URL解析模式
一.URL 解析
- ThinkPHP 框架非常多的操作都是通过 URL 来实现的;
- http://serverName/index.php/模块/控制器/操作/参数/值…;
- index.php 为入口文件,在 public 目录内的 index.php 文件;
- 模块在 application 目录下默认有一个 index 目录,这就是一个模块;
- 而在 index 目录下有一个 controller 控制器目录的 Index.php 控制器;
- Index.php 控制器的类名也必须是 class Index,否则错误;
- 而操作就是控制器 class Index 里面的方法,比如:index 或 hello;
- 那么完整形式为:public/index.php/index/index/index
- 官方给的默认模块,默认控制器,默认操作都是 index,所以出现四个 index;
- 而操作还另给了一个带参数的方法:hello,如下: 完整形式为:public/index.php/index/index/hello/name/Lee
- php首字母必须大写
二.URL模式
如果 wamp 环境没有开启伪静态,那么 ThinkPHP 不支持 URL 重写;
没有开启 URL 重写,那只能使用 PATH_INFO 模式,如下: public/index.php?s=test/abc/eat/who/主人老李;
打开 httpd.conf 文件,加载 mod_rewrite.so,即去掉前面的#号;
此时的 URL 重写,可以省略 index.php 了,路径如下:public/test/abc/eat/who/主人老李模块设计
一.目录结构
ThinkPHP5.1 默认是多模块架构,也可以设置为单模块操作;
所有模块的命名空间以 app 这三个字母作为根命名空间(可通过环境变量更改);
手册摘入的结构列表:
模块下的类库文件命名空间统一为:app\模块名; 比如:app\index\controller\Index
多模块设计在 URL 访问时,必须指定响应的模块名,比如:public/test/abc/eat;二.空模块
- 可以通过环境变量设置空目录,将不存在的目录统一指向指定目录;
2. 在 config 目录下的 app.php 修改:
// 默认的空模块名
‘empty_module’
=> ‘index’,
空模块只有在多模块开启,且没有绑定模块的情况下生效;三.单一模块
- 如果你的应用只有一个模块,那可以直接设置单模块;
2. 在 config 目录下的 app.php 修改:
// 是否支持多模块
‘app_multi_module’
=> false,
3. 目录结构可变为,手册摘入:
4. URL 地址 public/index/one,即:控制器/操作;
5. 单一模块的命名空间也变更为:app四.环境变量
ThinkPHP5.1 提供了一个类库 Env 来获取环境变量; return Env::get(‘app_path’);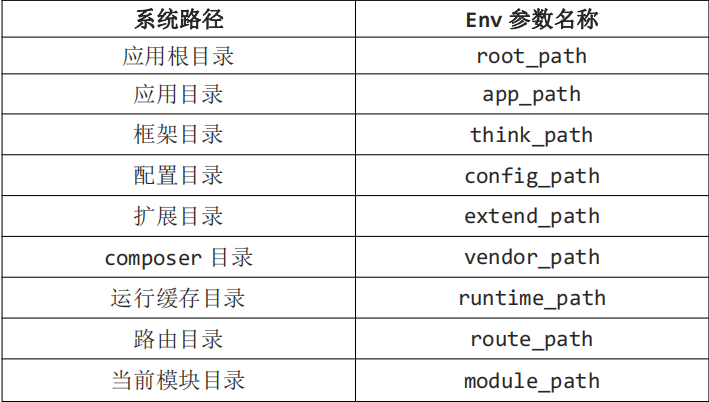
控制器定义
一.定义
控制器,即 controller,控制器文件存放在 controller 目录下;
类名和文件名大小写保持一致,并采用驼峰式(首字母大写);
use think\Controller;
class Index extends Controller
继承控制器基类,可以更方便使用功能,但不是必须的; 系统也提供了其它方式,在不继承的情况下完成相同功能;
如果创建的是双字母组合,比如 class HelloWorld; URL 访问时必须为:public/hello_world;
如果你想原样的方式访问 URL,则需要关闭配置文件中自动转换;
‘url_convert’
=> false,
此时,URL 访问可以为:public/HelloWorld;
如果你想改变根命名空间 app 为其它,可以在根目录下创建.env 文件;
然后写上配对的键值对即可,app_namespace=application;二.渲染输出
ThinkPHP 直接采用方法内 return 返回的方式直接就输出了;
使用 json 输出,直接采用 json 函数;
使用 view 输出模版,开启错误提示,可知道如何创建模版;$data = array('a'=>1, 'b'=>2, 'c'=>3);return json($data);
默认输出方式为 html 格式输出,如果返回的是数组,则会报错;return view();
可以更改配置文件里的默认输出类型,更改为 json;
一般来说,正常页面都是 html 输出,用于模版,AJAX 默认为 json;return ['user'=>'Lee','age'=>100];'default_return_type'=> 'json',
如果继承了基类控制器,那么可以定义控制器初始化方法:initialize();
initialize()方法会在调用控制器方法之前执行;
initialize()方法不需要任何返回值,输出用 PHP 方式,return 无效;protected function initialize(){//parent::initialize();echo 'init';}
控制器操作
一.前置操作
继承 Controller 类后可以设置一个$beforeActionList 属性来创建前置方法;
此时,我们可以分别 URL 访问不同的方法来理解前置的触发执行;protected $beforeActionList = ['first',//one 方法执行不调用 second 前置'second' => ['except'=>'one'],//third 前置只能通过调用 one 和 two 方法触发'third' => ['only'=>'one, two'],];protected function first(){echo'first<br/>';}
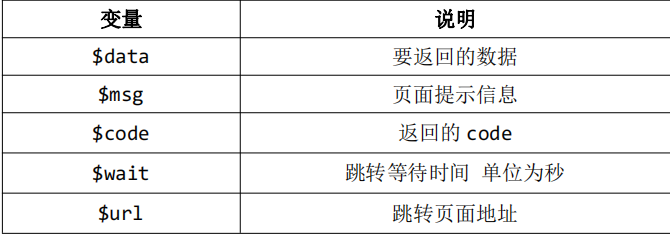
二.跳转和重定向
Controller 类提供了两个跳转的方法,success(msg,url)和 error(msg);
成功或错误有一个固定的页面模版:’thinkphp/tpl/dispatch_jump.tpl’;publicfunction index(){if($this->flag) {//如果不指定 url,则返回$_SERVER['HTTP_REFERER']$this->success('成功!', '../');} else {//自动返回前一页$this->error('失败!');}}
在 app.php 配置文件中,我们可以更改自己个性化的跳转页面;
如果需要自定义跳转页面,可以使用如下的模版变量:// 默认跳转页面对应的模板文件'dispatch_success_tmpl' => Env::get('think_path') .'tpl/dispatch_jump.tpl','dispatch_error_tmpl' => Env::get('think_path') .'tpl/dispatch_jump.tpl,
三.空方法和空控制器
当访问了一个不存在的方法时,系统会报错,我们可以使用_empty()来拦截;
当访问了一个不存在的控制器时,系统也会报错,我们可以使用 Error 类来拦截;public function _empty($name){return '不存在当前方法:'.$name;}
系统默认为 Error 类,如果需要自定义,则在 app.php 配置文件中修改;class Error{public function index(Request $request){return '当前控制器不存在:'.$request->controller();}}
// 默认的空控制器名'empty_controller'=> 'Error',
数据库与模型
一.连接数据库
ThinkPHP 采用内置抽象层将不同的数据库操作进行封装处理; 数据抽象层基于 PDO 模式,无须针对不同的数据库编写相应的代码;
使用数据库的第一步,就是连接你的数据库;
在根目录的 config 下的 database.php 可以设置数据库连接信息;
大部分系统已经给了默认值,你只需要修改和填写需要的值即可;
type 属性默认支持的数据库有:mysql、sqlite、pgsql、sqlsrv;// 数据库类型'type'=>'mysql',// 服务器地址'hostname'=>'127.0.0.1',// 数据库名'database'=>'grade',// 用户名'username'=>'root',// 密码'password'=>'123456',// 端口'hostport'=>'3306',// 编码'charset'=>'utf8',// 数据库表前缀'prefix'=>'tp_',
配置完数据库,我们使用如下代码,在控制器端输出 mysql 里的数据;public function getNoModelData(){//$data= Db::table('tp_user')->select();$data =Db::name('user')->select();return json($data);}
模型定义
在 MVC 中,我们已经使用过 Controller(C),View(V),剩下一个就是 Model(M);
Model 即模型,就是处理和配置数据库的相关信息;
在项目应用根目录创建 model 文件夹,并且创建 User.php;
当创建了 User 模型了,控制器端可以这么写:namespace app\model;use think\Model;class User extends Model{}
而此时,命名空间会自动导入 User 模型:use app\model\User;public function getModelData(){$data = User::select();return json($data);}
很多时候,我们需要调试 SQL 是否正确,建议打开 Trace,可以查看原生 SQL;// 应用 Trace'app_trace'=> true,
查询数据
一.基本查询
Db::table()中 table 必须指定完整数据表(包括前缀);
如果希望只查询一条数据,可以使用 find()方法; Db::table(‘tp_user’)->find();
Db::getLastSql()方法,可以得到最近一条 SQL 查询的原生语句; SELECT FROMtp_userLIMIT 1
想指定数据查询,可以使用 where()方法; Db::table(‘tp_user’)->where(‘id’, 27)->find() SELECT FROMtp_userWHEREid= 27 LIMIT 1
没有查询到任何值,则返回 null;
使用 findOrFail()方法同样可以查询一条数据,在没有数据时抛出一个异常; Db::table(‘tp_user’)->where(‘id’, 1)->findOrFail()
使用 findOrEmpty()方法也可以查询一条数据,但在没有数据时返回一个空数组; Db::table(‘tp_user’)->where(‘id’, 1)->findOrEmpty();
想要获取多列数据,可以使用 select()方法; Db::table(‘tp_user’)->select(); SELECT FROMtp_user
多列数据在查询不到任何数据时返回空数组,使用 selectOrFail()抛出异常; Db::table(‘tp_user’)->where(‘id’, 1)->selectOrFail();
当在数据库配置文件中设置了前缀,那么我们可以使用 name()方法忽略前缀; Db::*name(‘user’)->selectOrFail();二.更多方式
ThinkPHP 提供了一个助手函数 db,可以更方便的查询; \db(‘user’)->select();
通过 value()方法,可以查询指定字段的值(单个),没有数据返回 null; Db::name(‘user’)->where(‘id’, 27)->value(‘username’);
通过 colunm()方法,可以查询指定列的值(多个),没有数据返回空数组; Db::name(‘user’)->column(‘username’);
可以指定 id 作为列值的索引; Db::name(‘user’)->column(‘username’, ‘id’);
数据分批处理、大批数据处理和 JSON 数据查询,当遇到具体问题再探讨;链式查询
一.查询规则
通过指向符号“->”多次连续调用方法称为:链式查询;
当 Db::name(‘user’)时,返回数据库对象,即可连缀数据库对应的方法;
而每次执行一个数据库查询方法时,比如 where(),还将返回数据库对象;
只要还是数据库对象,那么就可以一直使用指向符号进行链式查询;
如果想要最后得到结果,可以使用 find()、select()等方法结束查询;
而 find()和 select()是结果查询方法(放在最后),并不是链式查询方法; Db::name(‘user’)->where(‘id’, 27)->order(‘id’, ‘desc’)->find()
除了查询方法可以使用链式连贯操作,CURD 操作也可以使用二.更多查询
如果多次使用数据库查询,那么每次静态创建都会生成一个实例,造成浪费;
我们可以把对象实例保存下来,再进行反复调用即可;
当同一个对象实例第二次查询后,会保留第一次查询的值;$user=Db::name('user');$data=$user->select();
使用 removeOption()方法,可以清理掉上一次查询保留的值;$data1=$user->order('id', 'desc')->select();$data2=$user->select();returnDb::getLastSql();SELECT * FROM `tp_user` ORDER BY `id` DESC
$user->removeOption('where')->select();
增删改操作
一.新增数据
使用 insert()方法可以向数据表添加一条数据;
如果新增成功,insert()方法会返回一个 1 值;$data = ['username'=>'辉夜','password'=>'123','gender'=>'女','email'=>'huiye@163.com','price'=>90,'details'=>'123','create_time'=>date('Y-m-d H:i:s')];Db::name('user')->insert($data);
你可以使用 data()方法来设置添加的数据数组; Db::name(‘user’)->data($data)->insert();$flag = Db::name('user')->insert($data);if ($flag) return '新增成功!';
如果你添加一个不存在的数据,会抛出一个异常 Exception;
如果采用的是 mysql 数据库,支持 REPLACE 写入; Db::name(‘user’)->insert($data, true);
使用 insertGetId()方法,可以在新增成功后返回当前数据 ID; Db::name(‘user’)->insertGetId($data);
使用 insertAll()方法,可以批量新增数据,但要保持数组结构一致;
批量新增也支持 data()方法,和单独新增类似; Db::name(‘user’)->data($data)->insertAll();$data = [['username'=>'辉夜 1','password'=>'123','gender'=>'女','email'=>'huiye@163.com','price'=>90,'details'=>123,'create_time'=>date('Y-m-d H:i:s')],['username'=>'辉夜 2','password'=>'123','gender'=>'女','email'=>'huiye@163.com','price'=>90,'details'=>123,'create_time'=>date('Y-m-d H:i:s')],];Db::name('user')->insertAll($data);
批量新增也支持 reaplce 写入,和单独新增类似; Db::name(‘user’)->insertAll($data, true);二.修改数据
使用 update()方法来修改数据,修改成功返回影响行数,没有修改返回 0;
或者使用 data()方法传入要修改的数组,如果两边都传入会合并;$data = ['username'=>'李白'];$update = Db::name('user')->where('id', 38)->update($data);return $update;
如果修改数组中包含主键,那么可以直接修改;Db::name('user')->where('id', 38)->data($data)->update(['password'=>'456']);
使用 inc()方法可以对字段增值,$data = ['username'=>'李白','id'=>38];Db::name('user')->update($data);
dec()方法可以对字段减值; Db::name(‘user’)->inc(‘price’)->dec(‘price’, 3)->update($data);
增值和减值如果同时对一个字段操作,前面一个会失效;
使用 exp()方法可以在字段中使用 mysql 函数;Db::name(‘user’)->exp(‘email’, ‘UPPER(email)’)->update($data);
使用 raw()方法修改更新,更加容易方便;
使用 setField()方法可以更新一个字段值; Db::name(‘user’)->where(‘id’, 38)->setField(‘username’, ‘辉夜’);$data = ['username'=>'李白','email'=>Db::raw('UPPER(email)'),'price'=>Db::raw('price - 3'),'id'=>38];Db::name('user')->update($data);
增值 setInc()和减值 setDec()也有简单的做法,方便更新一个字段值; Db::name(‘user’)->where(‘id’, 38)->setInc(‘price’);
增值和减值如果不指定第二个参数,则步长为 1;三.删除数据
极简删除可以根据主键直接删除,删除成功返回影响行数,否则 0; Db::name(‘user’)->delete(51);
根据主键,还可以删除多条记录; Db::name(‘user’)->delete([48,49,50]);
正常情况下,通过 where()方法来删除; Db::name(‘user’)->where(‘id’, 47)->delete();
通过 true 参数删除数据表所有数据,我还没测试,大家自行测试下; Db::name(‘user’)->delete(true);查询表达式
一.比较查询
在查询数据进行筛选时,我们采用 where()方法,比如 id=80;
Db::name(‘user’)->where(‘id’, 80)->find();
Db::name(‘user’)->where(‘id’,’=’,80)->find();
where(字段名,查询条件),where(字段名,表达式,查询条件);
其中,表达式不区分大小写,包括了比较、区间和时间三种类型的查询;
使用<>、>、<、>=、<=可以筛选出各种符合比较值的数据列表; Db::name(‘user’)->where(‘id’,’<>’,80)->select();二.区间查询
- 使用 like 表达式进行模糊查询;
Db::name(‘user’)->where(‘email’,’like’,’xiao%’)->select();
like 表达式还可以支持数组传递进行模糊查询;
Db::name(‘user’)->where(‘email’,’like’,[‘xiao%’,’wu%’], ‘or’)->select();
SELECT FROM tp_user WHERE (email LIKE ‘xiao%’ OR email LIKE ‘wu%’)
like 表达式具有两个快捷方式 whereLike()和 whereNoLike();
Db::name(‘user’)->whereLike(‘email’,’xiao%’)->select();
Db::*name(‘user’)->whereNotLike(‘email’,’xiao%’)->select();
- between 表达式具有两个快捷方式 whereBetween()和 whereNotBetween();
Db::name(‘user’)->where(‘id’,’between’,’19,25’)->select();
Db::name(‘user’)->where(‘id’,’between’,[19, 25])->select();
Db::name(‘user’)->whereBetween(‘id’,[19, 25])->select();
Db::name(‘user’)->whereNotBetween(‘id’,[19, 25])->select();
- in 表达式具有两个快捷方式 whereIn()和 whereNotIn();
Db::name(‘user’)->where(‘id’,’in’, ‘19,21,29’)->select();
Db::name(‘user’)->whereIn(‘id’,’19,21,29’)->select();
Db::name(‘user’)->whereNotIn(‘id’,’19,21,29’)->select();
- null 表达式具有两个快捷方式 whereNull()和 whereNotNull();
Db::name(‘user’)->where(‘uid’,’null’)->select();
Db::name(‘user’)->where(‘uid’,’not null’)->select();
Db::name(‘user’)->whereNull(‘uid’)->select();
Db::name(‘user’)->whereNotNull(‘uid’)->select();
三.其他查询
使用 exp 可以自定义字段后的 SQL 语句;
Db::name(‘user’)->where(‘id’,’exp’,’IN (19,21,25)’)->select();
Db::name(‘user’)->whereExp(‘id’,’IN (19,21,25)’)->select();
时间查询
一.传统方式
可以使用>、<、>=、<=来筛选匹配时间的数据;Db::name(‘user’)->where(‘create_time’, ‘> time’, ‘2018-1-1’)->select();
可以使用 between 关键字来设置时间的区间;
Db::name('user')->where('create_time','between time', ['2018-1-1','2019-12-31'])->select();Db::name('user')->where('create_time','not between time', ['2018-1-1','2019-12-31'])->select();
二.快捷方式
时间查询的快捷方法为 whereTime(),直接使用>、<、>=、<=; Db::name(‘user’)->whereTime(‘create_time’, ‘>’, ‘2018-1-1’)->select();
快捷方式也可以使用 between 和 not between; Db::name(‘user’)->whereBetween(‘create_time’, [‘2018-1-1’, ‘2019-12-31’])->select();
还有一种快捷方式为:whereBetweenTime(),如果只有一个参数就表示一天;
Db::name(‘user’)->whereBetweenTime(‘create_time’, ‘2018-1-1’, ‘2019-12-31’)->select();
默认的大于>,可以省略; Db::name(‘user’)->whereTime(‘create_time’, ‘2018-1-1’)->select()
三.固定查询
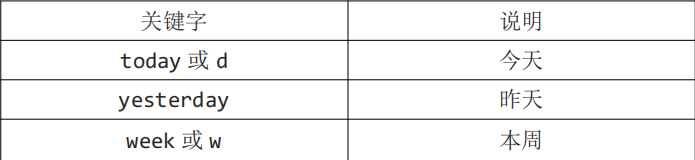
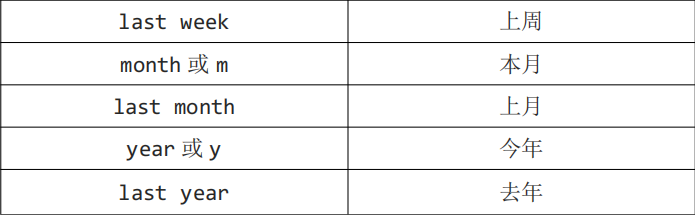
Db::name(‘user’)->whereTime(‘create_time’,’d’)->select();
Db::name(‘user’)->whereTime(‘create_time’,’y’)->select();
四.其他查询
查询指定时间的数据,比如两小时内的; Db::name(‘user’)->whereTime(‘create_time’, ‘-2 hour’)->select();
查询两个时间字段时间有效期的数据,比如会员开始到结束的期间;
Db::name(‘user’)->whereBetweenTimeField(‘start_time’, ‘end_time’)->select();
聚合、原生和子查询
一.聚合查询
使用 count()方法,可以求出所查询数据的数量; Db::name(‘user’)->count();
count()可设置指定 id,比如有空值(Null)的 uid,不会计算数量; Db::name(‘user’)->count(‘uid’);
使用 max()方法,求出所查询数据字段的最大值; Db::name(‘user’)->max(‘price’);
如果 max()方法,求出的值不是数值,则通过第二参数强制转换; Db::name(‘user’)->max(‘price’, false);
使用 min()方法,求出所查询数据字段的最小值,也可以强制转换; Db::name(‘user’)->min(‘price’);
使用 avg()方法,求出所查询数据字段的平均值; Db::name(‘user’)->avg(‘price’);
使用 sum()方法,求出所查询数据字段的总和; Db::name(‘user’)->sum(‘price’);
二.子查询
使用 fetchSql()方法,可以设置不执行 SQL,而返回 SQL 语句,默认 true; Db::name(‘user’)->fetchSql(true)->select();
使用 buidSql()方法,也是返回 SQL 语句,但不需要再执行 select(),且有括号; Db::name(‘user’)->buildSql(true);
结合以上方法,我们实现一个子查询;
$subQuery= Db::name('two')->field('uid')->where('gender','男')->buildSql(true);$result =Db::name('one')->where('id','exp','IN'.$subQuery)->select();
使用闭包的方式执行子查询;
$result = Db::name('one')->where('id','in', function ($query) {$query->name('two')->where('gender', '男')->field('uid');})->select();
三.原生查询
使用 query()方法,进行原生 SQL 查询,适用于读取操作,SQL 错误返回 false; Db::query(‘select from tp_user’);
使用 execute 方法,进行原生 SQL 更新写入等,SQL 错误返回 false; Db::*execute(‘update tp_user set username=”孙悟空” where id=29’)
链式方法
一.where
表达式查询,就是 where()方法的基础查询方式; Db::name(‘user’)->where(‘id’, ‘>’, 70)->select();
关联数组查询,通过键值对来数组键值对匹配的查询方式;
$result = Db::name('user')->where(['gender'=>'男','price'=>100//'price'=> [60,70,80]])->select();
索引数组查询,通过数组里的数组拼装方式来查询;
$result = Db::name('user')->where([['gender', '=', '男'],['price', '=', '100']])->select();
将复杂的数组组装后,通过变量传递,将增加可读性;
$map[]=['gender', '=','男'];$map[]=['price', 'in',[60, 70, 80]];$result = Db::name('user')->where($map)->select();
字符串形式传递,简单粗暴的查询方式; Db::name(‘user’)->where(‘gender=”男” AND price IN (60, 70, 80)’)->select();
二.field
使用 field()方法,可以指定要查询的字段;
Db::name(‘user’)->field(‘id, username, email’)->select();
Db::name(‘user’)->field([‘id’, ‘username’, ‘email’])->select();
使用 field()方法,给指定的字段设置别名;
Db::name(‘user’)->field(‘id,username as name’)->select();
Db::name(‘user’)->field([‘id’, ‘username’=>’name’,])->select();
在 field()方法里,可以直接给字段设置 MySQL 函数;
Db::name(‘user’)->field(‘id,SUM(price)’)->select();
对于更加复杂的 MySQL 函数,必须使用字段数组形式;
Db::name(‘user’)->field([‘id’, ‘LEFT(email, 5)’=>’leftemail’ ,])->select();
使用 field(true)的布尔参数,可以显式的查询获取所有字段,而不是; Db::name(‘user’)->field(true)->select();
使用 field()方法中字段排除,可以屏蔽掉想要不显示的字段;
Db::name(‘user’)->field(‘details,email’, true)->select();
Db::name(‘user’)->field([‘details,email’], true)->select();
使用 field()方法在新增时,验证字段的合法性; Db::*name(‘user’)->field(‘username, email, details’)->insert($data);
三.alias
使用 alias()方法,给数据库起一个别名; Db::name(‘user’)->alias(‘a’)->select();
四.limit
使用 limit()方法,限制获取输出数据的个数; Db::name(‘user’)->limit(5)->select();
分页模式,即传递两个参数,比如从第 3 条开始显示 5 条 limit(2,5); Db::name(‘user’)->limit(2, 5)->select();
实现分页,需要严格计算每页显示的条数,然后从第几条开始;
//第一页Db::name('user')->limit(0,5)->select();//第二页Db::name('user')->limit(5,5)->select();
五.page
page()分页方法,优化了 limit()方法,无须计算分页条数;
//第一页Db::name('user')->page(1,5)->select();//第二页Db::name('user')->page(2,5)->select();
六.order
使用 order()方法,可以指定排序方式,没有指定第二参数,默认 asc; Db::name(‘user’)->order(‘id’, ‘desc’)->select();
支持数组的方式,对多个字段进行排序; Db::name(‘user’)->order([‘create_time’=>’desc’, ‘price’=>’asc’])->select();
七.group
使用 group()方法,给性别不同的人进行 price 字段的总和统计; Db::name(‘user’)->field(‘gender, sum(price)’)->group(‘gender’)->select()使用 group()方法,给性别不同的人进行 price 字段的总和统计; Db::name(‘user’)->field(‘gender, sum(price)’)->group(‘gender’)->select()
八.having
使用 group()分组之后,再使用 having()进行筛选;
$result = Db::name('user')->field('gender, sum(price)')->group('gender')->having('sum(price)>600')->select();

若有收获,就点个赞吧
0 人点赞
