No.1 冒泡排序
冒泡排序无疑是最为出名的排序算法之一,从序列的一端开始往另一端冒泡(你可以从左往右冒泡,也可以从右往左冒泡,看心情),依次比较相邻的两个数的大小(到底是比大还是比小也看你心情)。

每轮都把最大或最小的数找出来,就像一个个泡泡吐出来一样,因此叫冒泡排序。
冒泡的代码还是相当简单的,两层循环,外层冒泡轮数,里层依次比较,江湖中人人尽皆知。
我们看到嵌套循环,应该立马就可以得出这个算法的时间复杂度为O(n2)。
代码:
for i := 0; i < len(arr)-1; i++ { //一共需要len(arr)-1 轮for j := 0; j < len(arr)-1-i; j++ {if arr[j] < arr[j+1] { //从大到小排序,> 则代表从小到大排序。tmp := arr[j]arr[j] = arr[j+1]arr[j+1] = tmp}}}
No.2 选择排序
选择排序的思路是这样的:首先,找到数组中最小的元素,拎出来,将它和数组的第一个元素交换位置,第二步,在剩下的元素中继续寻找最小的元素,拎出来,和数组的第二个元素交换位置,如此循环,直到整个数组排序完成。

双层循环,时间复杂度和冒泡一模一样,都是O(n2)。
代码:
for i := 0; i < len(arr)-1; i++ { //排完前N-1个元素,最后一个元素也是有序的min := ifor j := i + 1; j < len(arr); j++ {//找到最小值if arr[j] < arr[min] {min = j}}//只有需要交换时,才交换位置if min != i {tmp := arr[i]arr[i] = arr[min]arr[min] = tmp}}
No.3 插入排序
插入排序的思想和我们打扑克摸牌的时候一样,从牌堆里一张一张摸起来的牌都是乱序的,我们会把摸起来的牌插入到左手中合适的位置,让左手中的牌时刻保持一个有序的状态。
那如果我们不是从牌堆里摸牌,而是左手里面初始化就是一堆乱牌呢? 一样的道理,我们把牌往手的右边挪一挪,把手的左边空出一点位置来,然后在乱牌中抽一张出来,插入到左边,再抽一张出来,插入到左边,再抽一张,插入到左边,每次插入都插入到左边合适的位置,时刻保持左边的牌是有序的,直到右边的牌抽完,则排序完毕。
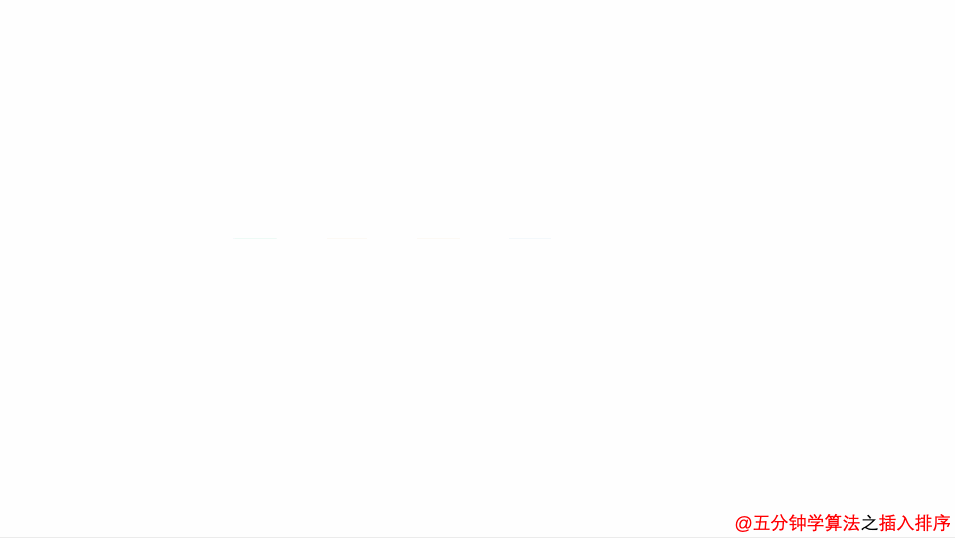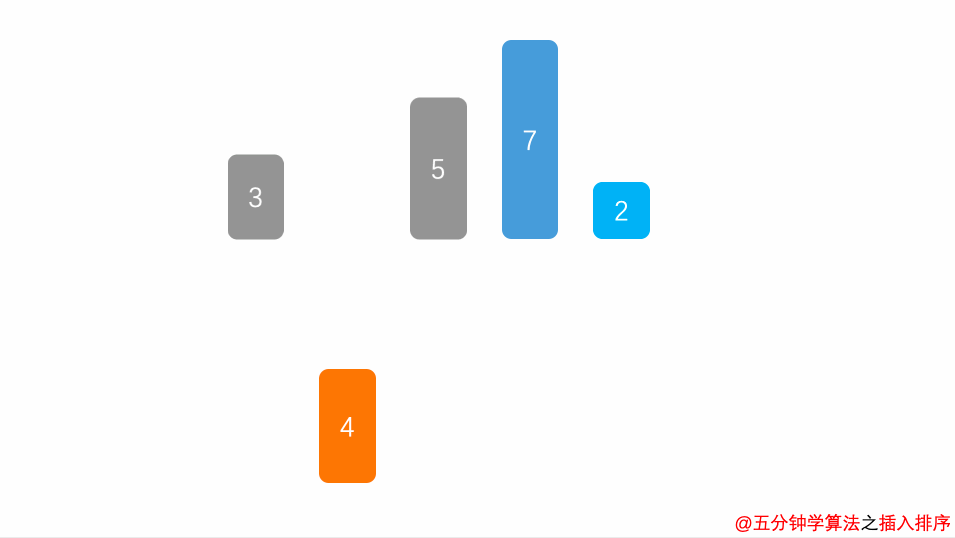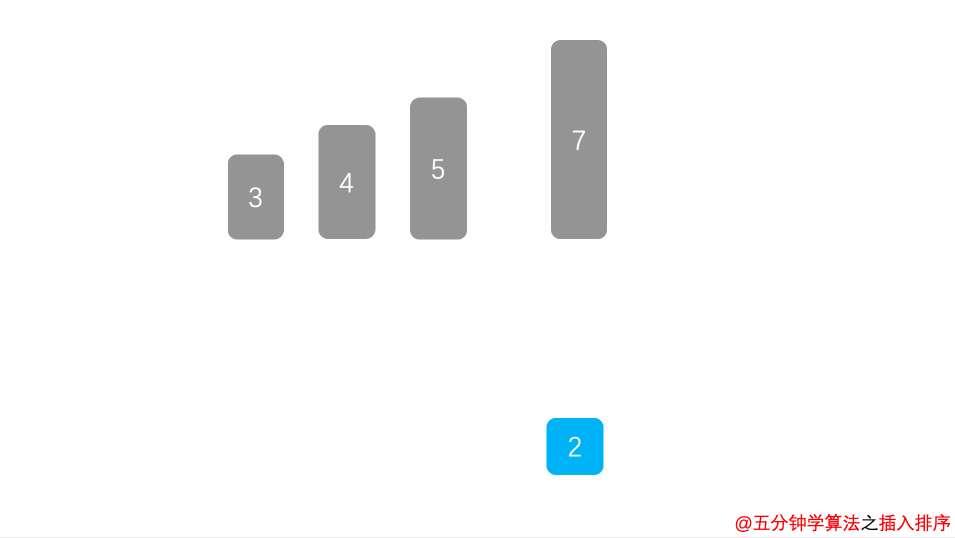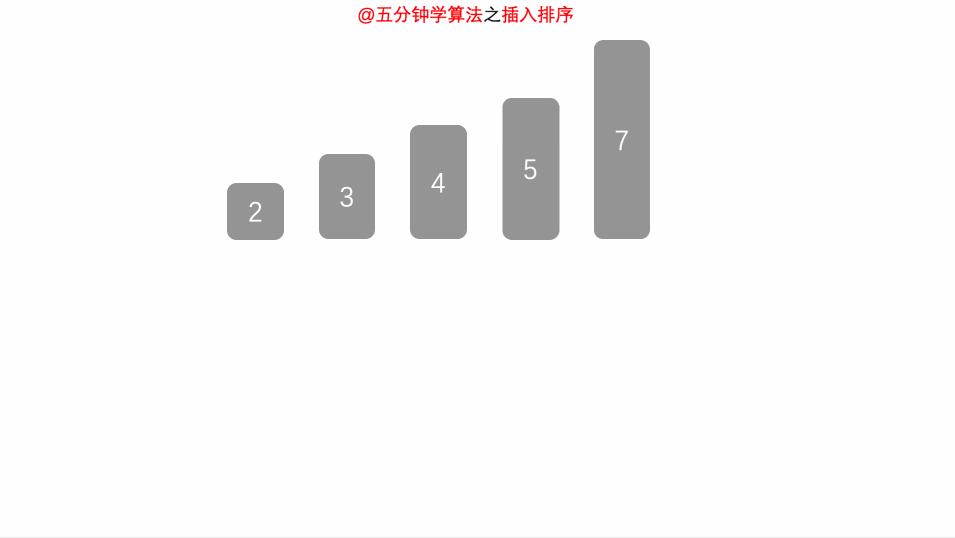
我们把数组中的数据分成两个区域,已排序区域和未排序区域,初始化的时候所有的数据都处在未排序区域中,已排序区域是空。
其实就是每次从未排序区域拿一条数据放到已排序区域中。
代码:
arr := []int{2, 1, 3, 5, 7, 7, 9, 0, 11, -1, 2}n := len(arr)//未排序区域。for i := 1; i < n; i++ {value := arr[i]j := i - 1//已排序区域,需要找到合适的位置插入。//这一步是判断是否需要挪位置。for j >= 0 && arr[j] > value {arr[j+1] = arr[j]j--}arr[j+1] = value}
从代码里我们可以看出,如果找到了合适的位置,就不会再进行比较了,就好比牌堆里抽出的一张牌本身就比我手里的牌都小,那么我只需要直接放在末尾就行了,不用一个一个去移动数据腾出位置插入到中间。
所以说,最好情况的时间复杂度是 O(n),最坏情况的时间复杂度是 O(n2),然而时间复杂度这个指标看的是最坏的情况,而不是最好的情况,所以插入排序的时间复杂度是 O(n2)。
No.4 希尔排序
希尔排序这个名字,来源于它的发明者希尔,也称作“缩小增量排序”,是插入排序的一种更高效的改进版本。
我们知道,插入排序对于大规模的乱序数组的时候效率是比较慢的,因为它每次只能将数据移动一位,希尔排序为了加快插入的速度,让数据移动的时候可以实现跳跃移动,节省了一部分的时间开支。
 代码:
代码:
arr := []int{2, 1, 3, 5, 7, 7, 9, 0, 11, -1, 2}n := len(arr)gap := 1for gap < n {gap = gap*3 + 1}for gap > 0 {for i := gap; i < n; i++ {value := arr[i]j := i - gapfor j >= 0 && arr[j] > value {arr[j+gap] = arr[j]j -= gap}arr[j+gap] = value}gap = gap / 3}
可能你会问为什么区间要以 gap = gap*3 + 1 去计算,其实最优的区间计算方法是没有答案的,这是一个长期未解决的问题,不过差不多都会取在二分之一到三分之一附近。
希尔排序时间复杂度是 O(n^(1.3-2)),空间复杂度为常数阶 O(1)。希尔排序没有时间复杂度为 O(n(logn)) 的快速排序算法快 ,因此对中等大小规模表现良好,但对规模非常大的数据排序不是最优选择,总之比一般 O(n^2 ) 复杂度的算法快得多。
No.5 归并排序
归并字面上的意思是合并,归并算法的核心思想是分治法,就是将一个数组一刀切两半,递归切,直到切成单个元素,然后重新组装合并,单个元素合并成小数组,两个小数组合并成大数组,直到最终合并完成,排序完毕。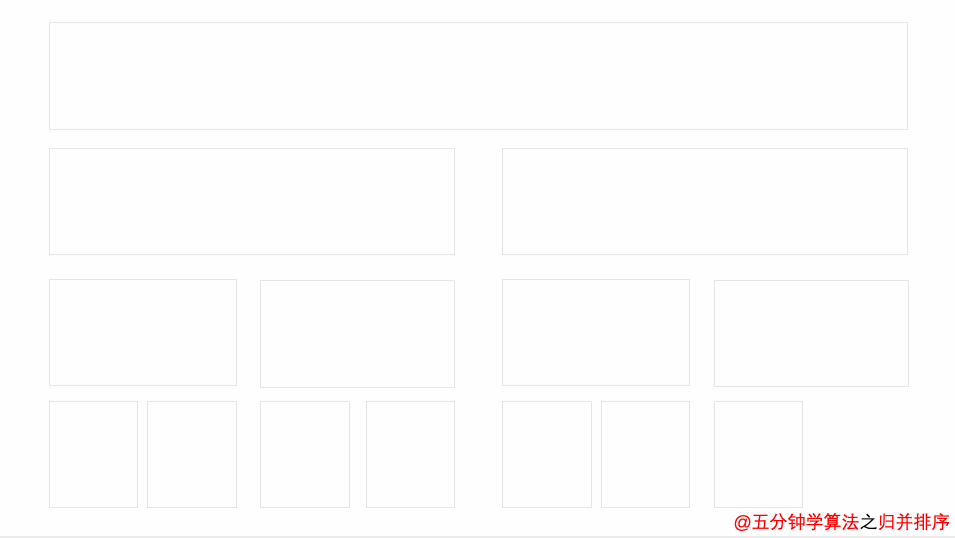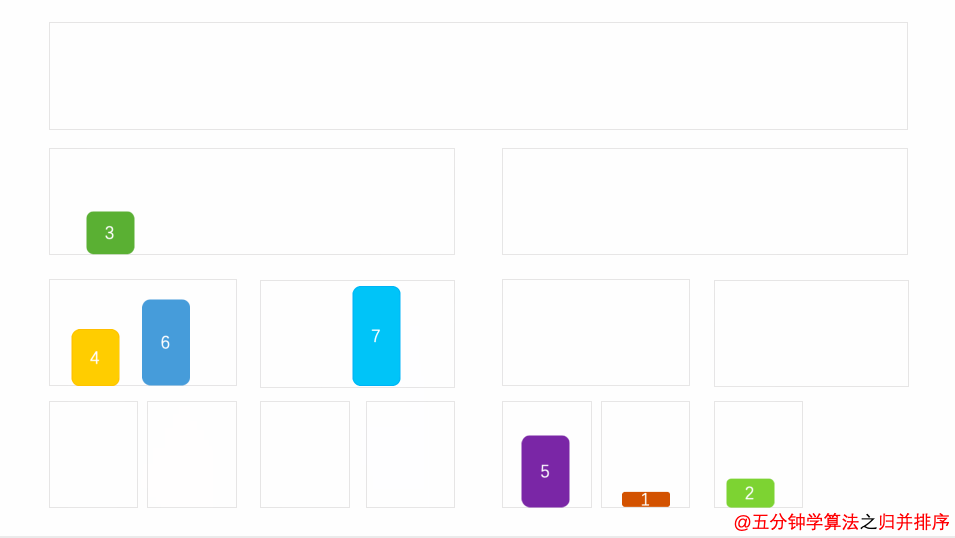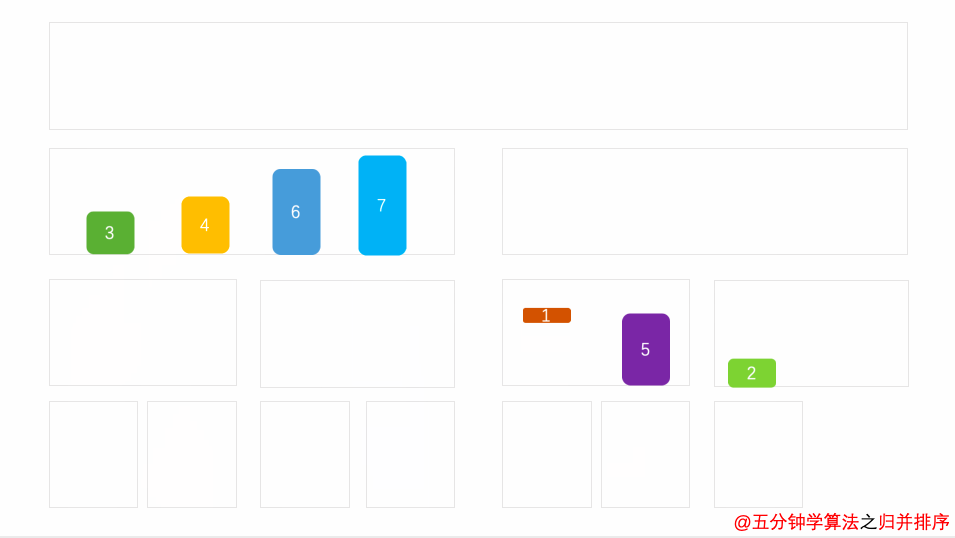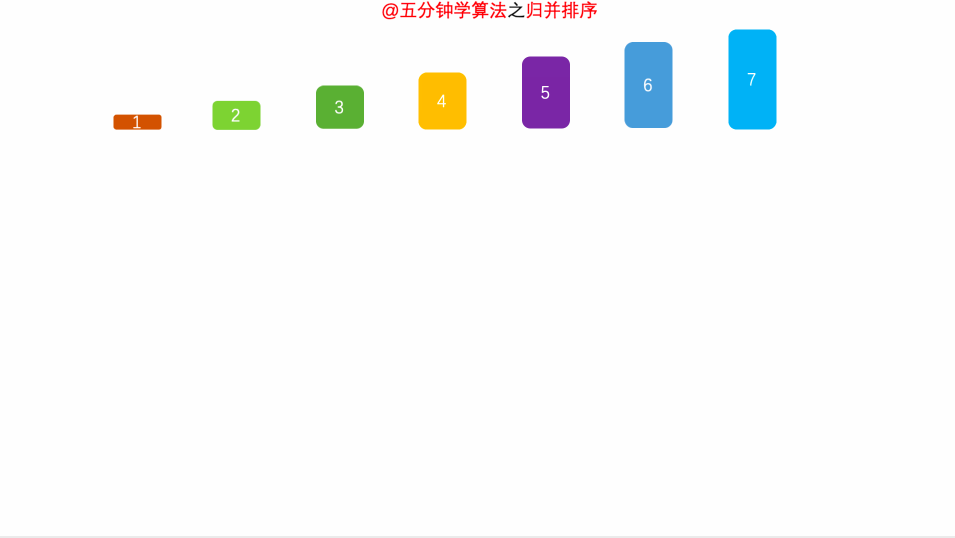
代码:
func main() {arr := []int{5, 3, 2, 7, 8, 9, 10, -1, 3, 4}tmp := make([]int, len(arr))sort(arr, tmp, 0, len(arr)-1)fmt.Println(arr)}func sort(arr []int, tmp []int, start int, end int) {if start >= end {return}mid := start + (end-start)/2//左半部分排序sort(arr, tmp, start, mid)//右半部分排序sort(arr, tmp, mid+1, end)//合并merge(arr, tmp, start, mid, end)}func merge(arr []int, tmp []int, start int, mid int, end int) {//复制要合并的数据for i := start; i <= end; i++ {tmp[i] = arr[i]}left := startright := mid + 1for i := start; i <= end; i++ {if left > mid {//如果左边的首位下标大于中部下标,证明左边的数据已经排完了。arr[i] = tmp[right]right++} else if right > end {//如果右边的首位下标大于了数组长度,证明右边的数据已经排完了。arr[i] = tmp[left]left++} else if tmp[left] < tmp[right] {arr[i] = tmp[left]//将左边的首位排入,然后左边的下标指针+1。left++} else {arr[i] = tmp[right]//将右边的首位排入,然后右边的下标指针+1。right++}}}
我们可以发现 merge 方法中只有一个 for 循环,直接就可以得出每次合并的时间复杂度为 O(n) ,而分解数组每次对半切割,属于对数时间 O(log n) ,合起来等于 O(log2n) ,也就是说,总的时间复杂度为 O(nlogn) 。
关于空间复杂度,其实大部分人写的归并都是在 merge 方法里面申请临时数组,用临时数组来辅助排序工作,空间复杂度为 O(n),而我这里做的是原地归并,只在最开始申请了一个临时数组,所以空间复杂度为 O(1)。
剑指 Offer 51. 数组中的逆序对
No.6 快速排序
快速排序的核心思想也是分治法,分而治之。它的实现方式是每次从序列中选出一个基准值,其他数依次和基准值做比较,比基准值大的放右边,比基准值小的放左边,然后再对左边和右边的两组数分别选出一个基准值,进行同样的比较移动,重复步骤,直到最后都变成单个元素,整个数组就成了有序的序列。

代码:
func sort(arr []int, start int, end int) {if start >= end {return}pivotIndex := partition(arr, start, end)sort(arr, start, pivotIndex-1)sort(arr, pivotIndex+1, end)}func partition(arr []int, start int, end int) int {pivot := arr[start] //选取第一个元素作为基准值mark := start//将小于pivot的值放入左侧for i := start + 1; i <= end; i++ {if arr[i] < pivot {mark++tmp := arr[mark]arr[mark] = arr[i]arr[i] = tmp}}arr[start] = arr[mark]arr[mark] = pivotreturn mark}
快速排序的时间复杂度和归并排序一样,O(n log n),但这是建立在每次切分都能把数组一刀切两半差不多大的前提下,如果出现极端情况,比如排一个有序的序列,如[ 9,8,7,6,5,4,3,2,1 ],选取基准值 9 ,那么需要切分 n – 1 次才能完成整个快速排序的过程,这种情况下,时间复杂度就退化成了 O(n2),当然极端情况出现的概率也是比较低的。
所以说,快速排序的时间复杂度是 O(nlogn),极端情况下会退化成 O(n2),为了避免极端情况的发生,选取基准值应该做到随机选取,或者是打乱一下数组再选取。
另外,快速排序的空间复杂度为 O(1)。
No.7 堆排序
堆排序顾名思义,是利用堆这种数据结构来进行排序的算法。

代码:
其实就是实现一个大根堆或小根堆,堆顶是最大值或最小值。
堆排序和快速排序的时间复杂度都一样是 O(nlogn)。
No.8 计数排序
计数排序是一种非基于比较的排序算法,我们之前介绍的各种排序算法几乎都是基于元素之间的比较来进行排序的,计数排序的时间复杂度为 O(n + m ),m 指的是数据量,说的简单点,计数排序算法的时间复杂度约等于 O(n),快于任何比较型的排序算法。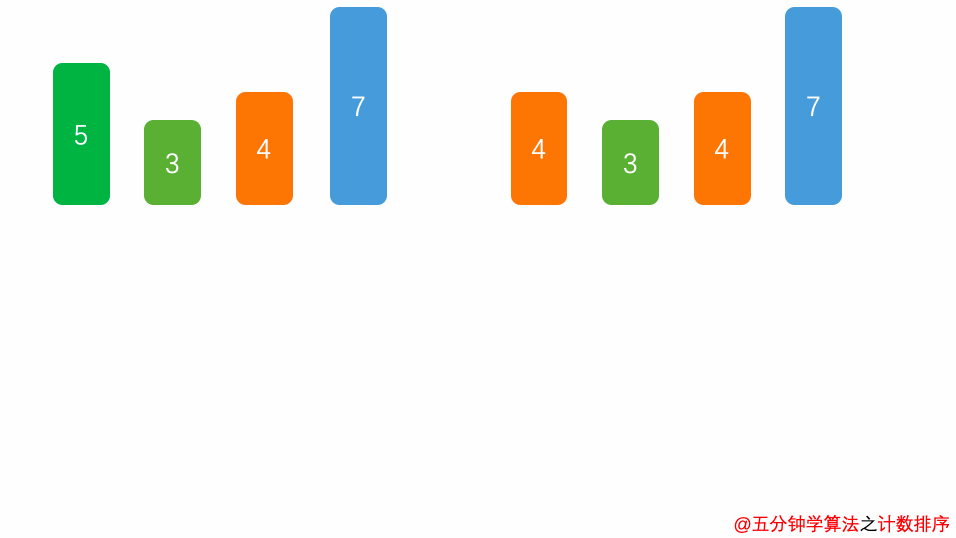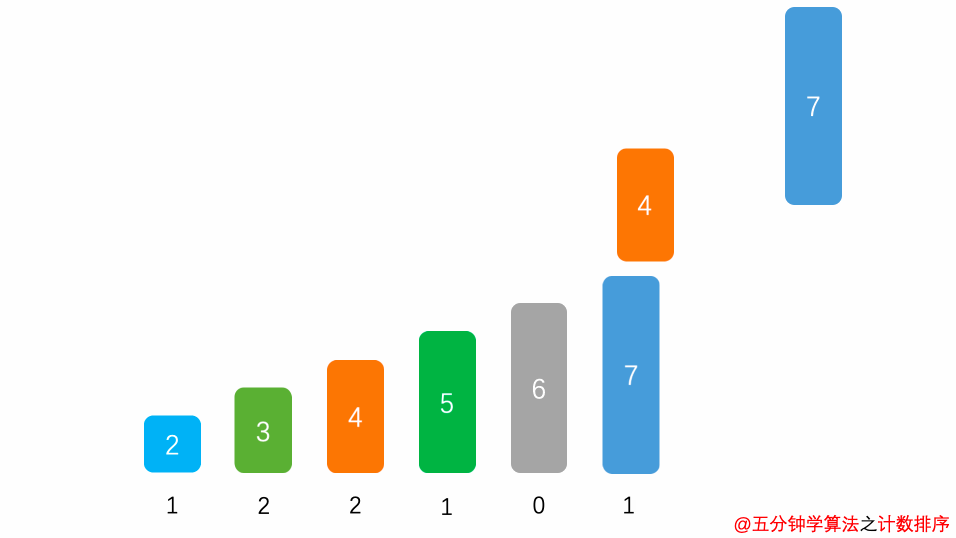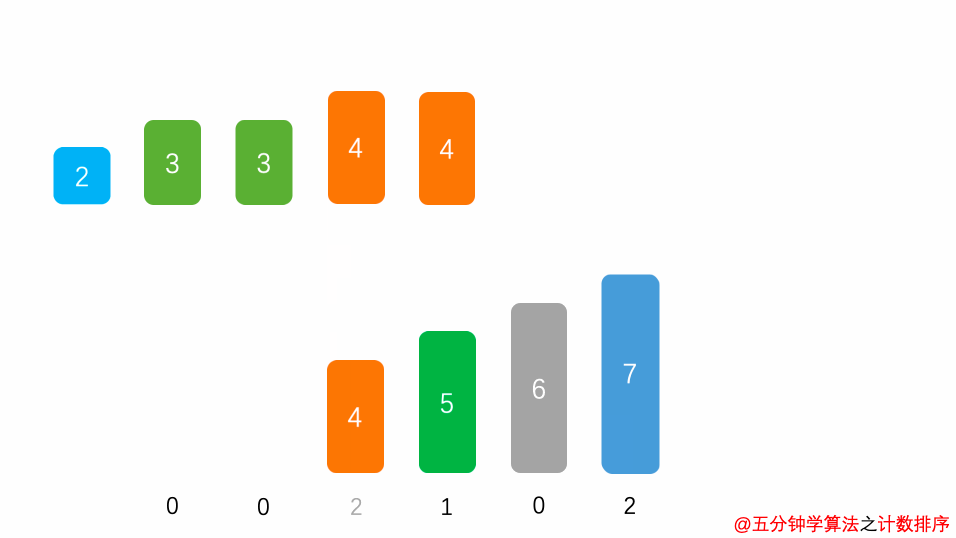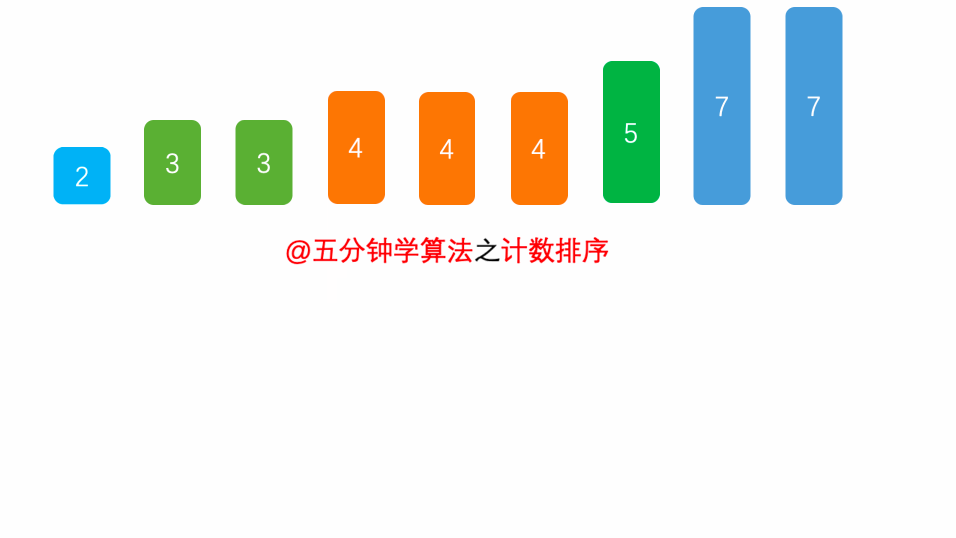
代码:
public static void sort(int[] arr) {//找出数组中的最大值int max = arr[0];for (int i = 1; i < arr.length; i++) {if (arr[i] > max) {max = arr[i];}}//初始化计数数组int[] countArr = new int[max + 1];//计数for (int i = 0; i < arr.length; i++) {countArr[arr[i]]++;arr[i] = 0;}//排序int index = 0;for (int i = 0; i < countArr.length; i++) {if (countArr[i] > 0) {arr[index++] = i;}}}
计数排序的毛病很多,我们来找找 bug 。
如果我要排的数据里有 0 呢? int[] 初始化内容全是 0 ,排毛线。
如果我要排的数据范围比较大呢?比如[ 1,9999 ],我排两个数你要创建一个 int[10000] 的数组来计数?
对于第一个 bug ,我们可以使用偏移量来解决,比如我要排[ -1,0,-3 ]这组数字,这个简单,我全给你们加 10 来计数,变成[ 9,10,7 ]计完数后写回原数组时再减 10。不过有可能也会踩到坑,万一你数组里恰好有一个 -10,你加上 10 后又变 0 了,排毛线。
对于第二个 bug ,确实解决不了,如果是[ 9998,9999 ]这种虽然值大但是相差范围不大的数据我们也可以使用偏移量解决,比如这两个数据,我减掉 9997 后只需要申请一个 int[3] 的数组就可以进行计数。
由此可见,计数排序只适用于正整数并且取值范围相差不大的数组排序使用,它的排序的速度是非常可观的。
No.9 桶排序
桶排序可以看成是计数排序的升级版,它将要排的数据分到多个有序的桶里,每个桶里的数据再单独排序,再把每个桶的数据依次取出,即可完成排序。 代码:
代码:
func sortNum(arr []int) {//最大值,最小值max := arr[0]min := arr[0]n := len(arr)for i := 1; i < n; i++ {if arr[i] > max {max = arr[i]}if arr[i] < min {min = arr[i]}}//创建桶buckets := make([][]int, n)//数据入桶for i := 0; i < n; i++ {index := arr[i] * (n - 1) / max //分配到哪个桶,桶映射关系写的并不好。fmt.Println(index)if index < 0 {index = 0}buckets[index] = append(buckets[index], arr[i])}//桶内排序for i := 0; i < len(buckets); i++ {sort.Ints(buckets[i])}//写入原数组index := 0for _, bucket := range buckets {if len(bucket) > 0 {for _, v := range bucket {arr[index] = vindex++}}}
在额外空间充足的情况下,尽量增大桶的数量,极限情况下每个桶只有一个数据时,或者是每只桶只装一个值时,完全避开了桶内排序的操作,桶排序的最好时间复杂度就能够达到 O(n)。
比如高考总分 750 分,全国几百万人,我们只需要创建 751 个桶,循环一遍挨个扔进去,排序速度是毫秒级。
但是如果数据经过桶的划分之后,桶与桶的数据分布极不均匀,有些数据非常多,有些数据非常少,比如[ 8,2,9,10,1,23,53,22,12,9000 ]这十个数据,我们分成十个桶装,结果发现第一个桶装了 9 个数据,这是非常影响效率的情况,会使时间复杂度下降到 O(nlogn),解决办法是我们每次桶内排序时判断一下数据量,如果桶里的数据量过大,那么应该在桶里面回调自身再进行一次桶排序。
No.10 基数排序
基数排序是一种非比较型整数排序算法,其原理是将数据按位数切割成不同的数字,然后按每个位数分别比较。
假设说,我们要对 100 万个手机号码进行排序,应该选择什么排序算法呢?排的快的有归并、快排时间复杂度是 O(nlogn),计数排序和桶排序虽然更快一些,但是手机号码位数是11位,那得需要多少桶?内存条表示不服。
这个时候,我们使用基数排序是最好的选择。
代码:
//最大值,最小值max := arr[0]n := len(arr)for i := 1; i < n; i++ {if arr[i] > max {max = arr[i]}}location := 1buckets := make([][]int, 10)for {dd := int(math.Pow(float64(10), float64(location-1))) //从个位数开始if max < dd {break}//数据入桶for i := 0; i < n; i++ {number := (arr[i] / dd) % 10buckets[number] = append(buckets[number], arr[i])}//写回数组index := 0for i := 0; i < 10; i++ {size := len(buckets[i])for j := 0; j < size; j++ {arr[index] = buckets[i][j]index++}buckets[i] = []int{}}location++}
基数排序可以看成桶排序的扩展,也是用桶来辅助排序。先排个位数,再排十位数,以此类推。

若有收获,就点个赞吧
0 人点赞
