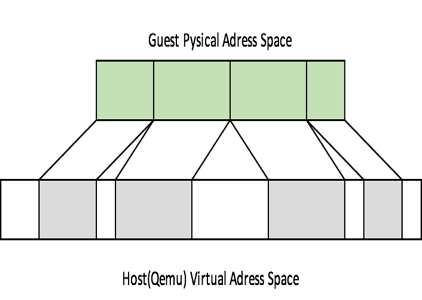
注:上图不是严格准确的,因为GPA中还有reserved空间,MMIO空间等,但是不影响我们理解guest physical memory跟QEMU对应的HVA之间的关系
页表建立(EPT)
QEMU在给虚拟机申请好memory region后,会将对应的region注册到内核kvm中的memslots,memslots的结构如下图所示
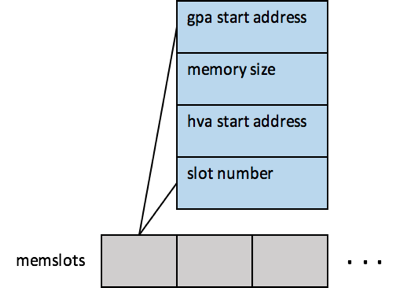
每个VM的memslots中可能会有多个slot,每个slot中记录了该slot中gpa和hva的对应关系,以及memory size,后面当产生EPT violation时会使用memslots中的信息建立EPT页表,EPT页表的建立过程如下图所示
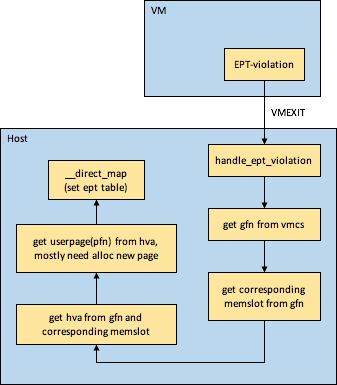
上图中的memslot就上前面讲到的把memory region信息注册到内核kvm中的memslot。
页表translation
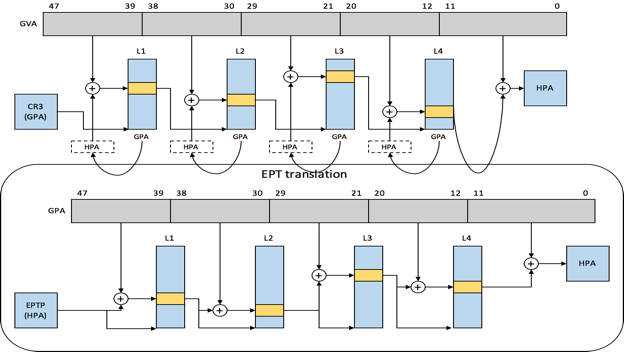
kvm的页表有两种,一种是影子页表,一种是借助硬件实现的EPT。
- 影子页表(shadow pagetable)
影子页表是直接从GVA=>HPA,但是很少在生产环境中使用,因为
- hypervisor中会给guest中的每个进程都维护一个页表,有一定的内存开销,维护比较麻烦- 每次页表更新和进程切换都会导致VMEXIT(因为guest os中的pagetable被设置了write-protected),然后由hypervisor来完成shadow pagetable的更新或者切换。由此带来的VMEXIT的开销是比较大的,对性能会造成一定的冲击
- EPT
生产环境中一般都会使用EPT,那么guest中的内存访问就会由两维页表负责整个address translation流程,其中GVA=》GPA的translation由primary MMU来完成,GPA=》HPA的translation由EPT(secondary MMU)来完成,各司其职,边界非常清晰。下图显示了在guest中访问一个变量(即symbol)时,从guest中的虚拟地址到最终的目标物理内存地址的整个translation过程,
2.2.3 virtio framework
kvm使用的virtio和xen上使用的PV drivers都是类似的,都属于para-virtualized I/O。para-virtualized I/O是相对Full-virtualized I/O而讲,比如QEMU模拟的E1000网卡,IDE磁盘就属于full-virtualization,full-virtualized I/O的坏处就是性能差,通信效率低,原因在于full-virtualizad device的datapath上经常会访问设备register,导致过多的vmexit,双向通知没有利用生产者-消费者模型中常用的按需通知导致太多VMEXIT和中断注入,另外就是一些高级特性支持上可能比较弱。
Para-virtualized I/O就是专门为虚拟化而生的,在提高数据传输效率,降低per-I/O开销,以及新特性(比如网卡的某些高级offloading特性,也有些新特性可能是物理世界没有的)支持,稳定性方面都做了增强。
virtio涉及前端部分(guest driver)和后端部分(qemu),大致示意图如下所示
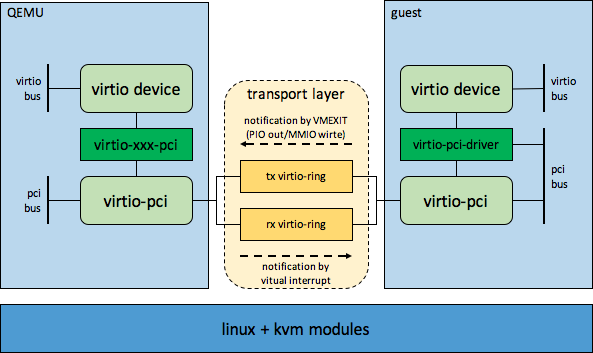
在上图中主要包括两部分的内容,一是virtio设备模型,一个是前后端通信机制(包括数据传递和通知),下面分别介绍下
virtio设备模型
virtio设备模型又分为两部分,一部分是qemu侧的设备模拟,一部分是guest侧的设备驱动。
- qemu virtio设备模拟
qemu侧的模拟的virtio设备,可以类比为一个物理服务器上的IO设备。virtio设备的模拟有两条线,一条是pci设备模拟线,一条是virtio设备模拟线,他们两个之间是通过virtio-xxx-pci设备类型连接起来,这里的virtio-xxx-pci就是virtio-net-pci,virtio-blk-pci,virtio-serial-pci之类的。
在介绍virtio设备模型前先介绍下QEMU QOM(QEMU Object Model),因为它是qemu中设备模拟的基本模型,QOM的组织模型跟面向对象的类型继承模型是类似的。QOM中对象的初始化主要包含以下4个步骤
- type的注册和初始化
每个type的root都是TYPE_OBJECT,type会使用module_init macro的wrapper(例如,type_init, block_init , opts_init, trace_init)来注册,先看下module_init的实现
/* This should not be used directly. Use block_init etc. instead. */#define module_init(function, type) \static void __attribute__((constructor)) do_qemu_init_ ## function(void) \{ \register_module_init(function, type); \}typedef enum {MODULE_INIT_BLOCK,MODULE_INIT_OPTS,MODULE_INIT_QOM,MODULE_INIT_TRACE,MODULE_INIT_MAX} module_init_type;#define block_init(function) module_init(function, MODULE_INIT_BLOCK)#define opts_init(function) module_init(function, MODULE_INIT_OPTS)#define type_init(function) module_init(function, MODULE_INIT_QOM)#define trace_init(function) module_init(function, MODULE_INIT_TRACE)
- 上面的gcc attribute “constructor”说明该函数会再QEMU进程的main函数之前执行。下面再来说下上面的function,以下pvpanic type为例,
static TypeInfo pvpanic_isa_info = {.name = TYPE_ISA_PVPANIC_DEVICE,.parent = TYPE_ISA_DEVICE,.instance_size = sizeof(PVPanicState),.instance_init = pvpanic_isa_initfn,.class_init = pvpanic_isa_class_init,};static void pvpanic_register_types(void){type_register_static(&pvpanic_isa_info);}type_init(pvpanic_register_types)
- 可以看出上面的function是type_register_static(或者type_register)的wrapper。那么前面register_module_init需要的两个参数function和type就清楚了,register_module_init其实就是把function和type作为一个module entry注册到以type分类的module list中。
在main函数开头处会之间或者间接调用module_call_init来分type注册调用之前注册的type的register function,我们看下通用的register type function的核心函数type_register_internal的实现
static TypeImpl *type_register_internal(const TypeInfo *info){TypeImpl *ti;ti = type_new(info);type_table_add(ti);return ti;}
- 可以看出是根据type info生成了type implementation,并做了一些初始化,然后添加到type hash表中- type class的初始化
在main函数中下面的代码会开始各个device的初始化,
if (qemu_opts_foreach(qemu_find_opts("device"),device_init_func, NULL, NULL)) {exit(1);}
- 在device_init_func函数中会调用qdev_device_add函数进行设备模拟,首先会进行创建并初始化相应的object。首先会调用qdev_get_device_class->object_class_by_name->type_initialize 递归的找到parent type的class逐级进行初始化,说白了就是把type对应的class进行定义,其中会注册realize callback。
每个type的class都会被直接或者间接(继承它的type的class初始化的时候回向上递归初始化继承的type的class)的初始化,并且只初始化一次,可以理解为一个type对应一个class实例,该class实例中更多的是该type公共部分的初始化,比如一种类型的pci设备的vendor id,device id。class通过结构体的首成员包含来模拟继承关系,比如TYPE_OBJECT对应的ObjectClass是基类,TYPE_DEVICE对应的DeviceClass继承了ObjectClass,其结构体首成员是ObjectClass,TYPE_PCI_DEVICE对应的PCIDeviceClass继承了DeviceClass,其结构体首成员是DeviceClass,TYPE_VIRTIO_PCI对应的VirtioPCIClass继承了PCIDeviceClass。如果该type没有配置class_size,则使用的就是其parent class。
- type instance的初始化
在初始化了class后,则会调用object_new(或者其变体)函数对object instance进行初始化,instance初始化也是按照type的继承关系递归的找到parent type的instance init函数逐个初始化,各个type对应的instance的结构体也是通过结构体首成员包含parent type结构体的方式继承的。每个type是可以有很多instance实例的。其中virtio-xxx-pci type的instance结构体比较有特点,它一头包含了virtio-pci type的instance结构体,一头包含了virtio-xxx type的instance的结构体,它是名副其实的link virito-pci和virtio-xxx。在instance init函数中可能还会使用到前面初始化的class信息。virtio-xxx-pci的instance init函数很特殊,他会调用virtio_instance_init_common(TYPE_VIRTIO_xxx)来初始化virito_xxx object。
从virtio-xxx-pci的instance结构体和instance init函数就可以知道它是virtio设备模型中pci设备和virito设备的中间桥梁。
- 添加、设置property
属性分为object属性和objectclass属性,也有各自相应的添加接口。有一个比较特殊的属性就是realize,在device_type_info的instance_init函数(device_initfn)中会添加realized属性,并且将DeviceState中的realized flag设置为false。
class init和instance init主要是做class简单初始化以及instance的创建和简单初始化,真正的设备逻辑功能的初始化是在realize时做的,realize可以认为是object的constructor。
在完成class init和instance init之后,一个object基本就初始化完成了,后面就会对前面创建的object进行realize,在qdev_device_add函数中,在object_new之后,就是set properties,其中一个就是set realized property为true,这时就会执行相应的realize函数。
下面以virito-net-pci为例介绍下virito设备的大致模拟流程,先看下virito-net的两条类型继承关系线,
TYPE_OBJECT => TYPE_DEVICE => TYPE_VIRTIO_DEVICE => TYPE_VIRTIO_NET
TYPE_OBJECT => TYPE_DEVICE => TYPE_PCI_DEVICE => TYPE_VIRTIO_PCI => TYPE_VIRTIO_NET_PCI
上面两条继承关系的关键节点就在TYPE_VIRTIO_NET_PCI。
我们在创建虚拟机时,指定的网卡参数一般如下所示
-netdev tap,fd=23,id=hostnet0,vhost=on,vhostfd=24 \
-device virtio-net-pci,netdev=hostnet0,id=net0,mac=52:54:00:30:7a:7e,bus=pci.0,addr=0x3
其中的-netdev tap,…,是跟tap相关的配置,跟virtio网卡模拟没有关系。我们重点关注-device virtio-net-pci,…
上面的virtio-net-pci对应的就是TYPE_VIRTIO_NET_PCI,在对其进行初始化时会递归的从TYPE_OBJECT开始一直初始化到TYPE_VIRTIO_NET_PCI,会创建一个挂在pci-bus的virtio-pci设备,在调用TYPE_VIRTIO_NET_PCI的instance_init函数时会对TYPE_VIRTIO_NET进行初始化,最终会创建一个挂载virtio-bus上的virtio-net设备。
- guest virtio驱动框架
guest os中virtio相关的bus-device-driver之间的关系如下图所示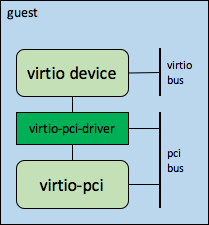
上图分为几个部分:virtio-bus的注册,virtio-pci设备的probe,virtio设备的生成与注册,以下分别介绍下
- virtio-bus的注册
virtio-bus是在guestos启动时作为一个core_initcall注册的,代码如下所示
static int virtio_init(void){if (bus_register(&virtio_bus) != 0)panic("virtio bus registration failed");return 0;}static void __exit virtio_exit(void){bus_unregister(&virtio_bus);}core_initcall(virtio_init);module_exit(virtio_exit);
- virtio-pci设备驱动
virito-pci驱动在virito驱动框架中处于承上启下的作用,前面在讲qemu侧的virtio设备模型中提到virtio设备首先是一个pci设备,从BIOS/OS discover的角度来看也是一个PCI设备,在qemu侧模拟的所有virtio-pci设备时设置的vendor ID都是PCI_VENDOR_ID_REDHAT_QUMRANET。virtio-pci驱动的ID table如下所示
/* Qumranet donated their vendor ID for devices 0x1000 thru 0x10FF. */static const struct pci_device_id virtio_pci_id_table[] = {{ PCI_DEVICE(PCI_VENDOR_ID_REDHAT_QUMRANET, PCI_ANY_ID) },{ 0 }};
- 所以说virtio-pci驱动正好可以驱动所有的virito-pci设备。所以当guest os发现virito-pci设备并注册到内核中的pci总线上后,virtio-pci驱动就会对其进行驱动(如果virtio-pci驱动还没有注册到pci总线上,在将virtio-pci设备注册到pci-bus总线上时会通过uevent通知udevd加载virtio-pci驱动)。
virtio-pci驱动会生成一个virtio_pci_device,它也是pci设备和virtio设备的结合体。在对virtio-pci设备中的virtio设备进行初始化时,会将virtio设备的device id设置成virito-pci设备的Subsystem Device ID(legacy)或者device id - 0x1040,无论使用哪种方式结果是一样的,得到的各个virtio设备的device id从1开始,比如virtio-net的是1,virtio-blk是2,这些都是QEMU和virtio设备驱动事先约定好的,如下所示
#define VIRTIO_ID_NET 1 /* virtio net */#define VIRTIO_ID_BLOCK 2 /* virtio block */#define VIRTIO_ID_CONSOLE 3 /* virtio console */#define VIRTIO_ID_RNG 4 /* virtio rng */#define VIRTIO_ID_BALLOON 5 /* virtio balloon */#define VIRTIO_ID_RPMSG 7 /* virtio remote processor messaging */#define VIRTIO_ID_SCSI 8 /* virtio scsi */#define VIRTIO_ID_9P 9 /* 9p virtio console */#define VIRTIO_ID_RPROC_SERIAL 11 /* virtio remoteproc serial link */#define VIRTIO_ID_CAIF 12 /* Virtio caif */#define VIRTIO_ID_GPU 16 /* virtio GPU */#define VIRTIO_ID_INPUT 18 /* virtio input */#define VIRTIO_ID_VSOCK 19 /* virtio vsock transport */
- 在QEMU侧,也会把virito device realize时设置的device id加上0x1040设置到相应的virtio-pci device的device id中。
在virtio-pci驱动设置好virtio_pci_device下的virtio_device后会将注册到virtio-bus上,那么根据上面设置的virtio_device的device id就会匹配相应的virtio-xxx设备驱动,virtio-xxx驱动的id table只匹配device id。
前后端通信机制(transport layer)
一般情况下,通信主要包含三个要素,媒介(通道),控制,协议,其中媒介和控制是基础,协议建立在两者之上。virtio框架主要实现了通道和控制,协议主要跟virtio设备类型有关了,比如virtio-net实现的是二层数据包的传递。
- 控制
这里说的控制是简化的,主要包括通道建立/销毁的协商,以及平时通信用的双向通知。这里我们主要关注平常通信用的双向通知(这里不考虑polling)。
- guest to host notification
guest通知host只有一种手段就是VMEXIT(当然你可以实现一些暴力的通知手段,不需要VMEXIT,比如把物理CPU的LAPIC page通过qemu map到guest地址空间,guest直接通过ICR发物理IPI),可以主动产生VMEXIT的手段很多,virtio设备使用的PIO out或者MMIO write。在x86体系结构下,有两种地址空间,即内存地址空间和port io地址空间,他们是两套独立的空间。在64位系统上,内存地址空间主要是指52位物理地址空间以及48位虚拟地址之间,虚拟地址空间可以map到物理地址空间,内存地址空间的一个很大的特点就是支持read/write,支持map;port io地址空间独立于内存地址空间,有64KB大小,它是通过in/out指令进行访问,不支持map,也就没有虚拟地址这些概念。PCI设备主要对外提供两部分访问空间,配置空间和6个BAR空间,BAR既支持像内存那种访问方式,即MMIO,也支持port io方式访问,即PIO。virtio设备作为一个pci设备,就是使用某个BAR的MMIO write或者pio out主动产生VMEXIT来通知后端。
前面在讲利用VMX实现guest空间和host空间的上下文切换时,讲到了VMCS的vm-execution control area,其中有一个I/O bitmap可以设置,这里的I/O指的就是port io,I/O bitmap结合Primary Processor-Based VM-Execution Controls中的”Use I/O bitmaps” control bit,可以指定哪些port地址的in/out会导致VMEXIT,哪些不会。
- host to guest notification
host通知guest也只有一种手段,那就是虚拟中断注入。
- 通道
virtio前后端通信用的通道是共享内存,由guest os驱动virtio pci设备时提供给后端以及平常传递payload时提供给后端。由于整个VM的物理内存都是QEMU给申请的,所以在VM和QEMU之间做共享内存是比较简单的(比xen上要简单,xen上还需要grant-map),而qemu/kvm module中本来就保存了虚拟机物理地址和qemu虚拟地址之间的映射关系,而且guest的virtio设备驱动传递给后端的共享内存地址也是GPA。前后端通信用的共享内存有两种
- 用于传递metadata和额外管理用的共享内存
这里就是指vring,是在guest os驱动virtio pci设备时提供给后端的,这种共享内存是长久存在的,生命周期跟虚拟设备一样长(除了个别支持动态修改queue个数,或者重新驱动)。vring主要包含3部分,descriptor ring,available ring,used ring,其中descriptor ring是核心,available ring和used ring用来辅助管理descriptor ring,前后端和三者之间的关系如下所示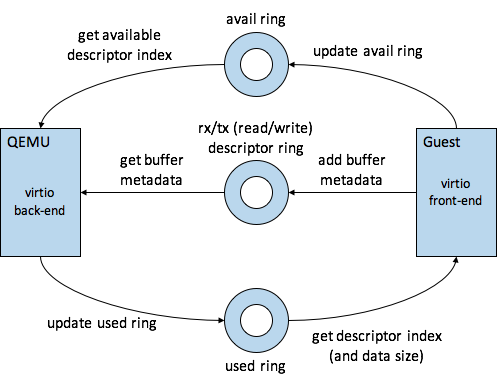
从上图中可以看出,前端(guest)生产buffer,并把buffer的medata放到descriptor ring中,然后更新avail ring提示后端哪些是新产生的desriptor,后端从descriptor ring取出descriptor进行解析,然后做相关处理,处理好了好后,将已经消费的descriptor的index更新到used ring中。
* descriptor ring
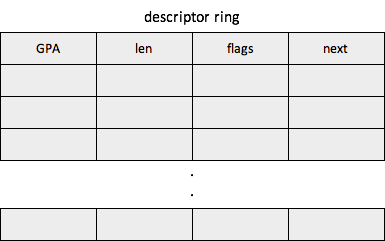
descriptor ring里面维护的是descriptors,每个descriptor有4个字段,
* gpa
主要用来描述要发送或者接受数据的元数据,主要有要发送数据的所在内存的GPA或者用来接收数据的内存的GPA,
* 内存大小* flags
flags的含义比较多,具体要看其定义
* next
下一个未使用的descriptor,要跟flags结合使用
- available ring

guest使用available ring告诉host,descriptor ring中哪些descriptor可以消费了,上面的flags主要用于优化,比如interrupt coalescing。
- used ring

host使用used ring告诉guest,descriptor ring中哪些descriptor已经被消费了,上面的flags也主要用于优化,比如guest可以压缩virtqueue_notify,即guest再添加buffer到available ring时可以不用kick host。
- 传递payload用的共享内存
这里是指平常通信时,前端发送(写)数据所在的内存或者前端接受(读)数据所用的内存,这种共享内存是动态产生、释放的,这些内存的GPA地址和大小(metadata信息)是在上面的vring中传递的。即使后端是vhost,也没问题,因为vhost线程会use_mm(qemu->mm)。
常用的virtio设备主要有virtio-net,virtio-blk,virtio-scsi,virtio-vsock,virtio-console,virtio-balloon,virtio-gpu等。
2.2.4 network
网络部分主要分为前后端网卡I/O相关的虚拟化(virtio-net)和虚拟化网络两部分。
virito-net
在上面介绍了virito framework后,其实virtio设备虚拟化的前后端部分就不用再详细介绍了,对virtio-net来说,主要是增加了在virito-pci之上的二层数据包的传递,前后端之间解包、组包。下面要介绍的是后端部分的处理,针对virtio-net来说,后端部分目前主要有三种处理方式
- virtio-net in qemu
这种方式的性能比较差,因为
- 双向通知的路径要稍长些- 发包时要多一次copy from user(qemu to kernel),收包时要多一次copy to user(kernel to qemu)
生产环境中一般不会使用这种方式。
- vhost-net
这个是对virtio-net in qemu的优化,把后端的收发包datapath放到kernel中,由vhost线程来做,控制面仍然放在qemu中做。这样就没有了上面的copy from/to user(qemu),并且通知路径也稍微短些。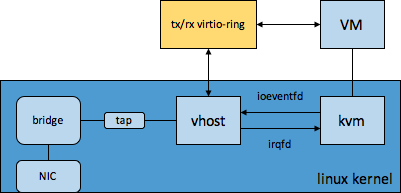
vhost-net的实现主要包含两部分,一部分是vhost,这部分实现了公用的vhost机制(vhost-scsi也会使用vhost机制),另一部分是vhost_net,这部分是跟网络相关的处理。
vhost_net甚至可以跟SRIOV结合,VF驱动alloc的rx buffer不使用标准接口,而是直接向vhost_net申请,vhost_net从vring中获取rx buffer,然后地址转换后交给VF驱动。收包时由于二层交换提前在SRIOV设备中做了,所以可以知道最终DMA到哪个VM,这么做就可以实现rx zero-copy。
- vhost-user
没有分析过vhost-user的代码,它主要是跟用户态vswitch对接的,比如DPDK、snabbswitch。
network virtualization
虚拟化网络包含的东西比较多,总体来说包含vswitch,overlay,vrouter,controller几部分。
- vswtich
- linux bridge
linux bridge可以说是功能最简单的二层vswitch,主要实现了基于mac-learning的mac-port转发。用一句话来概括linux bridge:源mac学习,目的mac转发,找不到就flood。下图是使用linux bridge时的一种典型的组网图,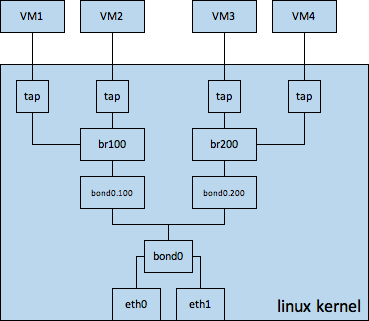
- macvtap
为了便于说明,先区分几个概念,macvlan指macvlan软交换机制,macvlan device指在macvlan软交换中创建出来的逻辑网络设备,macvtap指的是macvtap软交换机制,注意没有macvtap device。
macvtap的核心还是macvlan,只是在每个macvlan device之上接了一个tap char device,这样macvlan收到的包就不用deliver到网络协议栈了,可以通过tap char device把包交给qemu或者vhost,qemu和vhost也可以通过tap char device将包发给macvlan,macvtap的network device还是macvlan。
macvtap/macvlan支持以下几种模式,
* bridge
这是macvlan最常用的模式,实现的最终功能跟linux bridge是类似的,只是macvlan/macvtap不需要mac-learning。
先看一下macvlan的转发逻辑图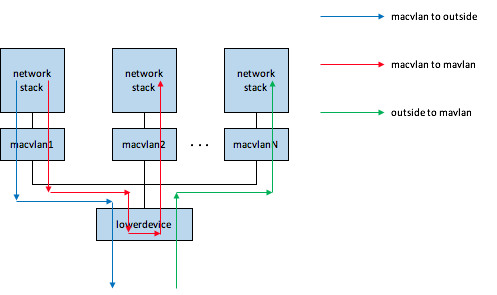
在上图中,lowerdevice就是可以对外通信的网络设备,一般是物理网卡,或者enslave 物理网卡的bond,或者直接/间接建立在物理网卡之上的vlan device。
macvlan device和lowerdevice的地位完全不同,macvlan device是在lowerdevice之上。macvlan中维护了所有macvlan device的mac hash,不需要动态学习,只有在创建/删除macvlan、修改macvlan mac地址时才会修改该mac hash表。下面介绍下上图中几种流程
+ outside to macvlan
当基于某一lowerdevice创建第一个macvlan时,会在lowerdevice上创建一个macvlan-port,这个主要用于管理,比如macvlan mac hash表,macvlan device个数之类的。在创建macvlan-port的同时,会在lowerdevice上注册一个rx handler,如下所示
err = netdev_rx_handler_register(dev, macvlan_handle_frame, port);
rx handler机制是linux中network device收包redirection的一个通用机制,比如linux bridge,bond,macvtap都是使用这种机制。
当外部进来的包到达lowerdevice后,最终会调用netif_receive_skb的核心处理函数netif_receive_skb_core,在这个函数中会获取之前注册的rx-handler(即macvlan_handle_frame),在该函数中会基于包的目的mac查询macvlan-port中维护的mac hash表,把匹配的macvlan device的netdev设置为skb的device,相当于包到达了macvlan device了,然后进入another_round(差不多相当于再走一遍netif_receive_skb_core)。
从上面流程可以看到,收包流程中涉及的macvlan软交换非常简单,就是查找macvlan-port维护的mac hash表。
+ macvlan to macvlan
当上面来的包(可能来自应用,也可能来自macvtap)到达macvlan,macvlan会判断目的mac是否可以在mac hash中找到,如果可以就将包的device修改为lowerdevice,然后走lowerdevice的收包流程,整个流程就跟“outside to macvlan”中介绍的流程是基本一样的。
+ macvlan to outside
当上面来的包(来自于应用,也可能来自macvtap)到达macvlan,macvlan会判断目的mac是否可以在mac hash中找到,如果找不到,就直接修改skb->dev为lowerdevice,然后通过lowerdevice将包发出去。
macvlan device是没办法直接跟lowerdevice通信的(这一点跟linux bridge不太一样),在使用macvlan机制的情况下,如果container或者VM想跟host通信,就需要在同一个lowerdevice上再创建一个macvlan device给host用,这样就可以通信了。
macvlan适用于container场景,因为macvlan是可以直接给OS的网络协议栈对接的,可以把macvlan device set到container的namespace中,如下图所示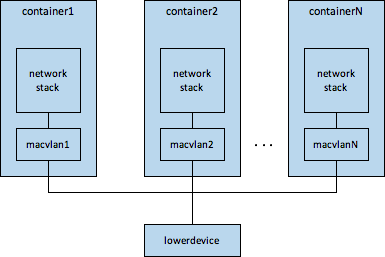
在容器场景下,macvlan完成的功能类似linux bridge + veth-peer,但是性能和cpu开销要稍微比linux bridge好一些,因为
* 少了veth-peer的开销* macvlan不需要mac-learning,比linux bridge的开销也稍微小一点
但是macvlan也有点小缺陷,就是将macvlan device设置到container的net-namespace后,在host上就没法直接看到macvlan device了,这一点类似ovs的internal-port。
* passthrough
这里所说的passthrough不同于pci-assign/vfio-pci把设备passthrough给VM,macvtap的passthrough是指lowerdevice专门只对接一个虚拟网卡后端,这样macvtap其实就没有软交换能力了,更多的起到虚拟化后端和物理网卡的一一对应的连接作用,如下图所示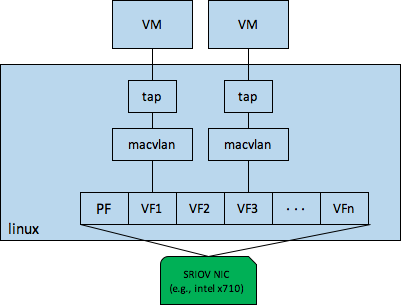
* vepa
没用过,利用外部转发设备实现了hairpin。
* private
没用过,macvlan之间不允许通信,只允许跟外部通信。
接下来介绍下macvtap,通过上面的介绍可以看出macvlan适用的是容器场景,而macvtap适用的VM场景。macvtap就是在macvlan之上接了一个tap字符设备,用于连接qemu/vhost和macvlan。macvtap大概包含两个方面的内容macvtap模块初始化和tap字符设备创建,tap如何连接qemu/vhost和macvlan。
* macvtap模块初始化和tap设备创建+ 初始化- macvtap char device相关的初始化,包括注册macvtap_fops- 注册macvtap_notifier_block notifier block- 注册netlink ops macvtap_link_ops注册+ macvtap设备创建:macvtap_newlink- 在生成的macvlan device之上注册rx handler,如下所示
err = netdev_rx_handler_register(dev, macvtap_handle_frame, vlan);
- 并且创建macvlan link- 在macvlan_common_newlink中register_netdevice(macvlan device)时,会call_netdevice_notifiers(NETDEV_REGISTER, dev),这时候会通过notifier机制调用之前macvtap注册的macvtap_notifier_block中的handler macvtap_device_event,在这里面创建相应的tap设备。* tap如何连接qemu/vhost和macvlan
这个又分为两方面,收包流程和发包流程。
+ 收包流程
在当包到达macvlan后,会执行前面在macvlan上注册的rx handler,macvtap_handle_frame,会根据选择的rx queue找到相应的tap queue,然后将包push到该queue中,然后wakeup阻塞在tap上的线程(比如qemu主线程)进行收包。
+ 发包流程
当包到达tap后,tap对会直接将包发给macvlan。
- OpenvSwitch
OVS一个支持openflow的可编程的虚拟交换机,所谓的可编程就是自定义openflow规则。贴一张来自网络的openvswitch框架图(https://github.com/rkuo/NetworkOS/blob/master/Open%20vSwitch%20Tutorial.md)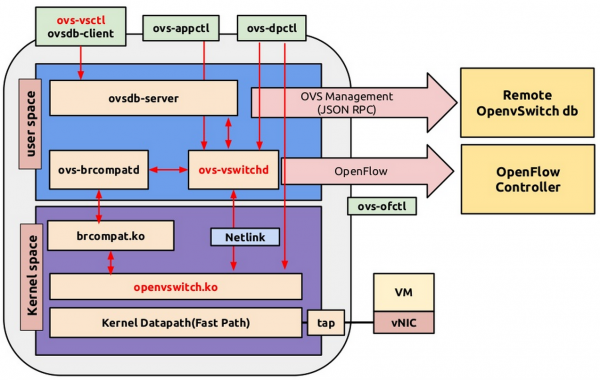
该图显示了ovs各个组件之间的关系,还缺的就是ovs的数据流,下图也是来自网络(http://hustcat.github.io/an-introduction-to-ovs-architecture/)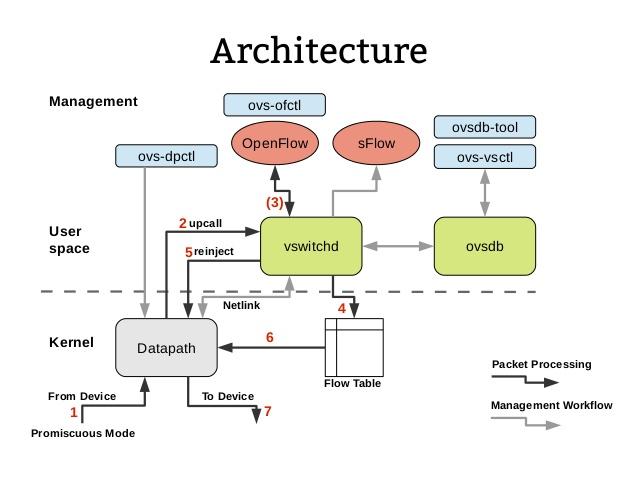
当某一flow的第一个packet到达kernel中OVS datapath时,首先通过upcall将该包送到vswitchd,vswitchd对其apply openflow规则,生成相应的dpflow规则下发到内核中的dpflow table中,该flow后面的包再到ovs datapath后可以直接在dp flowtable中匹配上,直接做相应的action。如果在dp flowtable中没有匹配上,说明相应的dp flow entry过期了,或者还没有生成。
所以每个flow的首包开销是比较大的,针对那种短连接场景,OVS的性能是不高的。
OVS支持的特性很丰富,比如常见的NetFlow, sFlow(R), SPAN, RSPAN,port-mirror,LACP,vlan,overlay(GRE, VXLAN, STT),这些都是linux bridge,macvtap所不具备的。但是OVS满足不了一些高性能(大吞吐或者低时延)场景,比如某些NFV场景,所以DPDK/netmap这种高性能转发方案就出来了。
- DPDK
没有真正分析过DPDK的代码,只是大致了解过它的一些性能优化点,比如
* 死轮代替网卡中断,可以避免由网卡中断带来的上下文切换* 通过VFIO+iommu,可以完全避免数据拷贝,device可以直接使用虚拟地址进行DMA* 数据包的metadata不需要SKB这么臃肿,可以减少cache miss* 隔离出独立的core给DPDK用户态进程帮核,避免线程迁移,避免其他线程造成cpu cache污染* 利用大页内存降低TLB miss* codepath更精简
从以上优化点可以看出,减少上下文切换和提高内存访问效率是关键,提供内存访问效率的手段主要是减少数据拷贝,减少cache miss。上述优化点跟下述判断是基本一致的,这是I/O datapath性能优化的金科玉律。

- fd.io vpp
没研究过。
- overlay
在介绍overlay之前,先说为什么要引入overlay。没引入overlay的网络模式一般称为vlan网络模式,vlan网络模式有以下问题
- <font style="color:black;">虚拟网络依赖物理网络拓扑(这个影响比较严重)</font>
虚拟网络依赖物理网络拓扑,会导致虚拟机/容器的调度(热迁移时创建VM也涉及到调度选择目的主机)受限于物理网络拓扑 ,在传统的三层物理组网下,同一网段的虚拟机不能跨pod区,如下图所示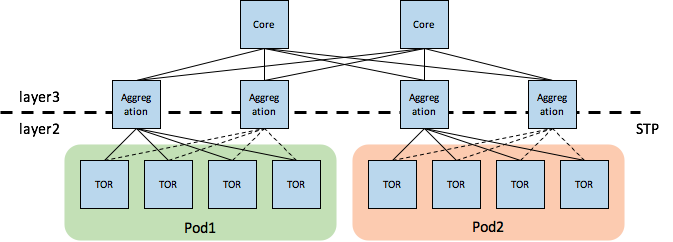
据说可以使用TRILL/SPB(Shortest Path Bridging)结合leaf-spine架构实现更大的pod区。
- 交换机转发表爆表
一个交换机的支持的转发表项是有限的,以前一般一个物理网卡占用一个表项,现在一个物理机上可以有很多虚拟机,容器的话可能会更多,导致某些交换机转发表项不够用
- vlan id不够用
4096(实际4094)个vlan id不够用,这在私有云内一般不是问题,但在公有云在可能会存在问题
- 各个租户没法独立规划自己的私有网络
一个是vlan划分的的问题,一个是三层物理网络共用要求各租户的IP不能重叠。
由于有以上限制,所以提出了overlay网络,把从虚拟机出来的L2包放在一个虚拟隧道中进行传输,在隧道的两端看起来像是同一个L2,从而使虚拟网络和物理网络解耦,组成逻辑大二层网络。overlay和underlay是两个对立的概念,underlay网络是承载overlay网络的物理网络,overlay网络是指通过隧道技术在物理网络之上建立的虚拟网络。overlay网络一般通过隧道协议来实现,比如VxLAN,GRE,STT,其中VxLAN和GRE是目前比较常用的两种用于构建overlay网络的协议。
overlay一般可以在以下几个地方实现,
- 在hypervisor所在的物理机上通过软件来实现- 在物理交换机上实现(比如VxLAN交换机)
我们重点关注在物理机上通过软件的方式实现overlay。
我们以VxLAN协议介绍overlay网络的大致实现。
每个overlay网络都有一个唯一标识,VNI(VXLAN Network Identifier),在VxLAN协议中,VNI占用了24位,也就是说可以有16M个overlay网络,这在同一个IDC或者专线相连的多个IDC中应该是够用了。VxLAN使用UDP作为封装协议,也就是说VxLAN隧道是无状态的。
VxLAN既然是一种layer2 over layer3的隧道协议,就涉及到隧道两端的封包、解包,这个是由VTEP(VxLAN Tunnel End Point)完成的。
隧道两端的封包/解包由VTEP来做了,那主要还剩同网段通信和跨网段通信的问题,同网段通信主要涉及的就是arp学习问题,跨网段通信主要是路由问题。
- vm arp学习
在介绍arp学习之前,先介绍下如何确定给VM发出的包打上哪个VNI。在集群管理平台的网络子系统部分会管理好network和VNI的对应关系,network和VNI是一一对应的,创建VM时,每个虚拟网卡可以指定一个network。真正在物理节点上创建虚拟机时会给每个network分配一个对应的local vlan,并维护了network的VNI和local vlan之间的对应关系,这会配置到物理机的vswitch中。在同一物理机上,一个network对应的local vlan是一样的,但是在不同物理机上一个network对应的local vlan可以不一样,也就是说物理机内部的VM之间使用VLAN隔离,不同物理机之上的VM使用VNI隔离。当VM发的包到达vswitch时先会根据配置打上相应的VLAN,然后再根据local vlan和VNI之间的对应关系打上对应的VNI,这些在OVS中是通过配置openflow规则做的。
目前知道的vm arp学习方法有以下几种,
* 统一请求controller,由controller下发
host上的proxy收到本机上的虚拟机发的arp request后,请求controller,controller把remote VTEP的IP以及目的虚拟机的MAC下发下来,(host本地可以缓存优化),这样host本地维护了目的虚拟机的{VM MAC,VTEP IP}之间的对应关系,proxy代为回复arp reply给源虚拟机。
* 组播学习
host上的proxy收到VM发的arp后,在同一overlay内组播,该overlay内的所有VM和VM所在的host都会收到该组播,IP匹配的VM就会回复arp reply,经过dst host VxLAN封包后再单播回复,这样源端host收到后,就建立了目的虚拟机的{VM MAC, VTEP IP}之间的对应关系,源端VM也收到了arp reply。在这个过程中,同一overlay内的所有VM和VM所在的host都会学习到,基于source进行学习。
* controller静态下发
每次创建、删除、迁移VM时,controller都会向所有的主机更新{VM MAC, VTEP IP}的维护,当向集群中添加物理主机时,也做把所有VM的{VM MAC, VTEP IP}下发到该物理机。当VM发arp request时,host上的proxy就可以直接代为回复了。
* 组播学习和请求controller结合
优先请求controller,如果请求controller失败,就走组播学习。
* 基于MP-BGP EVPN控制协议
没分析过
- 跨网段通信
使用overlay时,跨网段通信有两大类方案
* 硬件VxLAN网关* 软件VxLAN网关
软件VxLAN网关又分为两种
+ 集中式的
这里说的集中式,并不是指只有一个VxLAN gateway实例,允许有多个实例,多个实例之间是负载均衡的,实例之间直接或者间接同步一些管理信息,支持水平扩展。从endpoint的角度来看就是一个逻辑VxLAN网关,再加上计算节点本地缓存优化,这样总体可以做到稳定,可控,性能也不错。
+ 分布式的
分布式的就是指每个hypervisor上都有VxLAN gateway的实例,这个也分为两种
- 先路由再走VTEP
neutron DVR就是这种方案,不同的租户在不同的namespace中进行路由。
- 先走VTEP再路由
这种情况下走的逻辑就跟集中式的VxLAN gateway是一样的,只是每个计算节点都有一个VxLAN gateway实例。
还是要区分南北向和东西向流量,东西向一般不经过network node,南北向一般还是要经过network node的VR的。
- overlay面临的挑战
使用overlay后,虚拟网络会扁平化,VM/container的调度范围会跨整个IDC,那么IDC内网络流量模型会动态变化,没有未使用overlay之前那么固定了,核心路由的流量负载压力可能会有较大波动。如果用集群调度域(availability-zone)去跟物理网络拓扑做适当的对应,也就是说用调度域去对应一个一个的网络区域,这样做可以解决这个问题,但会弱化overlay的好处
* 解决办法
使用leaf-spine物理组网架构,leaf-spine支持水平扩展,leaf和spine之间跑OSPF。
另外,使用VxLAN封包后,包会变大,也要注意MTU的问题。
- vrouter
- L3
L3就是一种集中式的路由方案,依靠VRRP解决HA问题,但是性能瓶颈问题依然存在。
- DVR
没有真正分析过DVR。DVR主要是为了解决L3的上述2个问题:SPoF和性能瓶颈。neutron DVR本身还是基于linux的三层路由和net namespace实现的。为了支持arp学习这块,做了些trick,具体请参考
https://docs.openstack.org/liberty/networking-guide/scenario-dvr-ovs.html
https://wiki.openstack.org/wiki/Neutron/DVR_L2_Agent
- controller
目前主流的主要有ODL和ONOS,没有分析过。
2.2.5 storage
存储主要分为前后端存储I/O虚拟化,镜像/镜像接口,存储后端几部分。
disk virtualization
- virtio-blk variants
- virtio-blk
- vhost-blk
- virtio-scsi
- vhost-scsi
- virtio-blk-data-plane
- virtio-scsi-data-plane
以上都是使用的virtio框架,其中virito-blk,vhost-blk,virtio-blk-data-plane的前端都是一样的,区别在后端实现,virito-scsi,vhost-scsi和virtio-scsi-data-plane的前端是一样的,区别在后端。下面做一下简单对比
- vhost-blk vs virtio-blk/vhost-scsi vs virtio-scsi
vhost-blk vs virtio-blk,vhost-scsi vs virtio-scsi,这种优化跟vhost-net vs virtio-net的优化是类似的,但效果看起来可能没有网络那么好,这是因为存储的性能瓶颈往往在存储介质上。
- virtio-scsi vs virito-blk
先对比下virito-scsi和virtio-blk的storage stack,
* virtio-blk
guest: app -> VFS -> Filesystem -> Generic Block Layer -> IO Scheduler -> virtio-blk
host: QEMU(hardware emulation & image layer) -> VFS -> Filesystem -> Generic Block Layer -> IO Scheduler -> Block Device Driver -> Hardware
* virtio-scsi
guest: app -> VFS -> Filesystem -> Generic Block Layer -> IO Scheduler -> SCSI Layer -> scsi_mod
host: QEMU(hardware emulation & image layer) -> VFS -> Filesystem -> Generic Block Layer -> IO Scheduler -> SCSI Layer -> Block Device Driver -> Hardware
从以上storage stack对比可以看出,virito-scsi的storage stack比virito-blk稍复杂些,所以性能应该是virito-scsi比virtio-blk稍差些,但是在如此长的storage stack中这点复杂倒也不算什么。
virito-blk是一个普通的PCI设备,每一个virtio-blk设备占用一个PCI slot。根据BDF(8:5:3)知道,每个PCI总线上之多只有32个PCI插槽,不过实际产品环境中,也够用了,实在不够用也可以使用pci-bridge配置多总线。而virtio-scsi虽然也有个数限制,不过可以认为没有限制,因为支持的数量太大了。另外在一些高级特性的支持上,可能virtio-scsi更具优势些,virtio-scsi也支持scsi命令透传,而virtio-blk不支持(事实上virito-blk在scsi=on时也支持scsi命令透传,但是还是缺少一些高级特性的支持)。
- virito-blk-data-plane vs virito-blk/virtio-scsi vs virtio-scsi-data-plane
virtio-blk-data-plane相比virito-blk主要优化点在于有单独的线程来处理IO,并且不用再争抢qemu大锁(qemu_global_mutex)。virito-blk-data-plane的IO基本原理图如下所示(来自http://smilejay.com/2016/06/virtio-blk-data-plane-configuration/)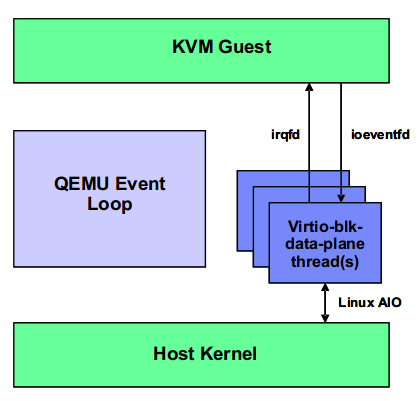
从上图可以看出,
* virt-blk-data-plane thread独立于繁忙的qemu main-loop,而使用virtio-blk时,不管io=threads还是io=native,IO completion都需要在main-loop中处理。另外上图中虽然没说,事实上virtio-blk-data-plane也不用再争抢qemu全局大锁(qemu_global_mutex)* 使用irqfd和ioeventfd通过kernel跟guest进行双向通知,尤其ioeventfd使vcpu线程不必再回到qemu中去通知相关IO线程,在kernel中通过ioeventfd通知用户态之后就可以vcpu_enter_guest,减少了vcpu线程停留在host空间的时间。
注:看代码貌似virtio-blk/virito-scsi也支持irqfd和ioeventfd。
* 使用LAIO提交IO到host kernel
virtio-scsi-data-plane相比virtio-scsi也是类似的。
image layer
qemu image driver有很多,以下是几种典型的。
- qcow2
可以说,qcow2是qemu中最重要的一种image格式,理解qcow2的关键在于理解qcow2 header以及L1/L2 table、refcount table和snapshot table(snapshot table用于内部快照,产品环境中多用外部快照),这些都属于qcow2的metadata,其中qcow2 header负责组织整个布局。
另外,虽然qcow2 L2 cache和refcount cache不属于qcow2 file,但是对于理解qcow2机制非常有用,L2 cache是用来缓存L2 entry的,以加速L2访问,refcount cache是用来缓存refcount entry的,以加速refcount访问。我们可以通过调整L2 cache和refcount cache的size来提高qcow2的访问性能,甚至可以优化cache的组织方式,以及使用last_used_cache记录last recently get cache等。
qcow2提供的高级特性有
- thin-provision- 支持快照
随着分布式存储大行其道,qcow2显得没那么重要了。
- raw
raw格式其实没什么格式,一般都是把一个逻辑/物理块设备作为raw设备传给qemu。
- rbd
rbd是ceph-rbd的image driver。
backend storage
存储后端一般包含:本地盘,IPSAN/FCSAN等共享存储,CEPH等分布式存储。
- local disk
就是把虚拟机存储放在本地文件系统上,因为image都是大文件,可以搞一个适用大文件的文件系统。
- IPSAN/FCSAN
一般是把IPSAN/FCSAN呈现的逻辑LUN做为raw设备传给QEMU。
- CEPH
分布式存储,也是目前比较主流的。没分析过。
2.2.6 live migration
热迁移就是把VM从当前所运行的物理机上迁移到另一个物理机上,这中间涉及到目的主机的选择,一般都是通过调度自动完成的,当然也可以指定目的主机或者目的zone。下图就是一个热迁移的简单示意图
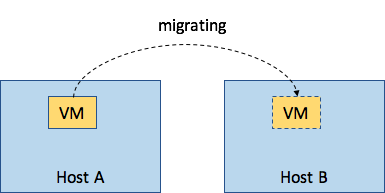
热迁移并不是真的把原来那个VM(称为src VM)迁移到另一个物理机上,而是在另一个物理机上起一个一样配置的VM(称为 dst VM),将src VM状态同步到dst VM,直到达成一致,才把src VM销毁,所以感觉就像把原来的VM原封不动的迁移过来了。注意在热迁移过程中,src VM和dst VM不会同时运行。
热迁移方案
具体热迁移的原理和流程跟热迁移实现方式有关,目前主要有precopy和postcopy两种实现。
- precopy
上面讲到热迁移开始时,会在目的主机上起一个一样的配置的dst VM(QEMU),但是dst VM对应的QEMU起来后先不运行VM,然后把src VM的状态分类、分步的传输到dst VM中,直到两边的状态完全一致了,然后停掉、销毁src VM,启动dst VM。那热迁移中的”热”从何而来?
前面说到VM的状态是分类、分步的同步到dst VM的,VM的状态主要分为存储,内存,以及其他设备的的状态,其他设备包括cpu,网卡,串口等,其中内存和存储的状态数据大小占到了绝大部分,cpu,网卡等设备的状态数据很小,可以在很短的时间内传输到目的端。那么占大头的内存和存储的状态就是通过迭代拷贝的方式同步到目的主机的。
如果存储使用的是共享或者分布式存储,比如IPSAN/FCSAN, CEPH这种,由于热迁移的源端和目的端都可以访问到相应的虚拟盘,所以热迁移时不需要迁移存储数据。如果目的端无法直接访问虚拟机的存储(例如虚拟机存储放在物理机本地盘上的),那么就需要迁移存储数据,早期实现是存储和内存同时迭代拷贝,后面存储采用了driver_mirror的方式在热迁移虚拟机前先进行迭代拷贝,然后再开始热迁移虚拟机。
热迁移虚拟机主要分为以下几个阶段:
- 两边前期准备
比如目的VM对应的qemu起来,源端热迁移线程起来,两边建立连接(一般是libvirt帮忙建立连接,然后将socket fd传给qemu)。
- setup
这一步主要做内存的dirty bitmap初始化,开始log dirty等
- 迭代拷贝内存
迭代拷贝内存脏数据,并且根据统计的传输速率,评估是否可在downtime(用户自己配置的,就是可容忍的停机时间,实际停机时间一般比设置的downtime稍长些)时间内把剩余数据拷完,如果不能就进行下一轮迭代,如果可以就进入停机阶段
- stop src vm and copy all remain states
暂停了src VM,然后把剩余的内存脏数据,以及其他设备(cpu,网卡等)的状态数据同步到dst VM。这个阶段就是虚拟机暂停服务的阶段,一般时间很短,比用户设置的可忍受的downtime稍长些。
- start dst vm
dst VM接收完所有的数据之后,两边VM的状态就已经完全一致了,这时会启动目的端VM,同时发免费arp更新二层上所有网络转发设备的转发表。
热迁移时如何知道迁移哪些数据,这是因为各个设备要迁移的数据都会事先通过vmstate_register或者其变体先注册好。
可以看到之所以称为热迁移,是因为热迁移整个过程中,虚拟机停机时间非常短,业务几乎无感知,之所以可以做到这一点就是因为使用过了内存/存储迭代拷贝,但是它也有一个很大的缺点,就是当VM中的脏内存产生速率比较大时,在可接受的downtime内可能永远无法收敛,这就会导致无法把VM热迁移过去,这是precopy最大的缺点。precopy的优点就是,热迁移过程中即使出现故障(除了最后的停机拷贝阶段出现故障,这一阶段时间很短,出现故障的概率比较低),src VM还是可以正常运行的,业务不受影响。
- postcopy
postcopy主要是为了解决precopy在某些业务场景下无法收敛的问题。
postcopy就是不等两边VM的状态达成一致就先stop src vm,然后把dst vm start起来,dst vm访问的内存如果没还有同步过来就从src vm pull过来,postcopy的优势很明显,就是
- 不会有无法收敛的问题- 热迁移总时间比较短
但是劣势也很明显
- 热迁移过程中出现故障,业务就会中断,源端和目的端的虚拟机都不可用,这一点是致命的,这也导致生产环境不一定敢用postcopy- 开始时demanding page阶段的性能比较差,不过也可以做一些优化,基于内存访问的局部性原理,优先拷贝pagefault内存附近的内存
热迁移使用场景
- 物理机维护
当集群规模比较大时,经常需要硬件维护、更新,这时候就可以把上面的VM热迁移走,业务基本不感知,这个场景比较常见。
- 滚动升级
当要升级内核,qemu等其他运行在计算节点的组件时,可以整个集群通过热迁移的方式滚动升级,这个场景也比较常见,但成本确实很高
- 集群级负载均衡
将负载高的物理机上的虚拟机迁移到负载低的物理机上,这涉及到比较复杂的策略和QoS控制,以及颠簸控制,性价比等。
- 节能
在业务低峰期,将VM集中到一部分物理机上,空出的物理机关机。
2.3 虚拟化之上的openstack
2.3.1 IaaS功能沙盘
把openstack放到kvm虚拟化章节中来介绍,层次显然是不对的,kvm负责的是单节点的虚拟化,而openstack负责的是整个集群的虚拟化host的管理,从下图就可以看出openstack与kvm的关系,
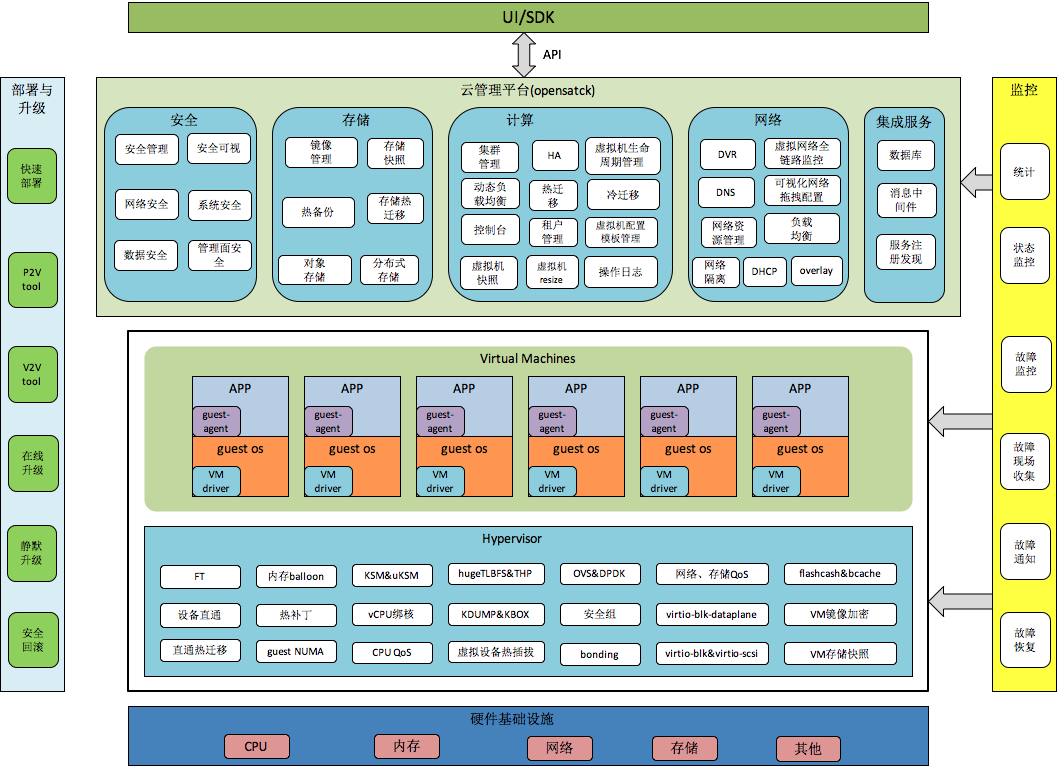
openstack目前是IaaS层事实的开源标准,openstack不止专注于IaaS,也在努力的向上扩展,比如LBaaS,DBaaS(trove),Elastic map reduce (Sahara),Messaging (Zaqar),DNS (Designate),Container orchestration (Magnum),等等。
2.3.2 openstack主要组件介绍
先看下openstack的主要组件图(来自mirantis的ppt),
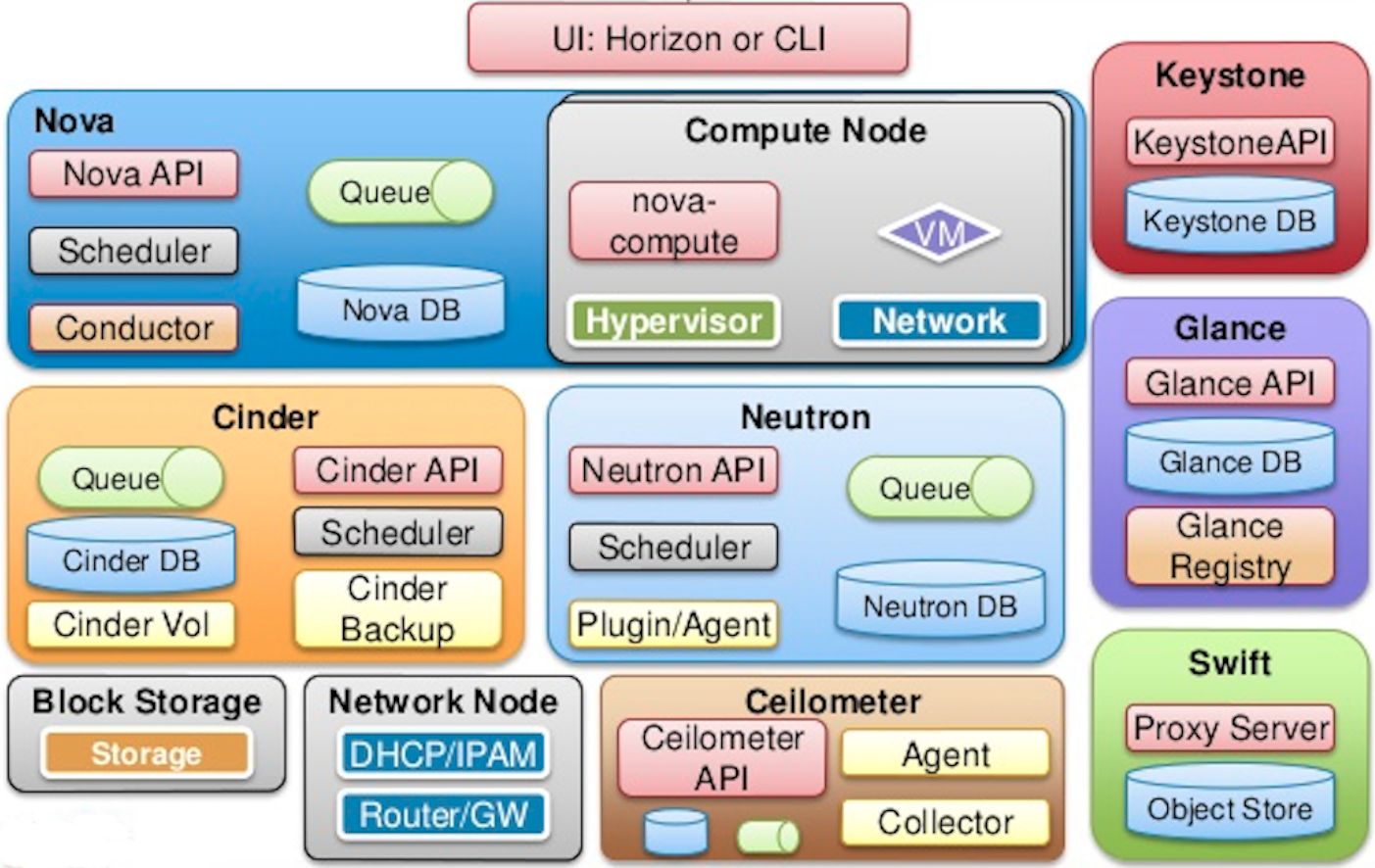
上图中基本涵盖了我们最常用的一些openstack服务(没用过swift),上述服务中比较特殊的两个服务是nova和keystone,后面会介绍为什么他俩比较特殊。
keystone
keystone是负责用户管理、访问控制和服务注册,每个服务的访问都得依赖它,每个服务如果想被别人发现首先得将其作为endpoint注册到keystone中,在访问一个服务前需要先到keystone中获取相应的token,然后携带该token访问相应的服务,服务收到请求后,会拿着该token请求keystone做校验(token的provider(pki,uuid)不同,该处处理会有所不同),如果校验通过了,该服务才会提供服务,不然就会拒绝该请求,鉴权流程大致如下
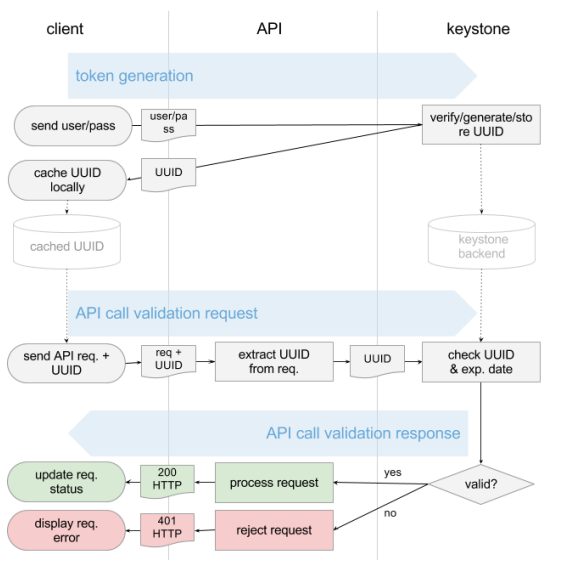
上图中,keystone的token provider是uuid,另外常用的还有PKI。
keystone支持RBAC(Role-Based Access control),不同的user/service可以关联自定义的role,role可以配置相应的权限,曾经基于RBAC做过一个比较特殊的需求,创建一种用户,该用户拥有跟admin一样的权限,除了不能删除资源,这是为了防止有人在夜里运维时迷迷糊糊中误删虚拟机。
nova
IaaS是以VM为中心,nova是openstack的计算服务,它生产、操作的对象主要是VM,所以说nova是openstack的核心服务,有统筹、协调其他服务的职责,其他服务基本是直接或者间接的为nova提供服务,比如虚拟机网络相关的资源和配置由neutron提供,虚拟机创建需要的镜像由glance提供,虚拟机存储业务数据需要的volume需要cinder提供。
先贴一个openstack官网关于nova服务自己的组件之间以及与其他服务之间的关系图,
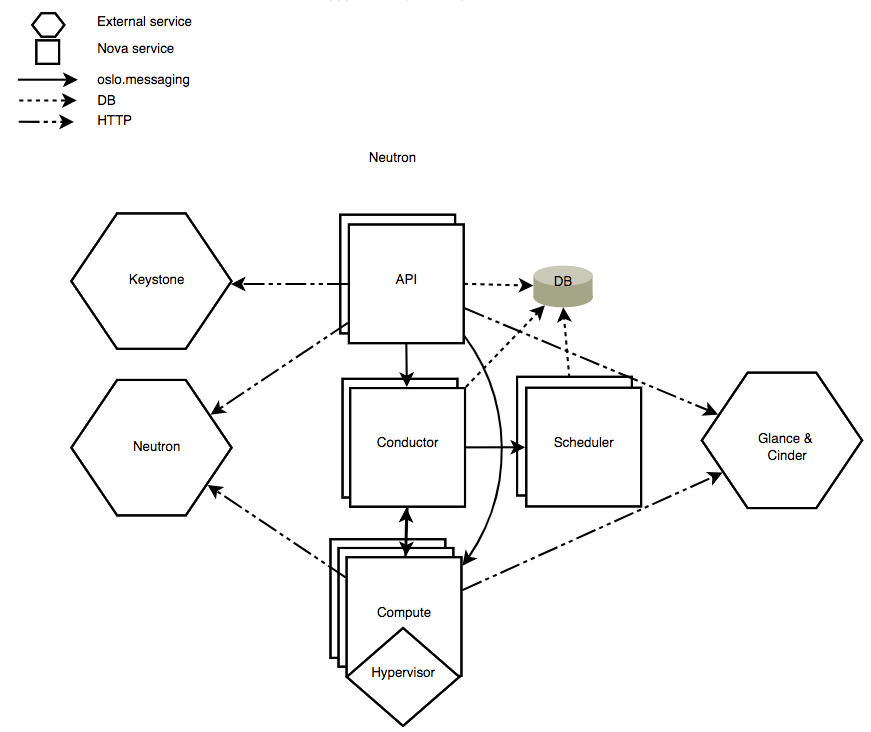
该图清晰的表示了nova组件内部之间的交互关系,以及与其他服务之间的交互关系,nova组件内部使用RPC(oslo messaging)进行通信,服务之间(比如nova和neutron,nova和cinder)之间使用REST API通信。nova服务主要包含以下几个组件
- nova-api
对外提供API服务,比如创建虚拟机,关闭虚拟机,热迁移之类的,凡是跟虚拟机相关的基本都是请求nova-api。
- nova-conductor
从名字和上图中的位置就可以看出nova-conductor是nova的协调者角色,在openstack的发展计划中,nova-compute的一部分工作后面还会移到nova-conductor中,比如跟neutron,cinder,glance的交互部分,让nova-compute成为一个less intelligent slave service ,只管傻傻的干活,不要动脑。
- nova-scheduler
从名字就知道是做调度的,openstack的调度器一般都是使用filter调度器,可以配置各种filter,比如ImagePropertiesFilter,AvailabilityZoneFilter,ComputeCapabilitiesFilter,ComputeFilter,CoreFilter,RamFilter,DiskFilter,SameHostFilter,ServerGroupAntiAffinityFilter,ServerGroupAffinityFilter,很多,并且也方便开发适合自己场景的filter。但是scheduling的效率并不是太高,尤其当集群规模很大时,以及并发创建虚拟机时。
- nova-compute
以上几个服务一般都是运行在管理节点,nova-compute运行在计算节点,当然一个物理节点可以同时作为管理节点和计算节点。nova-compute说白了就是nova在计算节点的proxy,用来连接nova conductor和libvirt(libvirt可以认为是hypervisor的API service),当然nova-compute下支持很多drvier,kvm是用libvirt管理的。现在在创建虚拟机时,nova-compute还是会跟neutron,cinder,glance交互。
neutron
neutron是openstack的网络服务,比较杂,里面包含了很多的网络服务,比如neutron-server,dhcp-agent,l3-agent, l2-agent,metadata-agent等等,你可以使用neutron创建网络(逻辑二层),subnet(三层),vrouter/dvr,port,loadbalancer等。在创建虚拟机前,一般需要先把网络准备好,在创建VM时,把准备好的网络资源,比如port传给VM,不过这时port只是一个上层管理对象,真正的底层port(比如ovs port)还需要在创建虚拟机的过程中创建,这中间会涉及nova-api,nova-compute和neutron之间的交互。
下面贴几张南北向和东西向的网络流量图(来自openstack官网),基本串起了neutron中的主要组件。这里vrouter是用的集中式的L3,没有使用DVR,L2用的是OVS。
- 虚拟机南北向网络通信(虚拟机使用了浮动IP)
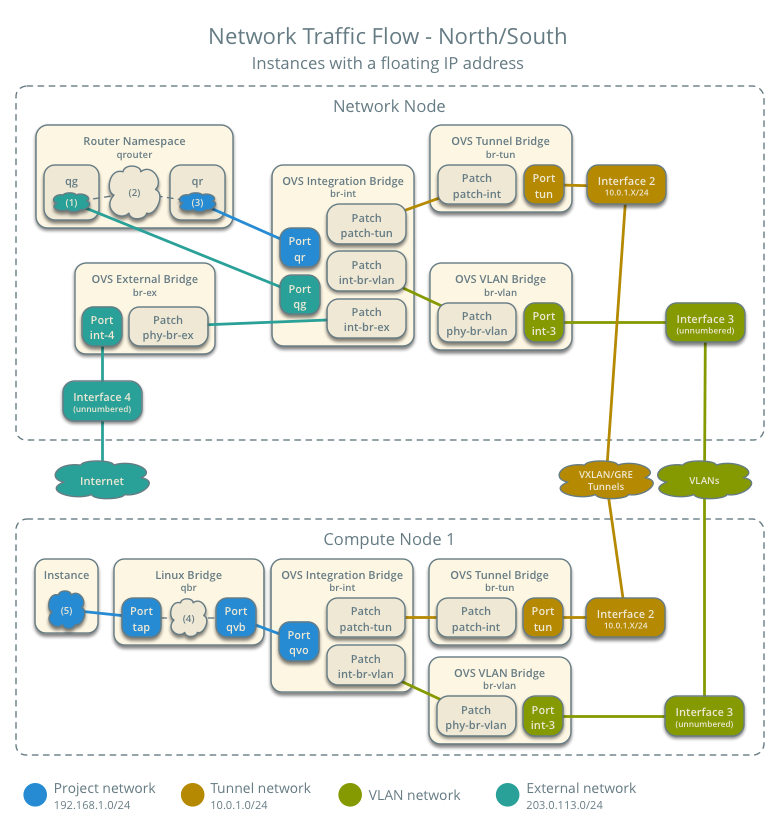
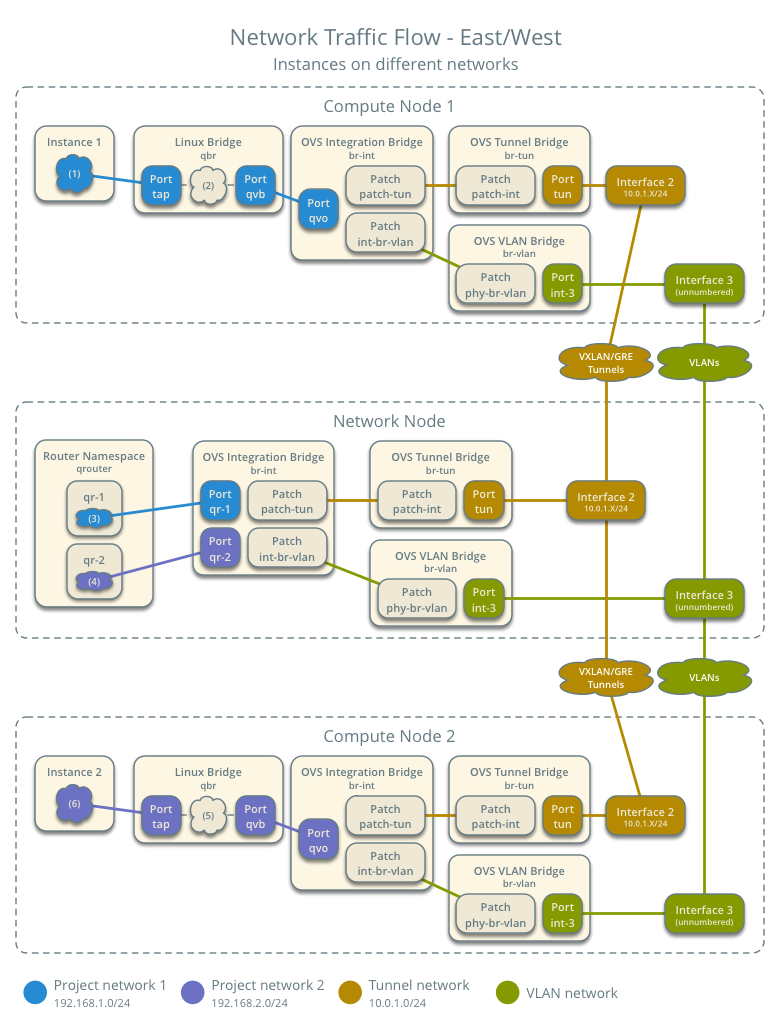
- 虚拟机东西向网络通信(跨网段)
- 虚拟机东西向网络通信(同网段)
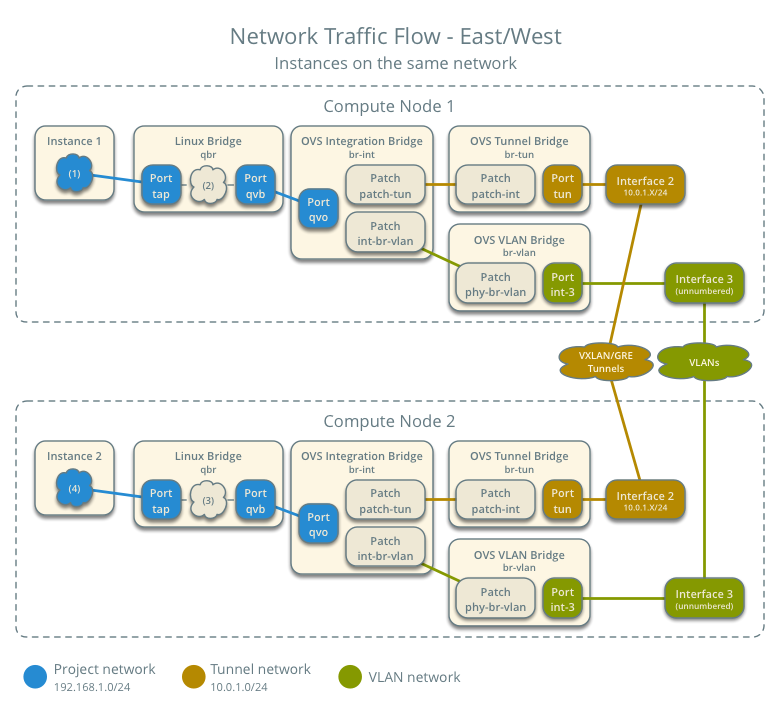
以上几个图都来自 (https://docs.openstack.org/liberty/networking-guide/scenario-classic-ovs.html)。上面的vrouting用的是L3,L3有SPoF问题和性能瓶颈问题,SPoF问题可以使用VRRP来做HA。
glance
glance服务就是openstack的虚拟机镜像管理服务,比如你给一个VM装好系统和必要的软件后,可以将其系统镜像上传到glance,以后可以从glance中download下来(是否要download取决于glance的backend store,如果backend store是跟VM磁盘存储打通的共享存储或者分布式存储,那么只需要在backend store中基于目的镜像建立一个子镜像链过去),然后使用该image作为base镜像创建虚拟机,这样可以加快虚拟机的创建速度,也便于统一管理。glance的组件关系图如下所示
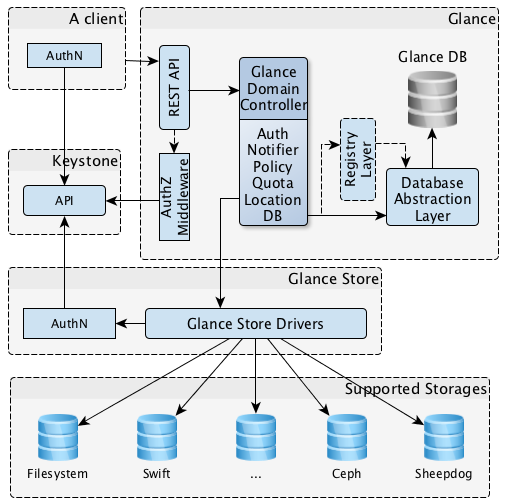
glance本身比较简单,重点是它的backend store,比如CEPH。
如果在创建虚拟机需要从glance backend store下载镜像,那么在并发创建虚拟机时可能就会面临glance API service的网络成为瓶颈的情况,一般有以下方法来解决这个问题
- 预热镜像,可以提前把新上传的镜像push到各个计算节点,一般情况下,一个数据中心内使用的VM镜像种类不会太多
- 使用P2P技术对镜像下载进行加速
- 使用LVS-DR对镜像下载进行负载分发,这要求glance的backend store是分布式或者共享存储,不过这只能解决中小规模的并发,太大规模的并发最好还是使用P2P,或者直接使用不需要下载镜像的backend store,基于backend store中的image建立子镜像,然后计算节点通过backend store API访问新建的子镜像。
cinder
cinder是openstack的卷管理服务,这些卷一般作为VM的数据盘。下图较好的表示了cinder,volume,VM(instance),hypervisor之间的关系
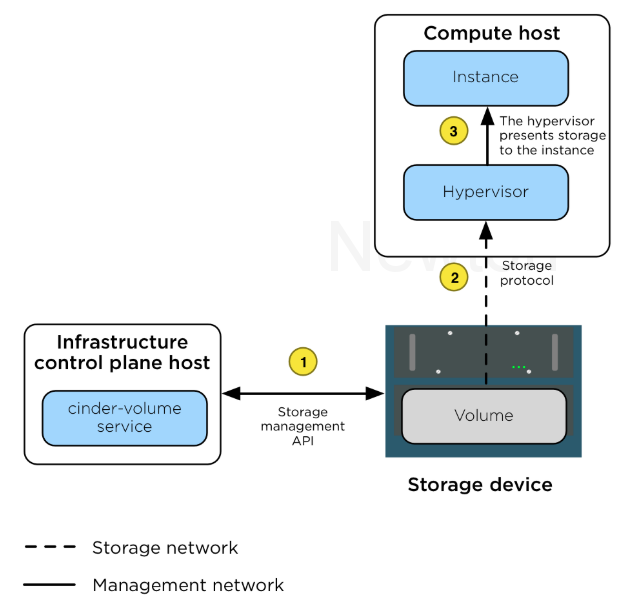
上图中还缺少cinder的backend store,因为backend store是真正承载volume实体的,不同的backend对volume的实现也不尽相同。
2.3.3 学习openstack的设计理念
搞openstack过程中学到了一点openstack的设计理念,在后来自研云管理平台的重构中得以相互印证,以下是关于集群管理系统设计的一些个人心得(参考了openstack,zstack,以及结合自研平台的问题)
- 控制&决策层和执行层严格分离,由控制、决策层统一控制、协调、调度,执行层只负责傻傻的执行,并汇报结果以及本节点一些状态
- 各服务(无论是控制层服务还是执行层服务)是无状态的,可重启重连(重连针对长连接),可水平扩展,这对控制、决策层服务尤其有用
- 各个解耦的子系统读写后端存储(比如数据库,etcd等)的入口由统一的服务去做,不同子系统可以有不同的入口,因为不同子系统存储的数据是不直接相关的。这样便于做读写异常处理、统一读写接口等
- 各个子系统服务之间尽量解耦,各服务对外提供API接口,服务之间只能通过API交互,子系统之间互不访问对方的数据(即不同服务间数据访问隔离);服务之间不直接感知对方的存在,而是通过服务注册中心提供的服务注册发现来感知对方
- 明确服务之间的分层&依赖关系,核心的集群管理服务尽量精简,很多服务是在集群管理服务之上的,只需要使用集群管理服务提供的API即可
- 不能指望底层服务(例如数据库,配置存储,消息队列等)能解决所有的问题,也不能指望底层服务是100%可靠的,作为使用者应该遵循良好的约束、规范,并且做好异常处理
- 使用taskflow来组织任务执行流,以简化任务的异常处理和恢复,并提高数据一致性,减少状态残留
- 非性能路径上的请求尽量统一使用短连接
- 使用REST API,API面向资源/对象,而不是面向操作/流程。一切以资源和对象为中心,无论是API设计还是系统内部设计。对象的组织要符合其内在逻辑
- 基于资源ID做一致性hash分发请求,做到无锁设计
3 容器技术介绍
3.1 发展历史
在容器的发展历史中出现过很多容器相关的技术,下面介绍几个比较典型的。
- chroot
chroot是change root directory的缩写,chroot后看到的根目录就不再是linux系统下默认的根目录,而是你chroot指定的目录作为根目录,没办法再访问原系统中的其他目录。不同的用户chroot到不同的目录,这样可以实现一定的隔离。chroot的功能是通过chroot系统调用实现的,它主要是通过set_fs_root(current->fs, path)函数修改当前进程的fs_struct的root path为指定目录,那么该进程的子进程也都会继承这个设置。
我们之前曾使用chroot提供隔离的编译环境。
- lxc
国内早期搞容器的大都是基于lxc搞的,lxc基本具备了当前容器技术的主要要素,namespaces,cgoups,在这些方面跟docker没有本质区别,唯一缺的就是对镜像的支持。
下面是lxc的示意图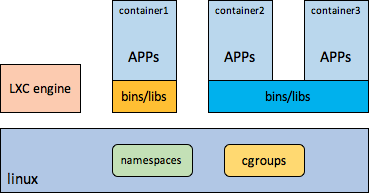
3.2 docker
相比lxc,docker之所以会很快火起来,主要是因为docker引入了image机制。docker的核心也体现在image方面,image打包了应用,配置,以及应用依赖的环境等,docker image远比VM image轻量,docker image使应用在打包,交付,部署,升级等运维方式上产生了根本性的变化,带来的是应用运维的标准化,一致性,高效率,并且基于它更易于做应用级分发、调度。
docker的示意图如下所示
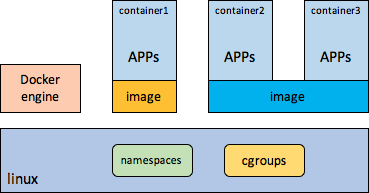
无论是容器技术,还是镜像分层机制都不是docker搞出来的,unionfs也早有了,支持在block层分层的devicemapper也早有的,image分层机制在IaaS领域也用了很久了。但是docker把容器和image分层机制结合起来了,这在理念上是一个比较大的创新,并且docker使用的image和VM使用的image虽然从技术上都支持分层,但是放进去的东西完全不一样,这在理念上有本质的区别。
3.2.1 docker的核心 - image
镜像最大的特点就是支持分层,分层跟快照是一个很类似的概念,下面是一个分层或者快照示意图,
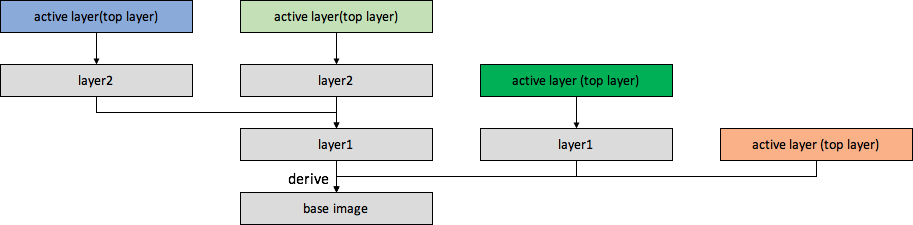
镜像的分层关系就像一棵树(这种数可以有很多棵),树根是一个base image,大家可以继承base image,在上面创建新的一层layer,依次类推,leaf layer就是active layer或者top layer,是应用真正读写的layer,只有active layer是读写层,其他layer都是只读层。分层的好处就是可以共享某些只读层,比如很多image都可以直接或者间接derive from同一个base image 。
应用只会直接使用active layer,它是看不到active layer下面的分层的,但是通过active layer可以访问所有的数据,比如应用要读数据A,如果A不在active layer,分层技术会向下面一层中去找,如果下面一层中没有就再去更下面一层找,直到找到数据A或者找到了base image,具体找的方式跟具体分层实现有关。如果你要修改一个数据,那么分层技术会把该数据县拷贝到active layer,然后再去修改,这就是COW(Copy On Write)技术,如果分层在block层实现,那么就会以block为粒度进行COW,如果分层在fs层实现,那么就会以文件为粒度进行COW。
关于docker image相关知识主要包含以下几个方面
- 镜像制作
创建docker容器时需要指定一个镜像,也就是说创建容器前需要先制作好镜像。制作镜像的方法主要有以下两种,但是一般情况下建议基于docker file来制作镜像,因为基于docker file制作镜像更加标准化。
- 基于docker file
没写过docker file
- docker commit
docker commit是把一个已经运行的容器的产生的变化作为top layer制作一个新的image。
- 镜像管理
docker是使用registry进行镜像管理。
- 镜像的通用保存格式
docker image的通用格式是把每个分层的所有文件和目录进行压缩、打包,然后使用menifest文件对镜像的分层等信息进行描述。在镜像制作时还可以在每个分层中添加一些操作配置,那么在把通用格式分层下载到计算节点时,graph driver会根据配置执行相关的操作。
镜像的通用格式是独立于各个graph driver的,不管各个计算节点使用哪个graph driver,存储在register的镜像的通用格式都是一样的,只有将registery中的镜像各分层下载到计算节点后,才会根据具体的graph driver实现,将分层中的内容写到各个具体的graph driver分层中。
- graph driver
我们知道docker最核心的思想是image,image最重要的特点就是支持分层,而graph driver是各个计算节点上支持image分层的具体实现,所以graph driver最大的特点就是分层,其中vfs是特例,它不支持分层,而是flatten所有分层。
按照分层的具体实现层次,graph driver大致可以分为两类,一类在block层实现,比如devicemapper,qcow2,另一类在是在fs层实现,比如overlayfs,aufs,btrfs,zfs。
docker支持的graph有以下几种,
- overlayfs- aufs- devicemapper- btrfs- vfs- zfs- qcow2
这个不是docker原生支持的,这个主要是为了支持hypervisor-based container场景。
docker image下载会面临跟VM image下载一样的问题,当并发下载量比较大时,registry的网络压力会特别大,这时候可以使用以下技术解决
- p2p
- lvs-dr
- 使用分布式存储,避免下载镜像
3.3 容器依赖的系统技术
容器主要依赖的系统技术有namespace,cgroups,rules-based安全增强。
3.3.1 namespace
可以说容器最依赖的系统技术就是namespace了,没有namespace也就没容器了。linux内核本身是一个共享式内核,总体来说资源是全局管理的,比如pid,port,file等。而namespace实现的就是对某一类资源(包括配置)的隔离,不同namespace之间互相看不到别的namespace中的此类资源,可以类比进程的虚拟地址空间,不同进程的虚拟地址空间范围虽然一样,但是相互独立,互不影响,进程A中的虚拟地址X和进程B中的虚拟地址X完全没关系。所以形象点也可以认为namespace提供了某种资源的隔离空间,不同空间之间相互透明。
另外,我们知道namespace的目的是给一个或者一组应用提供一个隔离的运行环境,而应用的核心是进程,应用也都是以进程/线程(linux内核并不严格区分进程和线程,他们的区别更多是资源共享的设置不同)为载体去访问、使用资源的。在内核中namespace的创建和管理也都是围绕进程的。
所以,namespace有两个层面的意思,一方面是namespace自身的功能,是实现了对某一类资源的隔离,比如net-namespace实现了网络资源的隔离,另一方面是namespace如何给进程提供这种资源隔离能力,这就涉及到namespace的管理和创建。
下面分别先介绍下namespace的管理和创建,然后再介绍各个namespace实现的资源隔离。
namespace的创建与以及与进程的关联
在每个进程的/proc/[pid]/ns/下都可以看到其关联的所有ns,如下图所示
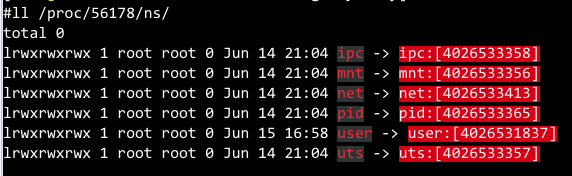
上图中的每个文件对应的是namespace的文件描述符,方括号中的是其inode值,同一个容器中的所有进程的各个namespace的inode值都是一样的。从上图大致也可以看出,每个namespace是独立的,也就是说创建一个进程时不一定要全部ns都创建新的,也可以创建指定的几个ns,其他的默认继承父进程的,两个没有父子关系的进程也可以设置关联某些相同的namespace,自由组合,比较灵活,但在容器场景下,不会这么灵活的去用,而是6个ns全部新建或者5个ns(除了netns,给host共享)新建。
如果一个namespace没有任何进程关联它了,那么该namespace就会自动被删除。
跟namespace的创建以及和进程的关联相关的有3个系统调用,clone,setns,unshare。
- clone
clone系统调用跟fork系统调用类似,只是比fork更灵活,fork创建的进程更多是通过COW的方式继承父进程的一部分资源,而clone系统调用允许以更灵活的方式继承或者共享父进程的某些资源,比如大家常用的创建线程的接口pthread_create就是封装了clone系统调用,指定了CLONE_VM(共享内存地址空间), CLONE_FS(共享文件系统信息), CLONE_FILES(共享文件描述符),CLONE_THREAD(同一个线程组,共享tgid,tgid等于主线程的pid)等flags。所以说在内核中并不是严格的区分进程和线程,更多是跟父进程共享的资源不同罢了,每一个进程或者线程都对应一个task_struct。
那么clone系统调用也可以指定是继承父进程的某些namespace还是新建某些namespace,clone系统调用的flags参数中可以指定要新建哪些namespace,arg参数中可以指定相关的参数。
- setns
setns可以把已经存在的一个进程从现在关联的namespace移出,然后关联另一个指定的netns,第一个参数指定要关联的namespace对应的fd,第二个参数指定相关的namespace类型,0代表可以是任意namespace。
- unshare
unshare有点类似setns,只是不是加入一个已经存在的namespace,而是新建一个namespace进行关联。
在内核中,每个进程的task_struct下面有一个struct nsproxy *nsproxy成员,这里面维护了该进程关联的namespace,struct nsproxy的定义如下所示
struct nsproxy {atomic_t count;struct uts_namespace *uts_ns;struct ipc_namespace *ipc_ns;struct mnt_namespace *mnt_ns;struct pid_namespace *pid_ns;struct net *net_ns;};
在创建进程时,如果不指定CLONE_NEWxxx,那么就会全部继承父进程关联的namespace。
namespace分类
我们现在知道namespace是为了隔离进程访问(读/写/申请…)的资源,那么进程会可能会访问哪些资源呢?
- 文件,目录
- 其他进程,进程之间的关系
- 进程间通信
- 网络相关的interface,port,配置
- 主机名
- 用户信息
namespace保证了不同container内的进程对以上这些资源的访问时隔离的,以上这些资源大致对应了以下几种namespace,
- MNT namespace (CLONE_NEWNS)
mount namespace从CLONE_NEWNS命名就可以知道它是一个独特的namespace,其实它是第一个namespace。mount namespace实现了挂载点的隔离,一个mount namespace中的进程是看不到另一个mount namespace中的挂载点的,所以说不同mount namespace中有不同的目录树结构。
在使用clone或者unshare系统调用时,如果指定CLONE_NEWNS,则会通过copy的方式继承父进程的挂载点列表,该mount namespace中后面再修改挂载点是不是影响parent mount namespace的。mount namespace中的进程的/proc/[pid]/mounts中保存了该mount namespace中的所有挂载点信息。
- PID namespace (CLONE_NEWPID )
pid namespace主要用来隔离pid空间,不同pid namespace中的pid独立编号,可以有相同的pid号,比如都可以有1号进程。调用clone系统调用时如果指定了CLONE_NEWPID,创建的进程则是作为新pid namespace的1号进程,pid namespace中的1号进程负责reaper该namespace内所有孤儿进程,除非该namespace中的某个进程X通过prctl(PR_SET_CHILD_SUBREAPER)配置child sub reaper,那么进程X中的后代进程中的孤儿进程由进程X来reaper。如果pid namespace中的1号进程挂掉了,那么系统会发SIGKILL信号给该pid namespace中的所有进程来kill他们。鉴于1号进程的重要性,unshare 和 setns 系统调用都不会把当前进程加入到新的namespace,而是将其子进程进入到新的namespace中,也就是说一个进程所属的pid namespace在进程创建时就定下来了,后期是没办法改变的,所以说一个进程的父进程要么跟它在同一个pid namespace,要么就在直接parent pid namespace。
pid namespace是可以嵌套的,形成一个树形结构,pid namespace树的根就是root pid namespace。
- IPC namespace (CLONE_NEWIPC)
ipc namespace主要是为了隔离不同IPC namespace中的用户进程之间使用IPC机制进行通信,IPC namespace中实现隔离的IPC机制主要是system V IPC和posix消息队列,每个IPC namespace都有自己的system V IPC和posix消息队列,但是不同IPC namespace中的进程还是可以使用socket通信的,包括unix socket,只要unix socket file在两边都能看到。
- NET namespace (CLONE_NEWNET)
network namespace主要是隔离网络相关的资源和配置,比如interface(包括物理网卡,以及bond,vlan,bridge,veth,macvlan,tap等逻辑网络设备),arp tables,route tables,iptables,conntrack tables,port,/proc/下的部分网络信息和配置。一个interface只能属于一个net namespace,但可以通过ip命令在namespace之间移动interface。容器间一般使用veth pair通信,当然也可以使用macvlan进行通信,也可以使用ovs internal port进行通信。目前/proc/sys/net下还有很多的网络配置不支持per-ns,这也是后面优化的一个方向。
注意:不同net namespace之间是可以使用unix socket进行通信的,前提是要共享unix socket文件。
ip netns命令可以用来验证net namespace的一些功能。
- UTS namespace (CLONE_NEWUTS)
UTS namespace的功能比较简单,主要用来隔离hostname,也就是说同一个UTS namespace下面的进程看到的host那么都是一样的。
- USER namespace (CLONE_NEWUSER)
user namespace实现了用户和组的隔离,每个user namespace可以有自己独立的uid,gid,互不影响,也就是说不同user namespace中可以有相同的uid,gid。
3.3.2 cgroups
上面讲到的namespace实现了不同container之间的几种资源空间隔离,而接下来要介绍的cgroups(control groups)实现了container之间(准确来说是进程组之间)资源分配的控制,比如cpu资源,内存资源,网络带宽,存储带宽/IOPS等,例如cpu cgroup subsystem。cgroups也是分资源类型进行控制的,可以自由组合,这一点跟namespace是一样的。
cgroups是分层的,child group会继承parent cgroup的一些属性。
概念解释
先介绍cgroups的几个概念以方便后面的说明,
- control group
有两方面的意思,
- 一方面就是指control group机制,用来控制进程组的资源分配- 一方面是用户在某个(些)subsystem cgroup的hierarchy下的root cgroup(或者叫root group),以及自己创建的sub cgroup(或者叫sub group),sub group可以是多层的,实际情况下一般也是多层的,可以将一组进程加入到group的task中,以对该组进程进行资源分配控制,这种group可以创建很多,比如一个hierarchy下一般会创建多个group,举个简单的例子,在kvm host上,cpu group subsystem的hierarchy下一般会有一个machine.slice subgroup,在machine.slice下还会有很多跟虚拟机对应subgroup,每个虚拟机对应一个。
cgroup的资源控制粒度就是这样一个group,可以将要控制的某组进程加入到一个group的task中,cgroup中说的task就是指进程,然后设置该group的一些资源分配控制参数,这样就可以控制该group的task中的进程组的资源分配。
为了加以区分,前者我用cgroup指代cgroup机制,后者用group(root group或者sub group)指代用来控制某个进程组的group。
- hierarchy
hierarchy是cgroup的树形组织形式,一个或者多个cgroup subsystem可以一起mount到某个挂载点下,这个挂载点就会形成一个hierarchy,hierarchy的最上层目录(也就是挂载点的根目录)被称为root group,或者default group,root group是mount cgroup subsystem时自动创建的,新创建一个hierarchy时,系统中所有的进程会自动加入到其root group下。在一个hierarchy下,一个进程只能在其中一个group中,不可能同时在多个group下。当创建一个子进程时,子进程自动继承父进程的cgroup设置,当然后面还可以修改。
一个hierarchy下是可以同时attach多个cgroup subsystem的,如果某一个hierarchy有多个cgroup subsystem,那么其中任意一个subsystem都不能再出现在其他hierarchy下。如果一个cgroup subsystem出现在多个hierarchy,那么说明这些hierarchy下肯定只有这一个cgroup subsystem。
- subsystem
一个subsystem对应一个resource controller,比如memory subsystem cgroup就是用来控制某个进程组的内存资源分配的,一个subsystem必须mount到一个hierarchy下才能使用。
各cgroup介绍
下面主要介绍下几个常用的cgroup
- cpuset
cpuset subsystem cgroup主要用来给一组进程指定可运行的cpu集合以及numa node集合。比如可以让container1中的所有进程都运行在cpu0-3上,内存只从numa node0上申请,那么就可以在cpuset subsystem所在的hierarchy下创建一个sub group,在该group中的cpuset.cpus指定0-4,cpuset.nodes中指定0,把container1中的所有进程都添加到该group的task中。
使用sched_setaffinity/mbind/set_mempolicy系统调用去设置进程的cpu亲和性和内存使用策略时,都要该进程所在的cpuset group中的cpuset.cpus和cpuset.nodes的filtering。
使用cpuset cgroup可以将一组进程提供隔离的物理cpu(physical core或者logical processor,取决于有没有打开超线程),以及内存placement,这么做的好处有
- 可以在一定程度上降低不同任务间的cpu干扰- 减少跨node迁移之类的,- 一定程度上减少cache互相覆盖
但是cpuset也有相应的缺点,就是在业务cpu开销模型不是太固定的情况下(实际情况下是不容器评估大量业务的cpu开销模型的),使用cpu_exclusive cpuset会造成一定程度的cpu资源浪费,解决这个问题一般是通过将所有cpu划分成几个大的set,一般是集合numa node和cpu个数进行划分。然后再使用cpu cgroup对同一个cpuset group内的进程进行分组控制cpu资源分配,所以实际情况下都会结合cpuset和cpu两个subsystem进行控制进程组的cpu资源分配。
考虑到cache对性能的影响是巨大的,在进行业务进程组的划分时,还可以考虑业务进程的LLC使用情况,尽量将LLC-hog类型的业务进程分散到不同的node上,当然还可以使用intel RDT进行更精细的cache控制,但是难点在如何获取业务进程精确、稳定的cache消耗模型。
- cpu
cpu subsystem cgroup以更加灵活的方式控制一组进程的cpu资源分配,在一定程度上保证一组进程的cpu资源分配,同时也可以做到一定程度的共享。cpu subsystem cgroup支持两种控制cpu分配的策略,ceiling/cap和share/weight,
- ceiling(绝对控制)
ceiling就是说在“一段时间”内,“最多允许使用多长时间”的CPU。这句话中包含两个变量:一段时间,也就是计算的步长,在每一个步长时间内,允许使用多少时间的CPU,这段时间用完后,又进入下一个分配循环;另一个就是“最多允许使用多长时间”,这个变量是在“一个步长时间”的基础上说的。
针对“一段时间”对应的变量是cpu.cfs_period_us,“最多允许使用多长时间”对应的变量是cpu.cfs_quota_us。
cpu.cfs_period_us:每次cpu resources reallocation的步长,从名字看,就知道时间单位时microsecond(us,微秒)。该值设置的upper limit是1s,lower limit是1000 us。
cpu.cfs_quota_us:在一个cpu.cfs_period_us时间内,该cgroup中的task最多允许cpu使用时间,注意,这里cpu.cfs_quota_us时可以大于cpu.cfs_period_us的,因为一个cgroup中的task数时大于1,并且系统中的cpu数也一般是大于1的。当cgroup中的tasks用完了
cpu.cfs_quota_us时间,那么就会被调度出去,直到cpu.cfs_period_us的剩余时间走完,进入下一个reallocation。
下面这段来自red hat enterprise linux 6 resource management guide的解释更加清楚,
If tasks in a cgroup should be able to access a single CPU for 0.2 seconds out of every 1 second, set cpu.cfs_quota_us to 200000 and cpu.cfs_period_us to 1000000. Note that the quota and period parameters operate on a CPU basis. To allow a process to fully utilize two CPUs, for example, set cpu.cfs_quota_us to 200000 and cpu.cfs_period_us to 100000.
Setting the value in cpu.cfs_quota_us to -1 indicates that the cgroup does not adhere to any CPU time restrictions. This is also the default value for every cgroup (except the root cgroup).
跟ceiling策略相关的还有一个统计文件,cpu.stat,其中包含三个数值,
nr_periods:记录过去了多少个cpu.cfs_period_us。
nr_throttled:记录了cgroup中的tasks因为quota用完而被throttle的次数。
throttled_time:记录了cgroups中的tasks因为quota用完被throttle的总时间,以ns为单位。
- share(相对控制)
每个group的cpu.shares的数值指定了group之间cpu share比例,按照这个比例去使用cpu,比如groupA指定的share值为100,cgroupB指定的share值为200, cgroupC的share值为100,那么他们可获取的CPU使用量比例就为1:2:1.
如果一个cgroup中的tasks没有使用完它的cpu,就把其剩余的cpu放到系统的global pool of unused cpu cycles,其他cgroup中的cpu如果已经使用完了,还可以从pool中borrow cpu。
另外有一点需要注意的是,这里指定的share值是针对系统上的所有CPU而言,不是针对一个cpu说的,也就意味着,一个cgroup中的tasks设置了25%的cpu值表示total CPU * 25%,另外就是对于一个cpu来说,它占用的并不是指25%,而100%都是有可能的。
一个cgroup的share值指定后,其可以使用的cpu量是可能变化的,因为的total share是可能增加或者减少的,share只是一个相对值。
实际情况下,会将上述两种策略结合使用,share用来控制相对分配比例,ceiling用来控制上限。
- cpuacct
cpuacct subsystem cgroup主要是用来记录一个group和它所有的child group中的进程的累加cpu使用情况。cpuacct group中主要有以下几个字段,
- cpuacct.stat
统计该group以及所有child group中的所有进程的user和system cpu使用情况
- cpuacct.usage
统计该group以及所有child group中的所有进程的cpu使用时间,单位是ns
- cpuacct.usage_percpu
统计该group以及所有child group中的所有进程在各个cpu上的使用时间,单位是ns
总体来说这个cgroup的作用不是太大。
- memory
memory subsystem cgroup主要用控制一组进程的内存分配以及统计该组进程的内存使用情况。下面介绍memory cgroup中的主要字段,
- memory.stat
记录详细的内存使用信息
- memory.usage_in_bytes
该group中的进程总共使用的内存量
- memory.memsw.usage_in_bytes
该group中的进程总共使用的内存量,加上使用的swap空间大小
- memory.max_usage_in_bytes
该group中的进程使用内存量到达过的最大值
- memory.memsw.max_usage_in_bytes
该group中的进程使用内存量加上使用的swap空间一起到达过的最大值
- memory.limit_in_bytes
设置该group内所有进程使用的内存的最大量,包括file cache,不可以使用该字段限制root group,只能用来限制sub group。-1表示没有限制。
- memory.memsw.limit_in_bytes
设置该group内所有进程使用的内存加上swap空间的最大量。
- memory.failcnt
统计由于到达memory.limit_in_bytes限制导致内存申请失败的次数
- memory.memsw.failcnt
统计由于到达memory.memsw.limit_in_bytes限制导致内存申请失败的次数
- memory.soft_limit_in_bytes
这个是一个软限制,值设置的要比memory.limit_in_bytes小,当到达memory.soft_limit_in_bytes限定值时,一般会触发内存回收,soft limit的生效是持续的。
- memory.force_empty
强制将该group中所有进程使用的内存page设置为0,只有当该group中没有进程时才会设置。一般当删除一个group前,会通过设置memory.force_empty,防止将该group中的进程的之前使用但现在没用的pagecache移到其parent group下。
- memory.swappiness
这个参数主要用来设置内核swap该group中的进程的内存的tendency。
- memory.move_charge_at_immigrate
如果设置了该参数,当发生进程跨group迁移时,该进程的对使用共享内存的charge会随着进程的迁移而计算到目的group身上。
- memory.oom_control
表示是否enable OOM killer。
- memory.numa_stat
统计每个numa node的内存使用情况
- memory.pressure_level
用来设置memory压力水平的notification
- memory.kmem.failcnt
kernel memory由于到达memory.kmem.limit_in_bytes导致内存申请失败的次数
- memory.kmem.limit_in_bytes
kernel memory使用量的上限值
- memory.kmem.max_usage_in_bytes
kernel memroy使用记录的最大值
- memory.kmem.tcp.failcnt
由于到达tcp buf上限导致申请tcp buf失败的次数
- memory.kmem.tcp.limit_in_bytes
tcp buf内存上限
- memory.kmem.tcp.max_usage_in_bytes
曾经使用过的tcp buf的最大值
- memory.kmem.tcp.usage_in_bytes
当前使用的tcp buf的内存量
- memory.kmem.usage_in_bytes
当前使用的kernel memory的大小
- blkio
blkio subsystem cgroup用于控制对某个块设备(物理盘,逻辑盘,分区等)读写带宽/IOPS的大小或者读写比例,支持cap(throttling)策略和weight策略,
- weight
weight策略是基于CFQ调度算法的,CFQ是基于进程/进程组进行调度的。跟weight策略相关的参数如下所示
* blkio.weight
这个设置的是该group在所有块设备上的weight值。
* blkio.weight_device
可以设置该group在每个块设备上的weight。这个在生产环境中还是比较常用的。如果设置某个设备的weight,那么blkio.weight在该设备上的设置就不发挥作用了。
- throttling
throttling策略主要用来限制对某个磁盘的读写带宽或者IOPS上限。跟throttling策略相关的参数如下所示
* blkio.throttle.read_bps_device
设置该group在指定设备上的读带宽上限
* blkio.throttle.read_iops_device
设置该group在指定设备上的读IOPS上限
* blkio.throttle.write_bps_device
设置该group在指定设备上的写带宽上限
* blkio.throttle.write_iops_device
设置该group在指定设备上的写IOPS上限
* blkio.throttle.io_serviced
该group在各个设备上的io分类次数统计情况
* blkio.throttle.io_service_bytes
该group在各个设备上的io分类带宽统计情况
另外还有很多公共的设置参数。
目前在centos7上还不支持buffer io的QoS,因为buffer io真正去读写设备时不再是最初 submit io的用户进程了,而是内核中大家公用的kworker执行flush job来flush buffer io。打个比方,有好几条河流(用户进程)要将水(data)流入长江(类似underlying块设备),想对这几条河流进行做流控(流控点在将要进入长江时),如果这几条河流都是直接流入(direct io)长江,那还是比较好对各个河流进行流控,但是如果这些河流不是直接流入长江,而是先流入一个公共的胡泊,后面由胡泊(公共的内核线程)将这些水再流入长江,那么这时就不好对各个河流进行流控了,因为这时区分不出这些水各自来自哪条河流了。
在不支持buffer io QoS的OS上,如果解决buffer IO的限速问题,有一个规避办法就是每个要限速的group(对应container,因为kvm在后端是可以控制使用direct io的,而container控制不住,因为是IO是业务发起的)使用一个独立的块设备,每个group使用的块设备不一样,这些块设备一般都是在某个或者某些资源池中创建出来的逻辑块设备。在这个块设备上进行throttling,因为一个group对应一个块设备,那么不管你中间过程中数据怎么转手,最终还是到达该分配给group的块设备中,当然这种规避办法有很多限制,比如不支持weight策略(1对1了的weight没啥价值),有些场景下不支持这么划分块设备。
在高版本内核中,利用memory cgroup和blkio cgroup一起配合完成了对buffer io的限速。
- net_cls
net_cls subsystem cgroup本身是完成不了对该group中的进程的网络IO流控的,它主要是完成了对该group中的进程发出的包进行打上classid(class id有两部分组成,major handle number: minor handler number ),然后跟tc的HTB策略配合进行分类 filter、限速。在这一点是net_cls跟使用iptables打mark是类似的,但是比iptables打mark更加易用、灵活。
其实net_cls还可以跟iptables和,基于net_cls打的id,iptables也可以一些相应的控制。
- freezer
freezer subsystem cgroup主要用来stop/resume group中的进程,一般可以用于制作checkpoint。
- devices
这个subsystem比较陌生,主要用户控制group中的进程对指定设备的访问。
- pids
pids subsystem cgroup主要用来控制group中的进程数。
- hugetlb
hugetbl subsystem cgrop主要用于控制group中的进程使用的hugepage量。
原理与实现
这块还没有深入分析,需要后面再补充。
cgroup相关的代码主要包含以下4个部分
- 初始化
在start_kernel阶段做cgroup各个subsystem的初始化,以及注册cgroup_fs_type文件系统。
- cgroup filesystem相关的处理
在初始化阶段注册了cgroup_fs_type问价系统,跟该文件系统相关的主要operations结构体的定义如下所示
static const struct file_operations cgroup_file_operations = {.read = cgroup_file_read,.write = cgroup_file_write,.llseek = generic_file_llseek,.open = cgroup_file_open,.release = cgroup_file_release,};static const struct inode_operations cgroup_file_inode_operations = {.setxattr = cgroup_setxattr,.getxattr = cgroup_getxattr,.listxattr = cgroup_listxattr,.removexattr = cgroup_removexattr,};static const struct inode_operations cgroup_dir_inode_operations = {.lookup = cgroup_lookup,.mkdir = cgroup_mkdir,.rmdir = cgroup_rmdir,.rename = cgroup_rename,.setxattr = cgroup_setxattr,.getxattr = cgroup_getxattr,.listxattr = cgroup_listxattr,.removexattr = cgroup_removexattr,};
- 在mount cgroup_fs_type文件系统系统是,在cgroup_mount函数中会注册cgroup_dir_inode_operations,该operations中,cgroup_mkdir是一个比较重要的函数,里面实现了如何创建一个group。
- cgroup与进程之间的管理
每一个进程的task_struct中都有以下成员
#ifdef CONFIG_CGROUPS/* Control Group info protected by css_set_lock */struct css_set __rcu *cgroups;/* cg_list protected by css_set_lock and tsk->alloc_lock */struct list_head cg_list;#endif
- 其中cgroups是该进程关联的cgroup信息,每个cgroup信息是通过css_set来维护的,css就是指cgroup subsystem。
css_set结构体定义如下所示
struct css_set {/* Reference count */atomic_t refcount;/** List running through all cgroup groups in the same hash* slot. Protected by css_set_lock*/struct hlist_node hlist;/** List running through all tasks using this cgroup* group. Protected by css_set_lock*/struct list_head tasks;/** List of cg_cgroup_link objects on link chains from* cgroups referenced from this css_set. Protected by* css_set_lock*/struct list_head cg_links;/** Set of subsystem states, one for each subsystem. This array* is immutable after creation apart from the init_css_set* during subsystem registration (at boot time) and modular subsystem* loading/unloading.*/struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT];/* For RCU-protected deletion */struct rcu_head rcu_head;};
- 每当有一个进程关联了一个css_set,则该css_set的引用计数ref_count就会加1。上面的hlist成员就是该css_set链到系统维护的全局css_set链表中,tasks成员就是维护了关联该css_set的进程列表,css_set结构体中比较重要的一个成员就是subsys指针数组了,每个成员指向了一个cgroup_subsys_state结构体,它对应一个cgroup subsystem。
在fork一个进程时,子进程默认会继承父进程的cgroup关联信息。
- 各cgroup的实现逻辑
还没分析。
3.3.3 rules-based安全增强
- SECCOMP (SECure COMPuting with filters)
seccomp主要是通过BPF来filter syscall以减少攻击面。每个syscall都会经历修改、成熟的过程,在这过程中可能是存在漏洞的,内核相关的CVE经常出现。linux内核提供的系统调用很多,但是对于一个应用来说,一般只会使用其中一部分系统调用,这样就可以通过设置whitelist来控制应用使用哪些syscall,以降低攻击面。但是实际产品环境中,seccomp是不太易用的,因为针对大型软件,都是多人参与并且软件版本不断迭代,不太容易知道使用了哪些syscall的,何况软件还在不断更新,就算今天搞清楚了,过不多久可能又变了。
另外,通过filter syscall只能说是缓解了部分安全问题。
- SELinux ( Security Enhanced Linux)
selinux是NSA搞得一个安全增强模块LSM,提供了 Mandatory Access Control (MAC)能力。selinux对系统上的所有用户,应用,进程,文件等定义了访问权限。比如,当一个应用访问一个文件时,selinux就会检查该应用和该文件的安全上下文以确定是否允许本次访问,然后缓存起来以加速下次访问check。所谓的访问者和被访问对象的安全上下文,是要实现配置好的。selinux的安全policy的配置是比较麻烦的,实际产品环境不太易用。
- AppArmor (Application Armor)
apparmor通过给每个应用配置一个访问控制文件,以控制它对各种资源的访问。
以上几种安全增强机制有一些公共特点,比如不易用,selinux和apparmor设置规则还比较复杂,维护起来不太容易,感觉不太适用于数量庞大、多变的业务场景,另外就是不彻底,更多是安全方面的增强。
3.4 容器面临的问题
资源隔离不彻底
这里说的“资源隔离不彻底”主要指两个方面,一个是指namespace的资源&配置隔离不彻底,一个是指cgroup的accounting不彻底。
- 网络
主要是配置没有做到per-ns,比如net.ipv4.tcp_max_syn_backlog,net.ipv4.tcp_rmem,net.ipv4.tcp_wmem等,有很多。其他namespace也有类似的问题。资源&配置的per-ns化也是优化的重点。
- cpu
我们知道cpu相关的 cgroup是针对进程(组)进行accouting或者隔离的,那么中断上下文呢?
以容器网络收包为例介绍下,组网图如下所示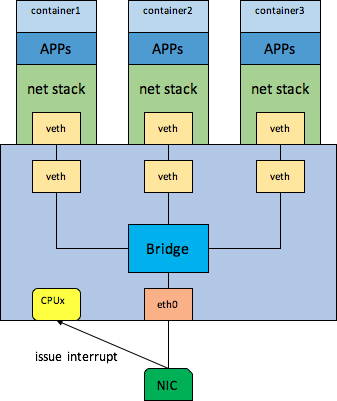
网卡收到包,会先将包DMA到网卡驱动提供的共享内存中,然后给某个cpu(取决于中断亲和性绑定以及中断路由策略等)发中断,收到中断的cpu就会处理该中断,然后在softirq中做收包处理,然后把包deliver到bridge进行转发,然后再转发到匹配的veth后端,然后再到peer veth,然后再deliver到upper net stack,直到tcp层,这整个过程都是在收到网卡中断的那个cpu上处理的,当然如果设置了rps,可能会换CPU,如果当前cpu上irq太多,也可能也会使用当前cpu上的softirqd内核线程处理。不管怎么说,cpu开销应该算到谁身上呢?
例子1,假设container1使用cpuset分配了cpu0-3, container2分配了cpu4-7,container3分配了cpu8-11,如果cpu2收到了中断,但是最终包转发到了container3,那么container1岂不是太亏。那是不是可以通过设置中断亲和性让中断发到最终收到的包的container的cpu上呢?如果使用的vswitch,那是做不到这一点的,因为在网卡发中断时,根本不知道这个包最终到container上,因为发中断在前,二层交换在后。那么使用SRIOV技术做到二层交换在前,发中断在后,把SRIOV VF分配给container,包会先经过SRIOV的L2 switch到VF对应的pool中的某个rx queue,然后在DMA到内存中,然后才会发中断,如下图所示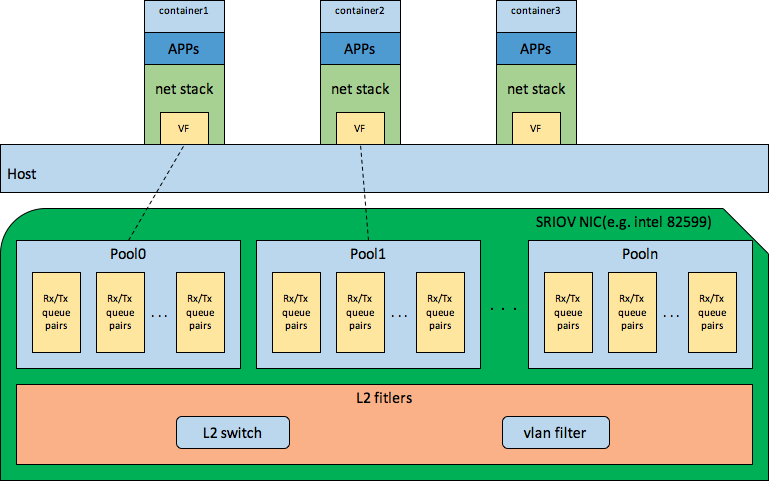
使用SRIOV技术也有很多限制,比如对VxLAN,ACL等高级特性的支持,QoS没有tc HTB那么灵活等。
例子2,假设container1,2,3都分配了cpu0-11,但是他们使用cpu cgroup给他们设置了相应的quota,如果cpu2收到了中断,cpu2在收到中断前正在跑container2上的一个线程,但最终转发到了container3中,那么container2岂不是太亏。
例子3,对例子2稍作改动,如果接收到中断的cpu上正在跑一个内核线程,那谁又来买单呢?
由于现在的网卡驱动收包处理都会使用NAPI,一般会在收到中断的cpu上处理很多包(直到rx descriptor ring上暂时没有包了)才会结束这一轮,尤其是网络流量比较大时,那么背锅的岂不是很倒霉?
所有的中断下文问都会面临这个问题,只是网络中断比较突出。
- 内存
主要是kernel-memory accounting的问题,一个用户进程消耗的内存,不只是用户态,还包括kernel-memory,但是有一部分kernel-memory是没有统计到用户进程的内存开销中的,这就导致从管理员配置容器内存的角度看好像没有overcommit,但是仍然可能会导致OOM。社区也在完善kernel-memory accounting这方面的工作,目前没还有把全部kernel-memory进行accounting。但有些确实是不好accounting的,比如共享内存,虽然算在了第一个touch的cgroup上,page cache也是采用同样的策略,但是实际情况下并不总是合适的。这些都是共享内核带来的,很多内核资源不是只为某一个进程服务的,而是会给很多进程提供服务。
安全隔离
container的安全问题的根源在共享内核,而内核中并不是所有的资源都per-ns化了,比如/dev/mem,很多内核模块。恶意程序利用内核漏洞攻陷内核了,相信上面的容器也就基本在攻击范围内了。
前面提到的安全增强只能说是缓解,并不能根治。
故障隔离
任意一个容器中的应用触发了内核故障(比如panic),所有的容器都会受到影响。
初始内存“碎片化”
容器的初始内存是很难保证有大块的连续物理内存的,原因在于容器中应用进程的内存分配跟non-container情况下的进程分配内存的方式没有任何区别,都是基于同一个host os进行分配的,随着docker host运行的时间变长,总体来说内存是趋向离散化的。
那么问题来了,有少量应用是希望使用大页,或者大块的连续物理内存的,比如DPDK,那么这种业务跑在容器中就不好搞了,必须做一些资源使用的控制,容器调度策略上做一些适配,比如有大页或者大块连续物理内存需要的业务调度到指定的物理机集合上。
老版本OS支持不友好
并不是说老版本OS不能跑容器,还是可以跑的,只是namespace,cgroups,graph driver还不是那么完善,另外也只能跑低版本的docker,比如高版本的docker要求内核支持PR_SET_CHILD_SUBREAPER,而kernel-3.4才开始支持这个能力的。
windows支持不友好
应该是比较新的windows server才支持container,存量windows应该大都不支持。
3.5 后续优化思路
- 性能优化
在容器中跑DPDK和用户态协议栈,大致有以下两个方案,
- 方案1
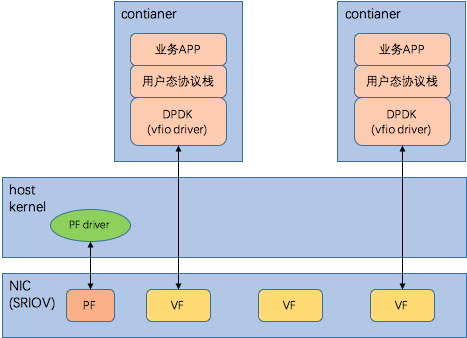
该方案优缺点如下,
* 优点:
1)简单,跟native环境下的dpdk方案是类似的
2)性能比较高
* 缺点:
1)每个容器中都跑dpdk,可能会浪费一些cpu,具体要看业务场景
2)直接将VF set到container net-ns中,这样host datapath上的一些特性可能就没有了,这要看硬件是否支持,比如vxlan,acl等
- 方案2
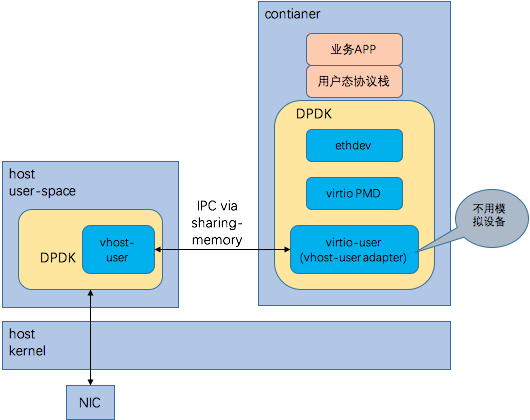
该方案的优缺点如下:
* 优点
1)跟VM+DPDK方案基本类似,可以使用host datapath上的一些功能,比如vxlan,acl/fw,port-mirror,sFlow,SPAN,RSPAN等
* 缺点
1)运行在container中的dpdk中的virtio-user需要自己实现或者移植
2)每个容器中都跑dpdk,可能会浪费一些cpu,具体要看业务场景
以上不管哪个方案,都会遇到容器没法保证提供大块连续物理内存的问题。
- 资源隔离增强
这个主要是在资源&配置的per-ns化方面做增强,比如把更多的网络配置per-ns化。
- 安全增强
看能否利用intel SGX来增强容器安全,具体参考 [9]
4 安全容器
4.1 hypervisor-based container
从技术上将,主要还是虚拟化技术,在虚拟化技术的基础上支撑了容器的理念,支持OCI标准。hypervisor-based container算是对container on vm组合的一种优化。
4.1.1 hyper
hyper是hyperhq公司发布的一款hypervisor-based container,应该是业界比较早的一款hypervisor-based container,结合了VM和docker的优势。hyper整个方案的组件关系图如下所示,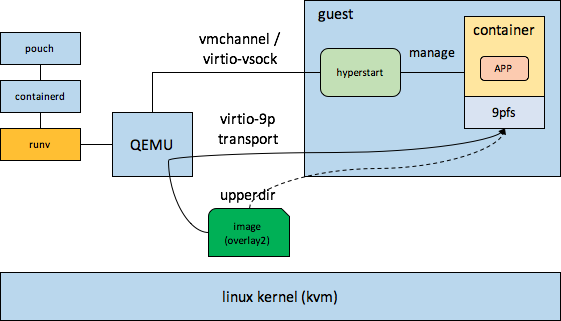
其实,hyper在VM中提供的是一个POD的概念,POD中时可以有多个容器的,当然也可以只有一个容器。另外hyper基于的hypervisor不止kvm,应该也支持xen。hyper更多的是利用底层的hypervisor,并不强依赖hypervisor的具体实现,当然会基于hypervisor的前后端通信机制作为runv和hyperstart的通信通道,以及share image to guest的方式也依赖hypervisor提供的能力。
在上图中,runv实现的个兼容OCI标准的runtime,hyperstart可以认为是runv在guest中的一个代理,他们之间通过hypervisor提供的通道进行交互,kvm提供的通道就是virtio-serial或者virtio-vsock,两者hyperstart都支持。
还有一个重点,就是host如何把docker image share给guest的,runv用的是virito-9pfs,但是9p存在以下问题
- 性能比较差- 老版本的guestos对virtio-9pfs支持不好,比如centos6.9上不支持writable&shared mmap
针对性能差的问题,社区虽然也搞了vhost-9pfs,已经有10个月没更新了。
4.1.2 clearcontainer
clearcontainer在VM启动速度,以及内存footprint这块做了很多优化。
- 启动速度优化* qemu侧
intel从qemu-2.9 fork了一个qemu-lite分支,对qemu做了些优化,主要有两类
+ 配置类优化
编译qemu时disable了一堆feature
+ 代码级优化
并行化vcpu初始化流程;新的machine type pc-lite,该machine type中对设备做了裁剪;优化掉了seabios;使用nvdimm作为guest的disk driver,通过DAX提高了启动速度;。。。
* guest kernel
配置了一些内核启动参数,比如rcupdate.rcu_expedited=1
VM启动时间优化到了1s以内。
- 内存开销优化
主要是使用了DAX(比较新的guest kernel才支持)技术,DAX可以bypass pagecache和虚拟内存子系统,这样一方面是可以提高性能(减少data copy),当然前提是后端存储性能比较好,一方面是节省内存,因为内核中不需要再用内存承载storage数据了,相当于直接把磁盘map到用户空间。
在host上qemu通过模拟nvdimm的方式将rootfs image提供给guest,guest使用DAX访问rootfs image。有一点需要注意的就是,当在qemu中模拟的nvdimm对应的backend rootfs image的mmap方式是MMAP_PRIVATE(即shared=off)时,guest向rootfs image中的写会发生COW,并不会持久化到后端存储中,只有该guest能看到写后的数据,当guest关机或者销毁后,之前写的数据就会丢失,可以使用MMAP_PRIVATE来共享image给多个guest。
4.1.3 katacontainer
katacontainer是hyperhq的hyper项目和intel clearcontainer项目融合后的的项目,结合了hyper的通用性和clearcontainer的高性能&低开销。katacontainer也继承了两者的目标,打造一个启动速度接近container,又拥有VM的强隔离,支持OCI标准的hypervisor-based container。
以下是katacontainer的组件关系图(来自 https://katacontainers.io/media/uploads/katacontainers/uploads/katacontainers/kata-containers-on-boarding-deck-for-website01022018.pdf)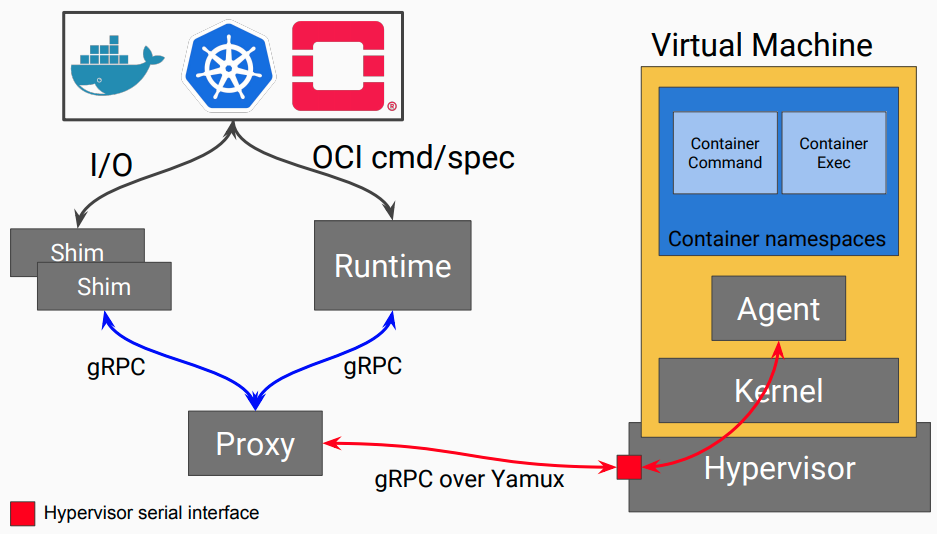
可以看出上图和hyper的组件关系图基本一样,运行在Guest中的Agent类似hyperstart,运行在host上的Proxy类似runv,proxy和agent之间使用hypervisor serial接口通信,对kvm来说就是virito-serial,另外还支持viriot-vsock接口。
后续优化思路
- vhost-9p
用virtio-fs替换。
- nfs over vsock
针对高版本Guest os,nfs over vsock机制会作为优化重点。
- docker增加一个支持qcow2的graph driver+virtio-blk-data-plane
针对老版本的guest os,9pfs支持的不好,考虑增加一个graph driver,以支持qcow2,然后通过模拟qcow2 image的方式share image给guest。
- devicemapper graphdriver- 网络性能优化* SRIOV passthrough + dpdk running in guest + 用户态协议栈* SRIOV passthrough + VT-d posted-interrupt- 跟unikernel的结合- 对windows的支持
考虑到目前跑在windows中的业务类型,对容器的需求可能没那么强烈。
4.1.4 firecracker
4.2 gvisor (sandboxed container)
gvisor应该是深度参考了dune那篇论文的思想以及dune的实现(https://github.com/project-dune/dune),利用硬件辅助虚拟化技术(主要指intel的VT-x)在容器的高性能、低开销和vm的强隔离之间找到一个平衡,相比VM具有更快的启动速度,更低的虚拟化开销,更灵活的资源伸缩,相比container主要是在安全方面做了更好的隔离。
gvisor的运行时包含两个核心的服务,sentry和gopher,sentry对dune做了较多扩展,主要表现在对OCI的支持,以及利用go runtime对go routine的支持,对应用提供了进程/线程的模拟支持。gopher是文件系服务代理。应用的所有系统调用会交给sentry来处理,sentry再根据需要请求host kernel,go runtime也会根据需要请求host kernel(比如 new一个M)。
sentry支持两种模式,ptrace和kvm模式。ptrace模式性能低,安全隔离弱,调测不友好,所以kvm模式应该是后面优化的方向。这里说的kvm模式的中的“kvm”并不是指通用的kvm虚拟化平台,是指借助了内核中现成的kvm相关模块以利用intel vt-x/amd svm技术。
贴一下来自kubecon上的“Container Isolation at Scale”报告中的一个插图,
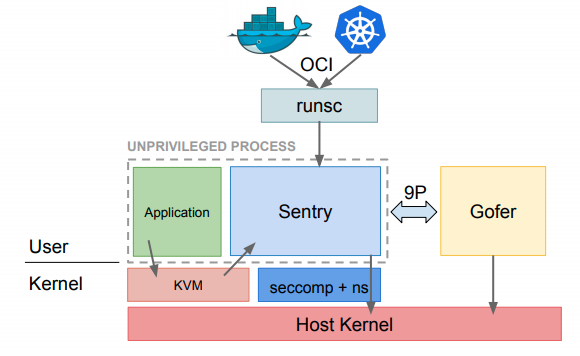
上图可以看出gvisor实现的runsc也是兼容OCI标准的。
gvisor的组件交互图,
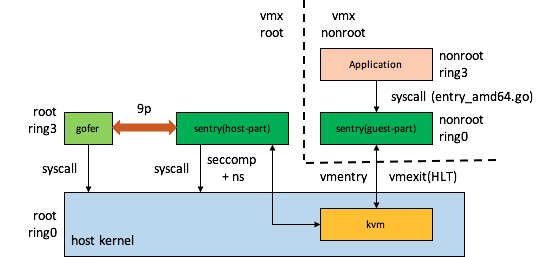
注: 以上是刚接触gvisor时写的,难免有误,目前在搞gvisor的优化,后面会着重介绍其相关技术。
4.3 vm+unikernel的结合
unikernel是相对通用OS(比如linux)来说的,unikernel也是一种比较老的技术了,以前多用于某些专用领域,随着VM技术的兴起,最初搞KVM的那些人(Avi)找到了VM与unikernel的结合点,搞了个叫OSv的unikernel,OSv是一种libos,OSv瞄准的是在VM中跑单应用的场景。因为hypervisor已经提供了VM这层隔离和抽象,guest os这一层提供的隔离和抽象的作用就不是那么大了,或者说不需要通用OS那么强的隔离和抽象了,前提是VM中只跑一个应用。因为只有一个进程,虽然OSv还是使用了虚拟内存,但是不再需要复杂的内存管理,任务调度时也不再需要切换页表。系统调用也不需要ring3和ring0的切换,更不涉及用户空间和内核空间的上下文切换问题。网络协议栈可以做到很精简,不像linux的网络协议栈那么臃肿。这样的结果就是unikernel的性能还是比较高的,尤其是网络性能。
但是unikernel也存在以下比较严重的缺陷,
- 不好调测,单进程模型下不太好使用调测工具
- 不好运维,单进程模型下运维工具和服务(比如监控)不太好用
- 通用性比较差,有些可能需要做代码适配,比如代码中使用了fork,以及访问procfs,sysfs,/dev下的某些文件等
- 能否完全兼容所有的posix接口?
- 是否可以做到支持docker image?
个人认为,unikernel可能更适合某些追求极致性能的个别业务,以及专有领域定制(比如某些嵌入式领域)。
4.4 xcontainer
https://www.csl.cornell.edu/~delimitrou/papers/2019.asplos.xcontainer.pdf
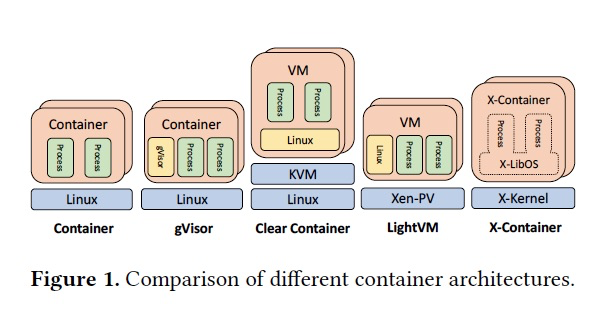
其中,x-Kernel类似一种hyper-kernel,运行在ring0,x-Libos被映射到每个用户进程的地址空间,有点类似SO。用户进程的系统调用被x-Kernel拦截后,x-Kernel将syscall替换为function call,后面就可以直接function call到x-Libos。感觉这个想法挺好的,貌似没有开源。
5 硬件加速/卸载
由于intel的VMX技术比较完善,kvm虚拟化技术在计算虚拟化方面的性能和开销已经做到很好了,接近物理机上的计算性能。但是I/O这一块的虚拟化开销还是很大,尤其是网络I/O和存储I/O在host侧的datapath还会有较多的cpu开销。针对I/O虚拟化开销和性能问题,介绍下下面几个减少host侧I/O虚拟化带来的cpu开销的方案。
5.1 passthrough
passthrough就是我们常说的设备直通,在虚拟化领域算是一个比较老的技术了,严格来说并不能把其归类为硬件卸载。qemu/kvm使用pci-assign/vfio-pci来做设备直通,设备直通示意图如下所示
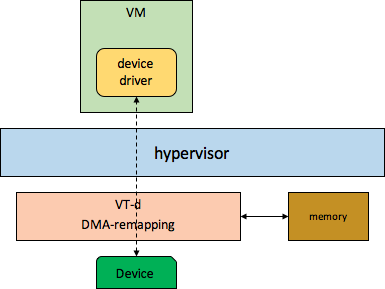
设备直通并不是真的把物理设备直通给VM了,其实VM看到的设备还是qemu模拟的。设备直通主要是把device driver和物理设备之间性能相关的datapath给直接打通了,这个打通工作是qemu帮忙做的,qemu把物理机设备的memroy region通过模拟的设备映射到了guest中,那么guest就可以直接访问直通物理设备的mmio空间。上面说的是VM访问device的数据通道打通了,那么device访问driver提供的内存的通道是靠VT-d的dma-remapping功能打通的,dma-remapping可以把GPA转换成HPA,这样物理设备就可以拿着VM中的device driver提供的GPA进行DMA了。
另外,提起设备直通很多人就会说起SRIOV,甚至等同看待SRIOV和设备直通,从技术上看两者之间并没有直接关系,但是实际产品环境中,设备直通一般都会使用支持SRIOV或者类SRIOV的设备,但是使用SRIOV设备并不一定都是做设备直通,比如前面讲到的macvtap和SRIOV设备的结合,以及SRIOV用于container场景等。为什么设备直通一般使用支持SRIOV或者类SRIOV的设备,主要原因有
- 成本问题
这里说的两本包含两个方面
- 设备本身的成本,如果不使用设备直通,也就意味着一个设备只能直通给VM,VM比较多的情况下,需要的设备就很多,成本太高- 如果是网卡这种设备,如果使用普通设备直通给VM,占用的成本不只是设备本身,另外还有交换机端口,这个成本就高了
- 服务器插槽一般没预留那么多
设备直通也存在一些限制,
- host无法介入直通设备的I/O流程,导致有些控制无法实现,比如ACL之类的
- 相比vswitch方案,passthrough的灵活性要差一些
- 无法对DMA产生的脏内存log dirty,导致像热迁移这种依赖脏内存log dirty的功能无法使用,当然业界也有一些方案来解决/规避passthrough设备log dirty的问题,比如intel OTC提出的使用pv网卡和passthrough网卡一起做bonding的方案,如下所示
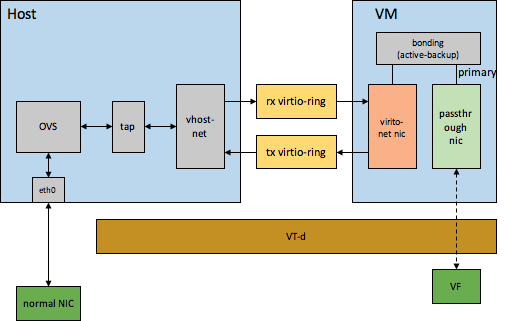
平常运行时,网络流量走passthrough网卡,passthrough网卡做为bonding的primary网卡。热迁移前hot-unplug passthrough网卡,热迁移过程中走virtio网卡,性能稍差些,热迁移完成后,再hot-plug一个passthrough网卡,然后将其加入到bonding中,仍作为primary网卡。
这些方案其实都不是特别优美。
5.2 vdpa(vHost Data Path Acceleration)
vdpa是将host上的vhost-net datapath offload到专门的硬件上。
具体请参考
http://events17.linuxfoundation.org/sites/events/files/slides/KVM17%27-vDPA.pdf
https://www.redhat.com/en/blog/introduction-vdpa-kernel-framework
https://www.redhat.com/en/blog/vdpa-kernel-framework-part-1-vdpa-bus-abstracting-hardware
https://www.redhat.com/en/blog/vdpa-kernel-framework-part-3-usage-vms-and-containers#
5.3 aws nitro/huawei zero
6 总结
随着业务场景&需求、服务提供方式的不断演进,虚拟化相关的底层技术也在不断发展,业界也在尝试提供新的技术或者思路来试图融合hypervisor,container,libos等技术的优势,katacontainer、firecracker是融合VM技术和容器理念,gvisor也是从一种新的思路提供进程级虚拟化的安全容器,xcontainer是融合容器和libos技术。
【引用】
[1] https://www.vmware.com/pdf/virtualization.pdf
[2] https://wiki.xen.org/wiki/Xen_Project_Software_Overview
[3] https://wiki.qemu.org/Documentation/Architecture
[4] https://www.usenix.org/system/files/conference/atc14/atc14-paper-kivity.pdf
[5] https://www.usenix.org/system/files/conference/osdi12/osdi12-final-117.pdf
[6] http://events17.linuxfoundation.org/sites/events/files/slides/KVM17%27-vDPA.pdf
[7] http://nadav.harel.org.il/homepage/papers/paas-2013.pdf
[8] https://www.usenix.org/legacy/event/osdi10/tech/full_papers/Soares.pdf
[9] https://www.usenix.org/system/files/conference/osdi16/osdi16-arnautov.pdf
[10] http://www.cs.unc.edu/~bhushan/graphene-eurosys14.pdf
[11] http://blog.vmsplice.net/2016/01/qemu-internals-how-guest-physical-ram.html
[12] https://software.intel.com/sites/default/files/managed/a4/60/325384-sdm-vol-3abcd.pdf
[13] https://www.slideshare.net/mirantis/openstack-architecture-43160012
[14] https://docs.openstack.org/nova/pike/user/architecture.html
[15] https://docs.openstack.org/glance/pike/contributor/architecture.html
[16] https://docs.openstack.org/project-deploy-guide/openstack-ansible/newton/overview-storage-arch.html
[17] https://github.com/rkuo/NetworkOS/blob/master/Open%20vSwitch%20Tutorial.md
[18] http://hustcat.github.io/an-introduction-to-ovs-architecture/
[19] https://lwn.net/Articles/169961/
[20] http://en.zstack.io/blog/lock-free.html
[21] https://github.com/clearcontainers/vhost-9pfs
[22] https://vmsplice.net/~stefan/stefanha-kvm-forum-2015.pdf
[23] http://smilejay.com/2016/06/virtio-blk-data-plane-configuration/
[24] https://lwn.net/Articles/389023/
[25] https://lwn.net/Articles/405889/
[26] http://man7.org/linux/man-pages/man7/namespaces.7.html
[27] https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt
[28] https://www.kernel.org/doc/Documentation/cgroup-v1/cpusets.txt
[29] http://doc.dpdk.org/guides/howto/virtio_user_for_container_networking.html
[30] https://github.com/qemu/qemu/blob/master/docs/nvdimm.txt
[32] https://schd.ws/hosted_files/kccnceu18/47/Container%20Isolation%20at%20Scale.pdf
[33] https://groups.google.com/forum/m/#!topic/gvisor-users/15FfcCilupo

若有收获,就点个赞吧
0 人点赞
