- Spark常用的端口?
7077 : spark 的master与worker进行通讯的端口 standalone集群提交Application的端口
8080 : master的WEB UI端口 资源调度
8081 : worker的WEB UI 端口 资源调度
4040 : Driver的WEB UI 端口 任务调度
18080:Spark History Server的WEB UI 端口
Spark的master和worker之间通过什么方式通信的?
Akka
Spark手写一个wordcount
val conf: SparkConf =
new SparkConf().setMaster(“local[*]”).setAppName(“WordCount”)
val sc = new SparkContext(conf)
sc.textFile(“/input”)
.flatMap(.split(“ “))
.map((, 1))
.reduceByKey( + )
.saveAsTextFile(“/output”)
sc.stop()
- Spark手写一个topN
方法1:
(1)按照key对数据进行聚合(groupByKey)
(2)将value转换为数组,利用scala的sortBy或者sortWith进行排序(mapValues)数据量太大,会OOM。
方法2:
(1)取出所有的key
(2)对key进行迭代,每次取出一个key利用spark的排序算子进行排序
方法3:
(1)自定义分区器,按照key进行分区,使不同的key进到不同的分区
(2)对每个分区运用spark的排序算子进行排序
4.10.22 京东:调优之前与调优之后性能的详细对比(例如调整map个数,map个数之前多少、之后多少,有什么提升)
这里举个例子。比如我们有几百个文件,会有几百个map出现,读取之后进行join操作,会非常的慢。这个时候我们可以进行coalesce操作,比如240个map,我们合成60个map,也就是窄依赖。这样再shuffle,过程产生的文件数会大大减少。提高join的时间性能。
Spark怎么实现实时查看用户的访问数?实时变动的需求怎么实现的?
Spark的并行度怎么设置的?
- Spark的一个executor给多大的内存?为什么?
以上两个问题的答案
1、Spark性能调优之资源分配 大体上这两个方面:core mem
(1)、分配哪些资源?
executor、core per executor、memory per executor、driver memory
(2)、在哪里分配这些资源?
在我们在生产环境中,提交spark作业时,用的spark-submit shell脚本,里面调整对应的参数
/usr/local/spark/bin/spark-submit \
—class cn.spark.sparktest.core.WordCountCluster \
—num-executors 3 \ 配置executor的数量
—executor-memory 100m \ 配置每个executor的内存大小
—executor-cores 3 \ 配置每个executor的cpu core数量
—driver-memory 100m \ 配置driver的内存(影响很大)
/usr/local/SparkTest-0.0.1-SNAPSHOT-jar-with-dependencies.jar \
(3)、调节到多大,算是最大呢?
Spark Standalone 6-8G 4-6cpu core 20台机器 executor 20 每个executor 6-8g 4-6cpu
第一种,Spark Standalone,公司集群上,搭建了一套Spark集群,你心里应该清楚每台机器还能够
给你使用的,大概有多少内存,多少cpu core;那么,设置的时候,就根据这个实际的情况,
去调节每个spark作业的资源分配。比如说你的每台机器能够给你使用4G内存,2个cpu core;
20台机器;executor,20;平均每个executor:4G内存,2个cpu core。
案例:
Spark on Yarn 500g内存 100cpu executor 50 每个executor10g 2个cpu
第二种,Yarn。资源队列。资源调度。应该去查看,你的spark作业,要提交到的资源队列,
hadoop spark storm 每一个队列都有各自的资源(cpu mem)
大概有多少资源?500G内存,100个cpu core;executor,50;平均每个executor:10G内存,2个cpu core。
(4)、为什么调节了资源以后,性能可以提升?
增加executor:
如果executor数量比较少,那么,能够并行执行的task数量就比较少,就意味着,我们的Application的并行执行的能力就很弱。
比如有3个executor,每个executor有2个cpu core,那么同时能够并行执行的task,就是6个。6个执行完以后,再换下一批6个task。增加了executor数量以后,那么,就意味着,能够并行执行的task数量,也就变多了。比如原先是6个,现在可能可以并行执行10个,甚至20个,100个。那么并行能力就比之前提升了数倍,数十倍。相应的,性能(执行的速度),也能提升数倍~数十倍。
增加每个executor的cpu core:
也是增加了执行的并行能力。原本20个executor,每个才2个cpu core。能够并行执行的task数量,
就是40个task。现在每个executor的cpu core,增加到了5个。能够并行执行的task数量,就是100个task。执行的速度,提升了2倍左右。
增加每个executor的内存量:
增加了内存量以后,对性能的提升,有三点:
1、如果需要对RDD进行cache,那么更多的内存,就可以缓存更多的数据,将更少的数据写入磁盘,
甚至不写入磁盘。减少了磁盘IO。
2、对于shuffle操作,reduce端,会需要内存来存放拉取的数据并进行聚合。如果内存不够,也会写入磁盘。如果给executor分配更多内存以后,就有更少的数据,需要写入磁盘,甚至不需要写入磁盘。减少了磁盘IO,提升了性能。
3、对于task的执行,可能会创建很多对象。如果内存比较小,可能会频繁导致JVM堆内存满了,
然后频繁GC,垃圾回收,minor GC和full GC。(速度很慢)。内存加大以后,带来更少的GC,垃圾回收,避免了速度变慢,性能提升。
2、分区个数和task个数的关系
(1)、RDD在计算的时候,每个分区都会起一个task,所以rdd的分区数目决定了总的的task数目。
申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的task。
每个节点可以起一个或多个Executor。
每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
每个Task执行的结果就是生成了目标RDD的一个partiton。
Task被执行的并发度 = Executor数目(SPARK_EXECUTOR_INSTANCES) * 每个Executor核数(SPARK_EXECUTOR_CORES)
3、Spark性能调优之合理设置并行度
(1)、Spark的并行度指的是什么?
spark作业中,各个stage的task的数量,也就代表了spark作业在各个阶段stage的并行度!
当分配完所能分配的最大资源了,然后对应资源去调节程序的并行度,如果并行度没有与资源相匹配,那么导致你分配下去的资源都浪费掉了。同时并行运行,还可以让每个task要处理的数量变少(很简单的原理。合理设置并行度,可以充分利用集群资源,减少每个task处理数据量,而增加性能加快运行速度。)举例:假如, 现在已经在spark-submit 脚本里面,给我们的spark作业分配了足够多的资源,比如50个executor ,每个executor 有10G内存,每个executor有3个cpu core 。 基本已经达到了集群或者yarn队列的资源上限。
task没有设置,或者设置的很少,比如就设置了,100个task 。 50个executor ,每个executor 有3个core ,也就是说
Application 任何一个stage运行的时候,都有总数150个cpu core ,可以并行运行。但是,你现在只有100个task ,平均分配一下,每个executor 分配到2个task,ok,那么同时在运行的task,只有100个task,每个executor 只会并行运行 2个task。 每个executor 剩下的一个cpu core 就浪费掉了!你的资源,虽然分配充足了,但是问题是, 并行度没有与资源相匹配,导致你分配下去的资源都浪费掉了。合理的并行度的设置,应该要设置的足够大,大到可以完全合理的利用你的集群资源; 比如上面的例子,总共集群有150个cpu core ,可以并行运行150个task。那么你就应该将你的Application 的并行度,至少设置成150个,才能完全有效的利用你的集群资源,让150个task ,并行执行,而且task增加到150个以后,即可以同时并行运行,还可以让每个task要处理的数量变少; 比如总共 150G 的数据要处理, 如果是100个task ,每个task 要计算1.5G的数据。 现在增加到150个task,每个task只要处理1G数据。
(2)、如何去提高并行度?
1、task数量,至少设置成与spark Application 的总cpu core 数量相同(最理性情况,150个core,分配150task,一起运行,差不多同一时间运行完毕)官方推荐,task数量,设置成spark Application 总cpu core数量的2~3倍 ,比如150个cpu core ,基本设置 task数量为 300~ 500. 与理性情况不同的,有些task 会运行快一点,比如50s 就完了,有些task 可能会慢一点,要一分半才运行完,所以如果你的task数量,刚好设置的跟cpu core 数量相同,可能会导致资源的浪费,因为 比如150task ,10个先运行完了,剩余140个还在运行,但是这个时候,就有10个cpu core空闲出来了,导致浪费。如果设置2~3倍,那么一个task运行完以后,另外一个task马上补上来,尽量让cpu core不要空闲。同时尽量提升spark运行效率和速度。提升性能。
2、如何设置一个Spark Application的并行度?spark.defalut.parallelism 默认是没有值的,如果设置了值比如说10,是在shuffle的过程才会起作用(val rdd2 = rdd1.reduceByKey(_+_) //rdd2的分区数就是10,rdd1的分区数不受这个参数的影响)new SparkConf().set(“spark.defalut.parallelism”,”“500)4、RDD.repartition,给RDD重新设置partition的数量5、reduceByKey的算子指定partition的数量val rdd2 = rdd1.reduceByKey(_+_,10) val rdd3 = rdd2.map.filter.reduceByKey(_+_)6、val rdd3 = rdd1.join(rdd2) rdd3里面partiiton的数量是由父RDD中最多的partition数量来决定,因此使用join算子的时候,增加父RDD中partition的数量。
SparkStreaming+Kafka实时计算 端到端 如何实现的ExactlyOnce?版本号?
Spark2.1.0、Kafka 0.10.2、Scala 2.11.8
方案一:利用关系型数据库的事务进行处理
出现丢失或者重复的问题,核心就是偏移量的提交与数据的保存,不是原子性的。如果能做成要么数据保存和偏移量都成功,要么两个失败。那么就不会出现丢失或者重复了。
这样的话可以把存数据和偏移量放到一个事务里。这样就做到前面的成功,如果后面做失败了,就回滚前面那么就达成了原子性。
问题与限制数据库选型受限, 只能使用支持事务的关系型数据库 ,如mysql, oracle ,无法使用其他功能强大的nosql数据库。
- 如果保存的数据量较大一个数据库节点不够,多个节点的话,还要考虑分布式事务的问题。做分布式事务,结构复杂,拖慢性能。
- 如果做本地事务 ,只能把分区数据提取到driver中进行保存,降低并发 ,增加executor到driver的数据传递io。
方案二:手动提交偏移量+幂等性处理
咱们知道如果能够同时解决数据丢失和数据重复问题,就等于做到了精确一次消费。
那咱们就各个击破。
首先解决数据丢失问题,办法就是要等数据保存成功后再提交偏移量,所以就必须手工来控制偏移量的提交时机。
但是如果数据保存了,没等偏移量提交进程挂了,数据会被重复消费。怎么办?那就要把数据的保存做成幂等性保存。即同一批数据反复保存多次,数据不会翻倍,保存一次和保存一百次的效果是一样的。如果能做到这个,就达到了幂等性保存,就不用担心数据会重复了。
难点
话虽如此,在实际的开发中手动提交偏移量其实不难,难的是幂等性的保存,有的时候并不一定能保证。所以有的时候只能优先保证的数据不丢失。数据重复难以避免。即只保证了至少一次消费的语义。
- SparkStreaming 活动窗口大小怎么设置的?数据重复了怎么办?数据丢失了怎么办?
1.数据丢失问题
receiver模式:
(该部分比较简单,可以跳过)
丢失原因:
首先,receiver task 接收 kafka 中的数据,并备份到其他 executor 中的blockmanager里,然后将偏移量提交给 zookeeper ,接着 存在备份的 executor 将数据的地址封装并发送到 driver 中的 receiver tracker,然后由 driver 发送 task ,以及监测任务执行和回收结果。
在这个过程中,如果数据已经提交到了 zookeeper ,此时,driver 挂了,executor 也会被 kill 掉,当 driver 重启时,内存中就没有数据的地址信息了,而且kafka 会从新的偏移量处发送数据,即发生数据丢失。
解决方案:
开启 WAL 机制,在数据备份的时候,同时将数据拷贝一份到 hdfs ,等数据备份完成之后,再提交偏移量。同时,driver启动时,如果 hdfs 上存在未消费的数据,则先消费该数据。
这样,即使zookeeper 提交偏移量之后 driver 挂了,当driver重启之后,依旧能从hdfs 上消费数据。
存在问题:
开启WAL机制可能导致数据重复消费等问题。
direct模式:
sparkstreaming 2.2 direct 模式采用的是kafka的 simple consumer api,该情况下,偏移量可以手动管理,只要保证数据都消费之后再提交偏移量,就不存在数据丢失问题。
2.数据重复消费问题:
receiver模式:
原因:
开启 WAL 机制后,如果数据成功备份到 hdfs 之后,driver 挂了,此时偏移量还未提交给 zookeeper,重启时,
driver会先消费 hdfs 中的数据,由于偏移量未提交,该数据会再次接收并消费。
解决方案:
以Receiver基于ZooKeeper的方式,当读取数据时去访问Kafka的元数据信息,在处理代码中例如foreachRDD或
transform时,将信息写入到内存数据库中(memorySet)
,在计算时读取内存数据库信息,判断是否已处理过,如果以处理过则跳过计算。这些元数据信息可以保存到内存数据结构或者memsql,sqllite中。
direct模式:
原因:
偏移量手动提交到 redis ,这种情况下,当数据处理完成之后,还未提交偏移量,此时如果发生故障,则会导致数据重复消费。
解决方案:
通过事务控制,如写一个 jdbc 事务。将业务逻辑,偏移量的提交放在一个事务中。
SparkStreaming如何处理数据积压的问题?反压机制的令牌桶算法怎么回事?
1.1 反压定义
当批处理时间(Batch Processing Time)大于批次间隔(Batch Interval,即 BatchDuration)时,说明处理数据的速度小于数据摄入的速度,持续时间过长或源头数据暴增,容易造成数据在内存中堆积,最终导致Executor OOM或任务奔溃。
1.2 反压的数据源方式及限流处理
spark streaming的数据源方式有两种:
若是基于Receiver的数据源,可以通过设置spark.streaming.receiver.maxRate来控制最大输入速率;
- 若是基于Direct的数据源(如Kafka Direct Stream),则可以通过设置spark.streaming.kafka.maxRatePerPartition来控制最大输入速率。
当然,在事先经过压测,且流量高峰不会超过预期的情况下,设置这些参数一般没什么问题。但最大值,不代表是最优值,最好还能根据每个批次处理情况来动态预估下个批次最优速率。
在Spark 1.5.0以上,就可通过背压机制来实现。开启反压机制,即设置spark.streaming.backpressure.enabled为true,Spark Streaming会自动根据处理能力来调整输入速率,从而在流量高峰时仍能保证最大的吞吐和性能。
2. 反压机制相关参数
| 参数名称 | 默认值 | 说明 |
|---|---|---|
| spark.streaming.backpressure.enabled | false | 是否启用反压机制 |
| spark.streaming.backpressure.initialRate | 无 | 初始最大接收速率。只适用于Receiver Stream,不适用于Direct Stream。 |
| spark.streaming.backpressure.rateEstimator | pid | 速率控制器,Spark 默认只支持此控制器,可自定义。 |
| spark.streaming.backpressure.pid.proportional | 1.0 | 只能为非负值。当前速率与最后一批速率之间的差值对总控制信号贡献的权重。用默认值即可。 |
| spark.streaming.backpressure.pid.integral | 0.2 | 只能为非负值。比例误差累积对总控制信号贡献的权重。用默认值即可 |
| spark.streaming.backpressure.pid.derived | 0 | 只能为非负值。比例误差变化对总控制信号贡献的权重。用默认值即可 |
| spark.streaming.backpressure.pid.minRate | 100 | 只能为正数,最小速率 |
3. 反压机制的使用
//启用反压
conf.set(“spark.streaming.backpressure.enabled”,”true”)
//最小摄入条数控制
conf.set(“spark.streaming.backpressure.pid.minRate”,”1”)
//最大摄入条数控制
conf.set(“spark.streaming.kafka.maxRatePerPartition”,”12”)
注意:
- 反压机制真正起作用时需要至少处理一个批:由于反压机制需要根据当前批的速率,预估新批的速率,所以反压机制真正起作用前,应至少保证处理一个批。
如何保证反压机制真正起作用前应用不会崩溃:要保证反压机制真正起作用前应用不会崩溃,需要控制每个批次最大摄入速率。若为Direct Stream,如Kafka Direct Stream,则可以通过spark.streaming.kafka.maxRatePerPartition参数来控制。此参数代表了 每秒每个分区最大摄入的数据条数。假设BatchDuration为10秒,spark.streaming.kafka.maxRatePerPartition为12条,kafka topic 分区数为3个,则一个批(Batch)最大读取的数据条数为360条(31210=360)。同时,需要注意,该参数也代表了整个应用生命周期中的最大速率,即使是背压调整的最大值也不会超过该参数
SparkStreaming窗口处理函数时,如果我处理近一个小时的数据,但是出现上一个小时数据如何处理?
Spark每天数据量多少?每天处理多少量的数据?处理这些数据的所需要时间是多长?
- SparkStreaming数据怎么去重
- (18)sparkStreaming的最小的批的大小时间是多少?你们批大小是多少秒?你们所有批都是5s吗?还是不同指标批次时间不一样?这个5s是怎么设置出来的?
- SparkStreaming如何保证数据有序性?实时数据出错了怎么处理?
- Spark出现OOM怎么解决?
- Spark的join?怎么优化的?
- SparkUDF 和Hive UDF的区别?
- Spark在跑任务的途中,Driver直接挂掉了,Exectuor还在继续跑?怎么解决这个问题?
- Spark落盘的场景
Spark数据积压
spark streaming消费kafka,大家都知道有两种方式,也是面试考基本功常问的:
a.基于receiver的机制。这个是spark streaming最基本的方式,spark streaming的receiver会定时生成block,默认是200ms,然后每个批次生成blockrdd,分区数就是block数。架构如下:
b.direct API。这种api就是spark streaming会每个批次生成一个kafkardd,然后kafkardd的分区数,由spark streaming消费的kafkatopic分区数决定。过程如下: kafkardd与消费的kafka分区数的关系如下:
kafkardd与消费的kafka分区数的关系如下:
2.常见积压问题
kafka的producer生产数据到kafka,正常情况下,企业中应该是轮询或者随机,以保证kafka分区之间数据是均衡的。
在这个前提之下,一般情况下,假如针对你的数据量,kafka分区数设计合理。实时任务,如spark streaming或者flink,有没有长时间的停掉,那么一般不会有有积压。
消息积压的场景:
a.任务挂掉。比如,周五任务挂了,有没有写自动拉起脚本,周一早上才处理。那么spark streaming消费的数据相当于滞后两天。这个确实新手会遇到。
周末不加班,估计会被骂。
b.kafka分区数设少了。其实,kafka单分区生产消息的速度qps还是很高的,但是消费者由于业务逻辑复杂度的不同,会有不同的时间消耗,就会出现消费滞后的情况。
_c.kafka消息的key不均匀,导致分区间数据不均衡。_kafka生产消息支持指定key,用key携带写信息,但是key要均匀,否则会出现kafka的分区间数据不均衡。
上面三种积压情况,企业中很常见,那么如何处理数据积压呢?
一般解决办法,针对性的有以下几种:
a.任务挂掉导致的消费滞后。任务启动从最新的消费,历史数据采用离线修补。最重要的是故障拉起脚本要有,还要就是实时框架异常处理能力要强,避免数据不规范导致的不能拉起。
b.任务挂掉导致的消费滞后。任务启动从上次提交处消费处理,但是要增加任务的处理能力,比如增加资源,让任务能尽可能的赶上消费最新数据。
c.kafka分区少了。假设数据量大,直接增加kafka分区是根本,但是也可以对kafkardd进行repartition,增加一次shuffle。
d.个别分区不均衡。可以生产者处可以给key加随机后缀,使其均衡。也可以对kafkardd进行repartition。
3.浪尖的骚操作
其实,以上都不是大家想要的,因为spark streaming生产的kafkardd的分区数,完全可以是大于kakfa分区数的。
其实,经常阅读源码或者星球的看过浪尖的源码视频的朋友应该了解,rdd的分区数,是由rdd的getPartitions函数决定。比如kafkardd的getPartitions方法实现如下:
override def getPartitions: Array[Partition] = { offsetRanges.zipWithIndex.map { case (o, i) => new KafkaRDDPartition(i, o.topic, o.partition, o.fromOffset, o.untilOffset) }.toArray }
offsetRanges其实就是一个数组:
val offsetRanges: Array[OffsetRange],
OffsetRange存储一个kafka分区元数据及其offset范围,然后进行map操作,转化为KafkaRDDPartition。实际上,我们可以在这里下手,将map改为flatmap,然后对offsetrange的范围进行拆分,但是这个会引发一个问题,浪尖在这里就不赘述了,你可以测测。
其实,我们可以在offsetRange生成的时候做下转换。位置是DirectKafkaInputDstream的compute方法。具体实现:首先,浪尖实现中增加了三个配置,分别是:
是否开启自动重分区分区sparkConf.set("enable.auto.repartition","true")避免不必要的重分区操作,增加个阈值,只有该批次要消费的kafka的分区内数据大于该阈值才进行拆分sparkConf.set("per.partition.offsetrange.threshold","300")拆分后,每个kafkardd 的分区数据量。sparkConf.set("per.partition.after.partition.size","100")
然后,在DirectKafkaInputDstream里获取着三个配置,方法如下:
val repartitionStep = _ssc.conf.getInt("per.partition.offsetrange.size",1000)val repartitionThreshold = _ssc.conf.getLong("per.partition.offsetrange.threshold",1000)val enableRepartition = _ssc.conf.getBoolean("enable.auto.repartition",false)
对offsetRanges生成的过程进行改造,只需要增加7行源码即可。
val offsetRanges = untilOffsets.flatMap{ case (tp, uo) => val fo = currentOffsets(tp) val delta = uo -fo if(enableRepartition&&(repartitionThreshold < delta)){ val offsets = fo to uo by repartitionStep offsets.map(each =>{ val tmpOffset = each + repartitionStep OffsetRange(tp.topic, tp.partition, each, Math.min(tmpOffset,uo)) }).toList }else{ Array(OffsetRange(tp.topic, tp.partition, fo, uo)) }}
Spark的join机制
Join背景
当前SparkSQL支持三种join算法:Shuffle Hash Join、Broadcast Hash Join以及Sort Merge Join。其中前两者归根到底都属于Hash Join,只不过载Hash Join之前需要先Shuffle还是先Broadcast。其实,Hash Join算法来自于传统数据库,而Shuffle和Broadcast是大数据在分布式情况下的概念,两者结合的产物。因此可以说,大数据的根就是传统数据库。Hash Join是内核。
Spark Join的分类和实现机制

Hash Join
先来看看这样一条SQL语句:select * from order,item where item.id = order.i_id,参与join的两张表是order和item,join key分别是item.id以及order.i_id。现在假设Join采用的是hash join算法,整个过程会经历三步:
- 确定Build Table以及Probe Table:这个概念比较重要,Build Table会被构建成以join key为key的hash table,而Probe Table使用join key在这张hash table表中寻找符合条件的行,然后进行join链接。Build表和Probe表是Spark决定的。通常情况下,小表会被作为Build Table,较大的表会被作为Probe Table。
- 构建Hash Table:依次读取Build Table(item)的数据,对于每一条数据根据Join Key(item.id)进行hash,hash到对应的bucket中(类似于HashMap的原理),最后会生成一张HashTable,HashTable会缓存在内存中,如果内存放不下会dump到磁盘中。
- 匹配:生成Hash Table后,在依次扫描Probe Table(order)的数据,使用相同的hash函数(在spark中,实际上就是要使用相同的partitioner)在Hash Table中寻找hash(join key)相同的值,如果匹配成功就将两者join在一起。
Broadcast Hash Join
当Join的一张表很小的时候,使用broadcast hash join。Broadcast Hash Join的条件有以下几个:
- 被广播的表需要小于spark.sql.autoBroadcastJoinThreshold所配置的信息,默认是10M;
- 基表不能被广播,比如left outer join时,只能广播右表。

broadcast hash join可以分为两步:
- broadcast阶段:将小表广播到所有的executor上,广播的算法有很多,最简单的是先发给driver,driver再统一分发给所有的executor,要不就是基于bittorrete的p2p思路;
hash join阶段:在每个executor上执行 hash join,小表构建为hash table,大表的分区数据匹配hash table中的数据。
Sort Merge Join
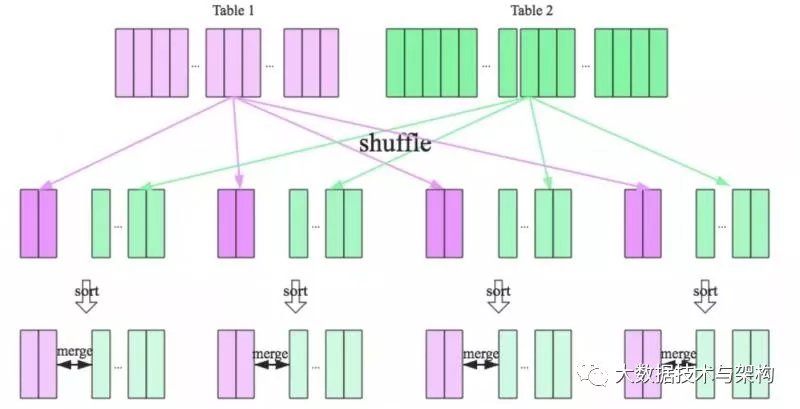
当两个表都非常大时,SparkSQL采用了一种全新的方案来对表进行Join,即Sort Merge Join。这种方式不用将一侧数据全部加载后再进行hash join,但需要在join前将数据进行排序。首先将两张表按照join key进行重新shuffle,保证join key值相同的记录会被分在相应的分区,分区后对每个分区内的数据进行排序,排序后再对相应的分区内的记录进行连接。可以看出,无论分区有多大,Sort Merge Join都不用把一侧的数据全部加载到内存中,而是即用即丢;因为两个序列都有有序的,从头遍历,碰到key相同的就输出,如果不同,左边小就继续取左边,反之取右边。从而大大提高了大数据量下sql join的稳定性。整个过程分为三个步骤:shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理
- sort阶段:对单个分区节点的两表数据,分别进行排序
- merge阶段:对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则继续取更小一边的key。
经过上文的分析,很明显可以得出这几种join的代价关系:cost(Broadcast Hash Join)< cost(Shuffle Hash Join) < cost(Sort Merge Join),数据仓库设计时最好避免大表与大表的join查询,SparkSQL也可以根据内存资源、带宽资源适量将参数spark.sql. autoBroadcastJoinThreshold调大,让更多join实际执行为Broadcast Hash Join。
我们都知道,Spark SQL上主要有三种实现join的策略,分别是Broadcast hash join、Shuffle hash join、Sort merge join。那Catalyst是依据什么样的规则来选择join策略的?本文来简单补个漏。
Catalyst在由优化的逻辑计划生成物理计划的过程中,会根据org.apache.spark.sql.execution.SparkStrategies类中JoinSelection对象提供的规则按顺序确定join的执行方式。不过在此之前,需要先来看看三个基本的判断条件。
join判断条件
build table侧的选择
Hash join过程的第一步就是根据两表之中较小的那一个构建哈希表,这个小表就叫做build table。相应地,大表叫做probe table,因为需要拿小表形成的哈希表来“探测”它。对应代码如下。
private def canBuildRight(joinType: JoinType): Boolean = joinType match {case _: InnerLike | LeftOuter | LeftSemi | LeftAnti | _: ExistenceJoin => truecase _ => false}private def canBuildLeft(joinType: JoinType): Boolean = joinType match {case _: InnerLike | RightOuter => truecase _ => false}
可见,只有当join类型为inner-like(包含inner join与cross join两种)或right outer join时,左表才有可能作为build table。而在join类型为inner-like或者left outer/semi/anti join时,右表有可能作为build table。顺便复习一下各种join类型的语义,用Venn图表示如下。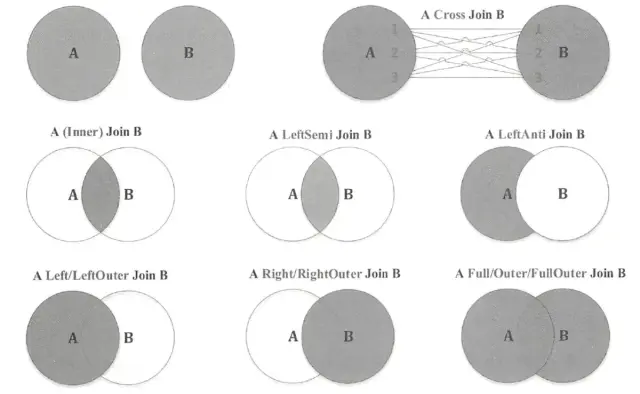
表如何被广播
如果有某个表的大小小于spark.sql.autoBroadcastJoinThreshold参数规定的值(默认值是10MB,可修改),那么它会被自动广播出去。对应代码如下。
private def canBroadcast(plan: LogicalPlan): Boolean = {plan.stats.sizeInBytes >= 0 && plan.stats.sizeInBytes <= conf.autoBroadcastJoinThreshold}private def canBroadcastBySizes(joinType: JoinType, left: LogicalPlan, right: LogicalPlan): Boolean = {val buildLeft = canBuildLeft(joinType) && canBroadcast(left)val buildRight = canBuildRight(joinType) && canBroadcast(right)buildLeft || buildRight}
除了上述阈值之外,Spark SQL还允许在语句里使用broadcast hint(即/* +BROADCAST(t) */)来手动指定要广播的表,判断逻辑如下所示。
private def canBroadcastByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan): Boolean = {val buildLeft = canBuildLeft(joinType) && left.stats.hints.broadcastval buildRight = canBuildRight(joinType) && right.stats.hints.broadcastbuildLeft || buildRight}
根据阈值和根据hint广播表的方法如下,逻辑比较简单。
private def broadcastSideBySizes(joinType: JoinType, left: LogicalPlan, right: LogicalPlan): BuildSide = {val buildLeft = canBuildLeft(joinType) && canBroadcast(left)val buildRight = canBuildRight(joinType) && canBroadcast(right)broadcastSide(buildLeft, buildRight, left, right)}private def broadcastSideByHints(joinType: JoinType, left: LogicalPlan, right: LogicalPlan): BuildSide = {val buildLeft = canBuildLeft(joinType) && left.stats.hints.broadcastval buildRight = canBuildRight(joinType) && right.stats.hints.broadcastbroadcastSide(buildLeft, buildRight, left, right)}
这两个方法最终都调用了broadcastSide()方法确定应该广播哪个表。
private def broadcastSide(canBuildLeft: Boolean,canBuildRight: Boolean,left: LogicalPlan,right: LogicalPlan): BuildSide = {def smallerSide =if (right.stats.sizeInBytes <= left.stats.sizeInBytes) BuildRight else BuildLeftif (canBuildRight && canBuildLeft) {// Broadcast smaller side base on its estimated physical size// if both sides have broadcast hintsmallerSide} else if (canBuildRight) {BuildRight} else if (canBuildLeft) {BuildLeft} else {// for the last default broadcast nested loop joinsmallerSide}}
该方法先根据表的统计信息找出左表和右表中size较小的那个,如果左表和右表都能或者都不能作为build table,就将较小的表广播。否则,先判断右表是否可作为build table,可行的话优先广播右表,再判断左表。可见,broadcast hint只能表示用户广播表的偏好,实际执行时未必会按照broadcast hint指定的表来。
是否可构造本地HashMap
Shuffle hash join过程中,如果数据量不大,就可以用本地哈希表保存Shuffle中间结果,提高效率。当逻辑计划的数据量小于广播阈值与Shuffle分区数的乘积,即小于spark.sql.autoBroadcastJoinThreshold * spark.sql.shuffle.partitions时,说明单个分区的数据量足够小,可以安全地构造本地HashMap。
private def canBuildLocalHashMap(plan: LogicalPlan): Boolean = {plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions}
join策略选择
这部分源码都位于JoinSelection对象的apply()方法中。重要的话再说一次,策略的选择会按照效率从高到低的优先级来排。
Broadcast hash join
// broadcast hints were specifiedcase ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if canBroadcastByHints(joinType, left, right) =>val buildSide = broadcastSideByHints(joinType, left, right)Seq(joins.BroadcastHashJoinExec(leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))// broadcast hints were not specified, so need to infer it from size and configuration.case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if canBroadcastBySizes(joinType, left, right) =>val buildSide = broadcastSideBySizes(joinType, left, right)Seq(joins.BroadcastHashJoinExec(leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))
可见是先根据broadcast hint来判断,其次是广播阈值。判断的条件在上一节已经说完了哈。
Shuffle hash join
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if !conf.preferSortMergeJoin && canBuildRight(joinType) && canBuildLocalHashMap(right)&& muchSmaller(right, left) ||!RowOrdering.isOrderable(leftKeys) =>Seq(joins.ShuffledHashJoinExec(leftKeys, rightKeys, joinType, BuildRight, condition, planLater(left), planLater(right)))case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if !conf.preferSortMergeJoin && canBuildLeft(joinType) && canBuildLocalHashMap(left)&& muchSmaller(left, right) ||!RowOrdering.isOrderable(leftKeys) =>Seq(joins.ShuffledHashJoinExec(leftKeys, rightKeys, joinType, BuildLeft, condition, planLater(left), planLater(right)))
选择Shuffle hash join策略的条件比较严苛,大前提是不优先采用Sort merge join,即spark.sql.join.preferSortMergeJoin配置项为false。与Broadcast hash join相同的,Shuffle hash join也是先检查右表,后检查左表。以右表为例,还需要满足以下3个条件:
- 右表能够作为build table;
- 能够从右表构建本地HashMap;
- 右表的数据量比左表小很多(即muchSmaller()方法),“很多”在代码中规定为3倍。
除去上述情况外,如果参与join的表的key无法被排序(即根本无法使用Sort merge join),那么也会fallback到Shuffle hash join策略。
Sort merge join
case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if RowOrdering.isOrderable(leftKeys) =>joins.SortMergeJoinExec(leftKeys, rightKeys, joinType, condition, planLater(left), planLater(right)) :: Nil
如果上面两种策略都不符合,并且参与join的key是可以排序的话,就会采取Sort merge join。这个要求不高,所以Spark SQL中非小表的join都会采用此策略。
Non equi-join
// Pick BroadcastNestedLoopJoin if one side could be broadcastcase j @ logical.Join(left, right, joinType, condition)if canBroadcastByHints(joinType, left, right) =>val buildSide = broadcastSideByHints(joinType, left, right)joins.BroadcastNestedLoopJoinExec(planLater(left), planLater(right), buildSide, joinType, condition) :: Nilcase j @ logical.Join(left, right, joinType, condition)if canBroadcastBySizes(joinType, left, right) =>val buildSide = broadcastSideBySizes(joinType, left, right)joins.BroadcastNestedLoopJoinExec(planLater(left), planLater(right), buildSide, joinType, condition) :: Nil// Pick CartesianProduct for InnerJoincase logical.Join(left, right, _: InnerLike, condition) =>joins.CartesianProductExec(planLater(left), planLater(right), condition) :: Nilcase logical.Join(left, right, joinType, condition) =>val buildSide = broadcastSide(left.stats.hints.broadcast, right.stats.hints.broadcast, left, right)// This join could be very slow or OOMjoins.BroadcastNestedLoopJoinExec(planLater(left), planLater(right), buildSide, joinType, condition) :: Nil
上面的三种经典情况都是equi-join,即等值连接。如果是非等值连接,它们就无能为力了。这时会先检查表是否可以被广播,如果可以,会使用Broadcast nested loop join策略。顾名思义,它的本质是Nested loop join(即之前讲过的二重循环扫描+比对),不过加上了广播build table而已。
如果表不能被广播,又分为两种情况:若join类型是inner join或者cross join的话,会直接将两表做笛卡尔积。若上述情况全部不满足,最后的方案是选择两个表中数据量较小的那个广播,即回到Broadcast nested loop join策略。可以预见,这两种情况的效率都是非常低的,要尽量避免。

若有收获,就点个赞吧
0 人点赞
