集合简介
- Scala中有三大类:序列Seq、集Set、映射Map(都是trait),所有集合都扩展自Iterable。而Java中List、Set继承自Collection,Map独立
- 对于所有集合类,Scala提供了可变和不可变的版本,分别位于以下两个包
- 不可变集合: scala.collection.immutable
- 可变集合:scala.collection.mutable
- Scala不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象,而不会对原对象的进行修改,类似java中String
- Scala可变集合,就是指该集合可以直接对原对象进行修改,而不会返回新的对象,类似java中StringBuilder对象
- 建议:在操作集合的时候,不可变用符号,可变用方法
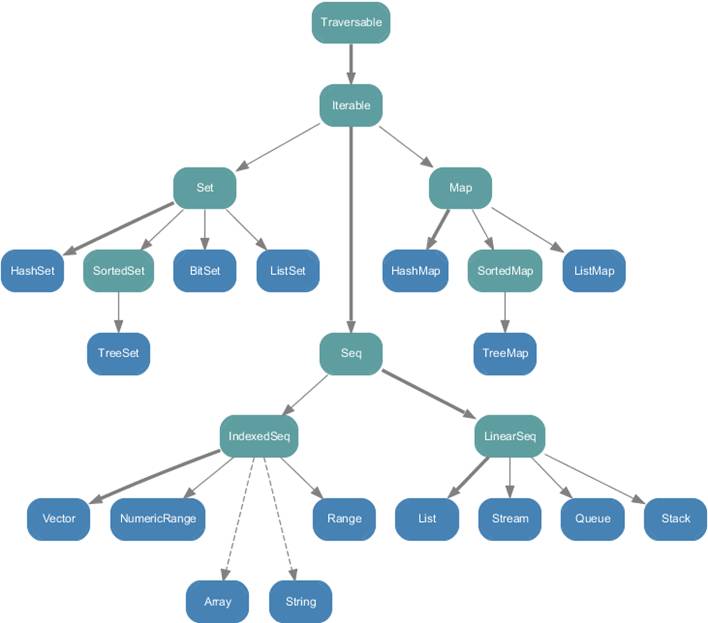
Traversable
是一个特质,他是其它集合的父特质,他的子特质immutable.Traversable和mutable.Traversabel分别是不可变集合和可变集合的父特质。集合中大部分通用方法在这个特质中定义
// 创建空Traversable对象val t1 = Traversable.empty[Int]val t2 = Traversable[Int]()val t3 = Nil// 创建带参数的对象val t1 = List(1, 2, 3).toTraversableval t2 = Traversable(1,2,3)//伴生apply方法// 比较是否不同println(t1 == t2) // 比较集合中的数据println(t1 == t3)println(t3 == t2)println(t1 eq t2) // 比较集合的地址println(t1 eq t3)println(t3 eq t2)
Traversable是一个特质,具体的实现还是依靠子类实现
案例:转置Traversable集合
Traversable集合t1,有三个元素,每个元素都是Traversable集合分别存储(1,4,7),(2,5,8),(3,6,9),进行转置transpose
def main(args: Array[String]): Unit = {val t1: Traversable[Traversable[Int]] = Traversable(Traversable(1,4,7),Traversable(2,5,8),Traversable(3,6,9))val t2: Traversable[Traversable[Int]] = t1.transpose}
案例:拼接集合
创建大量临时集合,使用concat()方法提高效率
def main(args: Array[String]): Unit = {val t1 = Traversable(11, 22, 33)val t2 = Traversable(44, 55)val t3 = Traversable(66,77,88,99)val t4 = Traversable.concat(t1,t2,t3)println(t4) //List(11,22,33,44,55,66,77,88,99)}
案例:利用偏函数筛选元素
collect()
def main(args: Array[String]): Unit = {val t1 = (1 to 10).toTraversable //底层vectorval t2 = Traversable(1,2,3,4,5,6,7,8,9,10) //底层List//筛选所有偶数val pf: PartialFunction[Int, Int] = {case x if x % 2 == 0 => x}val t3 = t1.collect(pf)// 合并val t4 = t2.collect({case x if x % 2 == 0 => x})// t3: Vector(2,4,6,8,10)// t4: List(2,4,6,8,10)}
案例:计算阶乘
def scan[B](z: B)(op: (B, B) => B)
B是返回类型,z是初始化值, op是具体运算函数scan()方法等价于scanLeft方法 相反的 scanRight()
val t1 = Traversable(1,2,3,4,5)val t2 = t1.scan(1)((x: Int, y: Int) => x * y)x: 前一个值的阶乘值 1 1 2 6 24 120y: 表示要计算的下一个数据 1 2 3 4 5val t3 = t1.scan(2)(_ * _)
案例:获取集合指定元素
head: 获取第一个last: 获取最后一个headOption: 获取第一个,返回Option
…find: 查找满足条件第一个元素slice: 截取集合的一部分元素
val t1 = Traversable(1,2,3,4,5,6)println(t1.head)println(t2.headOption)println(t3.find(_ % 2 == 0)) //找到第一个偶数t1.slice(2,5) //包左不包右 List(3, 4, 5)
案例: 元素是否合法
forall() 如果集合中的所有元素都满足指定条件,则返回true, 否则返回false exists()只要有一个满足,就返回true
val t1 = Traversable(1,2,3,4,5,6)t1.forall(_ % 2 == 0)//所有元素都是偶数 falset1.exists(_ % 2 == 0) // 有一个是偶数 true// filter方法用来过滤val t2 = t1.filter(_ % 2 != 0)//返回的是集合t2.size == 0 // false
案例: 聚合函数
count:获取满足条件个数sumproduct: 获取所有元素乘积maxminval t1 = Traversable(1,2,3,4,5,6)println(t1.count(_ % 2 != 0)) //奇数个数println(t1.product) // 720
案例: 集合类型转换
val t1 = (1 to 5).toTraversableval arr = t1.toArray // 这个输出的是数组的地址值!!!val list = t1.toList // 输出的是列表val set = t1.toSet // 输出的是集
案例: 填充元素
fill(): 快速生成指定数量的元素iterate(): 根据条件生成指定个数元素range()方法:生成某个区间内指定间隔的所有数据 ```scala Traversable.fill(5)(“xxx”) //5是元素个数,xxx是填充内容 List(“xxx”,”xxx”,”xxx”,”xxx”,”xxx”) Traversable.fill(3)(Random.nextInt(100)) //包含三个随机数 Traversable.fill(3, 2)(“x”) // List(List(“x”,”x”), List(“x”,”x”), List(“x”,”x”))
Traversable.iterate(1,5)( * 10) // 1是初始值,5是获取元素个数,*10是规则 1 10 100 1000 10000
Traversable.range(1, 21, 5) //包左不包右 5是间隔 不写默认是1 1, 6, 11, 16
<a name="MyY8D"></a>#### 案例:随机学生序列```scalacase class Student(name: String, age: Int)def main(args: Array[String]): Unit = {val names: List[String] = List("张三", "李四", "王五")val r: Random = new Random()val t1: Traversable[Student] = Traversable.fill(3)(new Student(names(r.nextInt(names.size)), r.nextInt(10) + 20)) //年龄范围20~30val t2: List[Student] = t1.toList// 按年龄降序排列val sortList: List[Student] = t2.sortBy(_.age).reverseval sortList = t2.sortWith(_.age > _.age)}
序列Seq
Seq特质代表按序排列的元素序列,特点是有序(存取顺序一致),可重复,有索引
val seq = (1 to 5).toSeq // Range(1,2,3,4,5)
获取长度和元素
val seq = (1 to 5).toSeqprintln(seq.length, seq.size)println(seq(3))println(seq.apply(3))
获取索引值
indexOf(): 获取元素在列表中第一次出现的位置
lastIndexOf: 获取指定元素在列表中最后一次出现的位置
indexWhere: 获取满足条件的元素,在集合中第一次出现的索引
lastIndexWhere: 获取满足条件的元素,在集合中最后一次出现的索引
indexOfSlice: 获取指定的子序列在集合中第一次出现的位置
val s1 = Seq(1,2,4,6,4,3,2)println(s1.indexOf(2)) //1println(s1.lastIndexOf(2)) //6//第一个参数:查找规则, 第二个参数:索引开始位置println(s1.indexWhere(x => x < 5 && x% 2 == 0, 2)) //1println(s1.LastIndexWhere(x => x < 5 && x% 2 == 0)) //6println(s1.indexOfSlice(Seq(1,2))) //0println(s1.indexOfSlce(Seq(1,2),3)) //null
判断是否包含指定数据
- startsWith: 判断是否以指定子序列开头
- endsWith: 判断集合是否以指定序列结尾
- contains: 判断是否包含某个指定的数据
- containsSlice: 判断是否包含某个指定的子序列 ```scala val s1 = (1 to 10).toSeq println(s1.startsWith(Seq(1, 2)))//true println(s1.endWith(Seq(9, 10))) // true
println(s1.contains(3)) //true println(s1.containsSlice(Seq(1,30))) // false
<a name="UQGaM"></a>#### 修改指定元素- updated: 修改指定索引位置的元素为指定的值- patch: 修改指定区间元素为指定的值```scalaval s1 = (1 to 5).toSeqval s2 = s1.updated(2, 10) //2: 修改位置 10:修改后的参数 1,2,10,4,5val s3 = s1.patch(1, Seq(10, 20), 3) // 3:替换几个元素 修改后的参数:1, 10 , 20, 5
数组
不可变数组
// 1. 创建数组val arr: Array[Int] = new Array[Int](5)// 另一种创建方式val arr2 = Array(22,33,44) // 调用了apply方法 Array.apply(22,33,44)// 2. 访问元素println(arr(0)) //0 arr.apply(0)println(arr(1)) //0println(arr(2)) //0arr(0) = 12 // 转换为 arr.update(0, 12)println(arr(0)) //12// 3. 数组的遍历// 普通for循环for (i <- 0 until arr.length) {println(arr(i))}for (i <- arr.indices) println(arr(i))// 增强for循环,直接遍历元素for (elem <- arry2) println(elem)// 迭代器val iter = arr2.iteratorwhile (iter.hasNext)println(iter.next())// 调用foreach方法arr2.foreach( (elemL int) => println(elem) )arr2.foreach(println)println(arr2.mkString("--")) //以--分割
变长数组
import scala.collection.mutable.ArrayBuffer// 定义一个长度为0 的变长数组val arr1 = ArrayBuffer[Int]()val arr2 = ArrayBuffer("hadoop", "storm", "spark")arr2 += "flume" //增加元素arr2 -= "hadoop" //删除元素// 将一个包含多个元素的数组,追加到变长数组中arr2 ++= Array("hive", "sqoop")arr2 --= Array("sqoop", "spark")println(arr2)
数组工具
val arr1 = Array(4, 1, 5, 6, 3)//求和println(s"sum: ${arr1.sum}")//最大值arr1.max//最小值arr2.min//排序升序val arr2 = arr1.sorted//反转val arr3 = arr1.reverse// 降序:先升序排再反转
元组
元组用来存储多个不同类型的值,例如同时存储姓名、年龄、性别等。元组元素和长度不可变
- 格式一:val 元组 = (元素1, 元素2,元素3……)
- 格式二:val 元组 = 元素1 -> 元素2 只适用于元组中两个元素的情况
访问元组中的元素
```scala val tuple1 = “zhangsan” -> “male”
// 方式一 拖过 _编号 获取,第一个元素从1开始 println(tuple1._1) println(tuple1._2)
// 方式二 通过迭代器 val it = tuple1.productIterator for(i <- it) println(i)
<a name="D2gs0"></a>## 列表特点:有序(存入和取出顺序一样)可重复<br />分为不可变列表和可变列表<a name="QHzJ7"></a>### 不可变列表列表元素、长度都是不可变的```scala// 方式一val list1 = List(1, 2, 3, 4)// 方式二 :不可变的空列表val list2 = Nil// 方式三val list3 = -1 :: -2 :: Nil
可变列表
import scala.collection.mutable.ListBuffer// 可变集合都在mutable中不可变再immutable包中(默认导入)val list1 = ListBuffer[Int]()val list2 = ListBuffer(1, 2, 3, 4)list1(0) = 3 //修改元素list2 += 4 //添加元素list2 ++= List(2,4,6) // 追加列表list -= 3 // 删除元素list --= List(2,4)val list3 = list2.toList // 变为不可变列表val arr = list2.toArray //
列表常用操作
基础操作
val list1 = List(1, 2, 3, 4)val list2 = List(4, 5, 6)// 判空println(list1.isEmpty()) //false// 拼接返回新的列表val list3 = list1 ++ list2// 获取首个元素println(list1.head) //1// 获取除首个元素外的其它所有元素println(list1.tail) // List(2, 3, 4)// 对列表进行反转,返回一个新的println(list1.reverse) //List(4, 3, 2, 1)// 获取列表中的前缀元素 表示前三个是前缀println(list1.take(3)) //List(1,2,3)// 获取后缀元素 表示前三个是前缀println(list1.drop(3)) // List(4)
扁平化
将嵌套列表的元素单独放到新列表中
val list1 = List(List(1, 2), List(3), List(4, 5))val list2 = list1.flatten // 转变为了List(1,2,3,4,5)
拉链与拉开
- 拉链:将两个列表组合成一个元素为元组的列表
- 拉开:将一个包含元组的列表,拆解成包含两个列表的元组 ```scala val names = List(“张三”, “李四”, “王五”) val ages = List(23, 24, 25) // 拉链操作 val list1 = names.zip(ages) // List((“张三”,23), (“李四”,24), (“王五”,25)) // 拉开 val tuple1 = list1.unzip // (List(“张三”, “李四”, “王五”), List(23, 24, 25))
<a name="2TSVm"></a>#### 列表转字符串```scalaval list1 = List(1, 2, 3, 4)println(list1.toString) // List(1, 2, 3, 4)println(list1) // 可省略,默认调用对象的toString方法println(list1.mkString(":")) // 1:2:3:4 用指定符号分隔
并集、交集、差集
val list1 = List(1, 2, 3, 4)val list2 = List(3, 4, 5, 6)// 并集val unionList = list1.union(list2) // 1,2,3,4,3,4,5,6val distinctList = unionList.distinct //去重 1, 2, 3, 4, 5, 6// 交集val intersectList = list1.intersect(list2) // 3,4// 差集val diffList = list1.diff(list2) // 1, 2
Stack
先进后出,immutable.Stack已经被弃用了,最常用的还是可变栈mutable.Stack, mutable.ArrayStack
top获取栈顶元素push入栈操作pop出栈操作clear移除集合所有元素- immutable.Stack独有方法pushAll()把多个元素压入栈
- mutable.ArrayStack独有方法:
dup复制栈顶元素preserving:执行一个表达式,执行完毕后恢复栈,即回到调用前
Stack可变栈
val s1 = mutable.Stack(1,2,3,4,5)println(s1) // Stack(1,2,3,4,5) Scala从后往前添加,栈顶元素是1println(s1.top) //1println(s1.push(6)) // Stack(6,1,2,3,4,5)println(s1.pushAll(Seq(11,22,33))) // 33,22,11,6,1,2,3,4,5println(s1.pop()) //33println(s1.clear) //Stack()
ArrayStack可变栈
val s1 = mutable.ArrayStack(1, 2, 3, 4, 5)println(s1) // ArrayStack(1, 2, 3, 4, 5)s1.dup()println(s1) // ArrayStack(1, 1, 2, 3, 4, 5)// 实现先情况集合元素,再回复集合中清除的数据s1.presercing({s1.clear()println("执行了吗")})println(s1) // 执行了吗 ArrayStack(1, 1, 2, 3, 4, 5)
Queue
队列先进先出
enqueue入队方法,可以传零到多个元素dequeue出队列, 移除一个元素dequeueAll移除所有满足条件元素dequeueFirst移除第一个满足条件元素val q1 = mutable.Queue(1, 2, 3, 4, 5)q1.enqueue(6)q1.enqueue(7,8,9)println(q1) // Queue(1,2,3,4,5,6,7,8,9)println(q1.dequeue()) //1println(q1.dequeueFirst(_ % 2 != 0)) //Some(3)println(q1.dequeueAll(_ % 2 == 0)) //ArrayBuffer(2,4,6,8)println(q1) // Queue(5,7,9)
集Set
Set代表没有重复的集合,唯一、无序
默认不可变集
- HashSet前缀树,元素唯一,无序
- LinkedHashSet唯一,有序
- TreeSet唯一,排序
val s1 = SortedSet(1, 4, 3, 2, 5)println(s1) // TreeSet(1,2,3,4,5)val s2 = mutable.HashSet(1, 4, 3, 2, 5)println(s2) // Set(1,5,2,3,4)val s3 = mutable.LinkedHashSet(1, 4, 3, 2, 5)println(s3) // Set(1,4,3,2,5)
不可变集
创建不可变集
```scala val set1 = SetInt
val set2 = Set(1, 1, 3, 2, 4)
println(s”set1: $set1”) // set1: Set() println(s”set2: $set2”) // set2: Set(1, 4, 3, 2) 无序 不重复
<a name="RYTrD"></a>#### 不可变集的常见操作```scalaval set1 = Set(1,1,2,3,4,5)// 获取大小println(set1.size) //5 删掉了一个1//遍历集for(i <- set1) println(i)// 删除元素1println(set1 - 1) // 5,2,3,4// 拼接另一个集val set3 = set1 ++ Set(6, 7, 8)println(set3) // 5,1,6,2,7,3,8,4// 拼接列表val set4 = set1 ++ List(6,7,8,9)println(set4) // 5,1,6,9,2,7,3,8,4
可变集
元素、集长度都可变
import scala.collection.mutable.Setval set1 = Set(1, 2, 3, 4)set1 += 5set1 ++= List(6,7,8)set1 -= 1set1 --= List(3,5,7)println(set1)
映射Map
Map,键值对组成的集合,键具有唯一性,但值可重复
默认是不可变map
val map = Map("A" -> 1, "B" -> 2, "C" -> 3)for((k, v) <- map) println(k, v)map.foreach(println(_))println(map.filterKeys(_ == "B")
不可变Map
不可变Map指元素长度都不可变
- val map = Map(键->值, 键->值, 键->值, 键->值)
- val map = Map((键,值),(键,值),(键,值)) 不推荐
val map1 = Map("张三" -> 23, "李四" -> 24, "李四" -> 40) // 40就被覆盖了
可变Map
```scala import scala.collection.mutable.Map
val map1 = Map(“张三” -> 23, “李四” -> 24)
map1(“张三”) = 30
<a name="NJKnO"></a>### Map基本操作```scalaval map1 = Map("张三" -> 23, "李四" -> 24)// 通过键查找值println(map1("张三")) // 23// 获取所有键println(map1.keys) // "张三" "李四"//获取所有值println(map1.values) ////遍历for((k, v) <- map1) println(k,v)// 通过键获取一个值,如果键不存在,返回一个值println(map1.getOrElse("王五",-1))// 增加一组数据(不可变)val map2 = map1 + "王五" -> 25//增加一组数据(可变)import scala.collection.mutable.Mapval map3 = mutable.Map("张三" -> 23, "李四" -> 24)map3 += "王五" -> 25=//删除一组数据(可变)map3 -= "王五"
迭代器
Scala对每一类集合都提供了迭代器
Iterable代表一个可迭代的集合,继承自Traversable特质,是其它集合的父特质,获得了iterator方法(抽象方法,需要具体集合类实现)
- iterator()属于主动迭代,可以通过next(),hasNext()自主控制迭代
- foreach()属于被动迭代,由集合本身控制 ```scala val list1 = List(1, 2, 3, 4, 5)
// 使用迭代器遍历 val it:Iterator[Int] = list1.iterator while(it.hasNext) { println(it.next()) } //迭代器已经迭代完毕 println(it.next()) // NoSuchElementException
//foreach遍历 //list1.foreach((x:Int)=>println(x)) list1.foreach(println(_))
<a name="fHHo4"></a>#### 案例:分组遍历def grouped(size: Int): Iterator[Iterable[A]]```scalaval list = (1 to 13).toIterableval it = list.grouped(5)val b1 = it.hasNextif(b1) {val result1 = it.next()println(b1, result1) // (true, Vector(1, 2, 3, 4, 5))}val b2 = it.hasNextif(b2) {val result1 = it.next()println(b1, result1) // (true, Vector(6,7,8,9,10))}val b3 = it.hasNextif(b3) {val result1 = it.next()println(b1, result1) // (true, Vector(11,12,13))}val b4 = it.hasNextval result1 = it.next() //NoSuchElementException// 合并while(it.hasNext) {val result = it.next()println(result)}
案例:按照索引生成元组
zipWithIndex()
val list1 = Iterable("A","B","C","D","E")val list2: Iterable[(String, Int)] = list1.zipWithIndex //List((A,0),(B,1),(C,2),(D,3),(E,4))val list3: Iterable[(Int, String)] = list2.map(x => x._2 -> x._1)list3.foreach(println(_))
案例: 判断集合是否相同
sameElements() 判断集合中元素及元素迭代顺序是否一致
val list1 = Iterable("A","B","C")println(list1.sameElements(Iterable("A","C","B"))) // falseval hs = HashSet(1, 2)val ts = TreeSet(2, 1) // TreeSet会默认升序println(hs.sameElements(ts)) //true
集合相关函数
遍历(foreach)
def foreach(f:(A) => Unit): Unit
val list1 = List(1, 2, 3, 4)list1.foreach((x: Int) => {println(x)})
简化函数定义
- 通过类型推断简化函数
list1.foreach(x => println(x))
- 通过下划线简化函数
函数参数只在函数体中出现一次,且没有复杂使用list1.foreach(println(_))
映射(map)
集合映射操作时将一种数据类型转换为另一种类型的过程def map[B](f: (A) => B): TraversableOnce[B]
val list1 = List(1, 2, 3, 4)// 将对应的数字转换为*个数val list2 = list1.map((x: Int) => {"*" * x})//类型推断val list3 = list1.map(a => "*" * a)// 下划线val list4 = list1.map("*" * _)println(list2)// List(*, **, ***, ****)
扁平化映射(flatMap)
扁平化映射可以理解为先map,然后flattendef flatMap[B](f:(A) => GenTraversableOnce[B]): TraversableOnce[B]
// 有一个长字符串列表,获取文本中的每一个单词,并将每一个单词放到列表中val list1 = List("hadoop hive spark flink flume", "kudu hbase sqoop storm")// 方式一val list2 = list1.map((x:String) => {x.split(" ")}) // 将每一个元素,按空格分割成数组// List(Array("hadoop",hive","spark","flink","flume"), Array(....))val list3 = list2.flatten// List("hadoop","hive",...)// 方式二 直接实现val list4 = list1.flatMap((x:String) => {x.split(" ")})val list5 = list1.flatMap(_.split(" "))
过滤
过滤出符合一定条件的元素def filter(f:(A) => Boolean): TraversableOnce[A]
val list1 = (1 to 9).toList// 过滤出所有偶数val list2 = list1.filter(x => x % 2 == 0)val list3 = list1.filter(_ % 2 == 0)
排序
默认排序(sorted)
升序排列,降序通过升序后reverse实现
val list1 = List(3, 1, 2, 9, 7)val list2 = list1.sortedval list3 = list2.reverse
指定字段排序
列表元素根据传入的函数转换后,再进行排序(升序)def sortBy[B](f:(A)=>B): List[A]
val list1 = List("01 hadoop", "02 flume", "03 hive", "04 spark")val list2 = list1.sortBy(x => x.split(" ")(1))// x.split(" ")表示 Array("01", "hadoop"), Array("02","flume")...// x.split(" ")(1)表示每个数组中第二个元素 "hadoop" "flume" ...println(list2) //List(02 flume, 01 hadoop", 03 hive", 04 spark)
自定义排序
根据自定义函数规则进行排序
传入一个比较大小的函数对象,接受两个集合类型的元素参数,返回两个元素大小,小于返回true,大于返回falsedef sortWith(f: (A, A) => Boolean): List[A]
val list1 = List(2,3,1,6,5,4)// 降序排列val list2 = list1.sortWith((x, y) => x > y)val list2 = list1.sortWith(_ > _)println(s"list2: ${list2}")// List(6, 5, 4, 3, 2, 1)
分组
val list1 = List("刘德华"->"男", "刘亦菲"->"女","hqw"->"男")//安照性别分组val map1 = list1.groupBy(x => x._2)// 优化成这样val map1 = list1.groupBy(_._2)// Map("男" -> List(刘德华"->"男","hqw"->"男"), "女" -> List("刘亦菲"->"女"))//统计不同性别的学生人数val map2 = map1.map(x => x._1 -> x._2.size)
聚合
val list1 = (1 to 10).toListval list2 = list1.reduce(_ + _) // (x,y)=>x+yval list3 = list1.reduceLeft(_ + _) //从左往右val list4 = list1.reduceRight(_ + _) //从右往左val list5 = list1.reduceRight(_ - _)/*第一次:9 - 10 = -1第二次:8 - -1 = 9...*/
案例:学生成绩
object test {def main(args: Array[String]): Unit = {// 定义列表val stuList = List(("张三", 34, 22, 44),("李四",22,44,55),("王五", 44, 55, 66))// 获取语文成绩60以上的学生val chineseLise = stuList.filter(x => x._2 >= 60)// 获取总成绩val countList = stuList.map(x => x._1 -> (x._2 + x._3 + x._4))// 按总成绩排列val sortList = countList.sortWith((x, y) => x._2 > y._2)
案例: 统计字符个数
println("请录入字符串:")val str = StdIn.readLine()val map = mutable.Map[Char, Int]()//转为字符数组val chs = str.toCharArrayfor (k <- chs) {if (!map.contains(k)) {// 如果字符第一次出现,将其记录为1map += (k -> 1)} else {map += (k -> (map.getOrElse(k, 1) + 1))}}map.foreach(println(_))

若有收获,就点个赞吧
0 人点赞
