1. 迭代器(iterator)
- 迭代是访问集合元素的一种方式。
- 迭代器是一个可以记住遍历的位置的对象。
- 迭代器对象从集合的第一个元素开始访问,只能往前不能后退。
- 实现了iter方法和next方法的对象,就是迭代器。
2. 可迭代对象(iterable)
- 可以通过 for…in… 这类语句迭代读取的数据对象为可迭代对象。
- 具备iter方法的对象,就是一个可迭代对象。
常见可迭代对象数据类型:
- 列表(list)
- 元祖(tuple)
- 字符串(str)
- 字典(dict)
- 集合(set)
判断一个对象是否是可迭代对象:
from collections import Iterable # 判断迭代器则导入Iteratorisinstance('abc', Iterable) # Trueisinstance({}, Iterable) # Trueisinstance(123, Iterable) # False
for item in Iterable循环的本质:
先通过iter()函数获取可迭代对象iterable的迭代器,然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item,当遇到StopIteration的异常后循环结束。
3. 生成器(generator)
- 迭代器需要自己记录当前迭代的状态,才能根据当前状态生成下一个数据。
- 生成器能记录当前状态,并配合next()函数进行迭代使用,语法简便。
- 生成器是一类特殊的迭代器。
- 使用了yield的函数不再是函数,而是生成器。
创建生成器:
(1)将列表生成式的 [] 改成 ()
In [15]: L = [ x*2 for x in range(5)]In [16]: LOut[16]: [0, 2, 4, 6, 8]In [17]: G = ( x*2 for x in range(5))In [18]: GOut[18]: <generator object <genexpr> at 0x7f626c132db0>
(2)使用yield关键字的函数
斐波那契数列(迭代器版):
class FibIterator(object):"""斐波那契数列迭代器"""def __init__(self, n):""":param n: int, 指明生成数列的前n个数"""self.n = n# current用来保存当前生成到数列中的第几个数了self.current = 0# num1用来保存前前一个数,初始值为数列中的第一个数0self.num1 = 0# num2用来保存前一个数,初始值为数列中的第二个数1self.num2 = 1def __next__(self):"""被next()函数调用来获取下一个数"""if self.current < self.n:num = self.num1self.num1, self.num2 = self.num2, self.num1 + self.num2self.current += 1return numelse:raise StopIterationdef __iter__(self):"""迭代器的__iter__返回自身即可"""return selfif __name__ == '__main__':fb = FibIterator(10)for i in fb:print(i, end=' ') # 0 1 1 2 3 5 8 13 21 34
斐波那契数列(生成器版):
def fib(n):current = 0num1, num2 = 0, 1while current < n:num = num1num1, num2 = num2, num1 + num2current += 1yield numreturnF = fib(10)print(list(F)) # [0 1 1 2 3 5 8 13 21 34]
yield关键字的作用:
- 保存当前运行状态(断点),然后暂停执行,将生成器函数挂起。
- 将yield关键字后面表达式的值作为返回至返回,相当于return作用。
Python3中的生成器可以return一个值,Python2中生成器的return后面不能有任何表达式。
唤醒生成器函数:
- next()
- next()
- send(data)
4. 闭包
在函数内部再定义一个函数,并且这个函数用到了外层函数的变量,那么将这个函数以及用到的一些变量称之为闭包。
def line_conf(a, b):
def line(x):
return a*x + b
return line
line1 = line_conf(1, 1)
line2 = line_conf(4, 5)
print(line1(5))
print(line2(5))
闭包的特点:
- 减少了参数的传递,优化了变量,增加可移植性和复用性,原来需要类对象完成的工作,闭包也可以完成。
- 由于闭包引用了外部函数的局部变量,导致外部函数的局部变量没有及时释放,消耗内存。
修改外层函数中的变量(nonlocal):
nonlocal需要绑定一个局部变量
def counter(start=0):
def incr():
nonlocal start
start += 1
return start
return incr
c1 = counter(5)
print(c1()) # 6
print(c1()) # 7
5. 变量作用域
global关键字用来在函数或其他局部作用域中使用全局变量。但是如果不修改全局变量也可以不使用global关键字。
声明全局变量,如果在局部要对全局变量修改,需要在局部也要先声明该全局变量:
gcount = 0
def global_test():
global gcount
gcount +=1
print (gcount)
global_test() # 1
在局部如果不声明全局变量,并且不修改全局变量。则可以正常使用全局变量:
gcount = 0
def global_test():
print(gcount)
global_test() # 0
global 定义的变量,表明其作用域在局部以外,即局部函数执行完之后,不销毁 函数内部以global定义的变量:
def add_a():
global a
a = 3
add_a()
print(a) # 3
nonlocal关键字用来在函数或其他作用域中使用外层(非全局)变量:
def make_counter():
count = 0
def counter():
nonlocal count
count += 1
return count
return counter
mc = make_counter()
print(mc()) # 1
print(mc()) # 2
print(mc()) # 3
def scope_test():
def do_local():
# 此函数定义了另外的一个spam字符串变量,
# 并且生命周期只在此函数内。此处的spam和外层的spam是两个变量,
# 如果写出spam = spam + “local spam” 会报错
spam = "local spam"
def do_nonlocal():
nonlocal spam # 使用外层的spam变量
spam = "nonlocal spam"
def do_global():
global spam
spam = "global spam"
spam = "test spam"
do_local()
print("After local assignmane:", spam)
do_nonlocal()
print("After nonlocal assignment:",spam)
do_global()
print("After global assignment:",spam)
scope_test()
print("In global scope:",spam)
outputs:
After local assignmane: test spam
After nonlocal assignment: nonlocal spam
After global assignment: nonlocal spam
In global scope: global spam
6. 装饰器
在不改变原来函数或类代码的基础上,为已经存在的对象添加额外的功能。
简单函数装饰器:
def use_logging(func):
def wrapper():
print("%s is running" % func.__name__)
return func() # 把 foo 当做参数传递进来时,执行func()就相当于执行foo()
return wrapper
def foo():
print('i am foo')
# 因为装饰器 use_logging(foo) 返回的时函数对象 wrapper,
# 这条语句相当于 foo = wrapper
foo = use_logging(foo)
foo() # 执行foo()就相当于执行 wrapper()
@语法糖:
def use_logging(func):
def wrapper():
print("%s is running" % func.__name__)
return func()
return wrapper
@use_logging
def foo():
print("i am foo")
foo() # 使用@语法糖,可以省去foo = use_logging(foo)
被装饰的函数有参数:
def timefun(func):
def wrappedfunc(*args, **kwargs): # 使用*args和**kwargs来接收不定长参数
func(*args, **kwargs)
return wrappedfunc
@timefun
def foo(a, b, c):
print(a+b+c)
foo(3,5,7) # 15
带参数的装饰器:
使用带参数的装饰器时,外层要多包裹一层函数用于接收装饰器的参数。
def use_logging(level): # 接收装饰器的参数
def decorator(func):
def wrapper(*args, **kwargs):
if level == "warn":
print("[WARN]%s is running" % func.__name__)
elif level == "info":
print("[INFO]%s is running" % func.__name__)
return func(*args)
return wrapper
return decorator
@use_logging(level="warn")
def foo(name='foo'):
print("i am %s" % name)
foo() # [WARN]foo is running
# i am foo
类装饰器:
相比函数装饰器,类装饰器具有灵活度大、高内聚、封装性等优点。
使用类装饰器主要依靠类的call方法,当使用@形式将类装饰器附加到函数上时,就会调用此方法。
class Foo(object):
def __init__(self, func): # 接收函数
# 为了能够在__call__方法中调用原来bar指向的函数
# 所以在__init__方法中就需要一个实例属性来保存这个函数体的引用
self._func = func
def __call__(self): # 调用方法
print('class decorator runing')
self._func()
print('class decorator ending')
@Foo # 类名装饰
def bar():
print('bar')
bar() # class decorator runing
# bar
# class decorator ending
多个装饰器的执行顺序
@a
@b
@c
def f ():
pass
它的执行顺序是从里到外,最先调用最里层的装饰器,最后调用最外层的装饰器,它等效于:
f = a(b(c(f)))
使用装饰器会造成函数的元信息丢失
def note(func):
"""note function"""
def wrapper():
"""wrapper function"""
print('note something')
return func()
return wrapper
@note
def test():
"""test function"""
print('I am test')
test()
# 输出test函数的文档注释
print(test.__doc__) # note something
# I am test
# wrapper function
结果输出的是wrapper函数的文档注释。
Python的functools包中提供了一个叫wraps的装饰器来消除这样的副作用。
from functools import wraps # 从functools中导入wraps装饰器
def note(func):
"""note function"""
@wraps(func) # 给wrapper函数加上wraps装饰器,带上参数func
def wrapper():
"""wrapper function"""
print('note something')
return func()
return wrapper
@note
def test():
"""test function"""
print('I am test')
test()
print(test.__doc__) # note something
# I am test
# test function
7. is与==
- is是比较两个引用是否指向了同一个对象(引用比较)。
- ==是比较两个对象的值是否相等(值比较)。
- ==实质上是调用对象的eq方法。
8. 可变类型与不可变类型
可变类型(内容可变,地址不变):
不可变类型(内容一变,地址就变):
整型(int)、浮点型(float)、字符串(string)、元祖(tuple)。
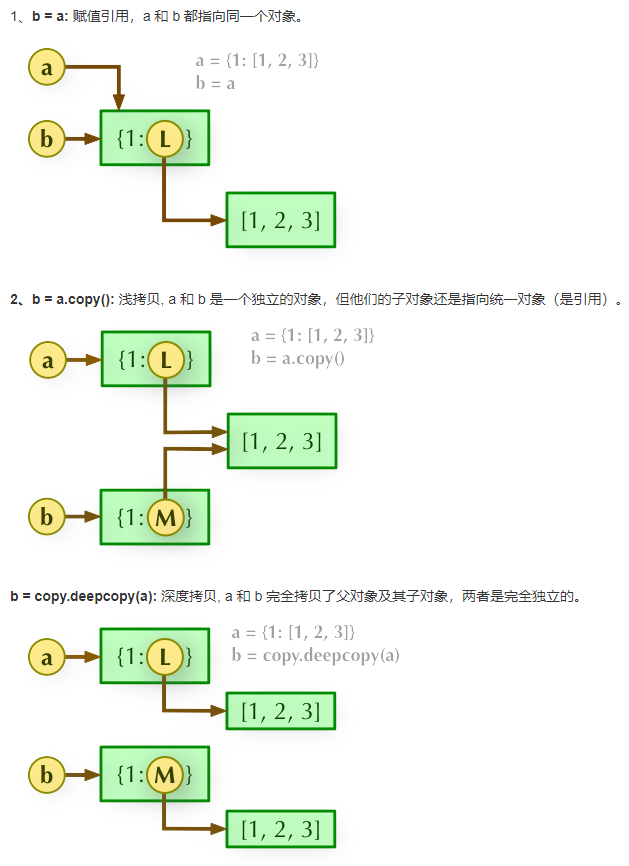
9. 浅拷贝与深拷贝与=赋值
- 赋值(=)是进行对象引用(内存地址)的传递。
- 浅拷贝(x.copy()或copy.copy(x))只拷贝对象本身,不会拷贝起内部的嵌套对象。对于内部的嵌套对象,依然使用原始的引用(顶层拷贝)。
浅拷贝可以分两种情况讨论:
- 当拷贝的只是不可变对象(数字、字符串、元祖)时和“赋值”的情况一样,是对象引用(同一内存地址)。
- 当拷贝的值是可变对象(列表、集合、字典)时会产生一个“不是那么独立的对象”存在。又为分两种情况:
- 复制的对象中无嵌套复杂对象
- 复制的对象中有嵌套复杂对象(例如一个列表中的一个子元素是一个列表)时,两个子元素列表是指向同一内存地址的。
- 深拷贝(copy.deepcopy(x))是对于一个对象所有层次的拷贝(递归拷贝,新建内存空间)。
10. 私有化变量
- xx: 公有变量
- _x: 单前置下划线,私有化属性或方法,from somemodule import *禁止导入,类对象和子类可以访问。
- __xx:双前置下划线,避免与子类中的属性命名冲突,无法在外部直接访问(名字重整所以访问不到)。
- xx:双前后下划线,用户名字空间的魔法对象或属性。例如:init ,不要自己发明这样的名字。
- xx_:单后置下划线,用于避免与Python关键词的冲突。
当类设置了私有变量后,因为外部不能直接访问,要为其额外增加方法来访问和修改私有变量(使用@property装饰器):
class Money(object):
def __init__(self):
self.__money = 0
@property
# 使用装饰器对money进行装饰,那么会自动添加一个叫money的属性,当调用获取money的值时,调用此下一行的方法
def money(self):
return self.__money
@money.setter
# 使用装饰器对money进行装饰,当对money设置值时,调用下一行的方法
def money(self, value):
if isinstance(value, int):
self.__money = value
else:
print("error:不是整型数字")
a = Money()
a.money = 100 # 使用@property装饰器后,与公有变量操作无异
print(a.money)
11.面向对象 / 类(OOP)
类属性与实例属性
- 实例属性属于各个实例所有,互不干扰;
- 类属性属于类所有,所有实例共享一个属性;
- 实例对象无法通过直接引用来修改类属性,直接引用修改会新生成一个同名的实例属性,并会屏蔽同名类属性。
```python
class People(object):
address = ‘山东’ # 类属性
def init(self):
self.name = '小王' # 实例属性 self.age = 20 # 实例属性
p = People() p.age = 12 # 修改实例属性 print(p.name) # 小王 print(p.age) # 12
print(p.address) # 访问类属性—>山东 p.address= ‘北京’ # 这里修改的不是类属性,而是给p新建了一个实例属性address print(p.address) # 访问的是新建的实例属性—>北京
print(People.address) # 访问类属性,类属性并未被修改—>山东
print(People.name) # 错误,类不能访问实例对象的属性 print(People.age) # 错误
<a name="g0XhX"></a>
#### 静态方法和类方法(@staticmethod & @classmethod)
- **类方法**使用 **@classmethod** 装饰器,可以使用类(也可使用实例)来调用方法(**带参数cls,表示类本身**)。
- **静态方法**使用 **@staticmethod **装饰器,它是跟类有关系但在运行时又不需要实例和类参与的方法(**没有 self 和 cls 参数**),可以使用类和实例来调用。
在静态方法中引用类属性的话,必须通过类对象来引用:
```python
class People(object):
country = 'china'
@staticmethod
def getCountry(): # 静态方法不需要参数
return People.country # 通过类对象来引用
p = People()
print(p.getCountry()) # china
print(People.getCountry()) # china
使用类方法,实例对象可以对类属性进行修改:
class People(object):
country = 'china'
@classmethod
def getCountry(cls): # 参数cls就是People类本身
return cls.country
@classmethod
def setCountry(cls,country):
cls.country = country
p = People()
print(p.getCountry()) # china
print(People.getCountry()) # china
p.setCountry('japan') # 实例对象调用类方法,修改类属性country
print(p.getCountry()) # japan
print(People.getCountry()) # japan
多态:
定义时的类型和运行时的类型不一样,此时就成为多态。
多继承中同名函数的调用优先级(mro):
class base(object):
def test(self):
print('----base test----')
class A(base):
def test(self):
print('----A test----')
# 定义一个父类
class B(base):
def test(self):
print('----B test----')
# 定义一个子类,继承自A、B
class C(A,B):
pass
obj_C = C()
obj_C.test() # ----A test----
print(C.__mro__) # 可以查看C类的对象搜索方法时的先后顺序
# 输出:(<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.base'>, <class 'object'>)
# 优先级:C > A > B > base
重写与调用父类方法:
子类中重写同名方法会覆盖掉父类方法:
class Animal(object):
def sayHello(self):
print("---1---")
class Cat(Animal):
def sayHello(self):
print("---2---")
kitten= Cat()
kitten.sayHello() # ---2---
调用父类方法:
class Animal(object):
def __init__(self,name):
self.name = name
self.color = 'yellow'
class Cat(Animal):
def __init__(self,name):
# 调用父类的__init__方法1(python2)
#Cat.__init__(self,name)
# 调用父类的__init__方法2
#super(Bosi,self).__init__(name)
# 调用父类的__init__方法3
super().__init__(name)
def getName(self):
return self.name
kitten= Cat('mimi')
print(kitten.name) # mimi
print(kitten.color) # yellow
魔法方法 / 属性:
- new 在 init 之前被调用,用来创建实例。
- del:删除一个对象时调用,析构函数。
- doc:查看类文档注释。
- str 是用 print 和 str 显示的结果,repr 是直接显示的结果。
slots:类属性,限制该class实例能添加的属性,不能限制继承它的子类。 ```python class Person(object): slots = (“name”, “age”) # 限制为只能添加name和age实例属性
def init(self):
self.name = '老宋' self.age = 22 # self.score = 90 # 不可定义该属性
P = Person() P.name = “老王” P.age = 20 print(P.name) print(P.age)
P.score = 100 # 报错:AttributError: ‘Person’ object has no attribute ‘score’ print(P.score) ```
- call 使得可以对实例进行调用,类装饰器。
- mro:查看类的对象搜索方法时的先后顺序。
- getitem 用类似 obj[key] 的方式对对象进行取值。
- getattr 用于获取不存在的属性 obj.attr。
12. 垃圾回收机制
python采用的是引用计数机制为主,分代收集机制为辅的策略。
- 小整数[-5,256]共用对象,常驻内存。
- 单个字符共用对象,常驻内存。
- 单个单词,不可修改,默认开启intern机制,共用对象,引用计数为0,则销毁。
- 字符串(含有空格),不可修改,没开启intern机制,不共用对象,引用计数为0,销毁。
- 大整数不共用内存,引用计数为0,销毁。
- 数值类型和字符串类型在 Python 中都是不可变的,这意味着你无法修改这个对象的值,每次对变量的修改,实际上是创建一个新的对象。

若有收获,就点个赞吧
0 人点赞
