前面我们已经知道雪花算法的三个问题,以及也简述了我们针对雪花算法的几个方案。这里详细描述针对雪花算法的调整和我们自己的方案。
bit划分调整
我们对雪花算法的bit划分做了调整,将“机器id(workerId)”从高位置换到了地位,同时将bit也边更为了13bit,同时缩减了序列号(自增域)的bit为9bit。
将其中“机器id”调整到最后,是为了避免“序列号”增1导致的整体数据增1的问题,这样可以在一定程度上规避外部数据对id的猜测,以防止恶意爬取。
==================================分割线===================================
v1.0.2 之后调整为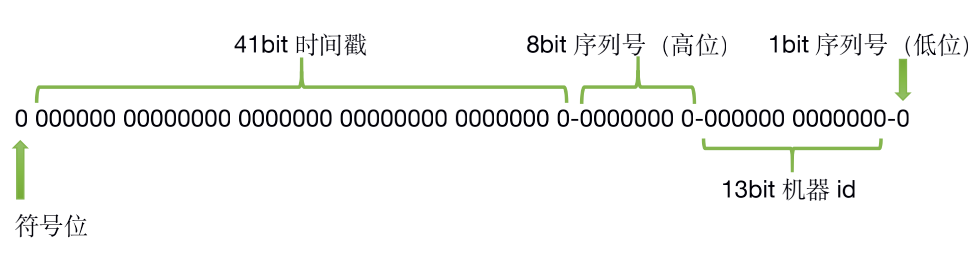
v1.0.2,解决整体总是为奇数或者偶数的问题,将9bit的序列号拆分,最低bit进行自增处理,可以解决持续的奇偶数问题
注意:
不过对应的机器码(也叫序列号)对应的值还是9bit,只是高8bit和低1bit拆分开了
时间获取处理
采用“历史时间”:
这里是我们方案的核心,我们这里采用的不是实际时间,而是历史时间,在进程启动后,我们会将当前时间(实际处理采用了延迟10ms启动)作为该业务这台机器进程的时间戳中的起始时间字段。后续的自增是在序列号自增到最大值时候时间戳增1,而序列号重新归为0,算是将时间戳和序列号作为一个大值进行自增,只是初始化不同。
序列号自增:
每次有数据请求,直接对序列号增加即可,序列号从0增加到最大,到达最大时,时间戳字段增加1,其实是时间增加1毫秒,序列号重0计算。
机器id分配和回收:
对机器的分配和回收这里有三种默认方式,不过也支持用户自定义实现
(单机版)zookeeper分配和回收:
分配采用哈希方式在预分配的一些空置永久节点中进行分配,节点后缀是有编号的,查找其中节点没有被占用,或者被占用但是占用超时的节点进行分配,其中分配的编号就是WorkerId。分配完毕,定期更新节点中的超时时间,超时后下次节点分配时会判断超时。这里初始节点默认设置为16个节点,如果节点都被占用(占用或者没占用但是超时时间没过),则模仿HashMap方式进行2倍扩容,然后重新分配。
(单机版)db分配和回收:
先看过期的里面最小的id,找到了则当前workerId就是机器id。如果过期中没找到,则查看其中最大的workerId并增1,然后新增,当前增1后的workerId就是分配的workerId。
(分布式版)集群分配workerId:
客户端的wokerId是每次Buffer请求中携带过来的,这样对客户端而言就没有workerId上限问题,因为workerId是服务端节点分配的。由于采用了网络传输,为了提高性能,客户端这里采用双Buffer+异步刷新方式,server端这里采用改进版的雪花+zookeeper分配和回收wokerId方式。
问题解决方式
1.时间回拨问题:
采用历史时间则天然的不存在时间回拨问题。但是在超高并发情况下,历史的时间很快用完,时间一直保持在最新时间的话,这个时候出现时间回拨,则采用业界对于时间回拨的处理方式(首次等待,即等待一段回拨时间)
2.机器id分配及回收:
机器的id分配和回收,我们这里采用zookeeper和db两种方式分配,这两种方式,均只有在进程启动的时候生效,后续就不再跟客户端有更多交互,唯一的是有个定时上报过期时间的任务。该过期时间为24小时,因此zookeeper或者db宕机一天,该发号器都不会有任何问题。回收这里采用的是上报的过期时间,过期了,则下次分配可以直接使用。
3.机器id上限
其中单机版的zookeeper和 DB均不是解决这个问题而存在的,其中(分布式版)distribute分配workerId是采用服务端方式,用服务端方式启动作为workerId的分配者,客户端使用的时候每次Buffer请求中服务端会将那一次的workerId和时间戳返回过来。这样虽然服务集群的workerId上限(即服务集群节点个数上限)是有的,但是对于客户端拥有的集群而言,理论上无上限,因为一个服务端节点就可以服务一个业务集群中的许多节点。
超高性能
由于时间戳采用的是过去时间,我们这样来看,如果实际QPS小于理论值(我们这里是9bit,理论值就是51.2w/s),那么一段时间后,产生的最新的全局id中包含的时间跟当前实际时间就有一定的时间差,那么这个时间差我们可以称之为“时间缓存”,而每一毫秒对应的都是0~最大值的这么多个数据,随着时间的积累,这里可以有海量的“逻辑上”的数据缓存。
我们想象这样一个场景,如果通常情况下业务的场景QPS是小于51.2w/s的,那么这个缓存就会越来越大,那么如果一瞬间有大量的请求过来的时候,由于我们有大量的缓存,我们这里就可以产生更多不重复的id,将QPS提高到几十倍甚至更多,自己的小本测试中可以达到1200w/s。
如果QPS一直是高位的话比51.2w/s高的话,那么这种其实业务方面就可以通过业务集群化扩容,将单个业务节点性能降低,不过就发号器技术上来说的话,目前单机版的这个在这种持续高并发情况下,经过测试理论上会保持在53w/s左右,更高则暂时无法支持。

若有收获,就点个赞吧
0 人点赞
