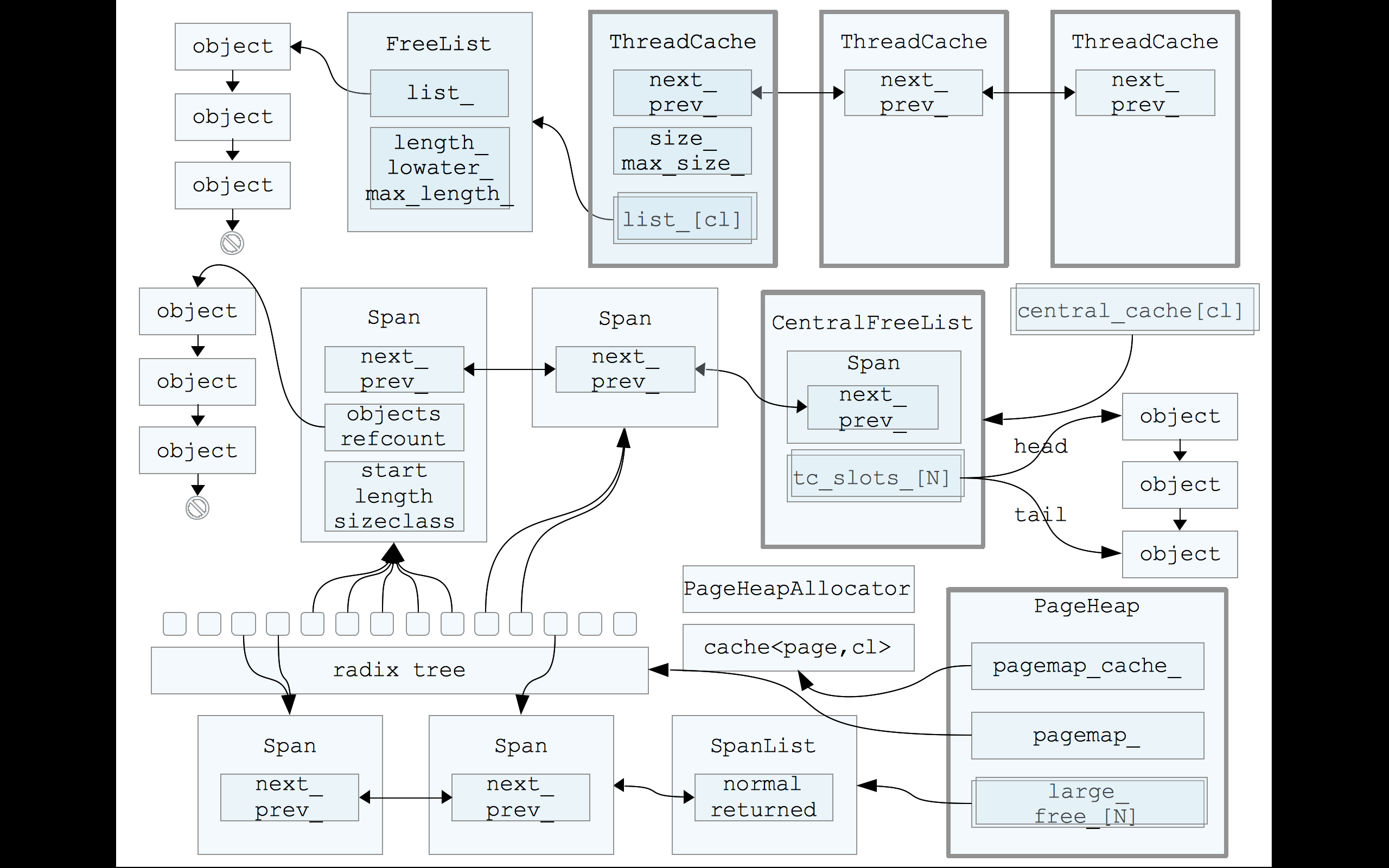
tcmalloc 的内存管理体系中,一共有三个层次: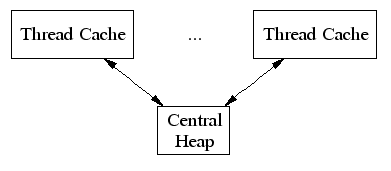
在tcmalloc中,<=32K的对象被称作是小对象,>32K的是大对象。
threadCache——小内存的分配
在小对象中,<=1K 的对象以8n bytes分配,1K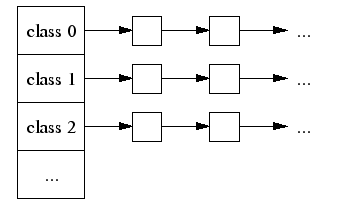
然后对所有的变长记录进行“取整”,例如分配7字节,就分配8字节,31字节分配32字节,得到多种规格的定长记录。这里带来了内部内存碎片的问题,即分配出去的空间不会被完全利用,有一定浪费。找到最小符合条件的。
如果小内存的分配器不够了,比如要分配7字节的,但是7字节分配器全都用完了,则会向 centralCache 申请一些内存,切割之后放进来。
centralCache 不够的话会向 pageHeap 申请。
threadCache 如何选择向 centralCache 申请的内存大小
由于小对象的分配是线程私有的,所以从这些 freelist 分配时无需加锁。centralCache是进程级别的,分配内存时会加自旋锁。
当threadCache 每次从 centralCache 申请内存的时候,分配多少内存也直接影响分配性能。申请地太少会导致频繁访问 centralCache,也就会频繁加锁,而申请的太多会导致内存浪费。
在tcmalloc里,threadCache 每次向 centralCache 申请的内存量是动态调整的,调整方式使用了类似把tcp窗口反过来用的慢启动(slow start)算法调整max_length, 每次申请内存是申请max_length和每个分配器对应的num_objects_to_move中取小的值的个数的内存块。
centralCache
中等大小的内存指的是 256K~1M 的内存。centralPageHeap 包含128个个空闲链表。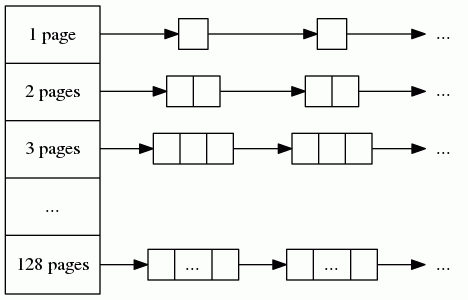
如果要申请 K 页的内存,会遍历上面对应的链表,如果找到了就返回,找不到的会找下一个空闲链表直到满足条件。如果k个页面的一次分配行为由连续的长度> k的页面满足了,剩下的连续页面将被重新插回到页面堆的对应的自由列表中。比如需要 22K的内存,最后只有25K的内存,剩下3K的内存会重新插入对应的链表中。
pageHeap
tcmalloc 中使用了 span 来管理分页,span是一组连续的页。在内存模型上粒度比页更大。
page array 维护了两个很重要的东西:page到span的映射关系,和空闲span的伙伴系统。
在一个连续的页数组里,每个span 是数组中一组连续的元素,span 的大小跟其区间有关。比如a span 是2页,b 是1页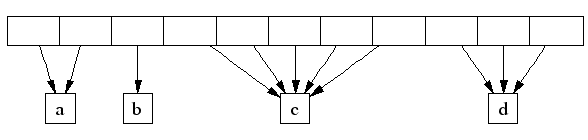
在32位系统中,使用一个中央数组(central array)映射了页面和span对应关系, 数组索引号是页面号,数组元素是页面所在的span。 在64位系统中,使用一个3-level radix tree记录了该映射关系。
大于 1M的内存申请时。如何找到满足的最小的 span? pageHeap 里维护了一颗红黑树,每个节点是一个 span。会在红黑树中找一个最小的满足条件的节点。然后将多余的重新插入到红黑树中。
内存回收
- 当一个object free的时候,会根据地址对齐计算所在的页面号,然后通过central array找到对应的span。
- 如果是小对象,span会告诉我们他的size class,然后把该对象插入当前线程的ThreadCache中。如果此时ThreadCache超过一个预算的值(默认2MB),则会使用垃圾回收机制把未使用的object从ThreadCache移动到CentralCache的central free lists中。
- 如果是大对象,span会告诉我们对象所在的页面号范围。 假设这个范围是[p,q], 先查找页面p-1和q+1所在的span,如果这些临近的span也是free的,则合并到[p,q]所在的span, 然后把这个span回收到PageHeap中。
- CentralCache的 central free lists类似ThreadCache的FreeList,不过它增加了一级结构,先根据size-class关联到spans的集合, 然后是对应span的object链表。如果span的链表中所有object已经free, 则span回收到PageHeap中。
优势
Tcmalloc的管理策略和ptmalloc有很大区别,理论上性能提高的主要原因在线程缓存不加锁和少量操作的自旋锁上。不过按照它的实现方式,不适合多线程频繁分配大于8个分页(32KB)的内存。否则自旋锁争用会相当厉害,不过这种情况也比较少。而减少和中央堆交互又依赖于他的线程缓存长度自适应算法
http://www.cnhalo.net/2016/06/13/memory-optimize/
https://gperftools.github.io/gperftools/tcmalloc.html

若有收获,就点个赞吧
0 人点赞
