1.直接内存回收引起 load 飙高或者业务时延抖动
直接内存回收是指在进程上下文同步进行内存回收,那么它具体是怎么引起 load 飙高的呢?因为直接内存回收是在进程申请内存的过程中同步进行的回收,而这个回收过程可能会消耗很多时间,进而导致进程的后续行为都被迫等待,这样就会造成很长时间的延迟,以及系统的 CPU 利用率会升高,最终引起 load 飙高。我们详细地描述一下这个过程,为了尽量不涉及太多技术细节,我会用一张图来表示,这样你理解起来会更容易。
从图里你可以看到,在开始内存回收后,首先进行后台异步回收(上图中蓝色标记的地方),这不会引起进程的延迟;如果后台异步回收跟不上进程内存申请的速度,就会开始同步阻塞回收,导致延迟(上图中红色和粉色标记的地方,这就是引起 load 高的地址)。那么,针对直接内存回收引起 load 飙高或者业务 RT 抖动的问题,一个解决方案就是及早地触发后台回收来避免应用程序进行直接内存回收,那具体要怎么做呢?我们先来了解一下后台回收的原理,如图: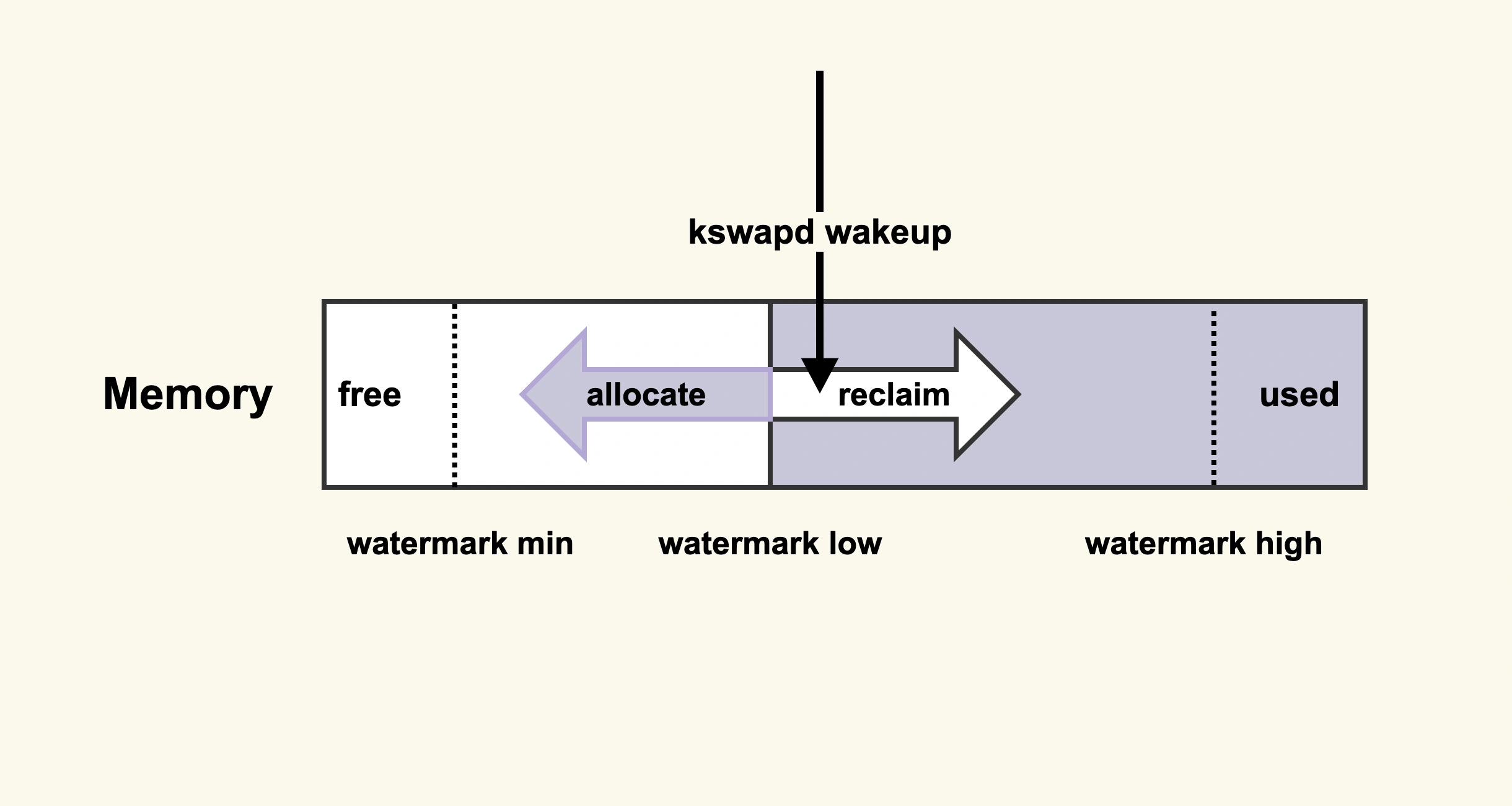
它的意思是:当内存水位低于 watermark low 时,就会唤醒 kswapd 进行后台回收,然后 kswapd 会一直回收到 watermark high。那么,我们可以增大 minfree_kbytes 这个配置选项来及早地触发后台回收,该选项最终控制的是内存回收水位,不过,内存回收水位是内核里面非常细节性的知识点,我们可以先不去讨论。
vm.min_free_kbytes = 4194304
通过修改该参数:**_echo 200000 > /proc/sys/vm/min_free_bytes**
当然了,这样做也有一些缺陷:提高了内存水位后,应用程序可以直接使用的内存量就会减少,这在一定程度上浪费了内存。所以在调整这一项之前,你需要先思考一下,应用程序更加关注什么,如果关注延迟那就适当地增大该值,如果关注内存的使用量那就适当地调小该值。除此之外,对 CentOS-6(对应于 2.6.32 内核版本) 而言,还有另外一种解决方案:vm.extra_free_kbytes = 4194304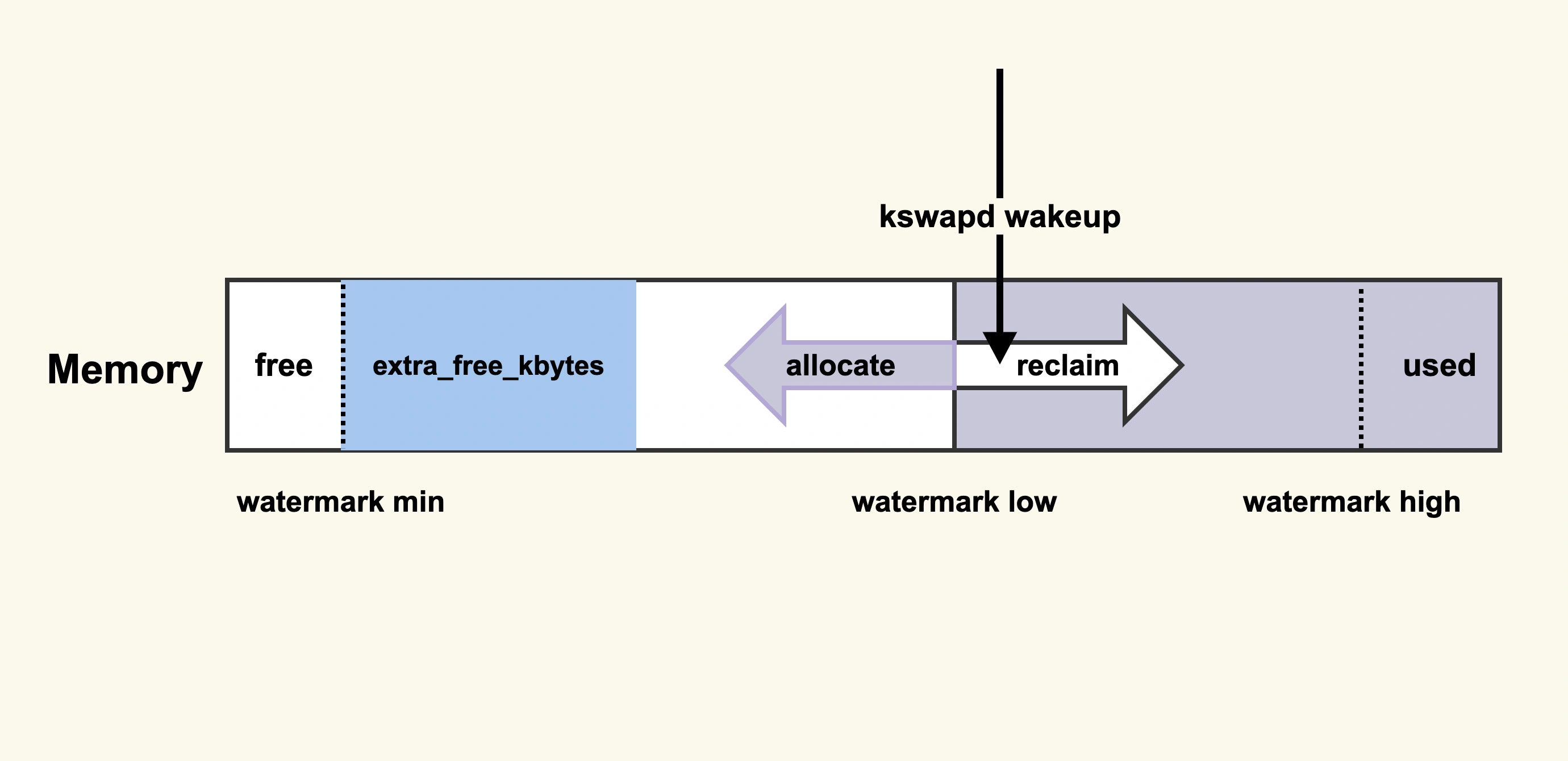
2.系统中脏页过多引起 load 飙高
接下来,我们分析下由于系统脏页过多引起 load 飙高的情况。在前一个案例中我们也提到,直接回收过程中,如果存在较多脏页就可能涉及在回收过程中进行回写,这可能会造成非常大的延迟,而且因为这个过程本身是阻塞式的,所以又可能进一步导致系统中处于 D 状态的进程数增多,最终的表现就是系统的 load 值很高。我们来看一下这张图,这是一个典型的脏页引起系统 load 值飙高的问题场景: 如图所示,如果系统中既有快速 I/O 设备,又有慢速 I/O 设备(比如图中的 ceph RBD 设备,或者其他慢速存储设备比如 HDD),直接内存回收过程中遇到了正在往慢速 I/O 设备回写的 page,就可能导致非常大的延迟。
如图所示,如果系统中既有快速 I/O 设备,又有慢速 I/O 设备(比如图中的 ceph RBD 设备,或者其他慢速存储设备比如 HDD),直接内存回收过程中遇到了正在往慢速 I/O 设备回写的 page,就可能导致非常大的延迟。
那如何解决这类问题呢?一个比较省事的解决方案是控制好系统中积压的脏页数据。很多人知道需要控制脏页,但是往往并不清楚如何来控制好这个度,脏页控制的少了可能会影响系统整体的效率,脏页控制的多了还是会触发问题,所以我们接下来看下如何来衡量好这个“度”。首先你可以通过 sar -r 来观察系统中的脏页个数:sar -r 1
root@k8s-master01:~/test# sar -r 1Linux 4.15.0-20-generic (k8s-master01) 2021年09月26日 _x86_64_ (2 CPU)09时00分55秒 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty09时00分56秒 3688740 5024740 2907440 44.08 118832 1355320 5620632 85.21 1292184 1066120 2009时00分57秒 3688740 5024740 2907440 44.08 118832 1355320 5620632 85.21 1292164 1066120 2009时00分58秒 3687856 5023868 2908324 44.09 118840 1355324 5755144 87.25 1292996 1066124 2009时00分59秒 3688756 5024768 2907424 44.08 118840 1355324 5619224 85.19 1292680 1066124 20
kbdirty 就是系统中的脏页大小,它同样也是对 /proc/vmstat 中 nr_dirty 的解析。你可以通过调小如下设置来将系统脏页个数控制在一个合理范围:
vm.dirty_background_bytes = 0vm.dirty_background_ratio = 10vm.dirty_bytes = 0vm.dirty_expire_centisecs = 3000vm.dirty_ratio = 20root@k8s-master01:~/test# cat /proc/sys/vm/dirty_expire_centisecs3000root@k8s-master01:~/test# cat /proc/sys/vm/dirty_ratio20
调整这些配置项有利有弊,调大这些值会导致脏页的积压,但是同时也可能减少了 I/O 的次数,从而提升单次刷盘的效率;调小这些值可以减少脏页的积压,但是同时也增加了 I/O 的次数,降低了 I/O 的效率。至于这些值调整大多少比较合适,也是因系统和业务的不同而异,我的建议也是一边调整一边观察,将这些值调整到业务可以容忍的程度就可以了,即在调整后需要观察业务的服务质量 (SLA),要确保 SLA 在可接受范围内。调整的效果你可以通过 /proc/vmstat 来查看:
root@k8s-master01:~/test# grep "nr_dirty" /proc/vmstatnr_dirty 2nr_dirty_threshold 252191nr_dirty_background_threshold 125941root@k8s-master01:~/test#
3.系统 NUMA 策略配置不当引起的 load 飙
除了我前面提到的这两种引起系统 load 飙高或者业务延迟抖动的场景之外,还有另外一种场景也会引起 load 飙高,那就是系统 NUMA 策略配置不当引起的 load 飙高。比如说,我们在生产环境上就曾经遇到这样的问题:系统中还有一半左右的 free 内存,但还是频频触发 direct reclaim,导致业务抖动得比较厉害。后来经过排查发现是由于设置了 zone_reclaim_mode,这是 NUMA 策略的一种。设置 zone_reclaim_mode 的目的是为了增加业务的 NUMA 亲和性,但是在实际生产环境中很少会有对 NUMA 特别敏感的业务,这也是为什么内核将该配置从默认配置 1 修改为了默认配置 0: mm: disable zone_reclaim_mode by default ,配置为 0 之后,就避免了在其他 node 有空闲内存时,不去使用这些空闲内存而是去回收当前 node 的 Page Cache,也就是说,通过减少内存回收发生的可能性从而避免它引发的业务延迟。
root@k8s-master01:~/test# numactl --hardwareavailable: 1 nodes (0)node 0 cpus: 0 1node 0 size: 6441 MBnode 0 free: 3495 MBnode distances:node 00: 10
推荐将 zone_reclaim_mode 配置为 0
root@k8s-master01:~/test# cat /proc/sys/vm/zone_reclaim_mode0root@k8s-master01:~/test#通过echo方式修改
因为相比内存回收的危害而言,NUMA 带来的性能提升几乎可以忽略,所以配置为 0,利远大于弊。

若有收获,就点个赞吧
0 人点赞
