- Spring cloud 基本架构图
- Spring Cloud 组件原理
- Spring Cloud 和 Dubbo 的区别
- 你们的服务注册中心进行过选型调研吗?对比一下各种服务注册中心!
- 注册中心比较
- 画图阐述一下你们的服务注册中心部署架构,生产环境下怎么保证高可用?
- 你们系统遇到过服务发现过慢的问题吗?怎么优化和解决的?
- 说一下自己公司的服务注册中心怎么技术选型的?生产环境中应该怎么优化?
- 你们对网关的技术选型是怎么考虑的?能对比一下各种网关技术的优劣吗?
- 如果网关需要抗每秒10万的高并发访问,你应该怎么对网关进行生产优化?
- 如果需要部署上万服务实例,现有的服务注册中心能否抗住?如何优化?
- 说说生产环境下,你们是怎么实现网关对服务的动态路由的?
- 你们是如何基于网关实现灰度发布的?说说你们的灰度发布方案?
- 说说你们一个服务从开发到上线,服务注册、网关路由、服务调用的流程?
Spring cloud 基本架构图
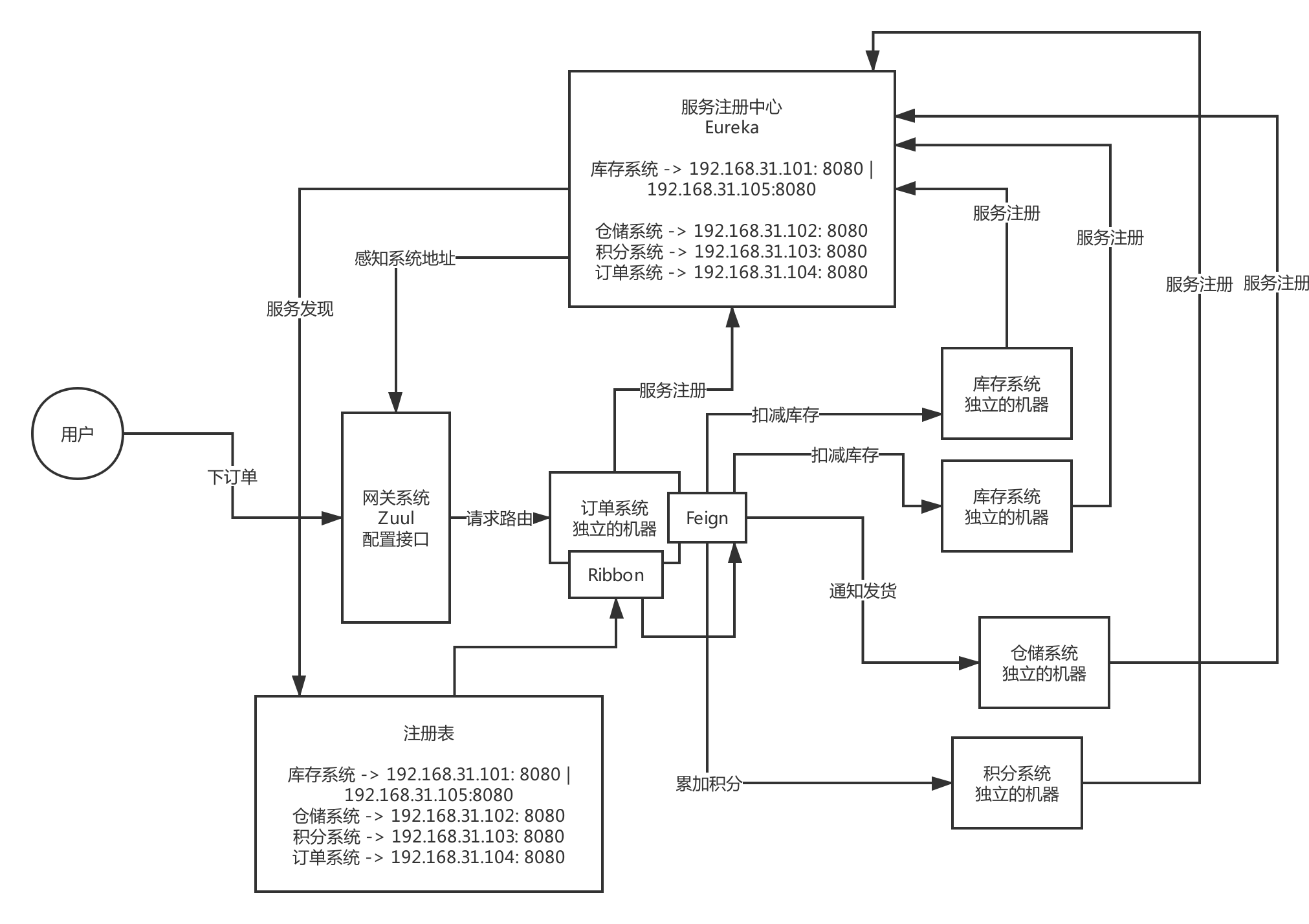
Eureka:服务注册中心
Feign:服务调用
Ribbon:负载均衡
Zuul/Spring Cloud Gatway:网关
这么多的系统,电商系统包含了20个子系统,每个子系统有20个核心接口,一共电商系统有400个接口,这么多的接口,直接对外暴露,前后端分离的架构,难道你让前端的同学必须记住你的20个系统的部署的机器,他们去做负载均衡,记住400个接口
微服务那块,网关
灰度发布、统一熔断、统一降级、统一缓存、统一限流、统一授权认证
Hystrix、链路追踪、stream、很多组件,Hystrix这块东西,其实是会放在高可用的环节去说的,并不是说一个普通系统刚开始就必须得用的,没有用好的话,反而会出问题,Hystrix线路熔断的框架,必须得设计对应的一整套的限流方案、熔断方案、资源隔离、降级机制,配合降级机制来做
Spring Cloud 组件原理
eureka 原理图
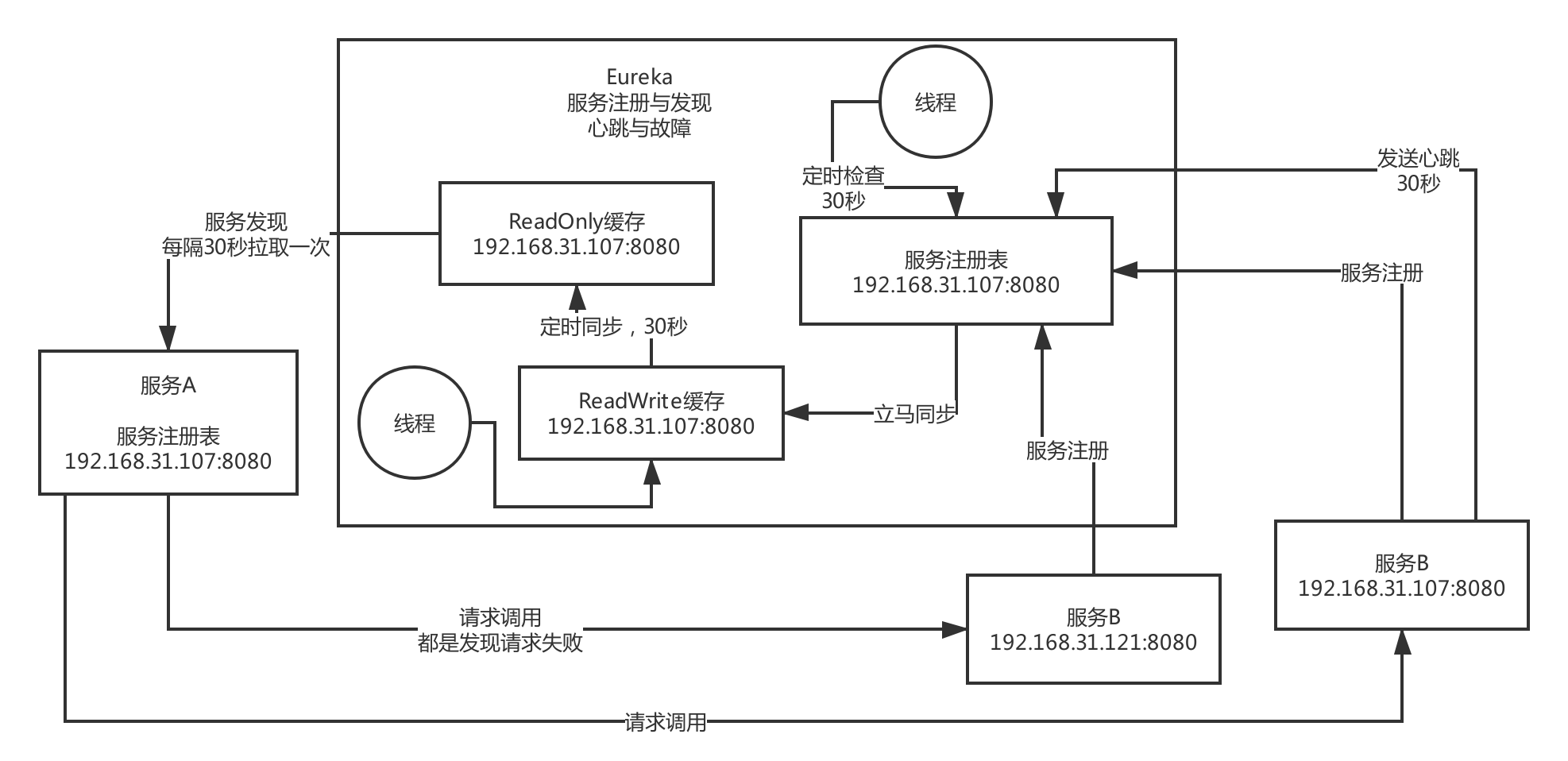
Eureka 缓存的设计目的
优化并发 并发冲突,如果操作服务注册表,读时加锁防止写,写时加锁不能读,效率降低。
Feign 原理
在配置类上,加上@EnableFeginClients,那么该注解是基于@Import注解,注册有关Fegin的解析注册类,这个类是实现 ImportBeanDefinitionRegistrar 这个接口,重写registryBeanDefinition 方法。他会扫描所有加了@FeginClient 的接口,然后针对这个注解的接口生成动态代理,然后你针对fegin的动态代理去调用他方法的时候,此时会在底层生成http协议格式的请求。
Ribbo 原理
底层的话,使用HTTP通信的框架组件,HttpClient,先得使用Ribbon去本地的Eureka注册表的缓存里获取出来对方机器的列表,然后进行负载均衡,选出一台机器,接着针对那台机器发送 Http请求过去即可
Zuul 原理
配置一下不同的请求路径和服务的对应关系,你的请求到了网关,他直接查找到匹配的服务,然后就直接把请求转发给服务的某台机器,Ribbon从Eureka本地的缓存列表里获取一台机器,负载均衡,把请求直接用HTTP通信扩建发送到指定机器上去。
Spring Cloud 和 Dubbo 的区别
Dubbo,RPC的性能比HTTP的性能更好,并发能力更强,经过深度优化的RPC服务框架,性能和并发能力是更好一些
很多中小型公司而言,其实稍微好一点的性能,Dubbo一次请求10ms,Spring Cloud耗费20ms,对很多中小型公司而言,性能、并发,并不是最主要的因素
Spring Cloud这套架构原理,走HTTP接口和HTTP请求,就足够满足性能和并发的需要了,没必要使用高度优化的RPC服务框架
Dubbo之前的一个定位,就是一个单纯的服务框架而已,不提供任何其他的功能,配合的网关还得选择其他的一些技术
Spring Cloud,中小型公司用的特别多,老系统从Dubbo迁移到Spring Cloud,新系统都是用Spring Cloud来进行开发,全家桶,主打的是微服务架构里,组件齐全,功能齐全。网关直接提供了,分布式配置中心,授权认证,服务调用链路追踪,Hystrix可以做服务的资源隔离、熔断降级、服务请求QPS监控、契约测试、消息中间件封装、ZK封装
胜是胜在功能齐全,中小型公司开箱即用,直接满足系统的开发需求
Spring Cloud原来支持的一些技术慢慢的未来会演变为,跟阿里技术体系进行融合,Spring Cloud Alibaba,阿里技术会融入Spring Cloud里面去
你们的服务注册中心进行过选型调研吗?对比一下各种服务注册中心!
注册中心比较
| 比较点 | Eureka | Zookeeper | Consul | Nacos |
|---|---|---|---|---|
| 一致性 | AP(最终一致性) | CP(强一致性) | CP | CP+AP |
| 时效性 | 服务注册心跳时间 注册表检查时间 readwrite 同步到 readonly时间 消费方拉取readonly注册表时间 |
快,强一致性 | 同步延迟 | CP 快 AP 慢 |
| 适用规模 | 20K~30K实例(节点) | 10K~20K实例(节点) | < 3K实例(节点) | |
| 通信方式 | Http Rest | 自定义协议 | Http Rest | HTTP/DNS |
| 集群模式 | Peer 2 Peer(服务器之间) | leader 读/写 follower 读 |
Agent 监听的方式 | |
| 性能问题 | 简单的更新机制, 设计复杂(扩容麻烦) |
扩容麻烦, 规模较大时GC频繁 |
3K节点以上, 更新列表缓慢 |
|
| 运维熟悉度 | 相对陌生 | 熟悉 | 更陌生 | |
| 一次性协议 | http定时轮询 | ZAB | RAFT |
Eureka、ZooKeeper
Dubbo作为服务框架的,一般注册中心会选择zk
Spring Cloud作为服务框架的,一般服务注册中心会选择Eureka
(1)服务注册发现的原理
集群模式 
Eureka,peer-to-peer,部署一个集群,但是集群里每个机器的地位是对等的,各个服务可以向任何一个Eureka实例服务注册和服务发现,集群里任何一个Euerka实例接收到写请求之后,会自动同步给其他所有的Eureka实例 
ZooKeeper,服务注册和发现的原理,Leader + Follower两种角色,只有Leader可以负责写也就是服务注册,他可以把数据同步给Follower,读的时候leader/follower都可以读
(2)一致性保障:CP or AP
CAP,C是一致性,A是可用性,P是分区容错性
CP,AP
ZooKeeper是有一个leader节点会接收数据, 然后同步写其他节点,一旦leader挂了,要重新选举leader,这个过程里为了保证C,就牺牲了A,不可用一段时间,但是一个leader选举好了,那么就可以继续写数据了,保证一致性
Eureka是peer模式,可能还没同步数据过去,结果自己就死了,此时还是可以继续从别的机器上拉取注册表,但是看到的就不是最新的数据了,但是保证了可用性,强一致,最终一致性
(3)服务注册发现的时效性
zk,时效性更好,注册或者是挂了,一般秒级就能感知到
eureka,默认配置非常糟糕,服务发现感知要到几十秒,甚至分钟级别,上线一个新的服务实例,到其他人可以发现他,极端情况下,可能要1分钟的时间,ribbon去获取每个服务上缓存的eureka的注册表进行负载均衡
服务故障,隔60秒才去检查心跳,发现这个服务上一次心跳是在60秒之前,隔60秒去检查心跳,超过90秒没有心跳,才会认为他死了,2分钟都过去
30秒,才会更新缓存,30秒,其他服务才会来拉取最新的注册表
三分钟都过去了,如果你的服务实例挂掉了,此时别人感知到,可能要两三分钟的时间,一两分钟的时间,很漫长
(4)容量
zk,不适合大规模的服务实例,因为服务上下线的时候,需要瞬间推送数据通知到所有的其他服务实例,所以一旦服务规模太大,到了几千个服务实例的时候,会导致网络带宽被大量占用
eureka,也很难支撑大规模的服务实例,因为每个eureka实例都要接受所有的请求,实例多了压力太大,扛不住,也很难到几千服务实例
之前dubbo技术体系都是用zk当注册中心,spring cloud技术体系都是用eureka当注册中心这两种是运用最广泛的,但是现在很多中小型公司以spring cloud居多,所以后面基于eureka说一下服务注册中心的生产优化
画图阐述一下你们的服务注册中心部署架构,生产环境下怎么保证高可用?
你们系统遇到过服务发现过慢的问题吗?怎么优化和解决的?
zk,一般来说还好,服务注册和发现,都是很快的
eureka,必须优化参数
- 服务器到注册中心心跳时间设置
- 注册中心定时检测心跳时间设置
- 心跳失效时间设置
- readWrite缓存定更新到readOnly时间设置
- 客户端定时拉取readWrite缓存时间设置
说一下自己公司的服务注册中心怎么技术选型的?生产环境中应该怎么优化?
- 可用性
- 时效性
- 数据一致性 CP AP
- 容量
你们对网关的技术选型是怎么考虑的?能对比一下各种网关技术的优劣吗?
网关的核心功能
(1)动态路由:新开发某个服务,动态把请求路径和服务的映射关系热加载到网关里去;服务增减机器,网关自动热感知
(2)灰度发布
(3)授权认证
(4)性能监控:每个API接口的耗时、成功率、QPS
(5)系统日志
(6)数据缓存
(7)限流熔断
几种技术选型
Kong、Zuul、Nginx+Lua(OpenResty)、自研网关
Kong:Nginx里面的一个基于lua写的模块,实现了网关的功能
Zuul:基于Java开发,核心网关功能都比较简单,但是比如灰度发布、限流、动态路由之类的,很多都要自己做二次开发。高并发能力不强,部署到一些机器上去,还要基于Tomcat来部署,Spring Boot用Tomcat把网关系统跑起来;Java语言开发,可以直接把控源码,可以做二次开发封装各种需要的功能
Nginx+Lua(OpenResty): 直接通过nginx来当做网关
自研网关:自己来写类似Zuul的网关,基于Servlet、Netty来做网关,实现上述所有的功能
如果网关需要抗每秒10万的高并发访问,你应该怎么对网关进行生产优化?
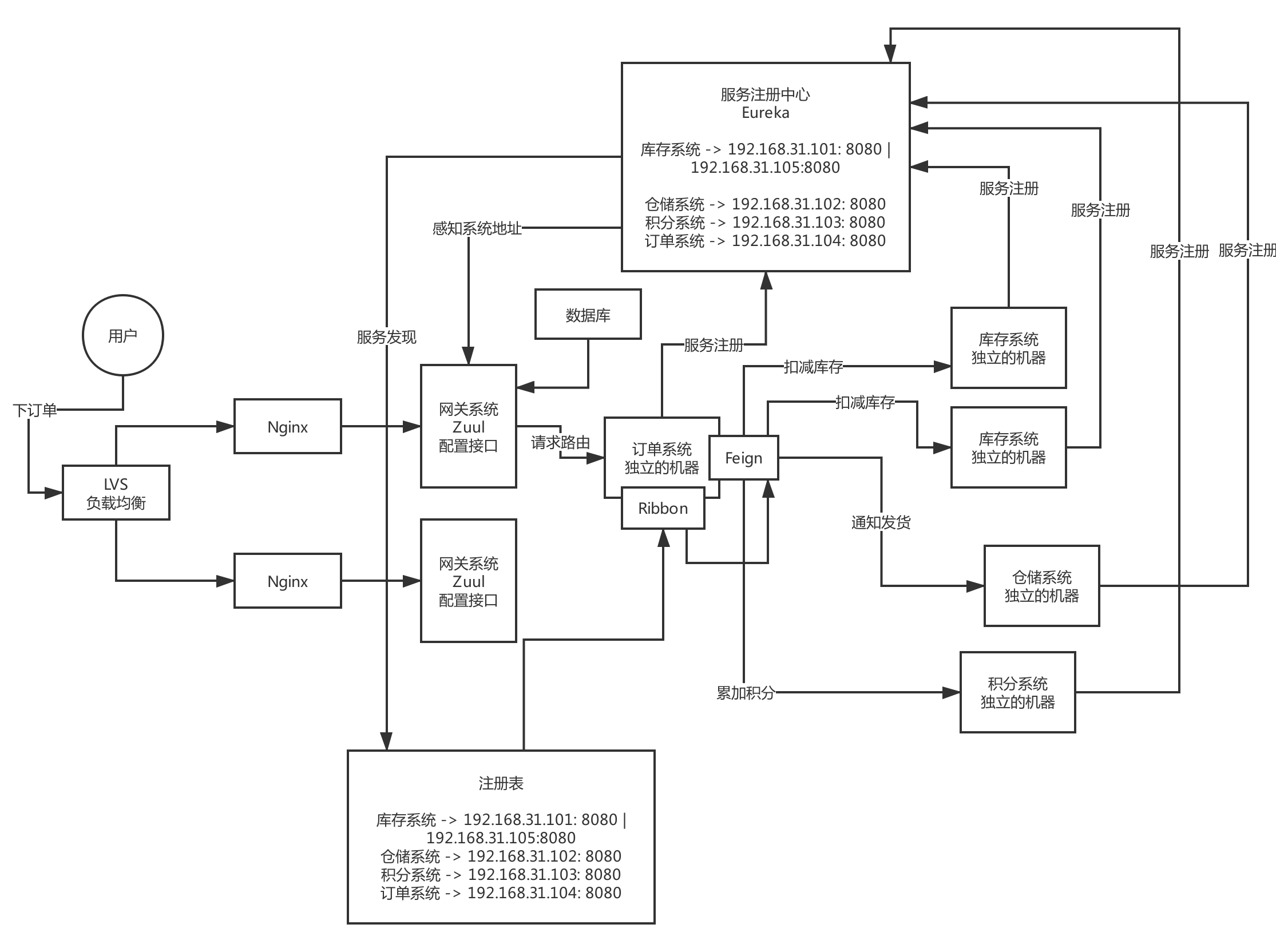
Zuul网关部署的是什么配置的机器,部署32核64G,对网关路由转发的请求,每秒抗个小几万请求是不成问题的,几台Zuul网关机器
每秒是1万请求,8核16G的机器部署Zuul网关,5台机器就够了
生产级的网关,应该具备我刚才说的几个特点和功能:
(1)动态路由:新开发某个服务,动态把请求路径和服务的映射关系热加载到网关里去;服务增减机器,网关自动热感知
(2)灰度发布:基于现成的开源插件来做
(3)授权认证
(4)限流熔断
(5)性能监控:每个API接口的耗时、成功率、QPS
(6)系统日志
(7)数据缓存
如果需要部署上万服务实例,现有的服务注册中心能否抗住?如何优化?
Eureka 和 ZK都是扛不住了,(可以主动说出注册中心的缺点)
eureka:peer-to-peer,每台机器都是高并发请求,有瓶颈
zookeeper:服务上下线,全量通知其他服务,网络带宽被打满,有瓶颈
- 可以加一个数据库层(或者是 redis缓存层),每个服务定时通过数据库(redis缓存层)来更新服务注册表,然后数据库(redis缓存层)定时拉取注册中心来更新注册表。
- 可以自研,类似于 redis 集群 加主备架构,将压力分散开。按需拉取局部的注册表。比如说服务A在,注册中心1,那么只用拉取注册中心1的注册表。而不用将注册中心1,2,3,4等等其他注册拉取过来。缓解压力。
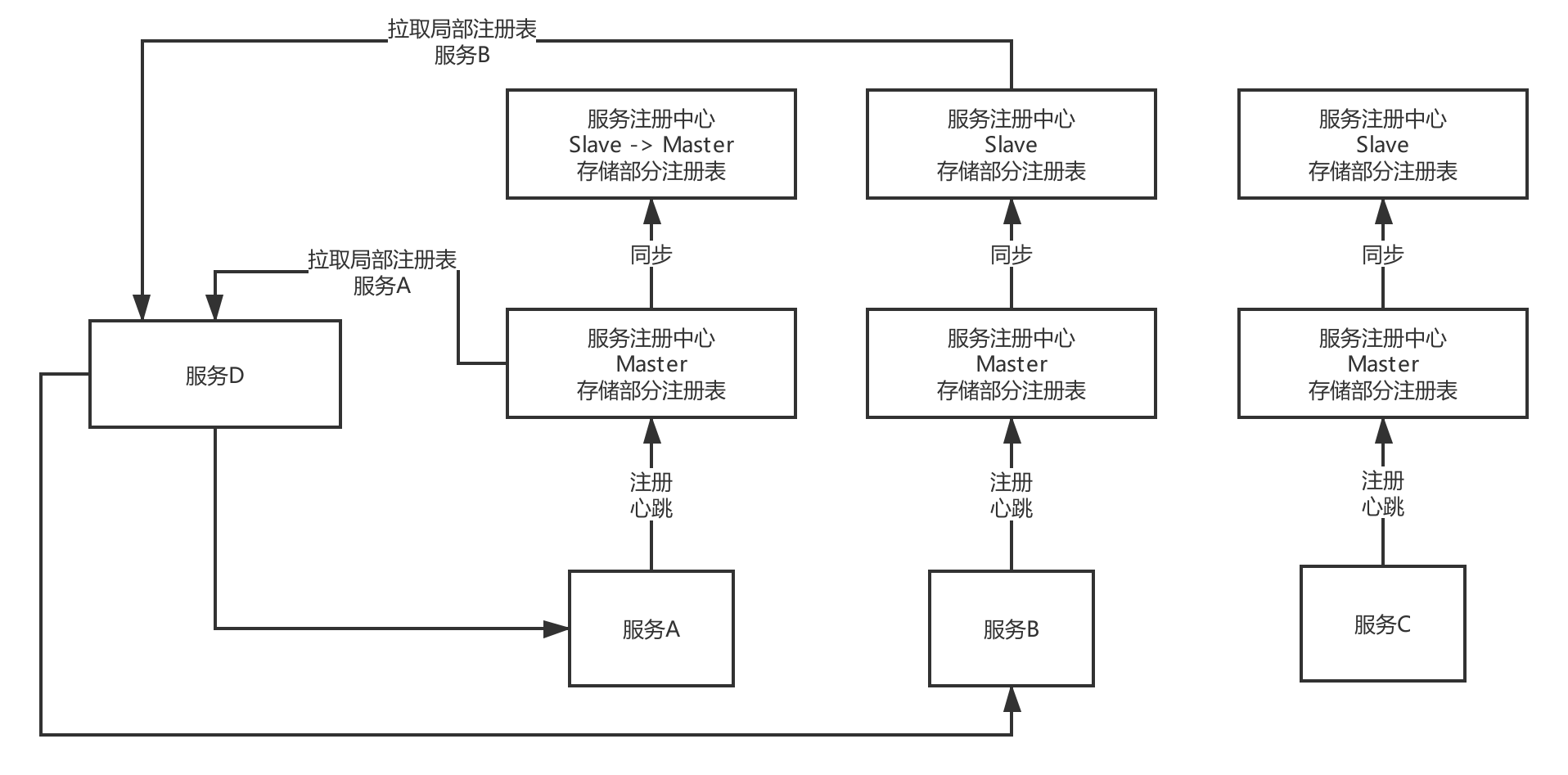
说说生产环境下,你们是怎么实现网关对服务的动态路由的?
- 通过数据库+网关定时拉取数据库 服务注册中心配置。
- 首先开发注册中心配置系统,通过页面可以动态的将增加新老服务。写入到数据库。
- 同时也可以通过拉取eureka来最新的服务注册中心配置。写入到数据库。
- 网关定时10秒拉取数据库的最新配置。
这样好处减少了eureka的压力,同时当注册中心服务宕机,也不影响当前网关的路由。
你们是如何基于网关实现灰度发布的?说说你们的灰度发布方案?
- 准备一个数据库和一个表(也可以用Apollo配置中心、Redis、ZooKeeper,其实都可以),放一个灰度发布启用表
- 写一个zuul的filter,对每个请求,zuul都会调用这个filter
- 当尝试新版本发布,修改新服务的版本为 new
- 通过页面 修改配置中心,或者修改数据库表,开灰度发布。
- 开灰度发布 网关的 filter 就会随机 百分之1的请求 带上 new 版本。这样请求就会跑到新服务
- 当新服务使用一段时间没有问题,再将old服务全部替换成 new服务 版本设置为 current,关闭灰度发布。
说说你们一个服务从开发到上线,服务注册、网关路由、服务调用的流程?
spring cloud 原理图。
注册中心 eureka
网关 zuul
服务调用 fegin
负载均衡 ribbon

若有收获,就点个赞吧
0 人点赞
