1.强化学习的概念
强化学习是机器学习的一个领域,它是关于采取适当的行动,以在特定情况下最大化奖励。强化学习与监督学习的不同之处在于,在监督学习中,训练数据具有答案,因此模型用正确答案本身训练,而在强化学习中,没有答案,代理人(agent)决定如何做执行给定的任务。 在没有训练数据集的情况下,必然要从其经验中学习。一个强化学习由以下几个部分组成。
(1)代理人agent:代理人就是行动者,例如象棋中的棋子,在机器学习中,算法就是agent
(2)动作action:action是代理人可以做出的所有可能行动的集合
(3)奖励(Reward):奖励是我们衡量代理人行为成败的反馈
(4)贴现因子(discount factor):是一个金融学名词,也称为折现系数,在金融学中,discount factor和年份以及汇率有关,在强化学习中,discount factor一般会用GAMMA来表示,称之为奖励的衰减值
(5)环境environment:代理人活动的范围
(6)状态state:是代理人当下具体的情况
(7)策略policy:代理人根据当前状态确定下一个操作的策略,策略通常用π来表示
(8)价值value:带有折扣的预期长期收益,而不是短期奖励
(9)Q_value:Q_value类似于value,但它需要一个额外的参数:当前动作a。 Qπ(s,a)指的是当前状态s的长期回报,在政策π下采取行动
2.强化学习的分类
(1)model-free和model-based
所有的强化学习都可以分为两大类,第一类是不理解环境(model-free),另外一类时理解环境(model-based)。model-free的方法有很多,Q Learning, Sarsa,Policy Gradients;model_based的方法和model-free一样,也是Q Learning, Sarsa,Policy Gradients,但对比model-free它多了一个想象力,在model-free中只能按部就班一步一步等待真实世界的反馈,再根据反馈采取下一步的方法,而在model-based中,可以通过想象来预判发生的所有情况,然后根据想象的情况来选择最好的那一种。
(2)policy-based和value-based
另外一种分类方法就是基于概率(policy-based)和基于价值(value-based)。基于价值能通过感官分析所处的环境,直接输出下一步采取各种行动的概率,然后根据概率采取行动,所有行动都有可能被选中,只是概率不同,基于概率有policy gradients。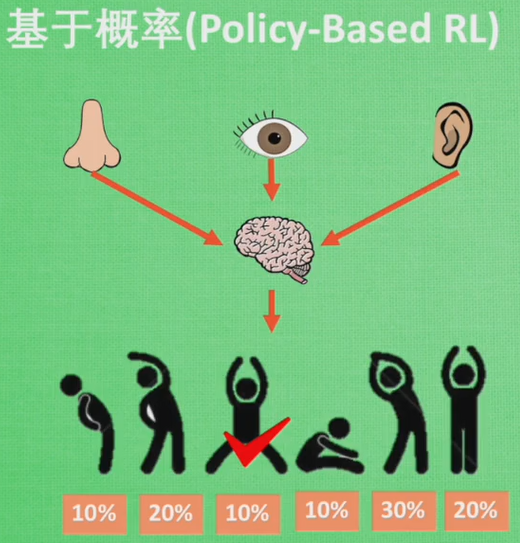
基于价值则是输出所有动作的价值,会根据最高价值来选择动作,相比基于概率,基于价值的选择更加铁定,毫不留情就选价值最高的,基于价值有Q learning 和 Sarsa。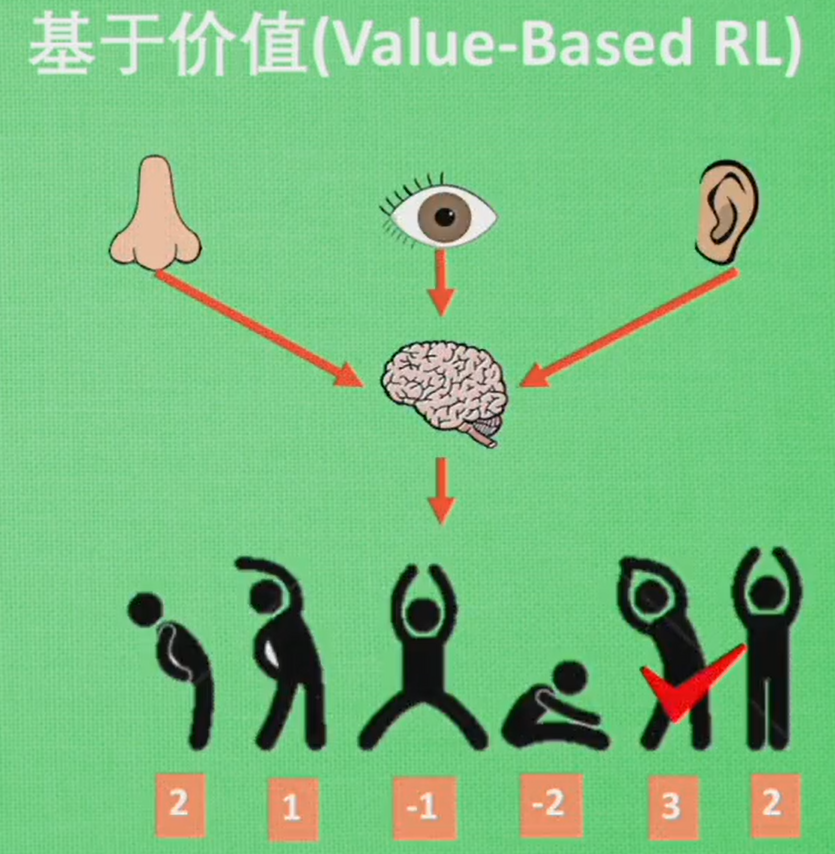
3.简单的Q learning 游戏代码
# -*- coding: utf-8 -*-"""@author: Haojie Shu@time: 2019/05/21@description: 简单的小游戏了解强化学习中的q_learning"""import numpy as npimport pandas as pdimport timenp.random.seed(2) # 伪随机数,让随机数固定下来N_STATES = 6 # 由于起始位置和终止位置的距离为6,因此状态数为6ACTIONS = ['left', 'right'] # 走左边或者走右边EPSILON = 0.9 # 90%选择最优动作,10%选择随机动作ALPHA = 0.1 # 学习效率GAMMA = 0.9 # 奖励的衰减值MAX_EPISODES = 13 # 只玩13个回合FRESH_TIME = 0.3 # 走一步花的时间def build_q_table(n_states, actions):"""建立q_table,并且用全0初始化它,最开始是一个全0的DataFrame"""table = pd.DataFrame(np.zeros((n_states, len(actions))),columns=actions,)"""left right0 0.0 0.01 0.0 0.02 0.0 0.03 0.0 0.04 0.0 0.05 0.0 0.0"""return tabledef choose_action(state, q_table): # 选择动作state_actions = q_table.iloc[state, :] # q_table的某一行# np.random.uniform:创建[low,high]的随机数,low默认值为0,high默认值为1,这样就可以保证10%的情况下会走这个if,随机选择左右# 当DataFrame的某一行全部为0也会走这个if,这个if会随机选择左或者右if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()):action_name = np.random.choice(ACTIONS)else:action_name = state_actions.idxmax() # 选择q_table里面left或者right比较大的索引return action_namedef get_env_feedback(s, a): # 环境对行为的反映if a == 'right': # 向右移动if s == N_STATES - 2: # 向右移动,并且如果s=4, 就会终止;因为再向右移动就是T了s_ = 'terminal'r = 1else:s_ = s + 1r = 0else: # 向左移动r = 0if s == 0:s_ = s # reach the wallelse:s_ = s - 1return s_, rdef update_env(s, episode, step_counter): # 这个是为了展示用env_list = ['-']*(N_STATES-1) + ['T']if s == 'terminal':interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter)print('{}'.format(interaction))time.sleep(2)else:env_list[s] = 'o'interaction = ''.join(env_list)print('{}'.format(interaction))time.sleep(FRESH_TIME)def rl():q_table = build_q_table(N_STATES, ACTIONS) # 初始化q_tablefor episode in range(MAX_EPISODES): # 从第一个回合玩到最后一个回合step_counter = 0 # 计步器s = 0 # 初始时,将探索者放到最左边is_terminated = False # 是否终止update_env(s, episode, step_counter)while not is_terminated: # 游戏没有终止就始终执行while循环a = choose_action(s, q_table) # 选择动作, 第一次由于全0,随机选择一个print a # 由于很多时候a都是随机的,最好打印一下动作a到底是左还是右s_, r = get_env_feedback(s, a) # 从动作中获取反馈q_predict = q_table.loc[s, a] # 估计值if s_ != 'terminal': # 没有终止q_target = r + GAMMA * q_table.iloc[s_, :].max() #else:q_target = r # 下个回合终止is_terminated = True # 断开while循环q_table.loc[s, a] += ALPHA * (q_target - q_predict) # 更新q_tableprint q_table # 每次看一下q_table到底是长什么样的s = s_update_env(s, episode, step_counter+1)step_counter += 1return q_tableif __name__ == "__main__":q_tables = rl()print(q_tables)
游戏的重要过程说明如下:
第一个游戏回合episode=0
初始化q_tables
left right
0 0.0 0.0
1 0.0 0.0
2 0.0 0.0
3 0.0 0.0
4 0.0 0.0
5 0.0 0.0
(1)第一步:观察者在起始位置s=0,此时输出
o——T
游戏没有终止
a=right
s =1, r=0
q_predict =0
由于s !=terminal
qtarget = r+ 0.9 * q_table. iloc [s, :].max=0+0.90=0
更新q_table
q_table[0, right] = q_table[0, right] + ALPHA (q_target-q_predict) = 0+0.1*0 = 0
此时的q_table:
left right
0 0.0 0.0
1 0.0 0.0
2 0.0 0.0
3 0.0 0.0
4 0.0 0.0
5 0.0 0.0
s=s_=1
此时s=1,episode=1,stepcounter+1=1,此时输出
-o—-T
并且step_counter=1
(2)第二步,此时没有跳出while语句,此时s=1,此时由于仍然是全0,继续随机选一个a = right
s = s+1=2, r=0
q_predict = 0
q_target = 0 +0.9*0=0
更新q_table,此时的q_table
left right
0 0.0 0.0
1 0.0 0.0
2 0.0 0.0
3 0.0 0.0
4 0.0 0.0
5 0.0 0.0
此时s = s =2,此时输出
—o—T
step_counter=2
(3)第三步,此时由于qtable仍然是全0,随机选择 a= left
此时 r= 0,s=s-1 =1
q_predict = 0
q_target = 0+0.9*0
更新q_table,此时的q_table
left right
0 0.0 0.0
1 0.0 0.0
2 0.0 0.0
3 0.0 0.0
4 0.0 0.0
5 0.0 0.0
s =s_ =1,此时输出
-o—-T
……
(38)第38步,s=4,随机选择的a=right
此时s_=terminal,r=1
q_predict = q_tables. iloc [4, right]=0
此时q_target =1,is_terminated = True
q_tables[4, right] = 0+ 0.1*1=0.1
此时的q_tables
left right
0 0.0 0.0
1 0.0 0.0
2 0.0 0.0
3 0.0 0.0
4 0.0 0.1
5 0.0 0.0
此时s=s_=terminal,此时完成一个游戏回合
第二个游戏回合epidosde=1
(1)s=0,先输出o——T,此时qtables的第一行由于全0,因此仍然是执行随机选择action,此次的随机结果为left
此时r=0,s由于等于0,撞墙了,此时是s=s=0
qpredict =0,q_target=0
此时q_tables不改变,s也不改变
(2)再次来一遍,此时的action为right,
s=s+1=1,r=0
此时qpredict=0,q_target = r=0
此时的q_tables仍然不改变
s=s=1
(3)此时的action为left,
s = s-1 =0,r=0
此时q_predict=0,q_target = r=0
此时的q_tables仍然不改变
s=s=0
…
(21)第21步,s=3,此时的a为right
此时的s_=s+1,r=0
此时的q_predict=0,q_target =0+0.1*0.9=0.09
此时的q_tables为
left right
0 0.0 0.0
1 0.0 0.0
2 0.0 0.0
3 0.0 0.009
4 0.0 0.1
5 0.0 0.0
(22)第22步,s=4,随机选取的a为right
此时s_=terminal,r=1,此时的q_predict =q_table. iloc[4, right]=0.1
q_target=1, is_terminated=True
q_table[4,right]=0.1+0.1*(1-0.1)=0.19
此时的q_table
left right
0 0.0 0.0
1 0.0 0.0
2 0.0 0.0
3 0.0 0.009
4 0.0 0.19
5 0.0 0.0
此时完成第二个游戏回合
第三个游戏回合epidosde=2
(1)…
(2)…
…
(7)第7步,此时s=2,a=right
此时s_=s+1=3,r=0
此时q_predict=0,q_target=0+0.9*0.009=0.0081
此时的q_table为
left right
0 0.0 0.0
1 0.0 0.0
2 0.0 0.00081
3 0.0 0.009
4 0.0 0.19
5 0.0 0.0
(8)第8步,此时s=3
此时的actionname 不再100%是随机的了,随机的概率降到了10%!!!
此时的action_name会选择left或者right中,数字大的那个索引,即right
此时s=s+1=4,r=0
此时q_predict = 0.009,q_target = 0.9(0.19-0)= 0.171
q_table.loc [3, right] = 0.009+0.1(0.171- 0.009) = 0.017829=0.0252
此时的q_table
left right
0 0.0 0.0
1 0.0 0.0
2 0.0 0.00081
3 0.0 0.009
4 0.0 0.252
5 0.0 0.0
(9)第9步,结束这一局的游戏…

若有收获,就点个赞吧
0 人点赞
