一、内存机制
1.1 js语言类型
JavaScript 是一种弱类型的、动态的语言。
- 弱类型:它支持隐式类型转换
- 动态:它在运行过程中才需要检查数据类型
1.2 js数据类型
基础类型:boolean、null、undefined、number、string、symbol
引用类型:object
原始类型的赋值会完整复制变量值,而引用类型的赋值是复制引用地址
1.3 内存空间
JavaScript 执行过程中, 主要有三种类型内存空间,分别是代码空间、栈空间和堆空间
栈空间:
- 栈空间就是调用栈,是用来存储执行上下文的空间
- 基础类型的数据值都会保存在栈中
- 栈空间不大,用于存放小数据
堆空间:
- 一块内存地址
- 引用类型的值存放在堆中
- 堆空间很大,能存放很多数据
区分栈、堆空间的原因:如果所有的数据都存放在栈空间,会影响上下文切换的效率,进而影响整个程序的执行效率
二、垃圾回收
javascript采用的是自动垃圾回收的策略,产生的垃圾数据是由垃圾回收器进行释放
2.1 栈中的垃圾回收
栈中有一个用于记录当前执行状态的指针(称为 ESP),当函数执行完需要出栈时,js会将ESP指针指向下一个需要执行的函数上下文中,这个下移操作就是销毁该函数保存在栈中的执行上下文
2.2 堆中的垃圾回收
了解堆中的垃圾回收前,需要了解两个概念:代际假说、分代收集
代际假说
- 大部分对象在内存中存在的时间很短,很多对象一经分配内存,很快就变得不可访问;
- 不死的对象,会活得更久
分代收集
在V8 中会把堆分为新生代和老生代两个区域,
新生代
- 存放的是生存时间短的对象
- 空间较小,只有1-8M
- 由副垃圾回收器进行垃圾回收
- 老生代
- 存放的生存时间久的对象
- 容量大
- 由主垃圾回收器进行垃圾回收
2.3 垃圾回收工作流程
- 标记空间中活动对象和非活动对象
- 活动对象指还在使用的对象
- 非活动对象指可以进行垃圾回收的对象
- 回收非活动对象所占据的内存
- 在所有的标记完成之后,统一清理内存中所有被标记为可回收的对象
- 内存整理
- 将不连续的内存空间(内存碎片)整理成连续的内存(这一步是可选的)
2.4 副垃圾回收器(新生代区域)回收流程
使用Scavenge 算法来处理:把新生代空间对半划分为两个区域,一半是对象区域,一半是空闲区域
新加入的对象都会存放到对象区域,当对象区域快被写满时,执行以下回收流程:
- 对对象区域中的垃圾做标记
- 将存活的对象复制到空闲区域中,同时还会把这些对象有序地排列起来(复制+内存整理)
- 对象区域与空闲区域进行角色翻转:也就是原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域
优点:
- 角色翻转的操作还能让新生代中的这两块区域无限重复使用下去
缺点:
- 执行清理时,都需要复制一次内容,需要时间成本
- 解决:新生代区域内存都比较小
- 因为区域较小,所以很容易就被填满
- 解决:对象晋升策略:经过两次垃圾回收依然还存活的对象,会被移动到老生代区中
2.5 主垃圾回收器(老生代区域)回收流程
老生区中的对象有两个特点:对象占用空间大、对象存活时间长
主垃圾回收器是采用标记 - 清除 算法进行垃圾回收
回收的流程:
- 标记阶段:遍历整个调用栈,如果没有找到对应堆中的内存地址的引用时,该地址就被标记为垃圾元素,如果找到对应堆的内存地址时,就被标记为活动对象
- 清除阶段:将标记的垃圾元素,从内存地址上删除
缺点:删除时会产生很多不连续的内存碎片
于是继续引入标记 - 整理 算法进行内存整理
整理的流程:
- 标记阶段:同回收流程的标记阶段,同时标记出垃圾元素、活动对象
- 整理阶段:让所有活动对象都向一端移动,然后直接清理掉端边界以外的内存
2.6 JavaScript运行时垃圾回收机制
全停顿:由于 JavaScript 是运行在主线程之上,一旦执行垃圾回收算法,都需要将正在执行的 JavaScript 脚本暂停下来,待垃圾回收完毕后再恢复脚本执行
具体影响:
新生代区域:区域较小,执行较快,对js运行影响不大
老生代区域:区域较大,执行时间较为长,很容易阻塞js运行
为了解决老生代区域垃圾回收卡顿问题于是引入:增量-标记 算法:
原理:把一个完整的垃圾回收任务拆分为很多小的任务,这些小的任务执行时间比较短,可以穿插在其他的 JavaScript 任务中间执行,降低单次垃圾回收执行时间
三、执行JavaScript机制
JavaScript 属于解释型语言,在每次运行时都需要通过解释器对程序进行动态解释和执行
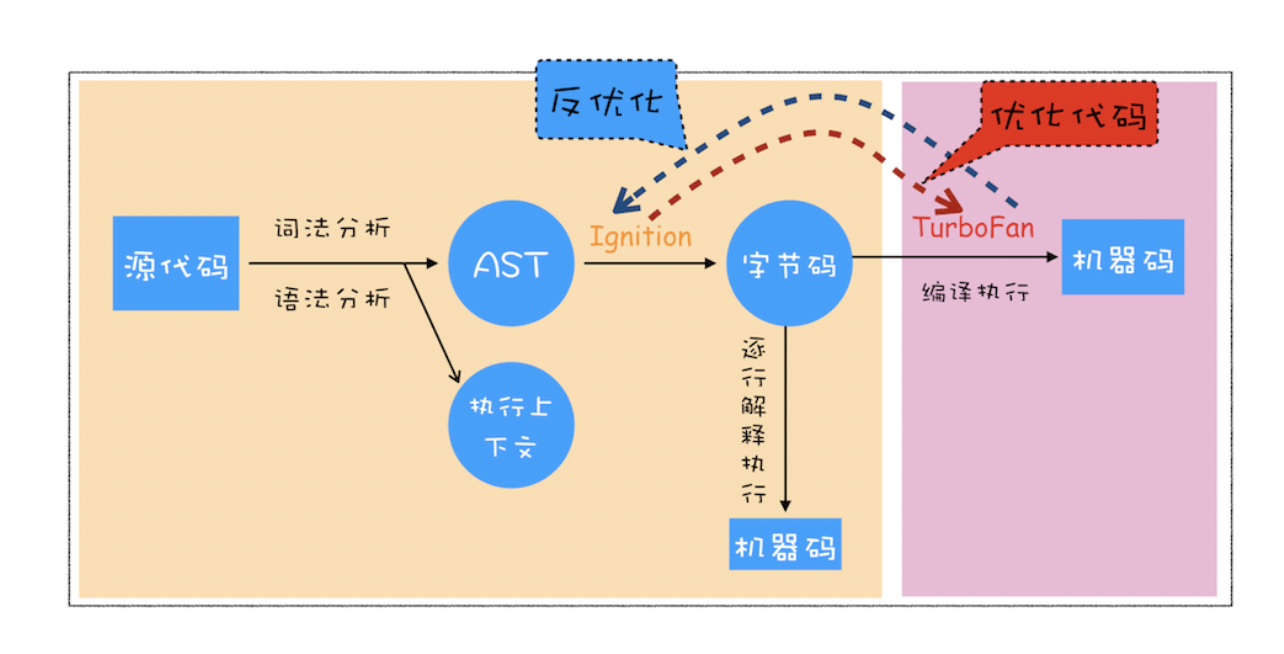
3.1 生成抽象语法树(AST)
具体阶段:
- 词法分析阶段:将一行行的源码拆解成一个个语法上不可能再分的、最小的单个字符或字符串 ```javascript let name = ‘gelx’
以上代码会被拆分为:
let —> 关键词 name —> 标识符 = —> 赋值 ‘gelx’ —> 字符串 ```
- 语法分析阶段:其作用是将上一步生成的 token 数据,根据语法规则转为 AST
3.2 生成字节码
有了以上AST后,解释器会根据AST生成字节码
字节码是介于 AST 和机器码之间的一种代码,与特定类型的机器码无关,字节码需要通过解释器将其转换为机器码后才能执行,它能够解决内存占用过多的问题
3.3 执行代码
执行流程如下:
- 判断该字节码是否是第一次被执行
- 第一次被执行的代码,解释器逐条解释执行
- 多次被执行的代码:标记为热点代码,编译器会把该字节码编译为高效的机器码,再次执行这段代码时,只需要执行机器码即可,(省去翻译为字节码的过程),大大提升代码的执行效率

若有收获,就点个赞吧
0 人点赞
