第二章:Java内存区域与内存溢出异常
运行时数据区域
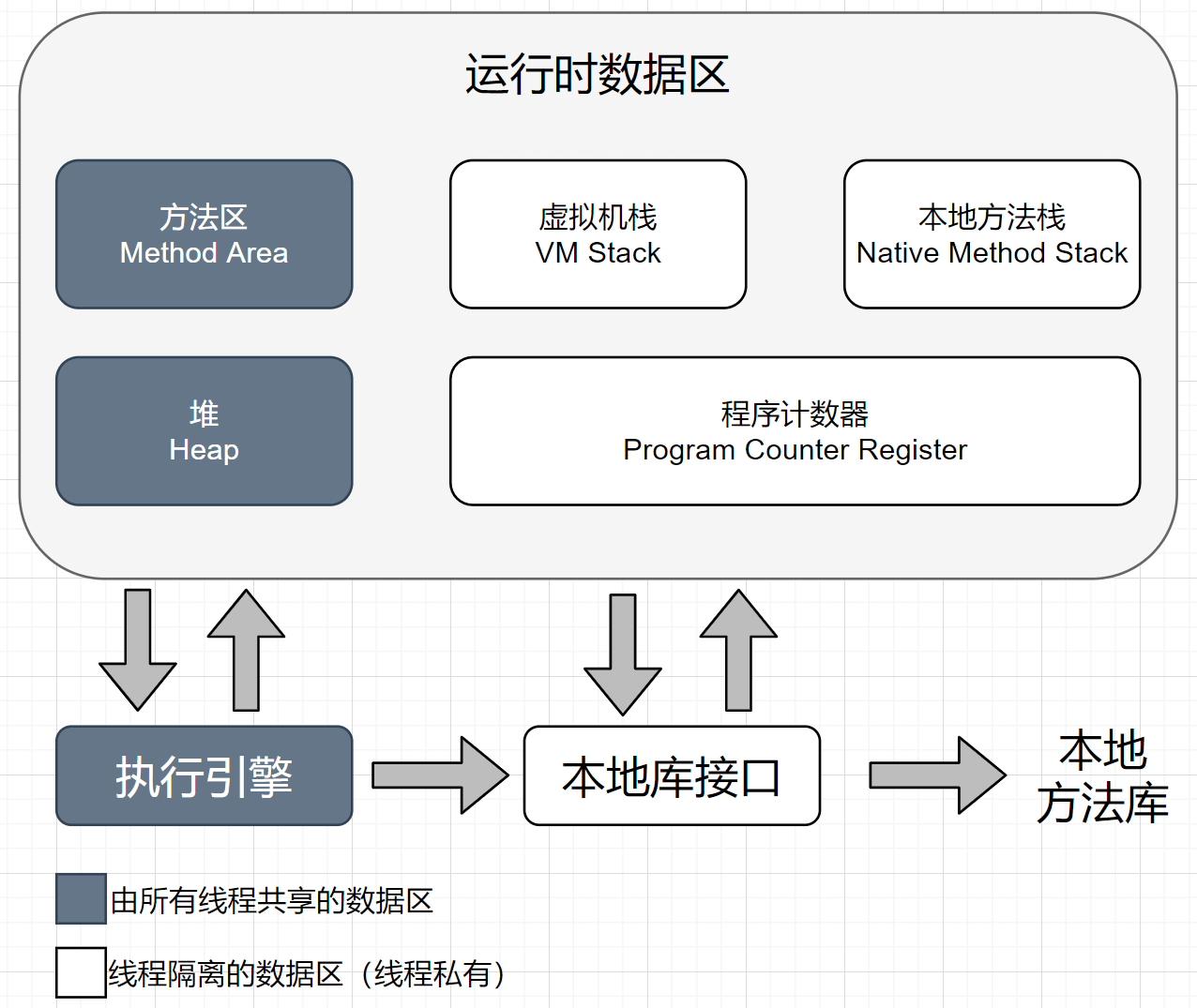
1、程序计数器 Program Counter Register
简述:可以看作是当前线程所执行的字节码的行号指示器。是一块内存较小的内存空间
存储:正在执行的虚拟机字节码指令的地址
作用:
- JVM通过改变这个计数器的值来选择下一条需要执行的字节码指令,它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
- Java虚拟机多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的(也就是线程状态的切换),为了线程切换后能恢复到正确的执行位置,为每个线程设定了程序计数器。
补充:
程序计数器由字节码执行引擎对其进行操作记录指令行号。
注意:
如果线程正在执行的是一个Java方法,计数器记录的是正在执行的虚拟机字节码指令的地址。
如果正在执行的是本地(Native)方法,计数器值则为空(Undefined)
计数器这块内存是唯一一个在《Java虚拟机规范》中没有规定任何OutOfMemoryError情况的区域。
2、Java虚拟机栈 VM Stack
简述:java虚拟机栈描述的是Java方法执行的线程内存模型,每个方法被执行的时候,JVM都会创建一个栈帧(入栈),方法调用完毕后栈帧出栈
存储:栈帧(局部变量表、操作数栈、动态连接、方法出口等信息)
| 局部变量表: 存储:编译期可知的各种Java虚拟机基本数据类型(八大)、对象引用(reference类型)、returnAddress类型(指向了一条字节码指令的地址) 注意:对象引用并不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或者其他与此对象相关的位置 |
|---|
3、本地方法栈 Native Method Stack
简述:与VM stack作用相似,其区别只是为虚拟机使用到的本地(Native)方法服务。
4、Java堆 Heap
简述:是JVM管理内存中最大的一块,所有线程共享,在JVM启动时创建,唯一目的就是存放对象实例。
存储:对象实例
Java堆是垃圾收集器管理的内存区域。堆中可以划分出多个线程私有的分配缓冲区(TLAB),以提升对象分配时的效率。Java堆细分的目的只是为了更好地回收内存,或者更快地分配内存。
Java堆可以处于物理上不连续的内存空间,但是在逻辑上应该被视为连续的。但对于大对象(典型如数组对象),多数虚拟机实现出于简单、存储高效的考虑,很可能会要求连续的内存空间。
5、方法区 Method Area
存储:已被虚拟机加载的类信息、常量、静态变量、即使编译器编译后的代码缓存等数据。
注意:《Java虚拟机规范》中把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做“非堆”,目的是与Java堆区分开。
6、运行时常量池 Runtime Constant Pool
描述:是方法区的一部分
存储:字面量、符号引用、由符号引用翻译出的直接引用
Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池表(Constant Pool Table),用于存放编译期生成的各种字面量与符号引用,这部分内容将在类加载后存放到方法区的运行时常量池。
HotSpot虚拟机对象探秘
对象的创建
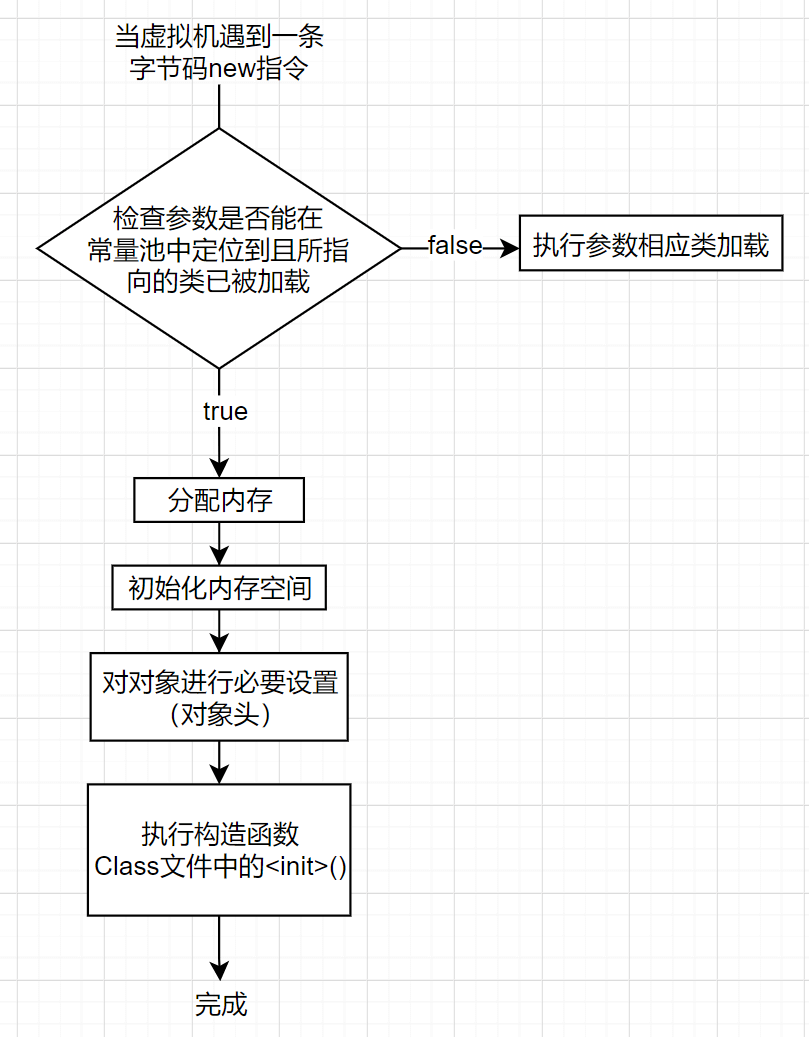
对象的内存布局
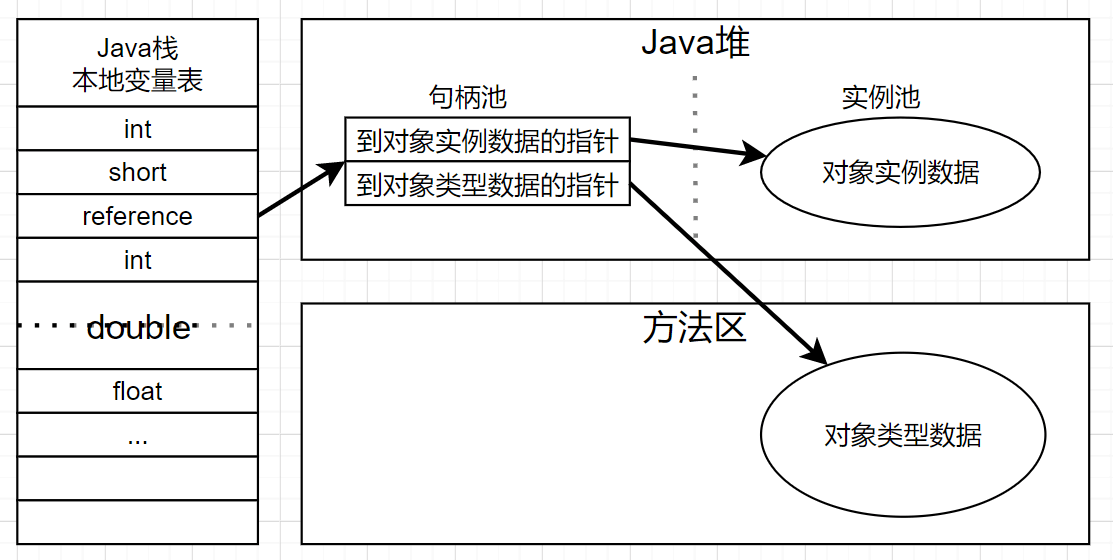
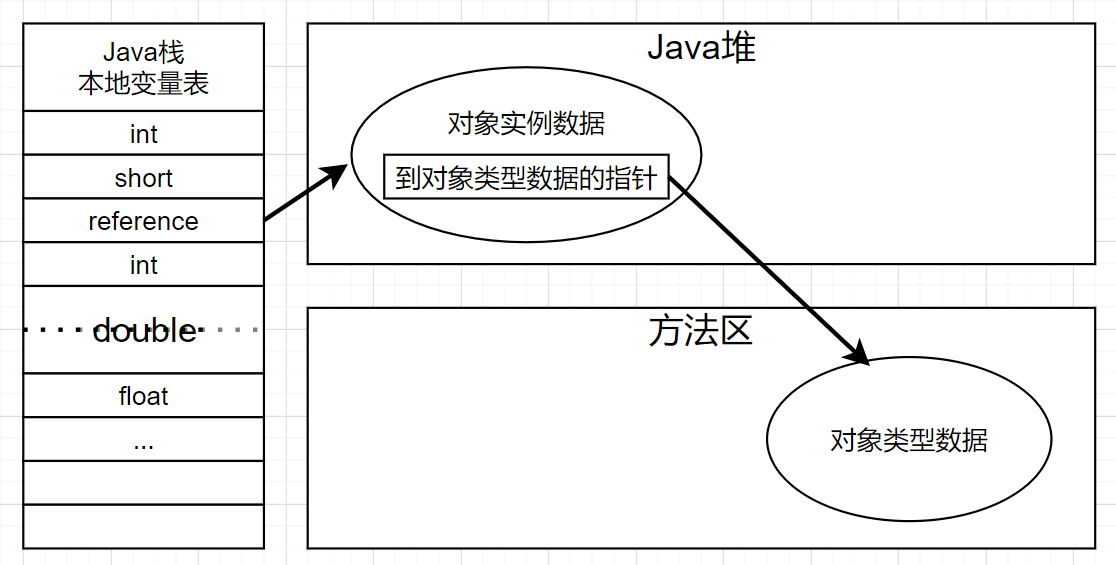
HotSpot虚拟机里,对象在堆内存中的存储布局可以划分为三个部分:
- 对象头(Header)包含以下三种数据:
- 对象自身运行时数据(Mark Word),如hash码、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。有着动态定义的数据机构。
- 类型指针:指向对象类型元数据的指针
- 如果对象是Java数组,还会有一块用来记录数组长度的数据。
- 示例数据(Instance Data)
- 是对象真正存储的有效信息。
- 对齐填充(Padding)
垃圾收集器
垃圾收集算法
GCRoot
Java 可以做GCRoots的对象
- 虚拟机栈(栈帧中的局部变量区,也叫做局部变量表
- 方法区中的类静态属性引用的对象。
- 方法区中常量引用的对象
- 本地方法栈中N( Native方法)引用的对象
三色标记(黑、灰、白)
查看JVM默认参数配置:-XX:+PrintCommandLineFlags -version
控制台输出: -XX:InitialHeapSize=265603904 -XX:MaxHeapSize=4249662464 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC 👈默认垃圾收集器 java version “1.8.0_40” Java(TM) SE Runtime Environment (build 1.8.0_40-b25) Java HotSpot(TM) 64-Bit Server VM (build 25.40-b25, mixed mode)

部分参数预先说明
DefNew:Default New Generation<br /> Tenured:Old<br /> ParNew:Parallel New Generation<br /> PSYoungGen:Parallel Scavenge<br /> ParOldGen:Parallel Old Generation
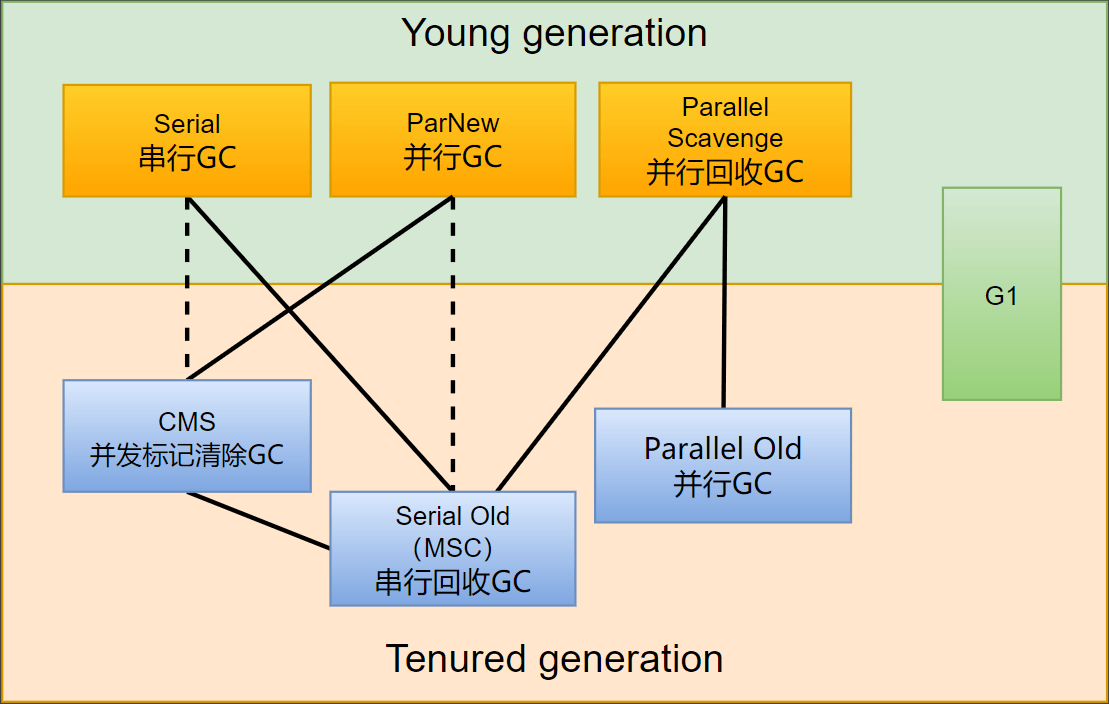
新生代
串行GC(Serial)/(Serial Coping)
并行GC(ParNew)
并行回收GC(Parallel)/(Parallel Scavenge)
老年代
串行回收GC(Serial Old)/(Serial MSC)
并行GC(Parallel Old)/(Parallel MSC)
并发标记清除GC(CMS)
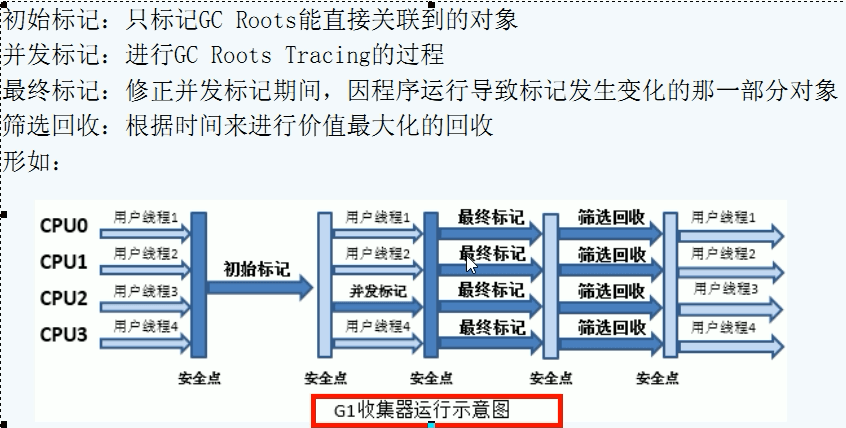
初始标记(CMS initial mark) :标记GCROOT可直达对象,耗时短
并发标记(CMS concurrent mark)和用户线程一起:从第一步标记的对象出发,并发标记可达对象
重新标记(CMS remark):修正并发标记时发送变化的对象及产生的对象,耗时短
并发清除(CMS concurrent sweep)和用户线程一起:并行的对无用的对象清除
优缺点
优
并发收集低停顿
缺
并发执行,对CPU资源压力大,在并发进行时会增加堆内存的占用,CMS必须在老年代内存用完前完成垃圾回收,否则CMS回收失败,将触发担保机制,串行老年代会以STW形式进行一次GC,从而造成较长停顿。
采用的标记清除算法会导致大量碎片,无法整理空间碎片,老年代会随着应用时长被耗尽,最后不得不通过担保机制对堆内存进行压缩。CMS提供了-XX:CMSFullGCsBeForeCompaction(默认0,即每次进行内存整理)来指定执行多少次CMS后进行一次压缩的Full GC
G1收集器
以前收集器特点
- 年轻代和老年代是各自独立且连续的内存块
- 年轻代收集使用单eden+S0 +S进行复制算法
- 老年代收集必须扫描整个老年代区域
- 都是以尽可能少而快速地执行GC为设计原则
G1是一种服务器端的垃圾收集器,应用在多处理器和大容量内存环境中,在实现高吞吐量的同时,尽可能满足垃圾收集器暂停时间的要求。另外:可以与应用线程并发执行。整理空闲空间更快。需要更多时间来预测GC停顿时间。不希望牺牲大量的吞吐性能。不需要更大的java heap。
G1收集器的设计目的是取代CMS收集器
G1特点:
- 充分利用多CPU、多核环境硬件的优势,尽量缩短了STW
- 整体使用标记整理,局部使用复制,不会产生内存碎片
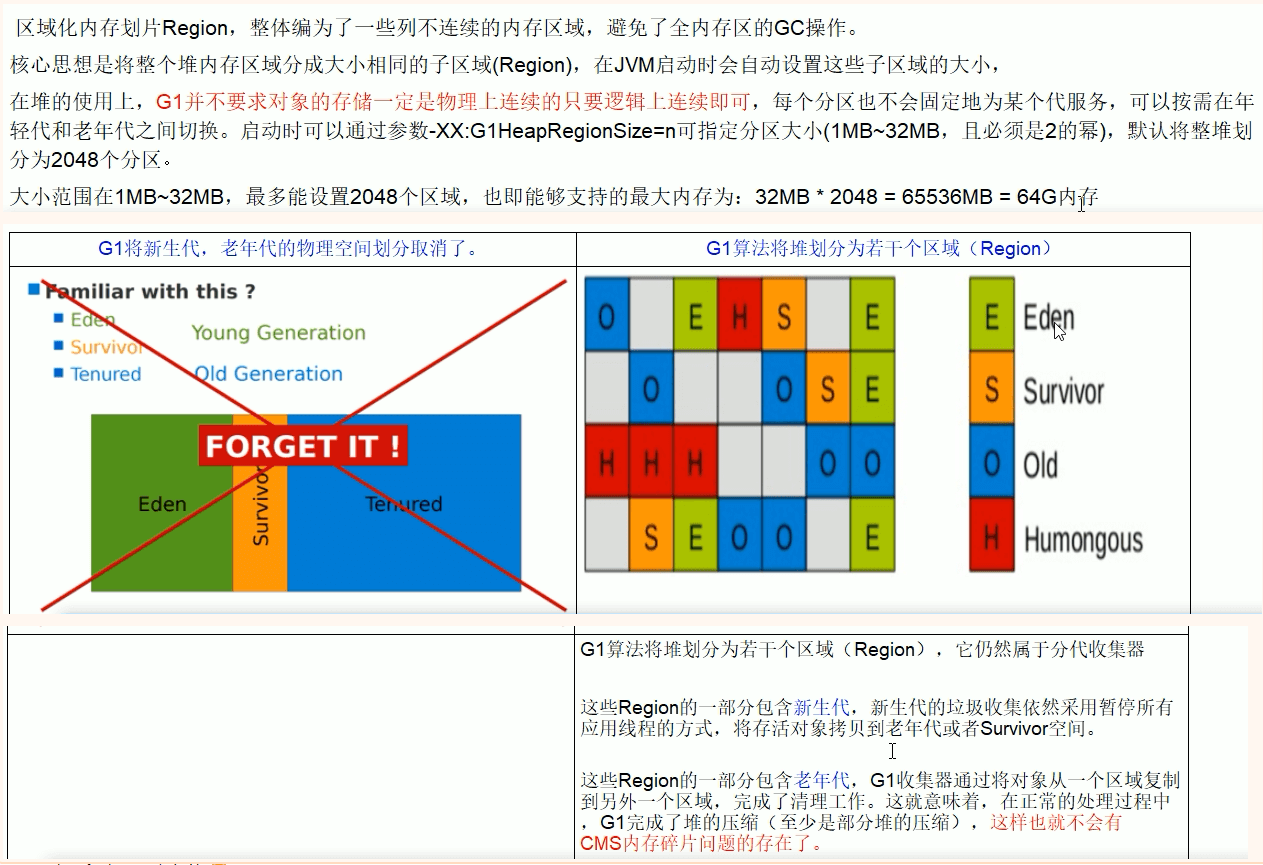
- 把内存分为多个独立子区域(Region),宏观上不区分年轻代和老年代
- 采用不同的GC方式处理不同区域(不连续的某系Region构成年轻代和老年代)
- Region划分的区间(年轻/老年/大对象)是可以动态改变的
底层原理
Region区域化垃圾收集器
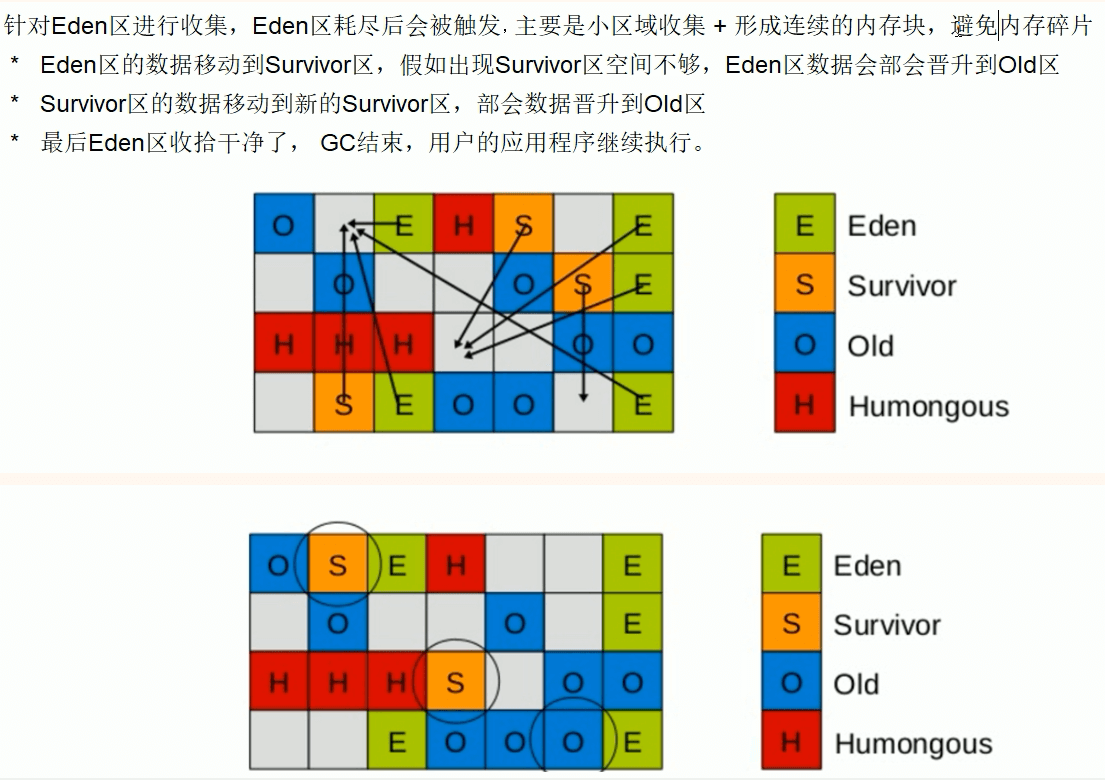
回收过程
四个步骤
常用配置参数(了解)
-XX:+UseG1GC
-XX:G1HeapRegionSize=n : 设置G1区域的大小。值是2的幂,范围是1M到32M。目标是根据最小的Java堆大小划分出约2048个区域
-XX:MaxGCPauseMillis=n : 最大停顿时间,这是个软目标,JVM将尽可能(但不保证)停顿时间小于这个时间
-XX:InitiatingHeapOccupancyPercent=n 堆占用了多少的时候就触发GC,默认是45
-XX:ConcGCThreads=n 并发GC使用的线程数
-XX:G1ReservePercent=n 设置作为空闲空间的预留内存百分比,以降低目标空间溢出的风险,默认值是10%

若有收获,就点个赞吧
0 人点赞
