题目信息
X老师上课讲了Robots协议,小宁同学却上课打了瞌睡,赶紧来教教小宁Robots协议是什么吧。
题目分析
这里帮助我们了解robots协议。Robots协议用来告知搜索引擎哪些页面能被抓取,哪些页面不能被抓取。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。当 一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
文件写法
User-agent: 这里的代表的所有的搜索引擎种类,是一个通配符
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
Disallow: /?* 禁止访问网站中所有包含问号 (?) 的网址
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以”.htm”为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
题目解法
解法一:
直接把所给网站后缀改为robots.txt查看。
显示为:

这里发现了禁止访问flag_1s_h3re.php。改后缀尝试访问该网址。得到flag。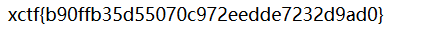
解法二:
用扫目录的脚本跑一波。扫目录脚本dirsearch(项目地址:https://github.com/maurosoria/dirsearch)
想到robots.txt,扫目录也可以扫到:
python
python3 dirsearch.py -u http://10.10.10.175:32793/ -e *

访问robots.txt再访问flag_1s_h3re.php即可。

若有收获,就点个赞吧
0 人点赞
