六、Mybatis缓存
⼀级缓存
在⼀个sqlSession中,对User表根据id进⾏两次查询,查看他们发出sql语句的情况
@Testpublic void oneLevelCache() {// 第一次执行将结果放入缓存System.out.println(iRoleMapper.findById(2));// 同sqlSession直接从缓存中取System.out.println(iRoleMapper.findById(2));}
通过console可以看到,实际上她只执行了一次sql
==> Preparing: select id, role_name roleName from role where id = ?==> Parameters: 2(Integer)<== Columns: id, roleName<== Row: 2, 游客<== Total: 1[Role(id=2, roleName=游客)][Role(id=2, roleName=游客)]
同样是对user表进⾏两次查询,但在两次查询之间进⾏了⼀次update操作
@Testpublic void oneLevelCache2() {// 第一次执行将结果放入缓存System.out.println(iRoleMapper.findById(2));// 由于默认开启自动提交, sqlSession.commit() 会清除缓存信息Role role2 = new Role();role2.setId(2);role2.setRoleName("leader2");iRoleMapper.update(role2);// 再次执行sqlSystem.out.println(iRoleMapper.findById(2));}
此时mybatis会查询两次
==> Preparing: select id, role_name roleName from role where id = ?==> Parameters: 2(Integer)<== Columns: id, roleName<== Row: 2, 游客<== Total: 1[Role(id=2, roleName=游客)]==> Preparing: update role set role_name = ? where id = ?==> Parameters: leader2(String), 2(Integer)<== Updates: 1==> Preparing: select id, role_name roleName from role where id = ?==> Parameters: 2(Integer)<== Columns: id, roleName<== Row: 2, leader2<== Total: 1[Role(id=2, roleName=leader2)]
总结
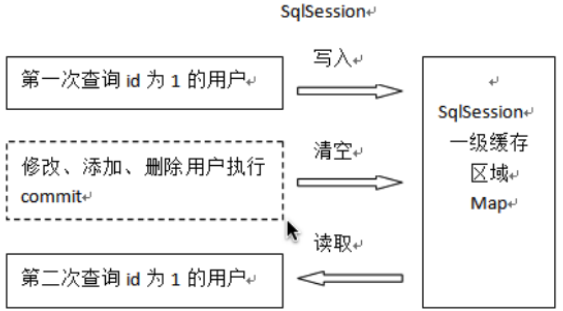
1、第⼀次发起查询⽤户id为1的⽤户信息,先去找缓存中是否有id为1的⽤户信息,如果没有,从数据
库查询⽤户信息。得到⽤户信息,将⽤户信息存储到⼀级缓存中。
2、 如果中间sqlSession去执⾏commit操作(执⾏插⼊、更新、删除),则会清空SqlSession中的 ⼀
级缓存,这样做的⽬的为了让缓存中存储的是最新的信息,避免脏读。
3、 第⼆次发起查询⽤户id为1的⽤户信息,先去找缓存中是否有id为1的⽤户信息,缓存中有,直 接从
缓存中获取⽤户信息。
⼀级缓存原理探究与源码分析
提到⼀级缓存就绕不开SqlSession,所以我们就直接从SqlSession,看看有没有创建缓存或者与缓存有关的属性或者⽅法
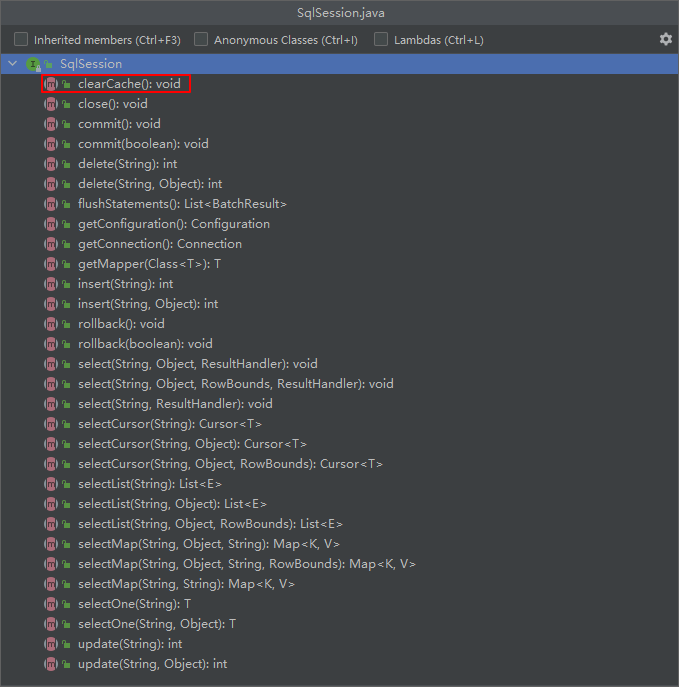
在SqlSession中发现好像只有clearCache()和缓存沾点关系,那么就直接从这个方法⼊手,分析源码时,我们要看它(此类)是谁,它的⽗类和⼦类分别又是谁,对如上关系了解了,才会对这个类有更深的认识,分析了⼀圈,你可能会得到如下这个流程图
再深⼊分析,流程⾛到Perpetualcache中的clear()⽅法之后,会调⽤其cache.clear()⽅法,那么这个cache是什么东⻄呢?点进去发现,
cache其实就是private Map cache = new HashMap();也就是⼀个Map,所以说cache.clear()其实就是map.clear(),也就是说,缓存其实就是
本地存放的⼀个map对象,每⼀个SqISession都会存放⼀个map对象的引⽤,那么这个cache是何时创建的呢?
我们可以查看一下putObject(Object key, Object value)这个方法,这个方法是向缓存map里put,找一下哪里调用了这个方法。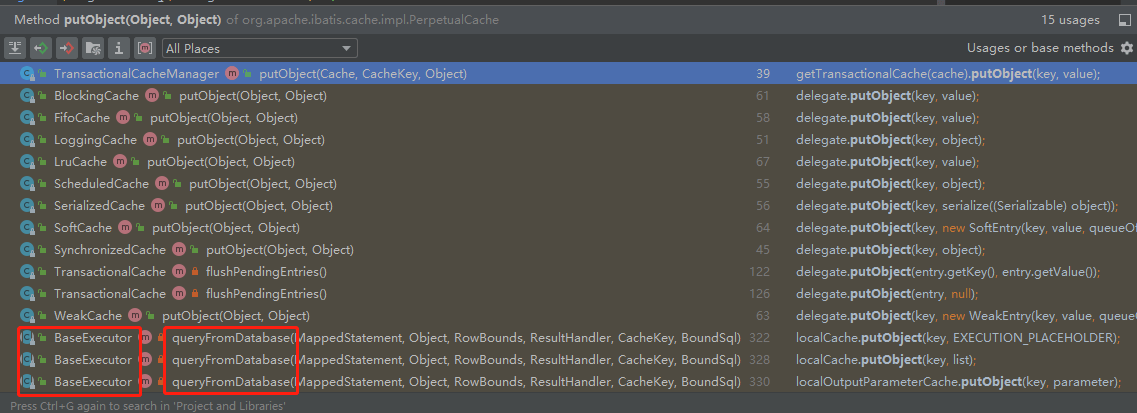
排除一些不太认识的缓存类,最熟悉的就是BaseExecutor了,我们可以不断的向上查找调用当前方法的方法,最后得出下面这个流程图
queryFromDatabase的主要意思就是从数据库中查询后向cache中put缓存,这里有个重要的参数key,这个key其实就是在第三步中createCacheKey中创建的。(此处第4步query方法中,会调用 localCache.getObject(key),如果获取到则直接返回从缓存中获取的数据)
那么我们来分析下这个方法@Overridepublic CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {if (closed) {throw new ExecutorException("Executor was closed.");}CacheKey cacheKey = new CacheKey();cacheKey.update(ms.getId());cacheKey.update(rowBounds.getOffset());cacheKey.update(rowBounds.getLimit());cacheKey.update(boundSql.getSql());List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();// mimic DefaultParameterHandler logicfor (ParameterMapping parameterMapping : parameterMappings) {if (parameterMapping.getMode() != ParameterMode.OUT) {Object value;String propertyName = parameterMapping.getProperty();if (boundSql.hasAdditionalParameter(propertyName)) {value = boundSql.getAdditionalParameter(propertyName);} else if (parameterObject == null) {value = null;} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {value = parameterObject;} else {MetaObject metaObject = configuration.newMetaObject(parameterObject);value = metaObject.getValue(propertyName);}cacheKey.update(value);}}if (configuration.getEnvironment() != null) {// issue #176cacheKey.update(configuration.getEnvironment().getId());}return cacheKey;}
大概看一遍,其重要逻辑就是把MappedStatement、RowBounds、BoundSql、Object parameterObject、configuration.getEnvironment().getId()通过CacheKey的update方法构造CacheKey。
configuration.getEnvironment().getId() 其实就是xml配置中environment 的id
public void update(Object object) {int baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);count++;checksum += baseHashCode;baseHashCode *= count;hashcode = multiplier * hashcode + baseHashCode;updateList.add(object);}
update方法其实就是重新计算 count、checksum、hashcode并且把新的对象更到添加到updateList(private transient List<Object> updateList;),再看一下CacheKey的equals方法
@Overridepublic boolean equals(Object object) {if (this == object) {return true;}if (!(object instanceof CacheKey)) {return false;}final CacheKey cacheKey = (CacheKey) object;if (hashcode != cacheKey.hashcode) {return false;}if (checksum != cacheKey.checksum) {return false;}if (count != cacheKey.count) {return false;}for (int i = 0; i < updateList.size(); i++) {Object thisObject = updateList.get(i);Object thatObject = cacheKey.updateList.get(i);if (!ArrayUtil.equals(thisObject, thatObject)) {return false;}}return true;}
二级缓存
⼆级缓存的原理和⼀级缓存原理⼀样,第⼀次查询,会将数据放⼊缓存中,然后第⼆次查询则会直接去缓存中取。但是⼀级缓存是基于sqlSession的,⽽⼆级缓存是基于mapper⽂件的namespace的,也就是说多个sqlSession可以共享⼀个mapper中的⼆级缓存区域,并且如果两个mapper的namespace 相同,即使是两个mapper,那么这两个mapper中执⾏sql查询到的数据也将存在相同的⼆级缓存区域中。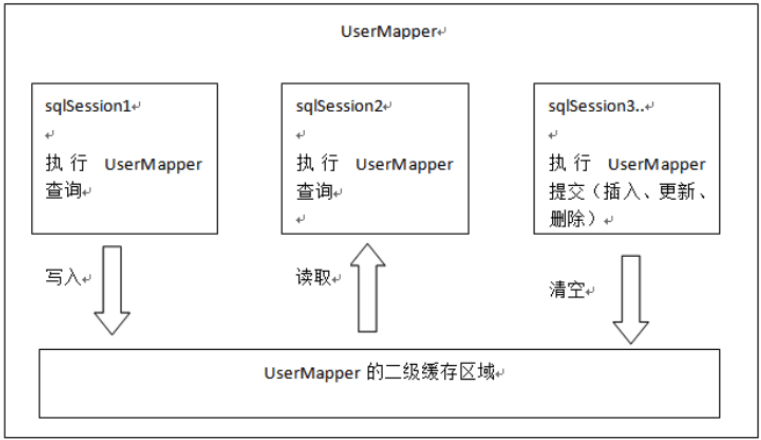
如何使用二级缓存
修改sqlMapConfig.xml,增加配置
<settings><setting name="cacheEnabled" value="true"/></settings>
之后,修改需要二级缓存的mapper.xml文件,加入cache即可
<cache/>
因为我们没有指定type,所以默认使用mybatis的二级缓存。
开启了⼆级缓存后,还需要将要缓存的pojo实现Serializable接⼝,为了将缓存数据取出执⾏反序列化操作,因为⼆级缓存数据存储介质多种多样,不⼀定只存在内存中,有可能存在硬盘中,如果我们要再取这个缓存的话,就需要反序列化了。所以mybatis中的pojo都去实现Serializable接口。
测试一下
@Testpublic void twoLevelCache() {SqlSession sqlSession = sqlSessionFactory.openSession();IUserMapper iUserMapper = sqlSession.getMapper(IUserMapper.class);System.out.println(iUserMapper.findAll());sqlSession.close();SqlSession sqlSession1 = sqlSessionFactory.openSession();IUserMapper iUserMapper1 = sqlSession1.getMapper(IUserMapper.class);System.out.println(iUserMapper1.findAll());sqlSession1.close();}
Cache Hit Ratio [com.lpy.mapper.IUserMapper]: 0.0Opening JDBC ConnectionCreated connection 1615039080.Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@60438a68]==> Preparing: SELECT *, o.id oid FROM user u left join orders o on o.uid = u.id==> Parameters:<== Columns: id, username, password, birthday, id, order_time, total, uid, oid<== Row: 1, lucy, 1, 2020-12-02, 1, 2021-10-23 10:01:46.0, 5.00, 1, 1<== Row: 2, lip, 2, 2021-10-21, 2, 2021-10-25 10:01:46.0, 10.00, 2, 2<== Row: 3, sc, 3, 2021-10-21, 3, 2021-10-27 10:01:46.0, 15.00, 3, 3<== Total: 3...Cache Hit Ratio [com.lpy.mapper.IUserMapper]: 0.5
首先可以看到不同的SqlSession只执行了一条sql,证明二级缓存生效了。其次可以看到第一查询缓存命中率 0%,是因为之前没有缓存,再次查询后命中率50%,是因为查询两次,有一次命中的缓存。
此处如果想既使xml中的配置二级缓存生效,又想mapper中的配置二级缓存生效,需要在Mapper接口加注解,name的值为当前接口的全类名
@CacheNamespaceRef(name = "com.lpy.mapper.IUserMapper")
再来测试一下修改的情况
@Testpublic void twoLevelCache2() {SqlSession sqlSession = sqlSessionFactory.openSession();IUserMapper iUserMapper = sqlSession.getMapper(IUserMapper.class);System.out.println(iUserMapper.findById(2));sqlSession.close();SqlSession sqlSession1 = sqlSessionFactory.openSession();IUserMapper iUserMapper1 = sqlSession1.getMapper(IUserMapper.class);User user = new User();user.setId(2);user.setUsername("lip");iUserMapper1.update(user);sqlSession1.commit();sqlSession1.close();SqlSession sqlSession2 = sqlSessionFactory.openSession();IUserMapper iUserMapper2 = sqlSession2.getMapper(IUserMapper.class);System.out.println(iUserMapper2.findById(2));sqlSession1.close();}
Cache Hit Ratio [com.lpy.mapper.IUserMapper]: 0.0Opening JDBC ConnectionCreated connection 230528013.Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@dbd940d]==> Preparing: select * from user where id = ?==> Parameters: 2(Integer)<== Columns: id, username, password, birthday<== Row: 2, lip, 2, 2021-10-21<== Total: 1User(id=2, username=lip, password=2, birthday=2021-10-21, orders=null)Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@dbd940d]Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@dbd940d]Returned connection 230528013 to pool.Opening JDBC ConnectionChecked out connection 230528013 from pool.Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@dbd940d]==> Preparing: update user set username = ? where id = ?==> Parameters: lip(String), 2(Integer)<== Updates: 1Committing JDBC Connection [com.mysql.jdbc.JDBC4Connection@dbd940d]Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@dbd940d]Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@dbd940d]Returned connection 230528013 to pool.Cache Hit Ratio [com.lpy.mapper.IUserMapper]: 0.0Opening JDBC ConnectionChecked out connection 230528013 from pool.Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@dbd940d]==> Preparing: select * from user where id = ?==> Parameters: 2(Integer)<== Columns: id, username, password, birthday<== Row: 2, lip, 2, 2021-10-21<== Total: 1User(id=2, username=lip, password=2, birthday=2021-10-21, orders=null)Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@dbd940d]
useCache和flushCache
在xml的statement中配置useCache=”false”则查询会禁用二级缓存,每次都查询数据库,默认为true,即会使用二级缓存。
<select id="findAll" resultMap="userMap" useCache="false">SELECT *, o.id oidFROM user uleft join orders o on o.uid = u.id</select>
同样的 如果配置flushCache=”false” 可以使增删改操作不清除缓存,但这样会造成脏读问题,所以一般默认刷新缓存就好。
注解方式:
@Options(useCache = false)@Select("select * from user where id = #{id}")User findById(Integer id);@Options(flushCache = Options.FlushCachePolicy.FALSE)@Update("update user set username = #{username} where id = #{id}")void update(User user);
二级缓存整合redis
上⾯我们介绍了 mybatis⾃带的⼆级缓存,但是这个缓存是单服务器⼯作,⽆法实现分布式缓存。 那么什么是分布式缓存呢?假设现在有两个服务器1和2,⽤户访问的时候访问了 1 服务器,查询后的缓存就会放在 1 服务器上,假设现在有个⽤户访问的是2服务器,那么他在2服务器上就⽆法获取刚刚那个缓
存,如下图所示:

若有收获,就点个赞吧
0 人点赞
