语音交互 JS SDK 的目标是封装领域操作,让你不需要语音相关的领域知识,就可以在你项目中使用语音识别、语音合成等语音交互功能。
SDK 主要做了以下几件事件:
- 封装 WebRTC、Web Audio API 的调用。SDK 中实时录音与流式播放的功能实现,都依赖了 WebRTC 与 Web Audio API,而这些 API 并不是前端开发的常用 API,上手会有一定成本,而在 SDK 层抹平将会大大提高易用性;
- 音频降采样。浏览器默认录音一般是 41.1 KHz 音频,而语音识别通常使用 16 KHz 音频,这里涉及到前端实现降采样算法,而降采样算法并没有标准 JS 库,并且不同的降采样实现对音质的影响又会产生差异,这种差异会放大地表现在识别结果上。所以在 SDK 内部提供的降采样将会解决这些问题,不会把问题抛给你;
- 保持与语音服务网关的通信。与网关的通信涉及到一系列自定义协议,包括
指令与事件,实现这套协议需要先对协议做一些了解,再花一定时间实现与调试。但在 SDK 中实现自定义协议后,你只需要针对 SDK 抛出的事件,来实现对应处理函数,就像给click写onClick函数一样。基本不需要知道网关的存在。
整体架构
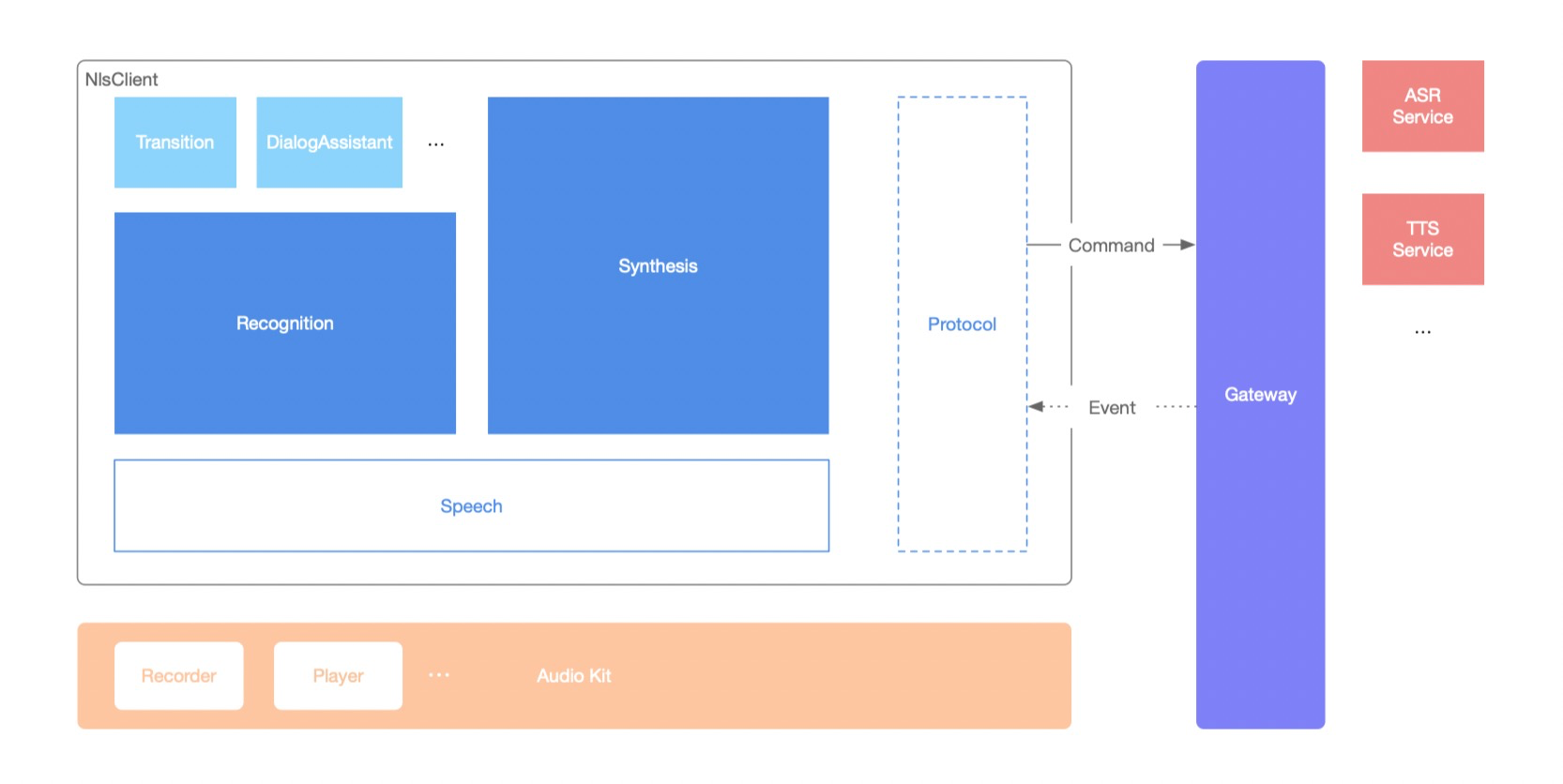
NlsClient 即 SDK 的对外实现。主要包含语音识别(Recognition)与语音合成(Synthesis)两个功能模块,它们都基于语音基础类 Speech 来实现。而 SDK 中的协议层则负责与网关保持 WebSocket 链接,并且实现自定义协议来完成通信。
由于基于语音识别还可以实现更多语音交互功能,包括但不限于同声传译(Transition)、对话助手(DialogAssistant)等,这些功能可以使用插件方式扩展语音识别来满足需求。
此外还有一个包含语音常用工具的 AudioKit 库,SDK 内部的实时录音、流式播放实现都由该库来提供。

若有收获,就点个赞吧
0 人点赞
