HashMap
1.new HashMap()
new一个HashMap,发生了什么
HashMap有几个构造函数,主要就是指定初始容量和负载因子的大小.
如果没有指定初始容量,则默认HashMap的大小为16,负载因子的大小为0.75.
如果指定了初始容量,则调用tableSizeFor()对其计算得到比这个值大的2次幂.
HashMap的容量只能是2次幂
- 在执行插入操作时,HashMap会根据key的来计算出哈希码,然后将哈希码的高16异或低16位做扰动计算,然后通过跟数组长度求余数计算出索引.
- 当保证容量为2次幂的时候,就可以用位运算替代取模,效率更高,
2次幂有助于减少哈希冲突的几率.如果长度为2的幂次方,则
length-1的二进制必定时1111..的形式,这样在与操作的时候可以利用到所有的低位,如果最低一位是0,那么与操作的最后一位也必定是0,那么所有最低位是1的的位置就永远是空的,这浪费了空间,也提高了哈希冲突的概率默认加载因子为什么是0.75
作者在源码中有注释,在一般情况下,默认负载因子(0.75),在时间和空间成本上提供了很好的折衷.
- 较高的负载因子会减低空间开销,但提高了查找成本.较低的负载因子则相反.
- 如果对时间和空间成本有特殊的需求,可以更改这个值,比如内存空间很多的同时对时间效率要求比较高,则可以降低负载因子的值.
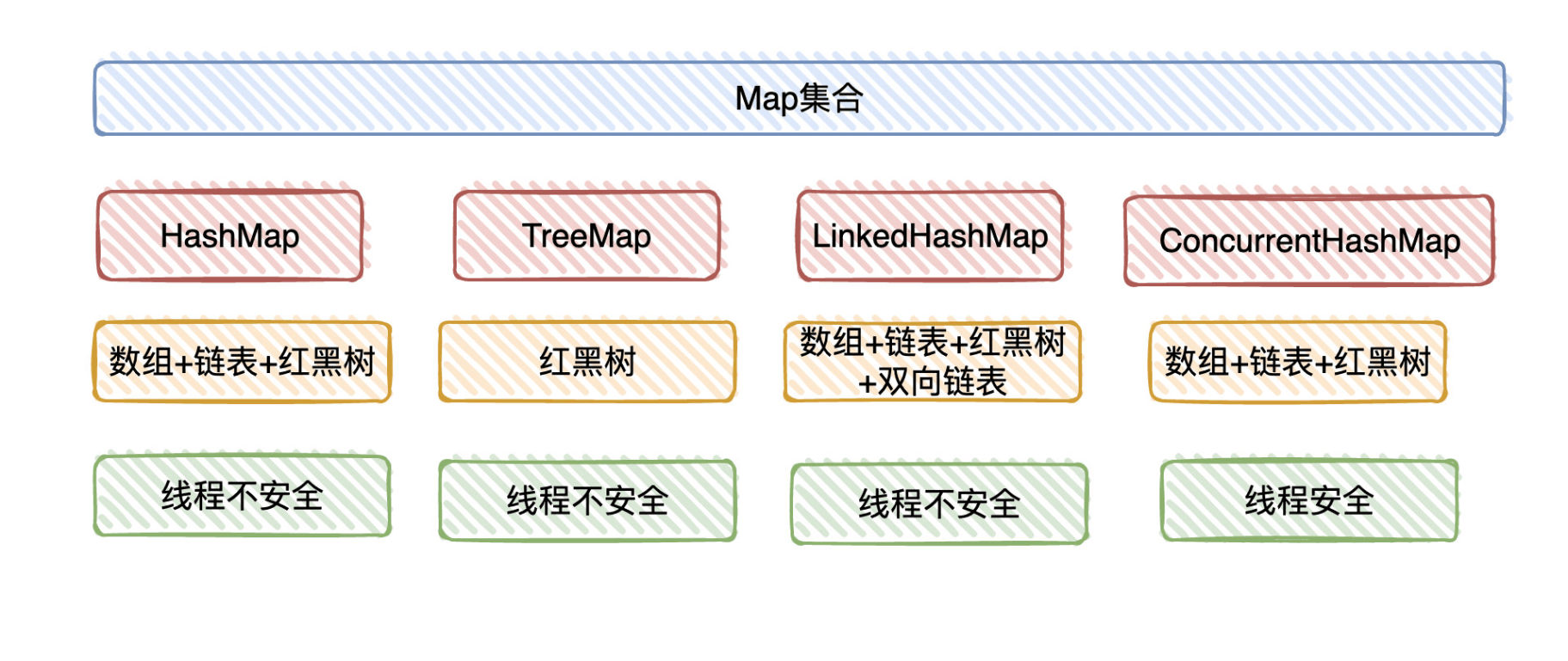
2.数据结构
HashMap是如何解决hash碰撞问题
- 首先通过对hashCode进行扰动计算,尽量减少不同hashCode的高位不同,但低位相同的hash冲突
在JDK1.8中,当数组大于64且链表中的元素达到了 8 个时,会将链表转换为红黑树,红黑树虽然没有减少hash碰撞的问题,但是在这些位置进行查找的时候可以降低时间复杂度为 O(logN),也就是说减少了hash碰撞带来的性能降低的问题
HashMap什么情况下会用到红黑树
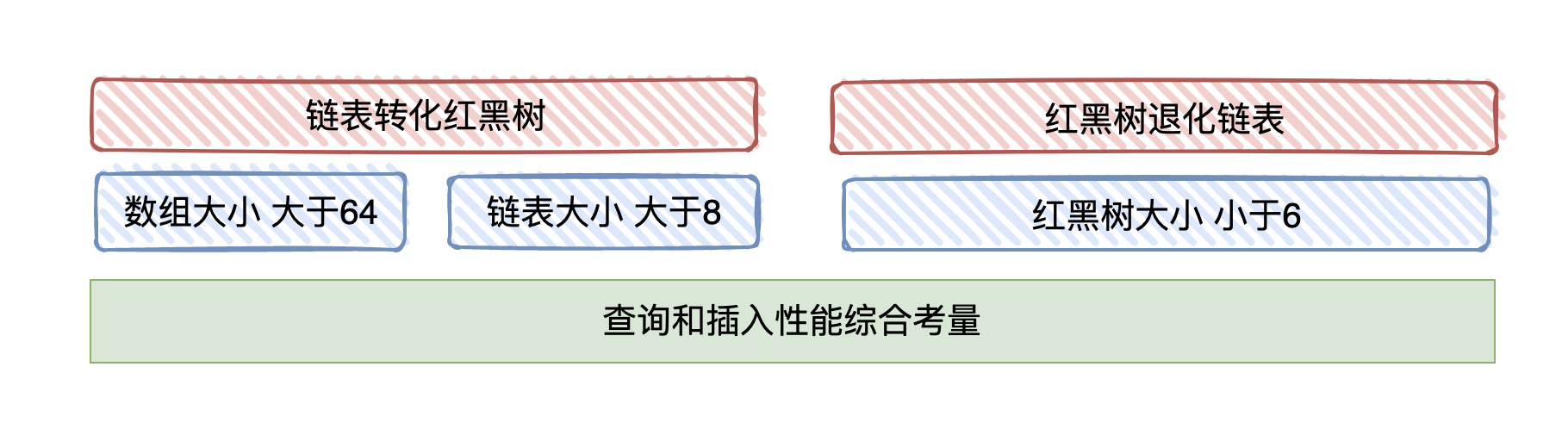
当数组大于64,链表大于8的时候,会将链表转化为红黑树,红黑树小于6的时候则会退化为链表.
- 链表跟红黑树的转化主要出于查询&插入时对性能的考虑.
- 链表查询时间复杂度O(N),插入时间复杂度O(1),红黑树查询和插入时间复杂度O(logN),
当链表过长时链表查询的线性时间复杂度会影响HashMap的性能
HashMap为什么不直接用红黑树
红黑树需要进行左旋&右旋,变色来保持平衡,而单链表不需要
- 当元素小于8的时候,链表的查询操作可以保证查询性能
- 当元素大于8的时候,红黑树遍历的时间复杂度时O(logn),而链表时O(n),此时需要红黑树来加快查询速度
但是红黑树的插入操作效率变慢了,如果直接用红黑树,在元素较少时,就会影响到插入效率
HashMap中链表改为红黑树的阈值为什么是8
作者在源码中有写,在理想情况下使用随机的哈希码,容器中节点分布在hash桶中的频率遵循泊松分布
- 按照泊松分布计算公式可以知道,链表中元素个数为8时的概率已经非常小
- 所以阈值为8时根据概率统计而得到的.
3.HashMap的方法
HashMap中put(),get()的实现
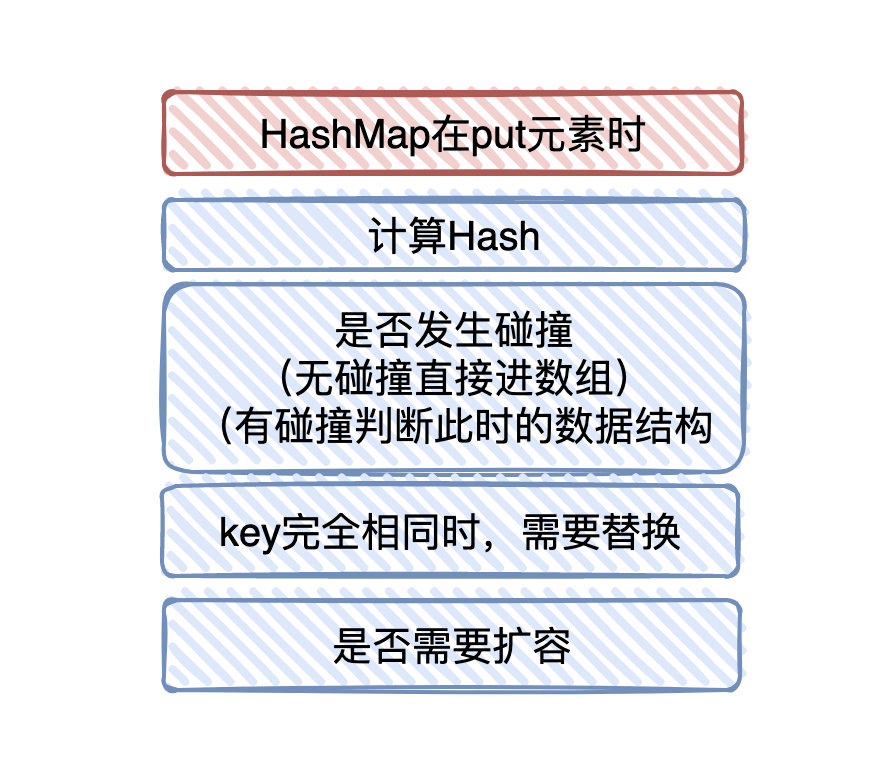
- 首先对key做hash运算,计算出该key所在的下标.
- 如果数组是空的,则调用resize进行初始化.
- 如果没哈希冲突,直接放到数组中,
- 如果冲突了,且 key 已经存在,就覆盖掉 value;
- 如果冲突后,发现该节点是红黑树,就将这个节点挂在树上;
- 如果冲突后是链表,判断该链表是否大于 8 ,如果大于 8 并且数组容量小于 64,就进行扩容;如果链表节点大于 8 并且数组的容量大于 64,则将这个结构转换为红黑树;否则,链表插入键值对,若 key 存在,就覆盖掉 value。
- get()的时候,首先对key做hash运算,计算出key所在的index,然后判断是否有hash碰撞
- 如果没有碰撞则直接返回.
- 如果碰撞了,就判断当前是不是红黑树,如果是则用红黑树的方法取数据
如果不是,则遍历链表,直到找到相等(==或equals)的key
HashMap中怎么判断一个元素是否相同
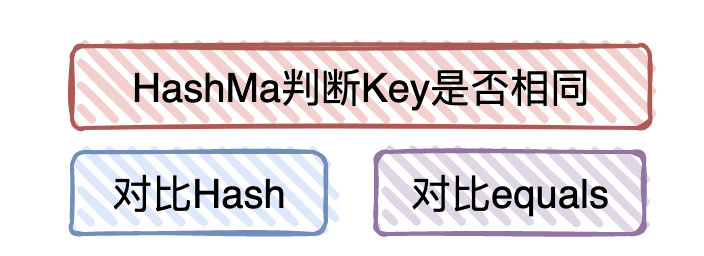
首先会比较hash值,然后会用==运算符和equals()来判断元素是否相同
HashMap是如何进行扩容的?
HashMap调用
resize()方法扩容,其中会将数组大小和阈值都扩大一倍- 然后用新的数组大小初始化新的数组
- 然后遍历原数组,进行数据迁移
- 如果是该数组位置上只有单个元素,则通过
e.hash & (newCap - 1)确定index,简单迁移即可 - 如果是红黑树//TODO
((TreeNode<K,V>)e).split(this, newTab, j, oldCap); - 如果是链表
- 就将此链表拆成两个链表,放到新的数组中,并且保留原来的先后顺序
- rehash过程通过
e.hash & oldCap == 0来确定索引 - 如果判断为true,就是原来的索引.
- 如果判断为false,就是
index + oldCap4.其他89 99 88888o
其他hash算法
Hash函数是指把一个大范围映射到一个小范围,目的往往是为了节省空间,使得数据容易保存。 比较出名的有MurmurHash、MD4、MD5等等.key 可以为 Null 吗?
可以,key 为 Null 的时候,hash算法最后的值以0来计算,也就是放在数组的第一个位置.一般用什么作为HashMap的key?
一般用Integer、String这种不可变类当 HashMap 当 key,而且 String 最为常用.
- 因为字符串是不可变的,所以在它创建的时候 hashcode 就被缓存了,不需要重新计算.这就是 HashMap 中的键往往都使用字符串的原因.
- 因为获取对象的时候要用到 equals() 和 hashCode() 方法,那么键对象正确的重写这两个方法是非常重要的,这些类已经很规范的重写了 hashCode() 以及 equals() 方法.
用可变类当 HashMap 的 key 有什么问题?
hashcode 可能发生改变,导致 put 进去的值,无法 get 出.ConcurrentHashMap
线程安全的Map
- HashMap不是线程安全的,在多线程环境下,HashMap有可能会有数据丢失和获取不了最新数据的问题.
- ConcurrentHashMap是线程安全的Map实现类,它在juc包下的
- 线程安全的Map实现类除了ConcurrentHashMap还有Hashtable
- 也可以使用Collections来包装出一个线程安全的Map
但无论是Hashtable还是Collections包装出来的都比较低效(因为是直接在外层套synchronize),所以一般使用ConcurrentHashMap
concurrentHashMap
ConcurrentHashMap的底层数据结构是数组+链表/红黑树,它能支持高并发的访问和更新,是线程安全的.
- ConcurrentHashMap通过在部分加锁和利用CAS算法来实现同步,在get的时候没有加锁,Node都用了volatile给修饰.
在扩容时,会给每个线程分配对应的区间,并且为了防止putVal导致数据不一致,会给线程的所负责的区间加锁
LinkedHashMap
LinkedHashMap
LinkedHashMap底层结构是数组+链表+双向链表
LinkedHashMap在HashMap的基础上,采用双向链表的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同.
TreeMap
TreeMap
TreeMap的底层数据结构是红黑树
- TreeMap的key不能为null,TreeMap有序是通过Comparator来进行比较的,如果comparator为null,那么就使用自然顺序

若有收获,就点个赞吧
0 人点赞
