递归反转整个链表
// 定义:输入一个单链表头结点,将该链表反转,返回新的头结点ListNode reverse(ListNode head) {if (head == null || head.next == null) {return head;}ListNode last = reverse(head.next);head.next.next = head;head.next = null;return last;}


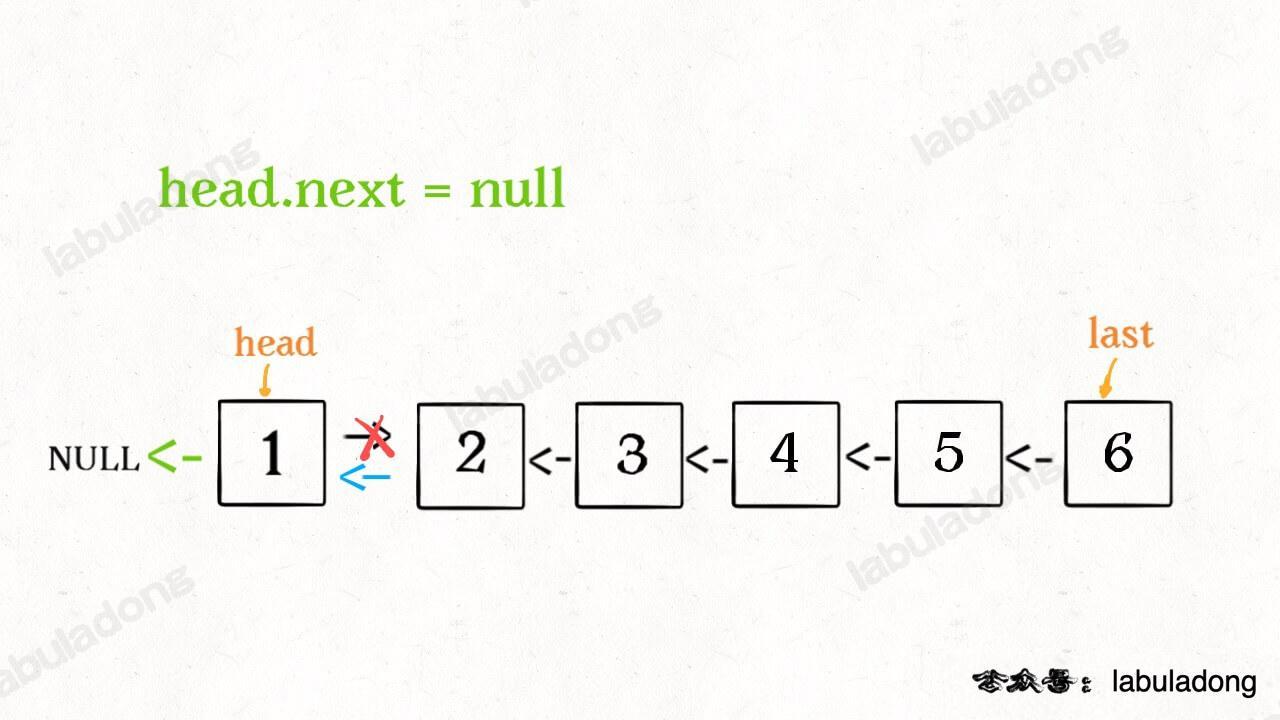
对于递归算法,最重要的就是明确递归函数的定义。具体来说,我们的 reverse 函数定义是这样的:
输入一个节点 head,将「以 head 为起点」的链表反转,并返回反转之后的头结点。
递归代码就是这么简洁优雅,不过其中有两个地方需要注意:
1、递归函数要有 base case,也就是这句:
if (head == null || head.next == null) {
return head;
}
意思是如果链表为空或者只有一个节点的时候,反转结果就是它自己,直接返回即可。
2、当链表递归反转之后,新的头结点是 last,而之前的 head 变成了最后一个节点,别忘了链表的末尾要指向 null:
head.next = null;
反转链表前N个节点
ListNode successor = null; // 后驱节点// 反转以 head 为起点的 n 个节点,返回新的头结点ListNode reverseN(ListNode head, int n) {if (n == 1) {// 记录第 n + 1 个节点successor = head.next;return head;}// 以 head.next 为起点,需要反转前 n - 1 个节点ListNode last = reverseN(head.next, n - 1);head.next.next = head;// 让反转之后的 head 节点和后面的节点连起来head.next = successor;return last;}

具体的区别:
1、base case 变为 n == 1,反转一个元素,就是它本身,同时要记录后驱节点。
2、刚才我们直接把 head.next 设置为 null,因为整个链表反转后原来的 head 变成了整个链表的最后一个节点。但现在 head 节点在递归反转之后不一定是最后一个节点了,所以要记录后驱 successor(第 n + 1 个节点),反转之后将 head 连接上。
反转链表的一部分
首先,如果 m == 1,就相当于反转链表开头的 n 个元素嘛,也就是我们刚才实现的功能
如果 m != 1 怎么办?如果我们把 head 的索引视为 1,那么我们是想从第 m 个元素开始反转对吧;如果把 head.next 的索引视为 1 呢?那么相对于 head.next,反转的区间应该是从第 m - 1 个元素开始的;那么对于 head.next.next 呢……
这就是递归思想,所以我们可以完成代码:
ListNode reverseBetween(ListNode head, int m, int n) {// base caseif (m == 1) {return reverseN(head, n);}// 前进到反转的起点触发 base casehead.next = reverseBetween(head.next, m - 1, n - 1);return head;}

若有收获,就点个赞吧
0 人点赞
